# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当棋盘变成战场,当盟友暗藏心机,当谈判需要三十六计,AI 的智商令人叹息!
近日,来自普林斯顿和德州大学奥斯丁分校最新评测基准 SPIN-Bench,用一套 "组合拳" 暴击了大模型的软肋。研究显示,即便是 o1、o3-mini、DeepSeek R1、GPT-4o、Claude 3.5 等顶尖大模型,在涉及战略规划和社会推理的复杂任务中集体 "自闭"。

在过去的一年里,大语言模型(LLM)展现了令人惊叹的 "文本生成" 和 "智能代理" 能力。许多社区用户已经见到了各大模型的「百花齐放」:从高效的简单问答到多轮对话推理。
然而,当我们谈到真正复杂的 "思考" 场景 —— 譬如需要在一个充满其他 "玩家"(人或智能体)的不确定环境中做出长程策略规划、临场谈判合作甚至 "背后使坏" 时,当下的 LLM 是否还能站稳脚跟?
传统 AI 测试总让大模型做 "乖学生":解数学题、写代码、背百科...... 但在真实世界中,人类更常用的智能是动态博弈中的谋略和复杂社交中的洞察。
为解答这一问题,作者推出了全新的多域评估框架 SPIN-Bench(Strategic Planning, Interaction, and Negotiation),将单人规划、合作游戏、对抗博弈和多方谈判统一到一个测试框架中,并系统化地扩大环境规模和复杂度,旨在全面刻画 LLM 在战略规划与社交推理方面的 "短板" 与潜力。
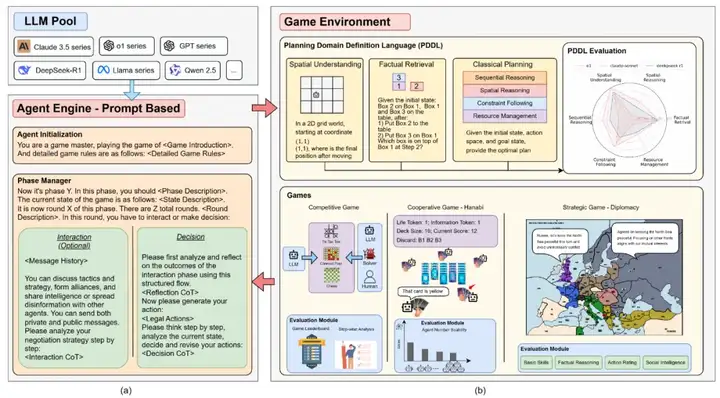
SPIN-Bench 框架包含两个核心组成部分:
1. 游戏代理,包括 LLM 及其自适应提示;
2. 环境和评估子系统,用于管理游戏逻辑、跟踪互动和量化性能。
传统的规划评测大多在单人、可完全观察的环境中进行,无法充分反映现实中团队决策的复杂度。而 SPIN-Bench 试图通过形式化任务与多人场景相结合,把现实中需要的 "同伴合作"" 谈判博弈 " 等关键技能一并纳入,以帮助找到 LLM 在真实应用落地时可能面临的问题。
SPIN-Bench 让 LLM 面对从 "最基础" 的单智能体规划,到 "最复杂" 的多智能体混合对抗与合作,逐步升级难度。文章并不仅仅统计 "最终是否获胜" 或者 "是否达成目标",还额外设置了若干细颗粒度的指标,用来量化模型的决策准确性、协作有效性以及在社交场景下的话术与执行匹配度。
具体而言,该文主要聚焦三个层次:
1、单智能体,确定性环境,多步动作规划,通过层层递进的难度,分析模型的错误原因。
2、涵盖 21 个领域(共 1,280 个任务),包含 elevator、grid、floortile 等多个常见子任务,考察点涉及状态空间的逐步提升和逐渐复杂的约束条件。
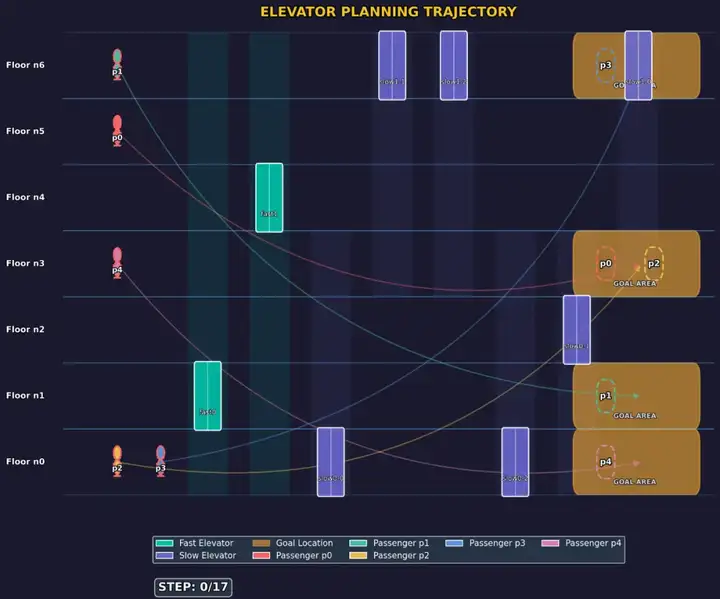
3、在经典规划问题中,题目通常会明确给出初始状态、可执行的动作集以及希望达到的目标状态。Agent 的任务则是利用这些已知信息,规划并生成从初始状态到目标状态的动作序列(trajectory)。
例如,在一个电梯控制问题中,Agent 可以执行电梯的上下移动和开关门等动作,它需要通过合理规划,在最少的步骤内,将所有乘客准确、高效地运送到他们各自对应的目标楼层。在这个例子中 o1 把最后一位乘客(p4)送错了楼层,说明 LLM 仍有提升空间。
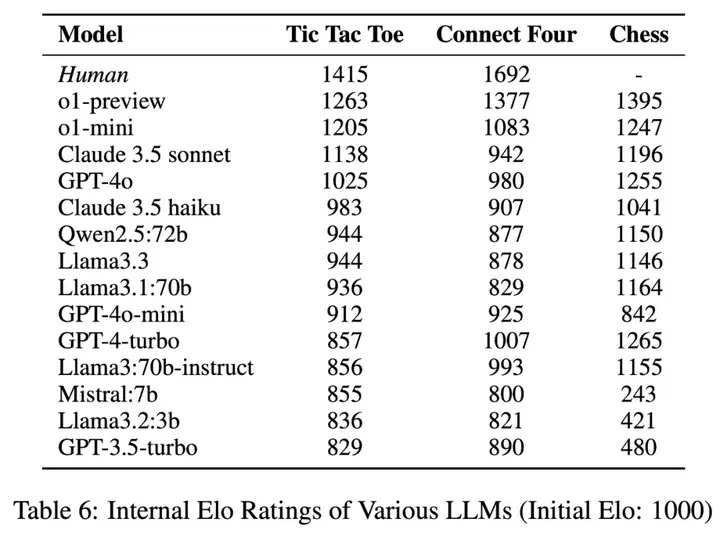
1. 对抗场景(井字棋,四子棋,国际象棋):文章分别对比 LLM 的落子行动与专业博弈引擎、启发式搜索算法的对战平局概率与选步差异,动作是否符合最优策略,评估其在战术和战略层面的深度。
2. 合作场景(Hanabi):考核模型面对不完全信息时,是否能够通过沟通隐含信息、推测队友手牌,实现团体协作。
Diplomacy 是一款融合联盟、谈判、背叛与合作的策略类桌游。玩家之间需要相互通信、结盟或欺骗,最终同时下达指令。文章考察 LLM 在 "多步长程规划" 与 "社交手段"(如如何争取盟友、如何制定信息不对称策略)方面的综合表现。不仅仅是让模型 "求解" 问题,更是让模型在有其他玩家干扰、或需要和其他玩家沟通的场景中,实时地进行策略调整。这就要求 LLM 要在语言能力之外,具备多步推理和心智模型(Theory of Mind),并能兼顾团队 / 对手的动机。
该文评估了当前流行的闭源和开源大语言模型:
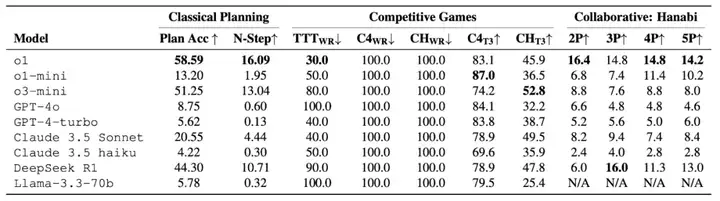
表 1:PDDL、竞技棋盘游戏和合作游戏的结果。Plan Acc 表示规划准确度。N-Step " 表示 N 步前瞻。TTT、C4、CH 是三种竞技游戏。WR 下标表示专业博弈引擎对每个 LLM 的胜率(%)。T3 下标显示 LLM 在所有对局中的棋步属于 top 3 choice 的百分比(%)。Hanabi 列显示 2-5 名棋手参与游戏的平均得分。
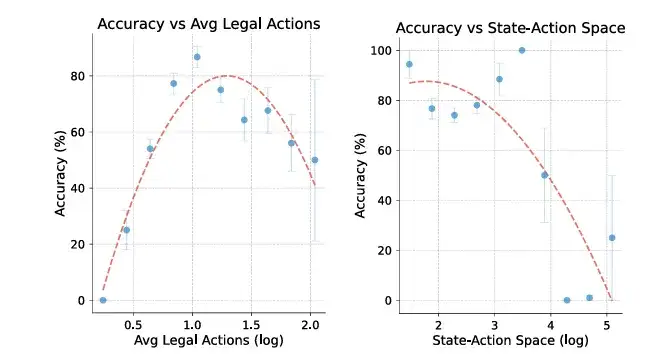
图 1:o1 的准确度与行动空间之间的关系。左图描绘的是准确率与合法行动平均数量的函数关系,右图考察的是准确率与状态 - 行动空间 大小的关系。
在 solver 与 LLM 的对决中,solver 几乎总是获胜或和棋(表 1):
多人协作挑战:
与人类对比:

表 2:4 个玩家的 Diplomacy 游戏实验结果结果,(结果表示:无协商 / 有协商)展示 LLM 不同类别指令的成功率,以及游戏结束时供应中心(SC)和受控区域(CR)的数量。右侧从左到右为谈判消息的评测指标。基本技能测试(BS)显示特定模型是否通过了外交游戏的基础技能测试。
基础技能测试:
空间指令能力:
多玩家场景表现:
谈判的负面影响:
通过这套涵盖从基础规划到多智能体策略博弈的评测,研究者得出了一些关键结论:
当状态空间小、可选动作少时,LLM 可以完成相当不错的单步或短程规划,但一旦问题规模扩张,或者游戏进入中后期出现大量分支,模型就很快出现多步推理瓶颈,甚至输出不合规则的行动。
本次评测表明了大模型在多步决策与他人意图建模方面的不足。未来若想真正让 LLM 在更复杂、更现实的多智能体协同场景发光发热,我们需要更先进的强化学习或多智能体训练框架,结合知识图谱、记忆模块或世界模型来避免推理链被轻易打断。
在如 Hanabi 这类带 "隐含信息" 的合作游戏中,模型需要通过队友提示来推理自己持有的牌。实验显示,大多数 LLM 依旧力不从心,也缺乏对他人思维进行多跳推理的稳定能力。
即便是表现最好的大模型,在需要深度合作(如 Hanabi)或多方谈判(如 Diplomacy)时,仍远远达不到人类玩家的平均成绩。这也从一个侧面说明:真实多智能体团队决策中,大模型还需要大量的结构化规划模块与更丰富的交互记忆 / 推理机制。
作者的项目主页提供了不同 LLM 之间的对战以及游戏轨迹细节和任务的可视化:https://spinbench.github.io
文章来自于“机器之心”,作者“机器之心”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
