# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

图片来源:Lightspeed
人工智能是前所未有的价值创造源泉,它重塑行业的速度甚至比我们在互联网、移动电话和云计算兴起时所观察到的平台和架构变革还要快。
不仅可用于游戏和互动媒体应用的生成,未来还有望在消费者和商业环境的复杂任务执行中发挥关键作用。
同时也存在着训练和运行世界模型所需的大量数据和计算能力以及如何处理模型产生的幻觉和偏差的两个主要问题。
通过渐进式创新和采用混合方法,或有望在游戏及机器人等领域实现广泛应用与突破。
Lightspeed是一家顶级风投公司,在AI领域投资广泛,如Anthropic、Stability AI等。
Naavik是专注游戏与AI领域分析的平台,通过发布深度报告等内容,帮助行业人士了解趋势,在游戏与AI融合领域有一定的专业地位与影响力。
如今像Gardens Interactive这样的顶级3A游戏工作室,大多数都非常擅长将人工开发与人工智能应用相结合,涵盖从代码辅助与测试,到程序性环境生成、
寻路算法以及社区管理等多个方面。那么在不远的未来,人工智能在游戏和互动媒体领域能否发挥更大的作用呢?
在Lightspeed公司,我们有着上下一致的信念并且始终坚持我们的观点:
人工智能是前所未有的价值创造源泉,它重塑行业的速度甚至比我们在互联网、移动电话和云计算兴起时所观察到的平台和架构变革还要快。
到目前为止,我们已经在人工智能技术栈领域的100多家公司投资了约25亿美元。
这些投资组合公司提供的产品范围广泛,从基础模型到原生人工智能开发者工具,
以及在企业、医疗保健、金融科技、消费者领域以及游戏和互动媒体等行业的应用。

图片来源:Lightspeed
上图是截至2025年2月26日Lightspeed在整个技术栈和行业垂直领域的人工智能投资组合情况。
需要说明的是,“人工智能”投资包括Lightspeed认为人工智能是其核心组成部分的公司,
包括原生人工智能公司和具备人工智能能力的公司,涵盖机器学习、自动化和数据分析等技术。
随着我们越来越多的时间花在网上并与数字内容互动,人工智能对游戏和互动媒体的影响不仅塑造了Lightspeed的投资策略,
比如支持定义品类的公司(ZP注:通常表示对在特定领域或行业中具有开创性、引领性,能够定义该领域产品或服务标准和范畴的公司),
包括在人工智能角色开发领域的Inworld、人工智能视频生成领域的Pika以及人工智能音乐创作领域的Suno,也深刻地影响了消费者的游戏、工作和社交方式。
虽然就人工智能应用的开发和消费者采用情况而言,我们仍处于相对早期的阶段,但我们已经看到基础模型在各种媒体形式中创造了巨大的经济价值,
包括:文本(例如,OpenAI的ChatGPT、Anthropic的Claude、xAI的Grok等);
音频和音乐(例如,Suno、ElevenLabs等),二维图像(例如,OpenAI的DALL·E 3、FLUX.1、Stable Diffusion 3.5、Ideogram、Midjourney等),
以及最近的二维视频(例如,Pika 2.0、Sora、Runway Gen-3 Alpha、Luma Photon、谷歌DeepMind的Veo 2等)——也被视为“3D”(二维加时间)。
这些基础性创新使消费者、创作者、爱好者和专业消费者都能参与内容创作,让他们能够设计和提供以前只有经过专业训练的人士才能实现的新颖内容消费体验。
在这些每一种媒体形式中,模型的能力每一代都不是呈线性增长,而是呈指数级增长。
以文本为例,从GPT-3到GPT-4,在模型规模(从1750亿个参数增长到1.8万亿个参数)、
上下文窗口(从2048个标记增长到12.8万个标记)以及最终的推理能力(从测试者中排名后10%提升到前10%)方面都有显著的提升。而且迭代的速度也在加快:
自从2023年3月GPT-4发布以来,OpenAI又发布了GPT-4 Turbo(2023年11月),提供了更大的上下文窗口;
GPT-4o(2024年5月)推出了首个真正的多模态大语言模型,速度是半年前Turbo版本的两倍,开发成本却只有一半;
GPT-4o Mini(2024年7月)的API成本更低;o1(2024年9月)具备先进的推理能力;o3(2024年12月)在编码、数学和科学领域设定了新的基准。
生成式视频之后会是什么呢?许多人认为世界模型将是人工智能领域的下一个主要形式。
从机器学习的角度来看,世界模型可以想象一个虚拟(或现实)世界如何随着一个主体(例如,一个玩家)的行为而演变。
基于视频生成和自动驾驶技术的进步,这些“世界模拟器”可以提供具有时间和空间一致性的三维互动体验——也被视为“4D”(三维加时间)。
为了简化理解,我们可以将世界模型看作是生成式或“无引擎”的视频游戏:即允许用户输入并实时做出连贯响应的虚拟世界。
虽然世界模型仍处于开发的最早期阶段,输出的保真度也有待提高,但它们已经大规模地展示出了各种新兴能力,
包括复杂的角色动画、物理效果、主体动作预测以及物体交互性。
世界模型通过对所有其他媒体形式(文本、音频、图像和视频)的大型数据集进行训练,最终发展出对行为后果进行推理的能力。
世界模型的影响将是深远的,不仅仅局限于虚拟世界。
Meta的首席人工智能科学家杨立昆在最近的一次演讲中描述了世界模型最终将如何理解(现实)世界,并具备“与人类同等水平的推理和规划能力”,
成为在消费者(打扫房间、洗盘子、遛宠物狗)和商业(功能完整的工业机器人)环境中执行复杂任务的基础,而这是目前的媒体形式所无法做到的。
然而我们预计世界模型在短期内的许多应用将是按需生成游戏和互动媒体应用(二维和三维风格的输出)或实时互动视频体验(二维风格的输出)。
目前仍然存在几个关键问题,一个是训练和运行世界模型所需的大量数据和计算能力,一个是如何处理模型产生的幻觉和偏差问题。
如果从之前的媒体形式的发展中可以吸取教训的话,那就是事情往往一开始有点不稳定,但几年后就会变得极具吸引力。
在我们深入探讨对未来影响和潜在应用的看法之前,让我们先简要回顾一下我们是如何走到今天这一步的。
人工智能世界模型正准备从根本上重塑游戏开发,推动在虚拟环境的创建、理解和交互方式方面的创新。
这段从基础性突破到前沿应用的历程,展示了一系列快速的进步,每一次进步都建立在其前辈的成功之上。
同样,人工智能在理解和玩游戏方面变得越来越出色,现在它们在可视化和创建复杂、交互式的三维世界方面也在迅速改进。
让我们看看世界模型的发展历史。
图片来源:Mediu
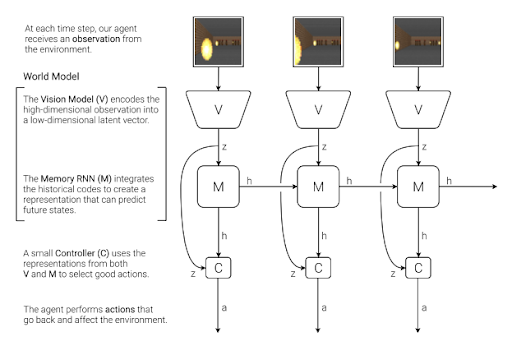
想象一下,一个人工智能通过在可视化游戏世界来学习如何导航,就像一个玩家在踏入迷宫之前先在脑海中描绘出迷宫的布局一样。
这就是大卫·河合(David Ha)和于尔根·施密德胡贝尔(Jürgen Schmidhuber)的学术论文《世界模型》的核心内容。
他们的框架结合了变分自动编码器(VAE)将视觉信息压缩为关键抽象概念,循环神经网络(RNN)来预测这些抽象概念如何随时间变化,
以及一个控制器来决定最佳行动。例如该模型通过在内部模拟圈数,在无需直接交互的情况下优化策略,从而掌握了游戏《CarRacing-v0》。
这一突破表明人工智能可以通过想象游戏世界来解决任务,就像在下棋时在脑海中预演走法一样。
通过抽象表示实现高效决策这一架构创新为未来的发展奠定了基础。
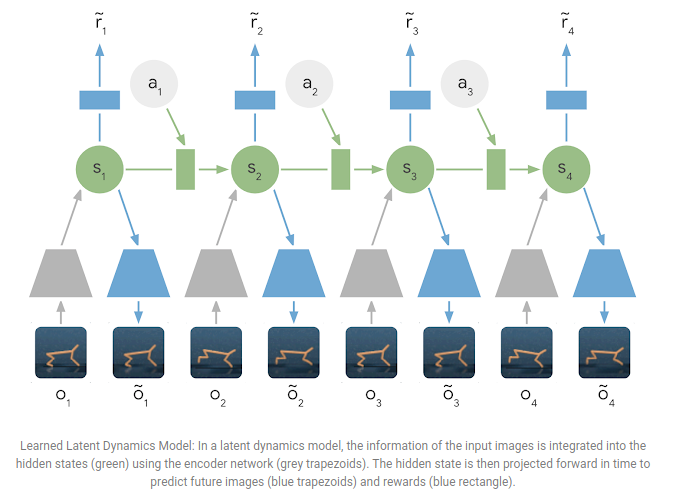
图片来源:PlaNet
虽然河合和施密德胡贝尔让人工智能能够想象游戏世界,但达尼贾尔·哈夫纳(Danijar Hafner)的深度规划网络(PlaNet)为其提供了绘制详细蓝图的工具。
PlaNet通过“潜在动力学”完善了模型的细节处理能力,这一过程类似于将整个城市地图总结为关键地标,以便高效导航。
这些对环境的简化抽象让PlaNet能够通过在这种压缩表示中模拟结果来规划行动,而不是依赖原始的、复杂的数据。
这一创新使PlaNet在需要连续控制的游戏中成为天生的策略制定者,例如机器人运动控制或在虚拟的《吃豆人》游戏中躲避幽灵。
通过关注大局,PlaNet证明了对环境的抽象草图可以带来更智能、更快的决策——这是向可通用的人工智能规划迈出的重要一步。
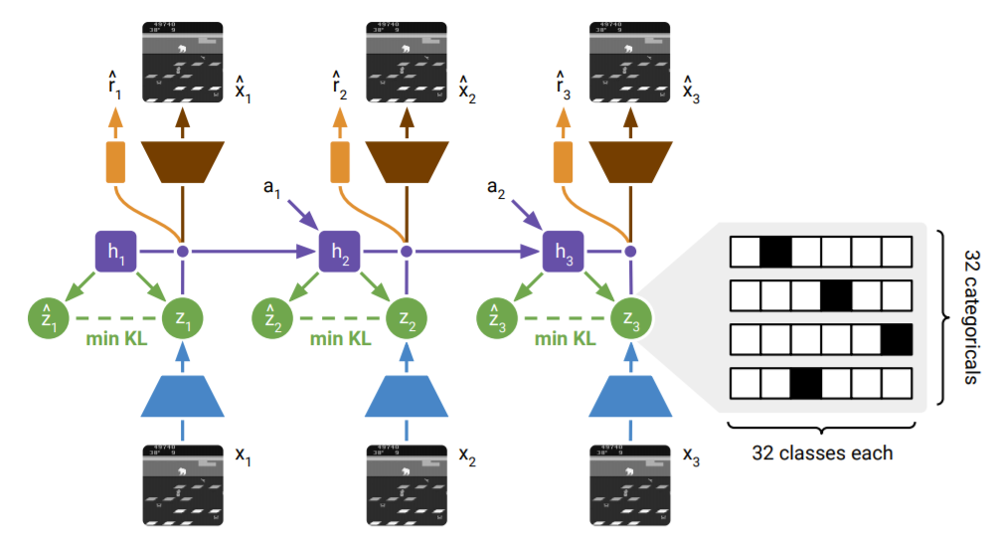
图片来源:Mulab.ai
Dreamer将想象的概念提升到了一个新的高度,因为人工智能从绘制草图发展到对可能的未来进行完整的“梦境”模拟。
Dreamer将PlaNet的潜在动力学与强化学习相结合,使其能够模拟详细的轨迹,并根据想象的场景完善策略。
就像一个玩家在策略游戏中想象自己的选择所产生的连锁反应一样,
Dreamer在其潜在空间中模拟未来场景的能力使其能够在不进行实际游戏中的试错的情况下完善策略。
例如,Dreamer在引导机械臂和在虚拟景观中导航等任务中表现出色,通过在内部生动地模拟其“梦境”动作来实现。
DreamerV2将这种能力扩展到更复杂的雅达利2600游戏中,成为评估想象预测和主体性能的基准。这有助于证明详细的模拟往往胜过暴力实验。

图片来源:Genie
2023年,人工智能视频生成领域的领导者之一Runway宣布了其通用世界模型计划,
该计划旨在使用生成对抗网络(GAN)和先进的空间建模技术来生成三维世界的模拟。
Runway在其视频生成的三维相机系统演示方面取得了一些进展,但交互性仍然受到严重限制。
在同一时期,DeepMind(隶属于Alphabet)的Genie将这项技术提升到了另一个水平。
当用户提供一张图片作为提示时,Genie会生成交互式的二维世界,具备实时物理效果和空间记忆。
从技术角度来讲,Genie使用了一种称为时空视频标记器的自回归动力学模型,以及一种可扩展的潜在动作模型,以实现逐帧交互,而无需标记动作数据进行训练。
更简单地说,想象一下描述一个“有秘密通道的鬼屋”,然后立即就能拥有一个完全可玩的关卡,而无需特殊的领域或类型知识,
尽管它是在公开可用的二维平台游戏视频上进行训练的。这是“世界模型”这个概念首次真正开始名副其实。
2024年,创新的步伐急剧加快,标志着一个转折点,人工智能世界模型开始从实验性研发阶段向游戏开发者的实用工具过渡。
生成式三维交互式世界现在正通过更多新老参与者的努力而变为现实。

图片来源:Genie 2
基于其前身,DeepMind的Genie 2引入了更精细的环境交互和扩展的多模态输入。
它还实现了向三维环境的跨越,具备更强大的物理效果和动画,包括第一人称、第三人称,甚至像驾驶和航海等基于载具的游戏。
这个版本还实现了更动态的交互,例如戳破气球、引爆木桶和爬梯子等。
DeepMind提供了许多不同的演示,但该模型尚未公开可用,并且在超过一分钟的交互时间后缺乏稳定性。
在世界模型方面的一个重大改进是它的“长时记忆”,这使得它能够记住场景的部分内容,以便在它们离开和再次进入视野时准确地重新渲染。
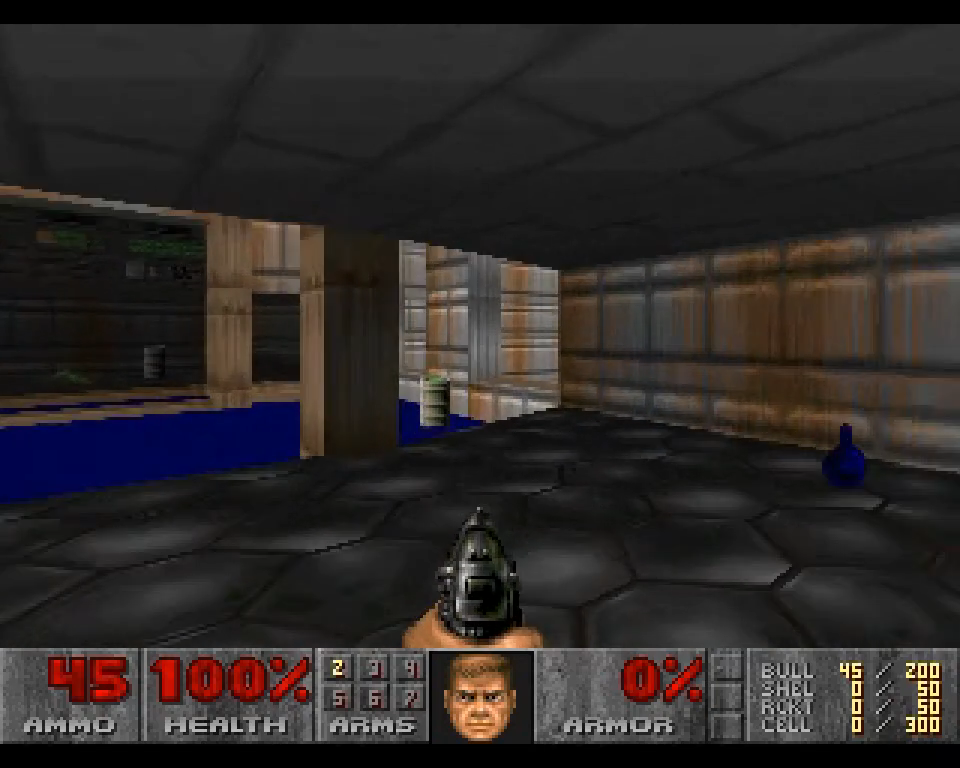
图片来源:GameNGen
另一个有趣的突破是GameNGen(来自谷歌的另一个研究团队),它使用一个神经游戏引擎,作为一个“有生命”的开发平台,能够实时调整游戏元素。
该系统通过以超过20帧每秒的速度模拟经典游戏《毁灭战士》(Doom)进行了演示,在玩家游玩过程中生成一个不断扩展的环境。
GameNgen使用了强化学习(通过一个人工智能主体在玩游戏时收集数据)和训练一个生成式扩散模型来渲染环境的组合方式。
更具体地说,该扩散模型基于Stable Diffusion 1.4构建,并经过巧妙修改,用之前的游戏画面帧(结合训练主体的动作输入)取代了常规的文本提示。
这样,生成的新画面帧与之前的游戏画面帧和玩家动作保持同步。

图片来源:GameGen AI
另一家科技巨头和全球最大的游戏公司腾讯正在开发 GameGen-O。腾讯最近通过使用扩散变压器模型瞄准开放世界游戏,暗示了大规模内容生成的未来。
其开放世界视频游戏数据集(OGameData)基于超过一百万个不同的游戏玩法视频片段构建,并带有来自GPT-4o的信息丰富的字幕。
该模型使用了一个两步过程,即预训练文本到视频模型,以及使用与游戏相关的多模态控制信号专家进行“指令网络(InstructNet)”控制模型训练。
目前的演示仅持续几秒钟,尽管在视觉上令人印象深刻,但目前还不是实时的。然而鉴于腾讯希望其工作室能够使用前沿技术,它值得关注。
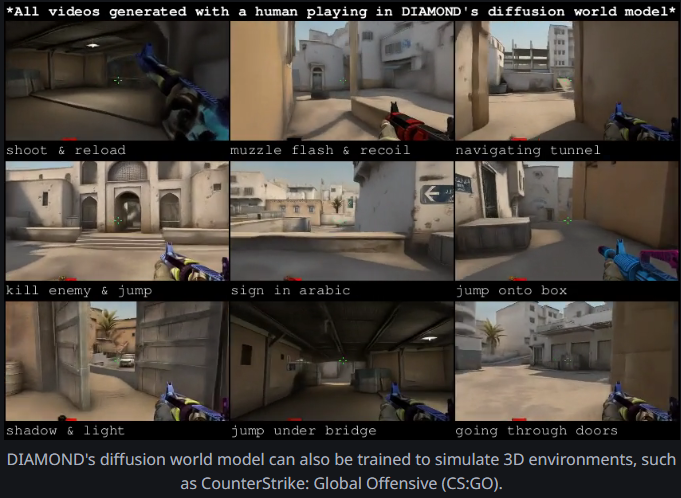
图片来源:DIAMOND的2024年迭代版本
经过几年的研发,人工智能模型从玩游戏发展到了创造游戏。
另一个学术模型DIAMOND(DIffusion As a Model Of eNvironment Dreams,扩散作为环境梦境模型)在2022年登上了舞台。
DIAMOND使用了扩散技术,这与Stable Diffusion 和 Midjourney 等流行图像生成器所使用的方法相同,
用于迭代地完善图像,就像一位艺术家为游戏世界绘制超逼真的背景一样。
这使得DIAMOND能够预测并生成高保真的视频模拟,包括一个可玩的模拟《反恐精英:全球攻势》(CS:GO)环境。
这个模型创建逼真场景的能力使其成为视觉丰富模拟领域的变革者,但不一定在交互性方面。
即便如此,世界模型有朝一日在游戏开发中可能发挥的作用变得更加清晰了。
DIAMOND在2024年的论文成为了2024年神经信息处理系统大会(NeurIPS 2024)的亮点,在训练模拟三维环境方面取得了重大进展。
再举一个例子,Decart和Etched创建了Oasis,作为一个类似《我的世界》(Minecraft)的生成式交互式世界模型的技术演示。
作为首个公开可用的演示,Oasis接收用户的键盘输入,并生成基于物理的实时游戏玩法,允许玩家移动、跳跃、拾取物品、破坏方块等等。
它的世界模型理解诸如建造、照明、物理和物品管理等游戏元素。
这个模型由一个基于变压器的空间自动编码器和潜在扩散主干两部分系统构建而成。
它是在来自VPT(OpenAI的麻省理工学院许可开源《我的世界》数据集)的开源数据上进行训练的。
就像上面提到的《毁灭战士》GameNgen演示一样,这个演示也以20帧每秒的速度运行,但它还允许实时玩家输入,并在定制芯片Sohu上运行。
Decart的联合创始人迪恩·莱特斯多夫(Dean Leitersdorf)和摩西·沙莱夫(Moshe Shalev)还提到了基于对GPU的定制底层性能优化在视频推理方面的突破——
这使得能够以经济高效的方式实时生成交互式二维和三维内容。
在它们发布后不久,Y Combinator公司Lucid展示了一个类似的《我的世界》演示。
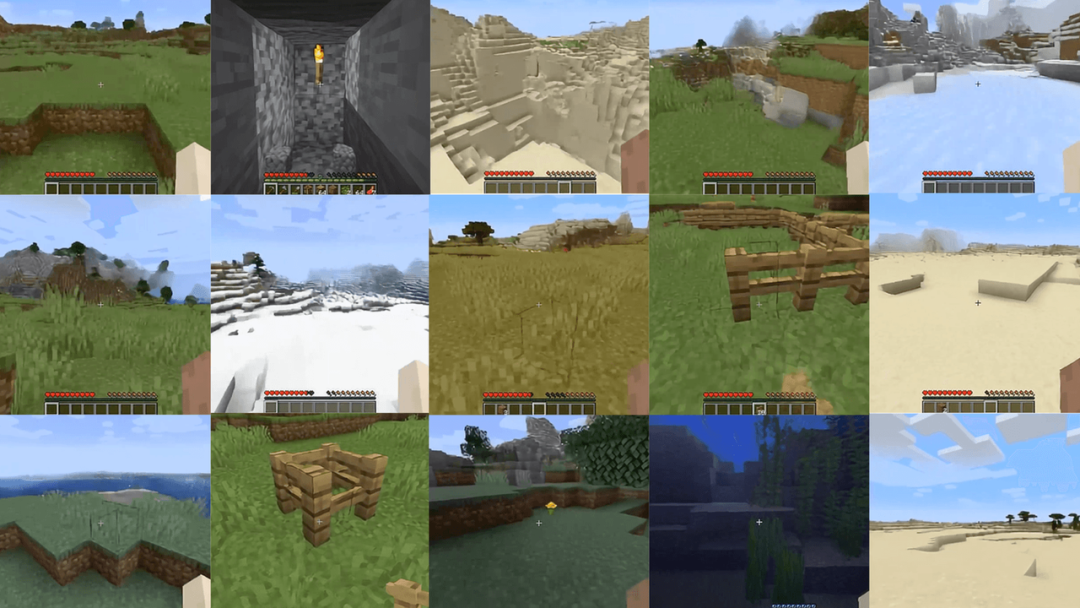
图片来源:OASIS/Etched
由著名人工智能研究员李飞飞创立的World Labs最近也推出了将二维照片转换为空间连贯的三维环境的工具。
所展示的环境在浏览器中实时渲染,可通过WASD键/鼠标控制,包括景深相机效果、带有视野(FOV)的推拉变焦以及正确的物理几何形状等功能。
与逐帧模型不同,World Labs同时生成完整的三维场景,具有稳定的持久性和实时玩家控制功能。
三维场景通过像素深度图生成,以从图像预测三维几何形状,并将其转化为保持物理一致性的世界模型。

图片来源:World Labs
最后,Odyssey的Explorer系统与Oasis类似,但由于在使用定制相机拍摄的真实世界360度全景图像上进行训练,它更适合生成逼真的场景
(而不是类似《我的世界》的外观)。使用Explorer创建的场景不包括实时游戏玩法或机制。
相反,它们是根据文本提示生成一个场景,可以加载到虚幻引擎(Unreal Engine)、Blender或After Effects中,用于游戏或媒体制作。
该团队利用他们在自动驾驶汽车领域的背景,并利用专有的三维数据收集作为其模型的竞争优势。

图片来源:Odyssey
为了不被初创公司超越,微软推出了自己的世界模型,该模型可用于生成视频游戏场景和环境,这些场景和环境会根据游戏玩家在游戏控制器上的动作而变化。
缪斯(Muse)是由微软的研究人员以及其Xbox游戏部门的员工,利用其Xbox游戏《边缘禁地》(Bleeding Edge)长达七年的游戏玩法视频片段进行训练的。
微软公司对这项技术的定位并非是取代传统游戏设计,而是对其进行增强。
这个模型旨在成为游戏开发者的一个工具,并且未来有一天它可能会被用于加快游戏开发进程,或者创建为单个玩家量身定制的游戏。
《游戏档案》(GameFile)的斯蒂芬·托蒂洛(Stephen Totilo)概括了玩家和开发者群体对该模型褒贬不一的反应。
从数据的角度来看这是有道理的。
得益于微软的Xbox生态系统以及对动视(Activision)的收购,对于微软来说,游戏视频结合玩家的操作行为(比如键盘或控制器输入),
就如同YouTube对于谷歌的Veo2一样重要。
图片来源:GameFile
最后值得一提的是:OpenAI的索拉(Sora)视频模型也能够呈现出类似游戏的体验。
在世界模型这样一个发展瞬息万变的领域,对即将出现的技术做出假设并非易事。
作为投资者,往往看清当下比预测未来更加现实——而且这是必要的,除非你偶然间能准确预测。
本着这种精神,我们走访了一些领先的世界模型初创企业和研究实验室,以了解他们的想法。以下是我们在交流中反复出现的一些设想:
1)世界模型在短期内不太可能取代大型3A视频游戏——相反,它们将带来新颖的、“以前不可能实现的体验”。
以能够推动真正创新的方式应用人工智能,这一点的重要性也是我们在2023年年中发布的上一篇关于人工智能与游戏结合的文章中的核心论点。
随着技术每季度都在取得重大进展,我们相信,对于成功方法的预测将回归到在过去类似互联网或移动技术这样的范式转变中,
那些曾造就伟大突破性公司的基本原则上。人工智能带来的效率提升和成本降低很有趣,也很重要。但真正的突破不会仅仅是对现有产品的改造或使其合理化;
它们将是为了全新的、以前不可能实现的体验而从根本上、原生地构建出来的。
对于世界模型来说,这样的体验可能包括:“玩”一本书或一张照片(例如,真正沉浸在你最喜欢的文本或一段家庭记忆中);
实时执导一部电影(即在电影播放时对其进行修改,就像《黑镜:潘达斯奈基》的实时版本一样);
用无限的滤镜或风格转换来增强自拍视频或视频会议(就像Snap的滤镜一样,只不过不局限于“手工制作”的选项)。
这些新的体验将由非凡的创始人来打造,他们凭借直觉获得独特的见解和想法。
2)状态性和内存限制将需要渐进式创新,以创造出长期吸引人且能留住用户的虚拟世界。
目前大多数世界模型能够生成高度详细的环境,但缺乏持久的状态建模,而这是传统视频游戏的一个基本要素。
与那些能够随着时间推移跟踪玩家进度、物品清单和世界变化的“手工制作”游戏引擎不同,如今的世界模型是独立生成新的画面帧或场景的,没有底层的内存结构。
这种限制使得它们无法支持诸如渐进式关卡变化、长期的因果关系或非线性叙事等复杂机制。
如果在有状态架构方面没有突破,世界模型将仍然更适合用于动态模拟,而非真正的交互式游戏世界。
3)就游戏而言,世界模型可能会被通过人工智能自动化实现的“传统”基于算法和引擎的体验超越。
这一点理解起来有点棘手,但尤其是随着人工智能在自动化代码生成和生成三维资产方面越来越出色,
对现有的游戏设计过程(使用虚幻引擎(Unreal Engine)或Unity等游戏引擎)进行自动化——
包括实时生成相关的三维资产和纹理——可能会被证明优于基于概率的实时视频生成模型。
如今甚至已经进行了一些混合实验:世界模型是二维呈现,根据用户输入预测下一视频帧。
人工智能自动化传统设计则是三维呈现,使用代码和资产来提供有状态的体验。
混合方法则通过使用“灰盒”三维呈现进行有状态建模以及保证空间和时间的完整性,并在其基础上应用视频模型。
4)“多人世界模型”即将问世。多人世界模型面临着重大挑战,但通过正确的架构方法仍然是可行的。
其核心困难在于,在利用本质上具有概率性和动态性的生成模型的同时,要在多个玩家之间保持一致、同步的世界状态。
与基于确定性状态更新运行的传统多人游戏不同,世界模型引入了可变性,这可能导致不同步和不一致的情况。
然而,诸如服务器端权威模型、将生成式人工智能与确定性物理相结合的混合方法以及高效的数据流式传输等技术,可以缓解这些问题。
我们尚未在实际中看到多人世界模型,但听说它们已经不远了。
5)法律和版权方面的考量是一件非常复杂的事情。随着世界模型越来越复杂,它们引发了复杂的法律和伦理问题。
程序生成的资产的权利归谁所有?如果一个基于现有视频游戏进行训练的模型输出了与已知知识产权高度相似的内容,这是否构成版权侵权?
例如,DeepMind的Genie可以根据视频输入生成交互式游戏关卡,这引发了人们对衍生作品的担忧。
同样,GameGen-O和GameNgen通过文本提示合成可玩的体验,可能会在不知不觉中生成与现有游戏系列相似的资产。
游戏工作室、发行商和监管机构将需要在一个快速演变的法律环境中摸索前行,在这个环境中,传统的知识产权框架可能不再适用。
对于所摄入的视频游戏流的法律层面问题更加复杂且层次繁多:想象一下一个关于《国际足联》(现称《EA Sports FC》)的Twitch视频:
有《国际足联》这款游戏——以及它的球员和球队的知识产权。但还有主播以及(可以说是具有艺术性或竞技性的)游戏和娱乐观众的行为。
还有观众的输入和聊天内容本身。以及为用户提供这种体验的流媒体平台。
6)要训练出令人信服的世界模型,将需要三维数据集以保证空间和时间的一致性。
如今大多数生成式人工智能模型主要是在二维数据集上进行训练的,这限制了它们在完全实现的三维环境中保持空间和时间一致性的能力。
游戏和模拟需要深入理解物体恒存性、遮挡、物理交互以及长期的状态变化——这些都是在二维数据集上训练的模型所难以应对的挑战。
例如,DeepMind的Genie可以生成交互式游戏场景,但如果没有原生的三维训练数据集,它在渲染深度、物体交互或持久的物理状态时就会面临不一致的问题。
为了实现真正的空间和时间连贯性,未来的世界模型可能需要大规模的三维数据集,这些数据集可能来自现实世界扫描、合成环境或高保真的游戏引擎。
7)没有可玩性的模拟无法长期吸引或留住用户。虽然世界模型在模拟环境方面表现出色,但将它们转化为引人入胜、结构合理的游戏体验仍然是一个重大挑战。
能够生成无限的景观或动态的非玩家角色(NPC),本身并不能带来有趣、平衡或有意义的玩家体验。
一款引人入胜的游戏需要精心设计的关卡、游戏进程系统以及玩家的自主性——这些都是单纯的程序生成难以保证的要素。
例如,Odyssey可以生成广阔的可探索世界,但要确保其中有连贯的任务结构或有意义的挑战,仍然需要人为干预。
未来的发展可能会涉及混合方法,即由人工智能生成的世界在精心策划的设计原则的指导下进行构建。
8)可扩展性和计算效率将继续提高,这可能不会对世界模型构成长期阻碍。
训练和运行大规模世界模型的成本仍然是其广泛应用的一个主要障碍,但人工智能效率的提高正开始改变这一局面。
在过去五年中,生成模型在成本效益方面有了显著提升,其架构针对更低的功耗和推理效率进行了优化。
例如,Decart的Oasis开创了新的GPU高效技术,降低了实时生成虚拟世界所需的计算资源。
与此同时,量化和模型蒸馏方面的进展使得在消费级硬件上运行复杂的模拟成为可能。
随着这些趋势的持续,世界模型不仅可能对大型工作室可行,对独立开发者甚至实时应用程序也可能变得可行。
9)世界模型在近期最有价值的应用场景可能在游戏领域之外,例如在机器人技术中。世界模型的直接应用场景远远超出了传统的游戏环境。
例如,在机器人技术中,它们可以为实时交互式视频模型提供动力,使这些模型能够动态地理解和应对复杂的环境——为更直观、自适应的机器人系统铺平道路。
原文:Hello, World Models!
https://lsvp.com/stories/hello-world-models/
编译:Nicole Zhu
文章来自于微信公众号“Z Potentials”,作者 :Lightspeed




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
