# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现阶段,微调大型语言模型(LLMs)的难点在于,人们通常没有高质量的标注数据。
最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。
众所周知,LLM 很难适应新的企业级任务。提示(prompting)的方式容易出错,且质量提升有限,而微调(fine-tuning)则需要大量的标注数据,而这些数据在大多数企业任务中是不可用的。
Databricks 提出的模型调优方法,只需要未标注数据,企业就可以利用现有的数据来提升 AI 的质量并降低成本。
TAO(全称 Test-time Adaptive Optimization)利用测试时计算(由 o1 和 R1 推广)和强化学习(RL)算法,仅基于过去的输入示例来教导模型更好地完成任务。
至关重要的是,尽管 TAO 使用了测试时计算,但它将其作为训练模型过程的一部分;然后,该模型以较低的推理成本(即在推理时不需要额外的计算)直接执行任务。
更令人惊讶的是,即使没有标注数据,TAO 也能实现比传统调优模型更好的质量,并且它可以将像 Llama 这样的开源模型提升到与专有模型(如 GPT-4o 和 o3-mini)相当的质量水平。
借助 TAO,Databricks 已经取得了三项突破性成果:
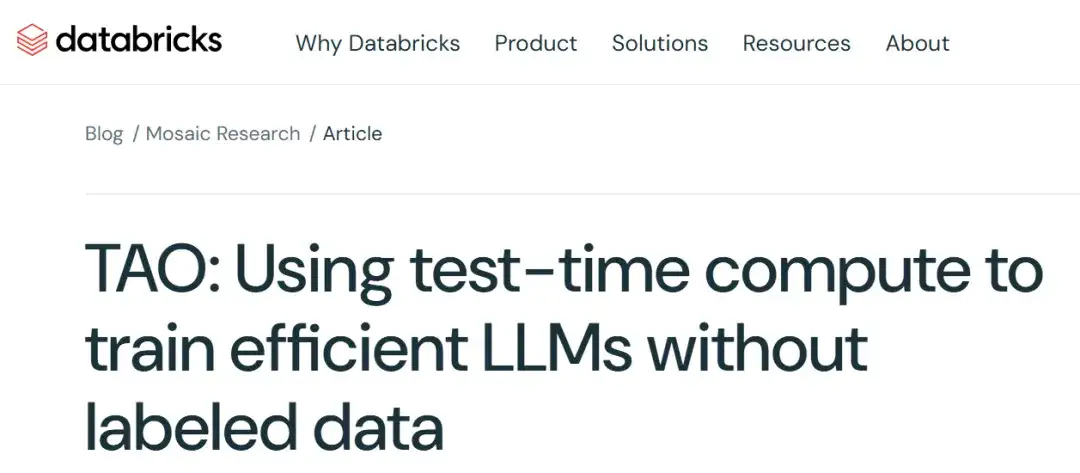
图 1 展示了 TAO 在三个企业级任务中对 Llama 模型的提升效果:尽管仅使用原始输入数据,TAO 不仅超越了需要数千标注样本的传统微调 (FT) 方法,更让 Llama 系列模型达到了商业模型的性能水准。
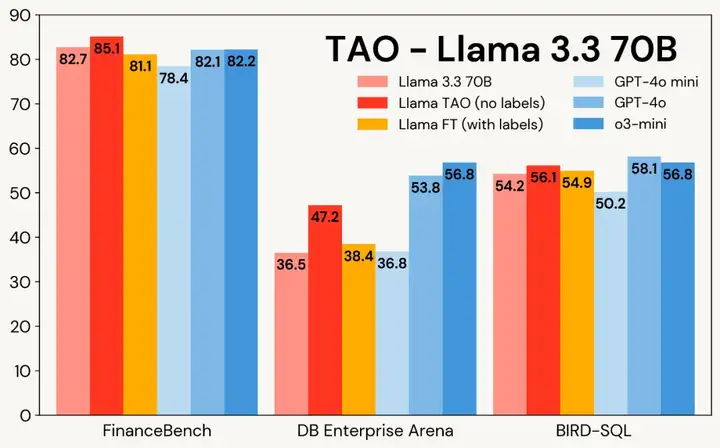
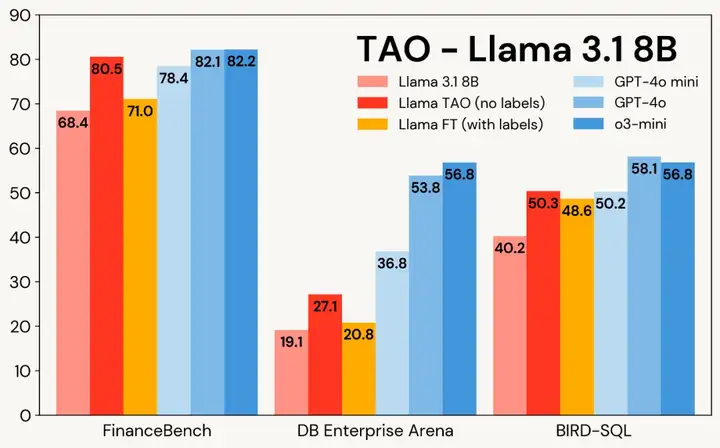
图 1:Llama 3.1 8B 与 Llama 3.3 70B 在三大企业级基准测试中应用 TAO 的效果对比。TAO 带来显著的性能提升,不仅超越传统微调方法,更直指高价商业大语言模型的性能水平。
TAO 工作原理
基于测试时计算与强化学习的模型调优
TAO 的核心创新在于摒弃了人工标注数据,转而利用测试时计算引导模型探索任务的可能响应,再通过强化学习根据响应评估结果更新模型参数。
该流程通过可扩展的测试时计算(而非昂贵的人工标注)实现质量提升,并能灵活融入领域知识(如定制规则)。令人惊讶的是,在高质量开源模型上应用该方法时,其效果往往优于依赖人工标注的传统方案。
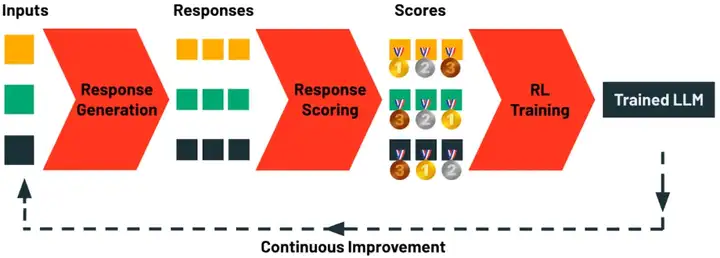
TAO pipeline
TAO 包含四个核心阶段:
虽然 TAO 在训练阶段使用了测试时计算,但最终产出的模型在执行任务时仍保持低推理成本。这意味着经过 TAO 调优的模型在推理阶段 —— 与原版模型相比 —— 具有完全相同的计算开销和响应速度,显著优于 o1、o3 和 R1 等依赖测试时计算的模型。实验表明:采用 TAO 训练的高效开源模型,在质量上足以比肩顶尖的商业闭源模型。
TAO 为 AI 模型调优提供了一种突破性方法:
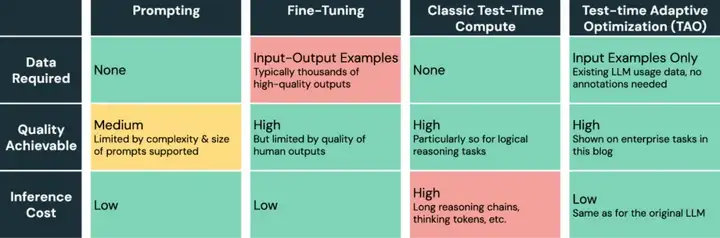
LLM 不同调优方法比较。
实验及结果
接下来,文章深入探讨了如何使用 TAO 针对专门的企业任务调优 LLM。本文选择了三个具有代表性的基准。

表 2:该研究使用的基准测试概览。
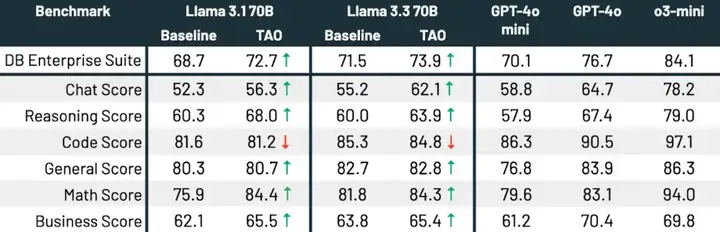
如表 3 所示,在所有三个基准测试和两种 Llama 模型中,TAO 显著提升了基础 Llama 的性能,甚至超过了微调的效果。

表 3:在三个企业级基准测试中使用 TAO 的 Llama 3.1 8B 和 Llama 3.3 70B 实验结果。
与经典的测试时计算类似,当 TAO 能够使用更多的计算资源时,它会产生更高质量的结果(见图 3 中的示例)。然而,与测试时计算不同的是,这种额外的计算资源仅在调优阶段使用;最终的语言模型的推理成本与原始语言模型相同。例如,o3-mini 生成的输出 token 数量比其他模型多 5-10 倍,因此其推理成本也相应更高,而 TAO 的推理成本与原始 Llama 模型相同。
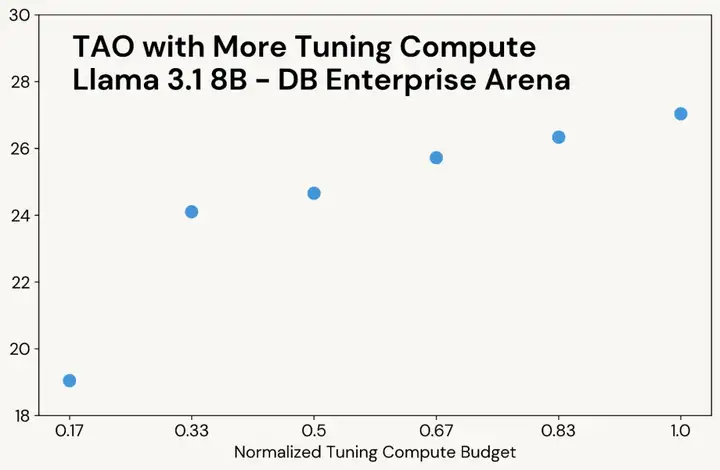
利用 TAO 提高模型多任务性能
到目前为止,该研究已经使用 TAO 来提升语言模型在单一任务(例如 SQL 生成)上的表现。接下来,该研究展示了 TAO 如何广泛提升模型在一系列企业任务中的性能。
结果如下,TAO 显著提升了两个模型的性能,将 Llama 3.3 70B 和 Llama 3.1 70B 分别提升了 2.4 和 4.0 个百分点。TAO 使 Llama 3.3 70B 在企业级任务上的表现显著接近 GPT-4o,所有这些改进都没有产生人工标注成本。
原文链接:https://www.databricks.com/blog/tao-using-test-time-compute-train-efficient-llms-without-labeled-data
文章来自微信公众号 “ 机器之心 ”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
