# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在日常生活中,你是否遇到过这样的情况:在嘈杂的环境中,语音助手听不清你的指令?或者在视频通话时,对方的发音不够清晰,让你难以理解?
自动语音识别(ASR)技术正在不断进步,但在真实世界的视频场景中,ASR仍然面临许多挑战,如噪声干扰、口语化表达、以及同音词混淆等问题。
那么,人们能否利用视觉信息来增强语音识别的准确性呢?

最近,来自中国人民大学及卡耐基梅隆大学的学者们在AAAI 2025会议上正式发布了他们最新的研究——
BPO-AVASR(Bifocal Preference Optimization for Audiovisual Speech Recognition)。
这是一种全新的双焦点偏好优化方法,能够有效提升多模态语音识别(AV-ASR)系统的性能,使其在真实世界视频场景下的表现更加强大!

论文链接:https://arxiv.org/pdf/2412.19005
代码地址:https://github.com/espnet/espnet
传统的ASR系统仅依赖音频输入进行语音识别,但在现实场景中,单靠音频往往不足以精准识别用户的语音。例如:
视觉信息,尤其是视频中物体、背景信息、文本等,能提供额外的线索来帮助ASR模型更精准地理解语音内容。
例如,看到屏幕上出现了一瓶「可口可乐」,ASR 识别「cola」而非「caller」的可能性会更高。
因此,AV-ASR(音视频语音识别)应运而生,结合视觉与语音信息,提升识别准确性。
双焦点偏好优化(BPO)
虽然多模态ASR近年来取得了显著进展,但目前的方法仍然存在一些关键问题:
为了解决这些问题,研究者们提出了一种全新的双焦点偏好优化(Bifocal Preference Optimization, BPO)方法,以BPO-AVASR模型为核心。
这篇工作的创新点包括:
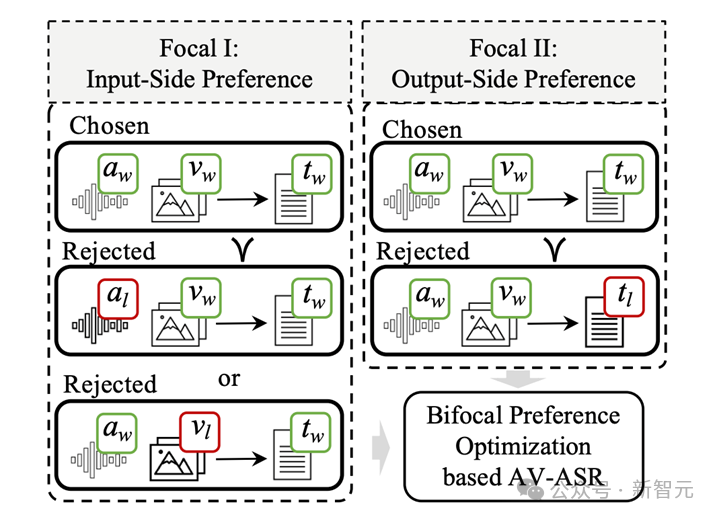
输入端偏好优化(Focal I):通过遮挡音频或扰动视频信息,模拟现实世界中的干扰因素,使模型学会如何在音视频信息缺失时做出更准确的预测。
输出端偏好优化(Focal II):通过引入AI生成的错误文本(如同音词替换、语音模糊重写等),让模型学习如何避免这些常见的识别错误。
换句话说,不仅要让模型学会「看」和「听」,更让它学会如何在信息不完整或错误的情况下做出更好的决策,
从而更好地在多模态的场景下同时利用视觉和听觉信息识别出准确的文本。
如何构造偏好数据?
BPO-AVASR架构概览
BPO-AVASR通过构造偏好数据来优化ASR,主要涉及输入端优化和输出端优化。
目标:让模型学会如何处理不完整的音视频信息,提升对噪声、模糊信息的适应能力。
目标:让模型学习如何避免常见的识别错误,优化ASR预测文本的准确性。
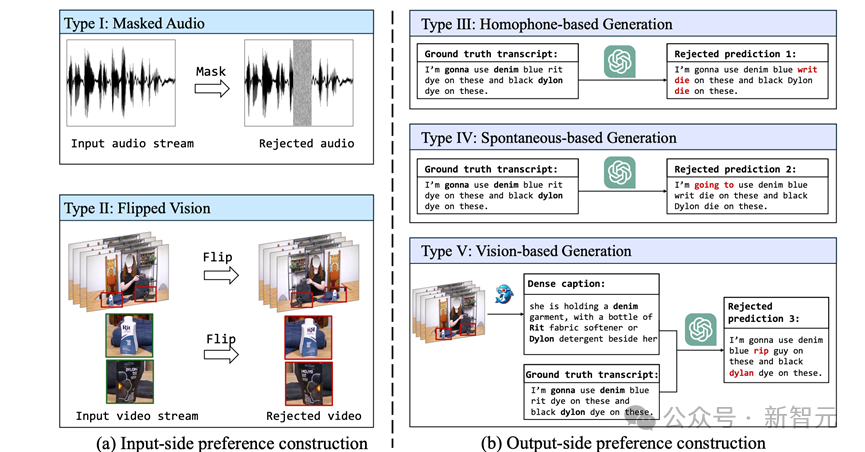
偏好数据构造方法
实验结果与结论:BPO-AVASR让ASR更强大!
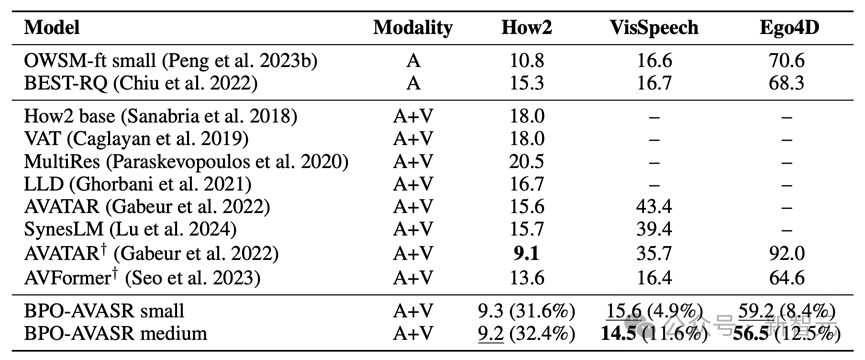
为了验证BPO-AVASR的效果,研究者们在多个基准数据集上进行了测试,包括:How2,VisSpeech和Ego4D,在不同领域的多模态数据上验证了方法的有效性。
实验结果表明,BPO-AVASR在大部分测试数据集上取得了SOTA(State-of-the-Art,最优)性能,尤其在嘈杂环境和复杂视频场景下表现出色。例如:

未来展望:让 AI 更懂「看」与「听」
BPO-AVASR的成功,不仅让ASR模型在复杂环境下更加稳定,同时也为未来的多模态学习提供了新的思路。未来,研究者们希望:
参考资料:
https://arxiv.org/pdf/2412.19005
文章来自于微信公众号“新智元”,作者 :LRST



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
