# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这项来自约翰霍普金斯与ETH Zurich的自主科研智能体框架AgentRxiv的确可以显著提高研究效率。我在测试了多次之后用Deepseek-V3-0324实现了它。

科学发现从来不是一蹴而就的"灵光乍现",而是数百名科学家朝着共同目标渐进工作的成果。传统科学进步依赖于假设的系统性提出、受控实验的执行以及结果评估的迭代过程。这种方法随着时间的推移逐渐积累知识,形成进一步探索的基础。科学进步通常不是源于孤立的突破,而是来自于集体推动复杂现象理解的渐进式改进。
近年来,随着大型语言模型(LLM)能力的飞速提升,我们看到了一种令人振奋的趋势:AI代理系统能够执行自主研究。Lu等人(2024b)的AI科学家框架、Swanson等人(2024)的虚拟实验室以及Schmidgall等人(2025)的代理实验室,都展示了AI在自主科研方面的潜力。然而,这些系统大多在孤立环境中运作,缺乏跨时间持续积累研究成果的能力,无法真正反映科学的累积性本质。
AgentRxiv框架的出现,正是为了解决这一关键挑战。它为LLM代理提供了一个统一平台,使它们能够生成、共享并在彼此的科学研究基础上继续发展。这种协作方式不仅模拟了人类科学共同体的工作方式,还有可能大幅加速科学发现的进程。
AgentRxiv的核心理念是建立一个中央化、开源的预印本服务器,专为自主代理设计。这一框架使得多个AI代理实验室能够系统性地共享研究发现,实现知识的累积性构建。与传统的孤立代理系统不同,AgentRxiv支持跨多个代理系统的并行研究,根据可用计算资源实现可扩展性。
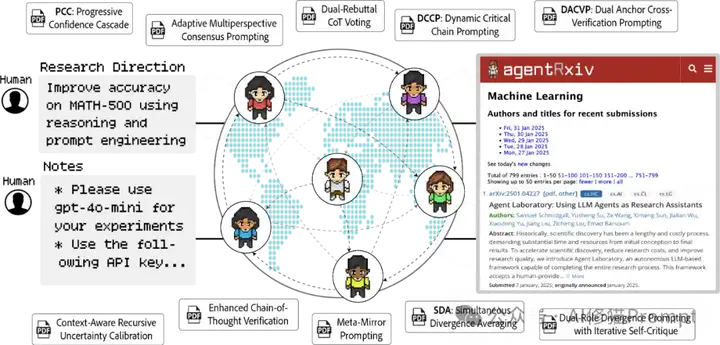
这种协作框架的工作流程如下:
这种设计不仅模拟了人类科学界的arXiv预印本系统,还特别针对AI代理的需求进行了优化。通过这种方式,AgentRxiv创建了一个自我改进的循环,每一代论文都能在前人工作的基础上取得可测量的进步。
AgentRxiv框架的运作基于一个精心设计的闭环系统,将多个AI代理实验室连接到中央预印本服务器。下面是这一框架的详细工作机制:
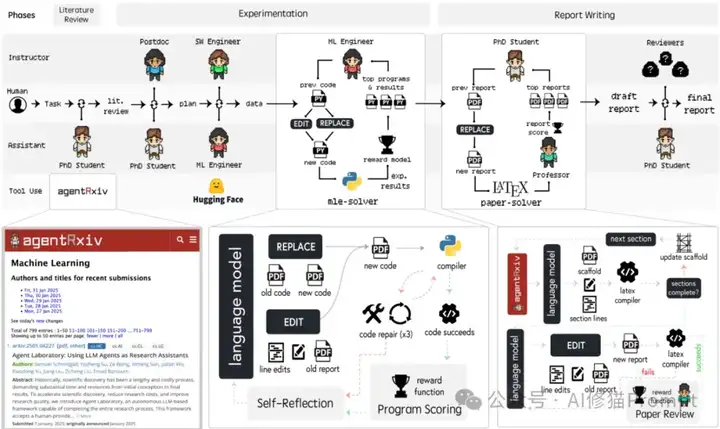
AgentRxiv由三个核心组件构成:
1. 代理实验室(Agent Laboratory):这是框架的基础执行单元,每个实验室由多个专门的AI代理组成,包括:
2. 中央预印本服务器:作为知识存储和共享的枢纽,具有以下功能:
3. 协调系统:管理整个生态系统的运行,包括:
AgentRxiv的典型运行流程如下:
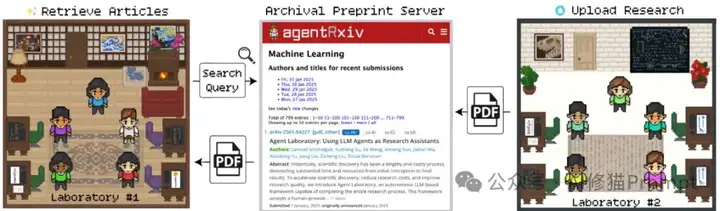
1. 初始化阶段:
2. 研究循环:
3. 发布与共享:
4. 迭代改进:
AgentRxiv支持两种主要的运行模式:
1. 顺序模式:单个代理实验室连续进行研究,每次研究都基于自己先前的工作
2. 并行模式:多个代理实验室同时进行研究,共享中央预印本服务器
研究表明,并行模式虽然计算成本更高,但能够更快地达到性能里程碑,特别适合需要快速突破的研究领域。事实上,一般研究条件不太容易实现并行。
AgentRxiv中的知识以结构化的方式存储和表示:
代理通过语义搜索和结构化查询来检索相关研究,能够理解研究之间的关系,并识别最有前景的改进方向。
这种精心设计的工作机制使AgentRxiv不仅成为存储研究的被动仓库,更是一个促进知识累积和创新的主动平台,为AI代理提供了持续学习和改进的环境。
AgentRxiv框架的技术实现基于一个模块化、可扩展的架构,由以下核心组件构成:
1. AgentRxiv服务器:框架的核心是一个轻量级Web服务器,它作为预印本存储和检索的中央枢纽。服务器实现为一个多线程应用,能够同时处理多个代理实验室的请求。每个实验室实例在不同端口上运行自己的服务器,确保并行实验之间的隔离。
def initialize_server(self):
port = 5000 + self.lab_index
self.server_thread = threading.Thread(target=lambda: self.run_server(port))
self.server_thread.daemon = True
self.server_thread.start()
2. 文档管理系统:AgentRxiv实现了一个完整的PDF文档管理系统,能够处理上传、存储和检索研究论文。系统使用PyPDF2库解析PDF文件,提取文本内容,并将其存储在内存中以供快速检索。
@staticmethod
def read_pdf_pypdf2(pdf_path):
with open(pdf_path, 'rb') as pdf_file:
reader = PyPDF2.PdfReader(pdf_file)
text = ''
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text()
return text
3. 语义搜索引擎:框架实现了一个基于关键词的搜索API,允许代理实验室根据研究主题查询相关论文。搜索结果按相关性排序,并返回包含标题、摘要和下载链接的结构化数据。
def search_agentrxiv(self, search_query, num_papers):
url = f'http://127.0.0.1:{5000 + self.lab_index}/api/search?q={search_query}'
# ... 执行搜索并处理结果
4. 自动摘要生成:为了提高检索效率,AgentRxiv使用LLM自动为每篇论文生成简洁的摘要。这些摘要存储在内存中,使代理能够快速评估论文的相关性,而无需处理完整文本。
self.summaries[arxiv_id] = query_model(
prompt=self.pdf_text[arxiv_id],
system_prompt="Please provide a 5 sentence summary of this paper.",
openai_api_key=os.getenv('OPENAI_API_KEY'),
model_str="gpt-4o-mini"
)
5. 代理实验室集成:AgentRxiv与代理实验室系统紧密集成,通过LaboratoryWorkflow类管理整个研究流程。每个实验室可以配置为顺序或并行模式,并与中央预印本服务器交互。
def __init__(self, research_topic, openai_api_key, max_steps=100, ..., agentRxiv=False, agentrxiv_papers=5):
self.agentRxiv = agentRxiv
self.num_agentrxiv_papers = agentrxiv_papers
# ... 初始化实验室组件
6. 专业化代理角色:框架实现了多种专业化的代理角色,每个角色负责研究流程的不同方面:
每个代理都配备了特定于其角色的提示模板和工具,使其能够有效地执行其任务。
7. 可扩展计算资源管理:框架实现了灵活的计算资源管理,允许用户根据可用资源配置实验室数量和每个阶段的最大步骤数。
self.mlesolver_max_steps = mlesolver_max_steps
self.papersolver_max_steps = papersolver_max_steps
8. 并行实验协调:对于并行设置,框架使用ThreadPoolExecutor管理多个实验室实例,确保它们能够同时运行并共享中央预印本服务器。
with ThreadPoolExecutor(max_workers=num_parallel_labs) as executor:
futures = [executor.submit(run_lab, lab_idx) for lab_idx in range(num_parallel_labs)]
for future in as_completed(futures):
try: future.result()
这种模块化设计使AgentRxiv能够灵活适应不同的研究需求和计算环境,同时保持代理之间的有效协作。框架的开源性质也允许研究者根据特定需求扩展和定制系统,进一步推动自主研究的边界。
在实际实验过程中,我们发现原始框架依赖大量外部库(如tensorflow、tf-keras等高阶深度学习的依赖和模块)并需要复杂的并行处理能力,这可能对资源有限的研究环境造成挑战,我想这也是很多读者测试不成功的主要原因。为此,我写了一个轻量级实现。注意,本简化版本专注于核心功能和Deepseek API集成。这个简化版本移除了复杂依赖,保留了基本的代理角色(PhD学生、博士后和教授)和研究流程,同时提供详细的过程信息输出。测试结果表明,即使在简化的环境中,AI代理仍能有效执行研究任务,生成有意义的结果。
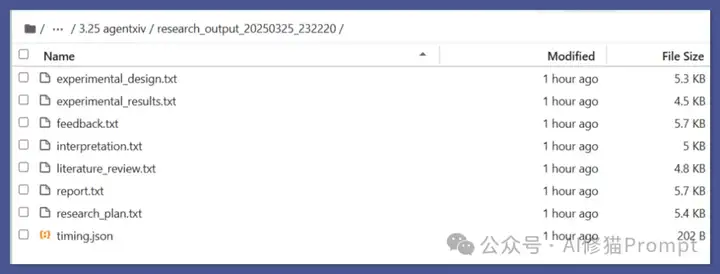
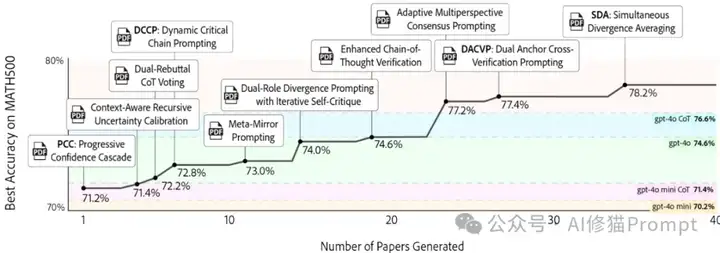
研究者们通过一系列实验证明了AgentRxiv框架的有效性。在MATH-500基准测试中,使用gpt-4o mini作为基础模型,通过AgentRxiv协作,准确率从基线的70.2%提升到了78.2%,使用新发现的推理技术如"同步发散平均法"(Simultaneous Divergence Averaging,SDA)。
研究人员还测试了 SDA 在不同语言模型上的表现,包括:
这种性能提升不仅限于单一任务。研究表明,通过AgentRxiv发现的推理策略能够泛化到其他基准测试和语言模型。例如,SDA技术在GPQA、MMLU-Pro和MedQA等多个基准测试上都展现出了一致的性能提升,跨越从DeepSeek-v3到Gemini-2.0 pro的多种语言模型(平均提升3.3%)。
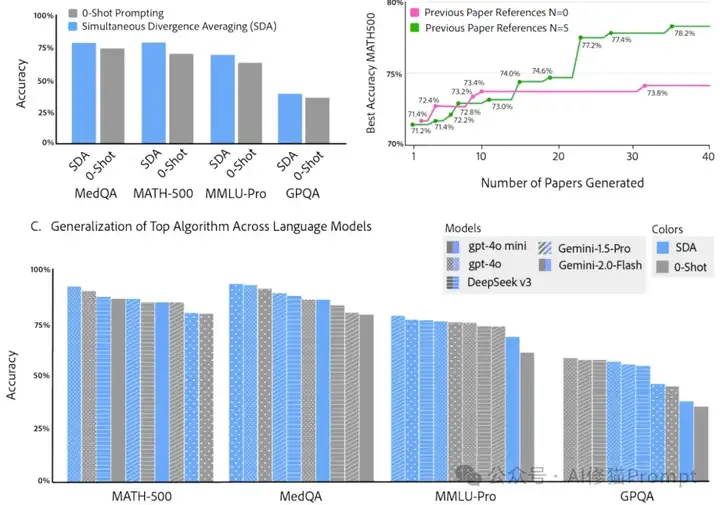
最引人注目的是,当多个代理实验室通过AgentRxiv共享研究成果时,它们能够比孤立实验室更快地朝着共同目标前进。在MATH-500基准测试上,三个并行实验室的协作使得最终准确率达到了79.8%,相比基线提高了13.7%,甚至超过了顺序研究设置的最佳表现(78.2%)。
研究中的一个有趣发现是,即使没有明确提示,代理也能自然地整合并改进先前迭代中的技术。在多个实例中,代理独立回忆起早期实验中的方法——如动态关键链提示或上下文感知递归不确定性校准——并将这些方法组合或修改,开发出全新的算法,如双角色发散提示。
我还观察到代理会将现有工作改编成第二版,例如元镜像提示2(基于元镜像提示)和改进的渐进置信度级联(基于渐进置信度级联)。这种自然的迭代改进能力表明,AI代理不仅能够执行单一研究任务,还能够在长期研究计划中展现出类似人类的知识积累和改进能力。
尽管AgentRxiv展示了令人印象深刻的结果,但研究者们也坦诚地指出了当前框架面临的几个关键挑战:
一个重要关切是传播偏见、错误信息和幻觉结果的潜力。LLM已被证明会放大训练数据中存在的偏见,并生成听起来权威但事实上不准确的信息。分析表明,LLM可能会伪造引用和引入错误,这表明需要相当程度的人类参与。
当前主要期刊和伦理机构的指导方针表明,AI系统不能被授予作者身份,因为它们无法对所生成的内容进行同意、验证或负责。此外,AI生成内容的所有权仍是持续辩论的话题。
LLM往往反映主流观点,同时低估边缘化观点,这可能无意中强化科学研究中的现有不平等。确保这些工具可访问至关重要;去偏见技术和AI技术民主化等策略对防止优势集中在资金充足的机构中至关重要。
原始代理实验室框架中的几个失效模式在AgentRxiv中仍然存在:
尽管采用o3-mini作为后端模型缓解了一些问题,但仍有大比例的实验完全失败(获得约0%的准确率),主要是由于代码中的重大错误。这部分是由于mle-solver步骤数量低,如果代码有非致命错误,它会继续进入文献综述阶段。
系统在编写正确的LaTeX代码方面也面临挑战。虽然paper-solver不会写出有致命错误的LaTeX(因为需要成功编译),但存在影响美观和可读性的错误。大多数情况下,这些错误只是美观问题,如表格或图形过大。然而,有些情况会影响论文可读性,如错误地进入和离开LaTeX数学模式,或使用ASCII编码的数学符号而非LaTeX形式。
AgentRxiv通过提供一个有效平台促进LLM代理之间的持续、协作发现,推进了代理驱动研究的前沿。
通过促进累积性知识构建、增强跨任务泛化能力并可能加速研究周期,AgentRxiv代表了将自主系统更全面地整合到科学工作流程中的一个有前景的发展。
这种方法不仅可以应用于科学研究,还可以扩展到各种需要复杂问题解决和持续学习的领域。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
