# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
通讯作者包括腾讯 AI Lab研究员宋林峰与涂兆鹏,以及厦门大学苏劲松教授。论文第一作者为厦门大学博士生王安特。
本文探讨基于树搜索的大语言模型推理过程中存在的「过思考」与「欠思考」问题,并提出高效树搜索框架——Fetch。本研究由腾讯 AI Lab 与厦门大学、苏州大学研究团队合作完成。

背景与动机
近月来,OpenAI-o1 展现的卓越推理性能激发了通过推理时计算扩展(Test-Time Computation)增强大语言模型(LLMs)推理能力的研究热潮。
该研究领域内,基于验证器引导的树搜索算法已成为相对成熟的技术路径。这类算法通过系统探索庞大的解空间,在复杂问题的最优解搜索方面展现出显著优势,其有效性已获得多项研究实证支持。
尽管诸如集束搜索(Beam Search)、最佳优先搜索(Best-First Search)、A*算法及蒙特卡洛树搜索(MCTS)等传统树搜索算法已得到广泛探索,但其固有缺陷仍待解决:树搜索算法需承担高昂的计算开销,且难以根据问题复杂度动态调整计算资源分配。
针对上述挑战,研究团队通过系统性解构树搜索的行为范式,首次揭示了该推理过程中存在的「过思考」与「欠思考」双重困境。
「过思考」与「欠思考」
研究团队选取最佳优先搜索算法为研究对象,基于 GSM8K 数据集开展系统性研究。实验设置中逐步增加子节点拓展数(N=2,3,5,10)时发现:模型性能虽持续提升但呈现边际效益递减规律(图 a),而计算开销却呈指数级增长(图 b),二者形成的显著差异揭示出传统树搜索在推理时计算扩展的效率瓶颈。
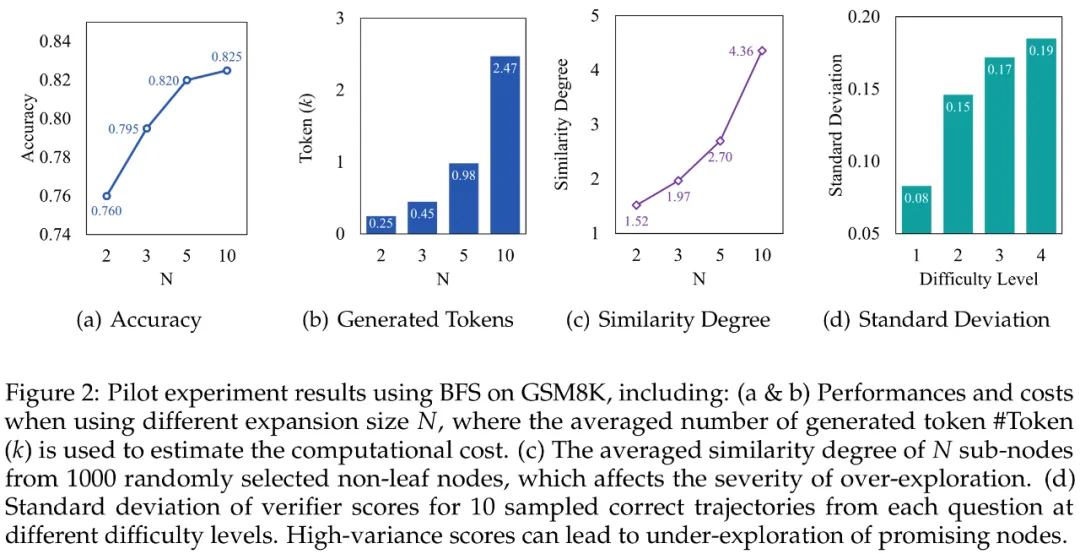
通过深度解构搜索过程,研究团队首次揭示搜索树中存在两类关键缺陷:
Fetch
为应对「过思考」与「欠思考」问题,研究团队提出适用于主流搜索算法的高效树搜索框架 Fetch,其核心包含两部分:
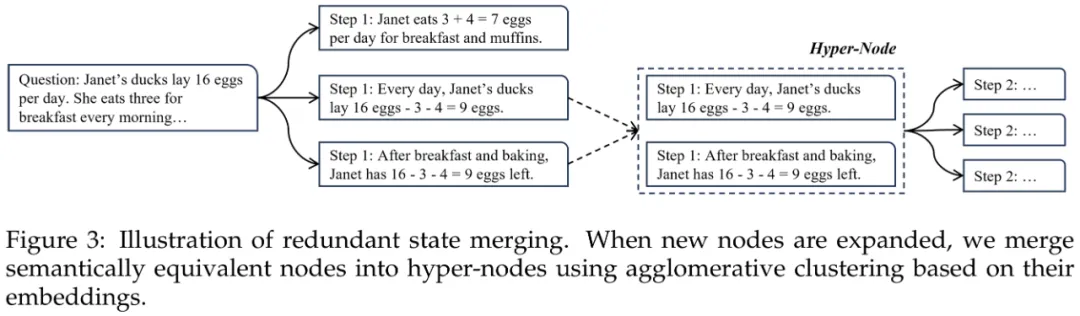
冗余节点合并

针对通用领域预训练 SimCSE 在数学推理场景下存在的领域适配问题,研究团队对 SimCSE 进一步微调。为此,提出两种可选的节点对语义等价标注方案:
最终,利用收集的节点对标注,通过交叉熵损失对 SimCSE 进行微调:
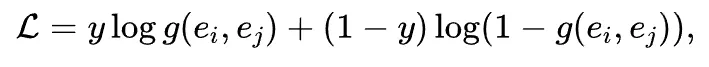

验证方差抑制
现有验证器普遍采用判别方式对树节点进行质量评分。传统训练方法基于强化学习经验,通过蒙特卡洛采样估计节点期望奖励:
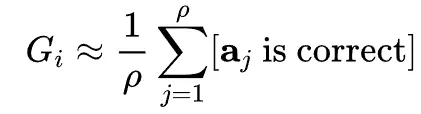

实验结果
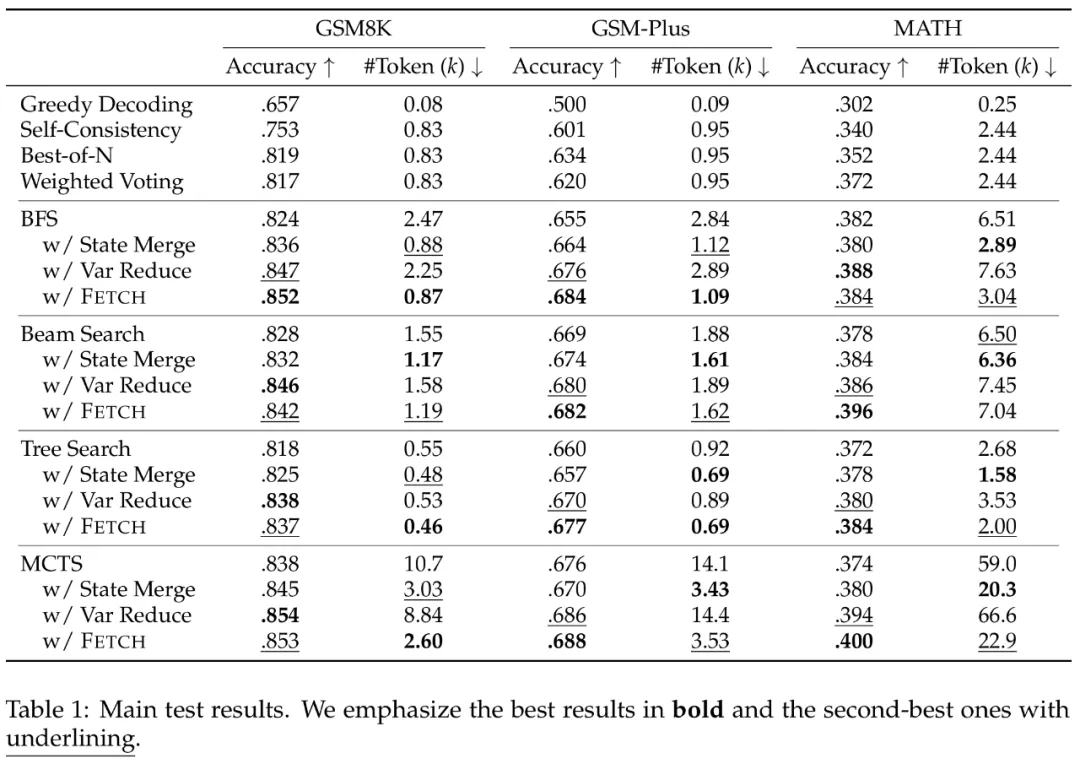
实验结果表明,Fetch 框架在跨数据集与跨算法测试中均展现出显著优势。例如,对于 BFS 及 MCTS 算法,相较于基线,Fetch 计算开销降低至原有的 1/3,并且保持 1~3 个点的准确率提升。
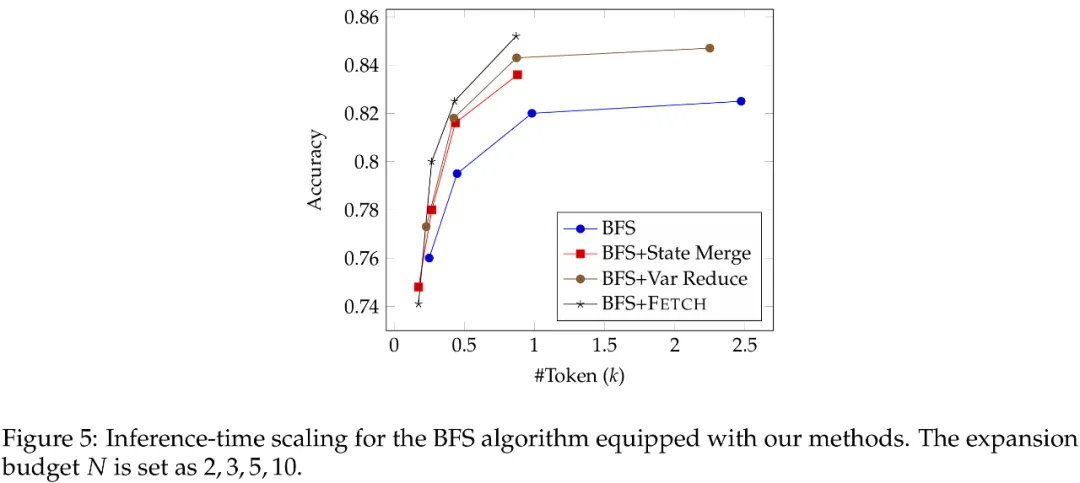
当测试时计算规模逐步提升时,Fetch 带来的增益也更加显著,验证了框架的效率优势。
总结
本研究由腾讯 AI Lab 联合厦门大学、苏州大学科研团队共同完成,首次揭示基于树搜索的大语言模型推理中存在的「过思考-欠思考」双重困境。
分析表明,该现象的核心成因源于两个关键缺陷:搜索树中大量语义冗余节点导致的无效计算循环,以及验证器评分方差过高引发的探索路径失焦。二者共同导致树搜索陷入计算资源错配困境——即消耗指数级算力却仅获得次线性性能提升。
针对上述挑战,研究团队提出高效树搜索框架 Fetch,其创新性体现在双重优化机制:
结果表明,Fetch 在 GSM8K、MATH 等基准测试中展现出显著优势:相较传统树搜索算法,框架实现了计算效率和性能的同步提升。该成果为提升大语言模型推理效能提供了新的方法论支持。
文章来自微信公众号 “ 机器之心 ”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
