# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何让你的模型能感知到视频的粒度,随着你的心思想编辑哪就编辑哪呢?
Sora掀起了一股视频生成的热潮,视频编辑作为视频生成的一个热门方向一直饱受关注。但是以往的视频编辑方法主要关注视频的风格转换,或者只编辑单一的目标。
如果用户想要同时编辑视频的多个区域,大到多个目标,小到头发丝或者身体的一部分,应该怎么办呢?
来自悉尼科技大学的ReLER lab实验室的同学和浙江大学的学者合作提出了一种多粒度视频编辑的任务,包括类别级、实例级和局部级的视频编辑。
通过深入研究扩散模型内部的表征空间,提出了VideoGrain的解决框架,无需任何训练,即可实现文本到多个区域的控制,实例级别的特征分离,在真实世界的视频上取得了最优性能。

论文已被ICLR 2025接收,是当天的HuggingFace daily paper top1。目前所有的数据集,模型,代码都已开源。

本文第一作者杨向鹏是悉尼科技大学的在读博士生,主要研究方向为扩散模型、视频生成与编辑,师从浙江大学计算机学院杨易教授和朱霖潮副教授。
首先来看看多粒度视频编辑是什么,到底有什么挑战。

根据真实世界的视频粒度,受语义分割任务的启迪,他们可以将视频的编辑分为三个的层次(粒度逐渐加深):
尽管现有的方法采用了各种视觉一致性的表征,比如检测框(groundvdieo)或者特征响应(TokenFlow)等等,但这些信号没有空间的感知能力,基于T2V模型的视频编辑,比如CVPR24的DMT,再至目前工业界的SOTA-Pika,仍然无法实现多粒度的视频编辑结果。

作者通过对扩散模型的特征进行深入研究,说明了多粒度视频编辑的两大挑战。
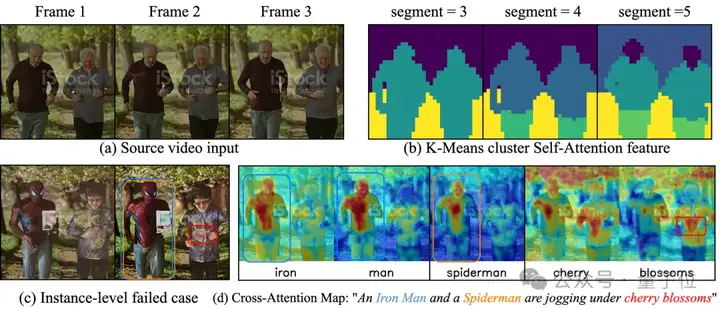
基于之前的观察,交叉注意力的分布和编辑的结果密切相关,而自注意力对于生成时间一致性的视频又十分重要。然而,一个区域内的像素有可能关注到外部或者相似的区域,这对于多粒度的视频编辑造成了很大的挑战。因此,需要去同时修改交叉和自注意力来让每个像素或者文本embedding只关注到正确的区域。
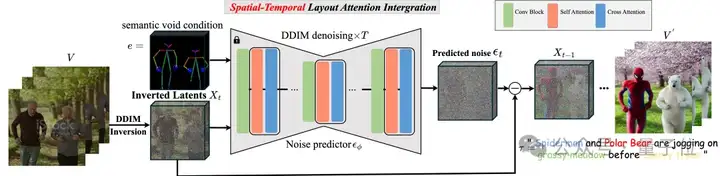
为了实现上述目标,团队提出**ST-Layout Attention (时空布局注意力机制),以一种unified的方式(即增强positive,减弱negative)来调节自注意力和交叉注意力。
具体来说,对于第i帧,他们修改Query-key对的condiation map:
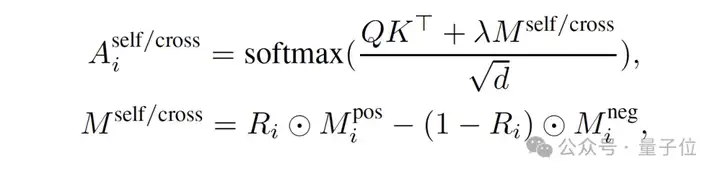
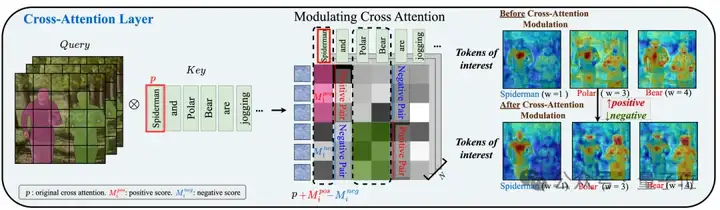
在交叉注意力层中,文本特征作为key和value,与来自video latents的query特征进行交互。由于编辑目标的外观和位置与交叉注意力的权重分布密切相关,团队目标是将每个实例的文本特征聚集到想要去编辑的位置。
如上图右侧所示,在增加positive value和减去negative value后,“Spiderman”的原始交叉注意力权重(例如 p)被放大并集中在左边的人身上。而“polar bear”的权重则集中在右边的人身上。这表明他们调节将每个局部文本提示的权重重新分配到目标区域上,实现了精确的文本到多个区域的控制。
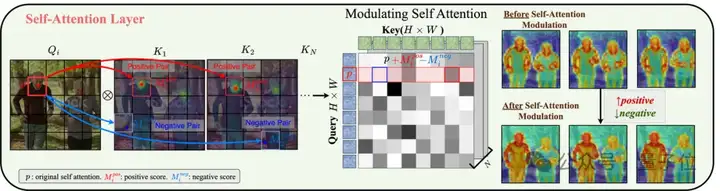
为了使T2I模型SD适应T2V编辑,作者将整个视频视为“一个更大的图像”,用时空自注意力替换空间注意力。这增强了跨帧交互,并提供了更广泛的视觉上下文。
然而,简单的自注意力可能导致,模型关注不相关或相似的区域(例如,上图底部,调节前左边人的鼻子p同时关注到左右两个人的鼻子),这会导致纹理混合。
为了解决这个问题,需要加强同一区域内的正向关注,并限制不同区域之间的负向交互。
如上图右侧所示,在应用自注意力调节后,来自左侧人物鼻子的query特征(例如p)仅关注左侧的人,避免了对右侧的人关注。这表明,自注意力调节打破了扩散模型原有的类别级特征响应,确保了实例级甚至以上的特征分离。
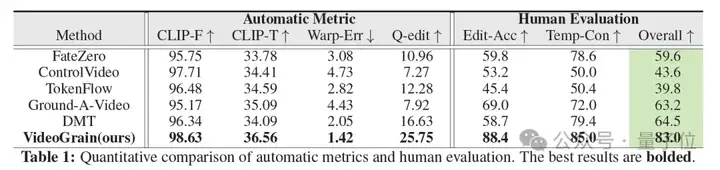
作者在涵盖类别级、实例级和部分级编辑的视频上评估了VideoGrain。

首先VideoGrain可以保持背景不变,单独的修左边的人和右边的人,或者同时修改两个人。

实例级别:VideoGrain对动物实例也同样有效,两个猴子可以被分别修改为泰迪熊和金毛犬。
在复杂的非刚性运动场景中,例如打羽毛球。以前的方法往往在处理这种非刚性运动时表现不佳,VideoGrain可以成功编辑。此外,该方法还可以多区域编辑,既可以编辑前景也可以编辑背景,在手推车场景中,背景变为“森林中的湖上,长满苔藓的石桥”。
部件级别:VideoGrain可以做到在将当前人的身份修改为超人的同时,给超人加上墨镜,这属于新增加新的object。同时,也可以修改物体的原有部分属性,比如小猫的头改成橘色。

总体而言,对于多粒度编辑,VideoGrain表现出色。
下图是VideoGrain与SOTA之间的比较,包括T2I和T2V方法的实例级和部分级编辑。

(1)部分级编辑:VideoGrain可以同时编辑太阳镜和拳击手套。ControlVideo编辑了手套,但在太阳镜和运动一致性方面表现不佳。TokenFlow和DMT只编辑了太阳镜,但未能修改手套或背景。

(2)人类实例:所有基于T2I的方法都将两个人都编辑成钢铁侠。VideoGrain则可以分别编辑,将左侧人物变成钢铁侠,右侧人物转变为猴子,打破了人类类别的限制。

(3)动物实例:即使是具有视频生成先验的DMT,也仍然将熊猫和贵宾犬的特征混合在一起。相比之下,VideoGrain成功地将一个编辑成熊猫,另一个编辑成贵宾犬。
ST-Layout Attn的时间一致性:作为视频的编辑方法,时空一致性一直是及其重要的一点,VideoGrain可以在准确的编辑多个区域的情况下,充分的保证时间一致性,防止编辑目标的纹理的抖动或者不稳定。

和最近twitter上很火的concept attention不同,该方法可以在localize concept(定位概念)的同时实现编辑:

目前,VideoGrain的数据和所有代码都已开源。
研究团队表示,VideoGrain为扩散模型提供了新的视频编辑范式,或将推动视频生成,扩散模型等领域以及视频编辑软件出现更多,好玩有趣的应用。
目前,该团队还在进一步的拓展视频生成方向,比如音视频的生成,视频的切换视角生成,以及电影级的多人物有声长视频生成,欢迎工业界有资源的小伙伴合作与加入,共同探索视频生成的未来。
论文链接: https://arxiv.org/abs/2502.17258
项目主页: https://knightyxp.github.io/VideoGrain_project_page
Github: https://github.com/knightyxp/VideoGrain
文章来自于“量子位”,作者“ReLER Lab团队”。



