# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
3月26号,ETH等团队的一项研究一经发布,就引起了圈内热议。
这项研究彻底撕开遮羞布,直接击碎了「LLM会做数学题」这个神话!

论文地址:https://files.sri.inf.ethz.ch/matharena/usamo_report.pdf
鉴于此前它们在AIME上的出色表现,MathArena团队使用最近的2025年美国数学奥林匹克竞赛进行了详细评估,结果令人大吃一惊——
所有大模型的得分,都低于5%!
DeepSeek-R1表现最好,得分为4.76%;而表现最差的OpenAI o3-mini(high)比上一代o1-pro(high)还差,得分为2.08%。

各顶尖模型在2025 USAMO中的得分
就在今天,这项研究再次被关注到,直接成为了Reddit的热议话题。

具体来说,在这项研究中,模型需要在2025年USAMO的六道基于证明的数学题上进行了测试。每道题满分7分,总分最高为42分。
然后会由人类专家来给它们打分。
这些模型取得的最高平均分,也就5%,简直惨不忍睹。
更好笑的是,这些模型对自己的解题进行评分时,还会一致高估自己的得分(此处点名O3-mini和Claude 3.7)。跟人类研究者相比,评分被夸大了能有20倍不止。

所以,此前模型之所以能骗过人类,营造出自己很擅长做数学的假象,纯纯是因为它们已经在所有可以想象到的数学数据上进行了训练——
国际奥数题、美国奥数档案、教科书、论文,它们全都见过!
而这次,它们一下子就暴露出了三大致命缺陷。
逻辑错误:模型在推理过程中做出了不合理的跳跃,或将关键步骤标记为「微不足道」。
缺乏创造力:大多数模型反复坚持相同的有缺陷策略,未能探索替代方案。
评分失败:LLMs 的自动评分显著提高了分数,表明他们甚至无法可靠地评估自己的工作。
这,就是人类投入数十亿美元后造出的成果。
好在,这项研究中,多少还是有一些令人鼓舞的迹象。
比如「全村的希望」DeepSeek,在其中一次尝试中,几乎完全解决了问题4。

问题4大意为:
设H为锐角三角形ABC的垂心,F为从C向AB所作高的垂足,P为H关于BC的对称点。假设三角形AFP的外接圆与直线BC相交于两个不同的点X和Y。
证明:C是XY的中点。
LLM数学能力,到底强不强?
LLM的数学能力,早已引起了研究人员的怀疑。
在AIME 2025 I中,OpenAI的o系列模型表现让人叹服。
对此,来自苏黎世联邦理工学院的研究人员Mislav Balunović,在X上公开表示:「在数学问题上,LLM到底具有泛化能力,还是学会了背题,终于有了答案。」
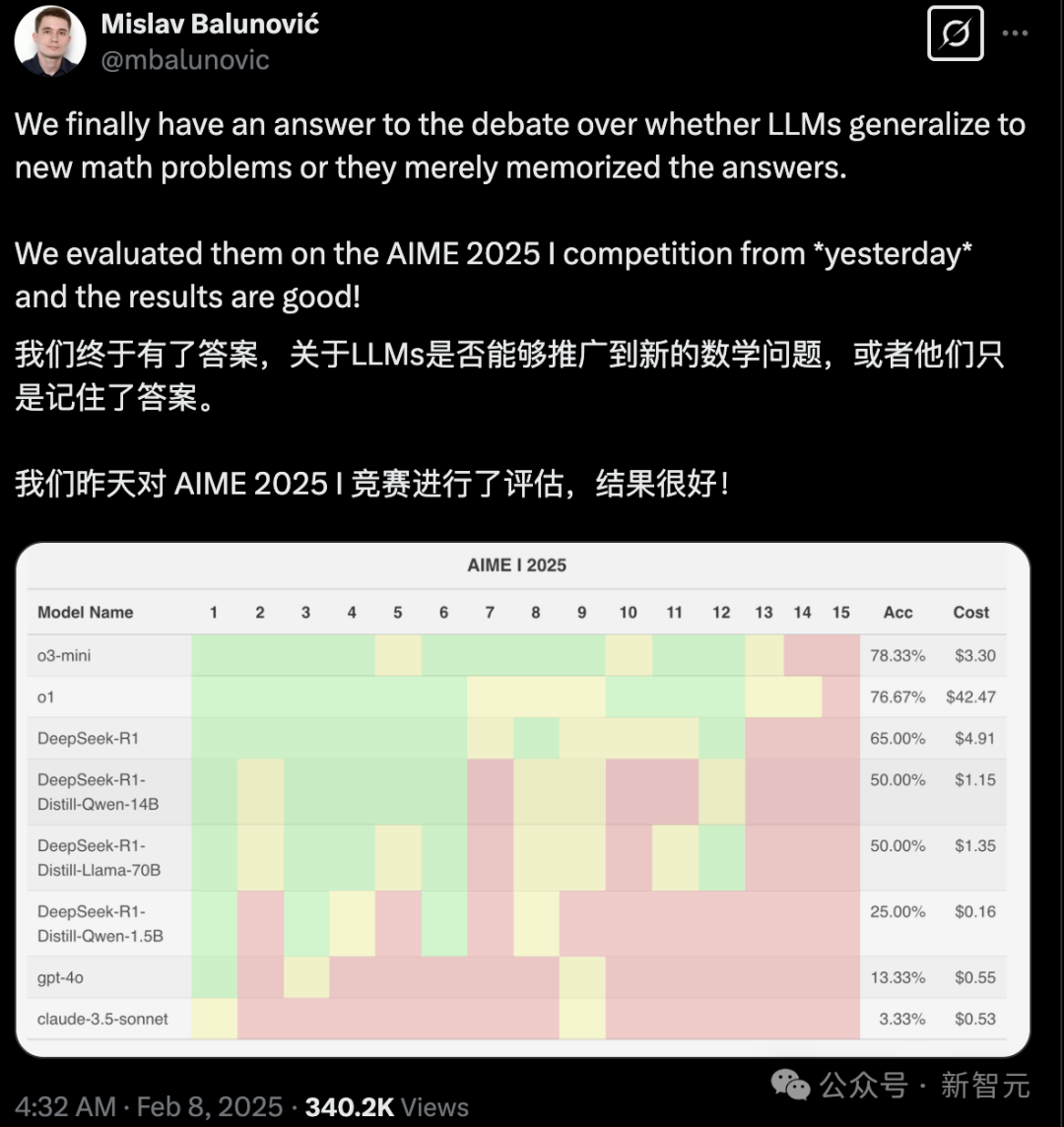
然而,马上有人发现,测试的题目网上就有「原题」,质疑LLM根本没学懂数学,只是记下了答案。

在AIME 2025 II中,o3-mini(high)准确率更是高达93%!
而来自普林斯顿的华人团队,研究显示LLM可能只是学会了背题 ——
将MATH数据集中的问题,做一些改动,多个模型的性能显著下降!

美国数学奥林匹克竞赛的选拔赛AIME 2025 I和AIME 2025 II是,成绩优异者才能参加2025年的USAMO
那问题来了,LLM的数学泛化能力到底强不强?
LLM真学会了数学证明吗?
这次,来自ETH Zurich等研究团队,终于证明:实际上,LLM几乎从未没有学会数学证明!
研究团队邀请了具有奥数评审经验的专家,评估了顶尖模型(如o3-mini、Claude 3.7和Deepseek-R1)的证明过程。
在评估报告中,研究人员重点指出了几个常见问题。
比如,AI会使用未经证明的假设,
再比如,模型总是执着于输出格式漂亮的最终答案,即便并未要求它们这样做。
美国奥赛,LLM表现堪忧
这是首次针对2025年美国数学奥林匹克竞赛(USAMO)的难题,系统评估LLM的自然语言证明能力。
USAMO作为美国高中数学竞赛的最高殿堂,要求证明与国际数学奥林匹克(IMO)同等级别的严密与详细阐述。
美国数学奥林匹克(USAMO)是美国国家级邀请赛,是国际数学奥林匹克队伍选拔中的关键一步。
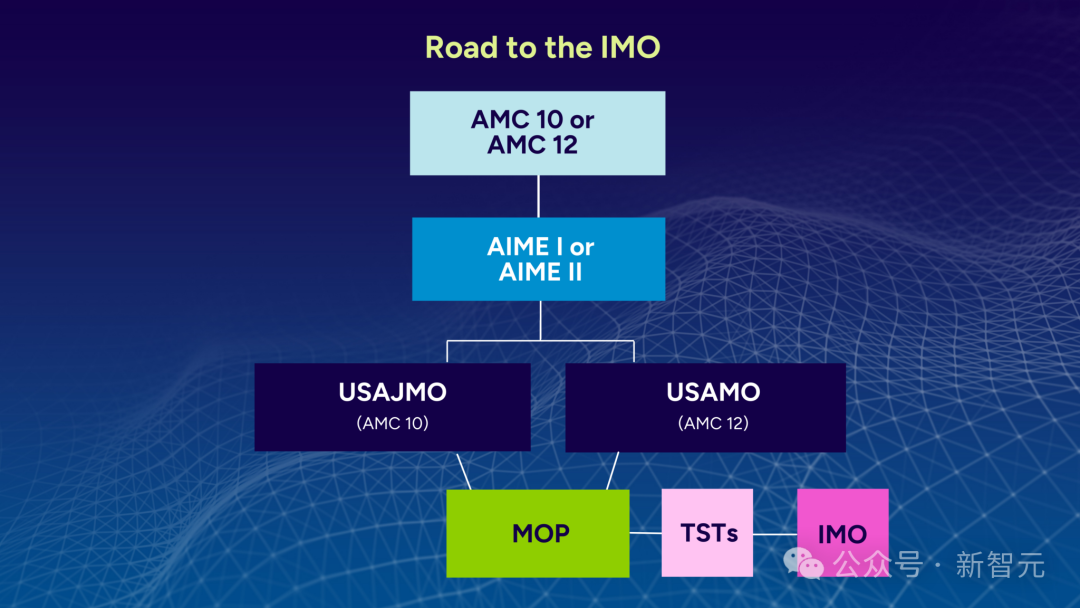
美国国际数学奥林匹克竞赛队员选拔流程
USAMO和USAJMO是为期两天、共包含六个问题、9小时的论文/证明考试。
USAMO完美契合评估LLM的目标:题目难度高、要求完整证明过程才能得分,且未经公开数据污染。
参赛者虽通过AIME等赛事晋级,但USAMO问题对解题的严谨性与解释深度要求显著更高。
整体而言,当前LLMs在USAMO问题中表现堪忧,最优模型的平均得分不足5%。
在生成严格数学证明方面,现有LLM还有重大局限!
本报告中,首先在§2阐述方法论,§3详述结果并分析核心弱点,§4则讨论多项定性观察结论。
LLM评估方法
在评估过程中,为每个模型提供题目,并明确要求其生成格式规范的LaTeX详细证明。
完整的提示词说明,原文如下:

提示词大意为:
请对以下问题给出详尽的答案。你的答案将由人工评委根据准确性、正确性以及你证明结果的能力来评分。你应包含证明的所有步骤。
不要跳过重要步骤,因为这会降低你的分数。仅仅陈述结果是不够的。请使用LaTeX来格式化你的答案
{问题}
为降低方差,每个模型对每道题独立求解4次。
所有解答(不含推理过程)经匿名化处理后统一转换为PDF格式供评分使用。
评分团队由四位专家组成,每位专家都拥有丰富的数学解题经验,
他们曾是国家国际数学奥林匹克(IMO)代表队成员,或者参加过各自国家的最终阶段国家队选拔。
在评分之前,评委们收到了详细说明评估目标和方法的指导意见。
2025年美国数学奥林匹克竞赛(USAMO)共有六道题目。

每一道都由2名评估人员独立进行评估,每位评委负责批改三道不同的题目。
这种双评的评分方法仿照了国际数学奥林匹克竞赛(IMO)的评估流程,确保了评分的一致性,并减少了个人偏见。
由于美国数学奥林匹克竞赛官方并不公布标准答案或评分方案,研究人员依靠数学界资源,
尤其是「解题的艺术」(Art of Problem Solving,简称AoPS)论坛,为每一道题目精心制定了标准化的评分方案。
在制定评分方案之前,评估人员对来自这些资源的所有解答进行了准确性验证。
按照美国数学奥林匹克竞赛的惯例,每道题目的最高分为7分,对于取得重大且有意义进展的解答会给予部分分数。
评审专家根据预先制定的评分标准,对每份解答进行独立评阅。当答案与评分标准存在偏差时,评审会在合理范围内给予部分得分。
每位专家均需详细记录评分依据,包括所有部分得分的授予理由,相关评语已公开在项目网站。
在评阅过程中,专家还需系统记录典型的错误模式。
「错误模式」定义为解题过程中首次出现的推理缺陷,包括但不限于:逻辑谬误、未验证的假设、数学表述不严谨或计算错误。
具体而言,这些错误被划分为以下四类:
1. 逻辑类错误:因逻辑谬误或未经论证的推理跳跃导致论证链断裂;
2. 假设类错误:引入未经证明或错误假设,致使后续推导失效;
3. 策略类错误:因未能识别正确解题路径而采用根本性错误解法;
4. 运算类错误:关键代数运算或算术计算失误。
此外,对于模型生成的解答中值得关注的行为或趋势,研究人员录为文档,以便进一步分析。
这些观察结果被用于找出模型在推理能力方面常见的陷阱和有待改进的地方。
评估结果
在解决美国数学奥林匹克竞赛(USAMO)的问题时,所有模型表现都很差。
此外,还会深入分析了常见的失败模式,找出了模型推理过程中的典型错误和趋势。
针对2025年美国数学奥林匹克竞赛(USAMO)的问题,对六个最先进的推理模型进行了评估,分别为QwQ、R1、Flash-Thinking、o1-Pro、o3-mini和Claude 3.7。
表1提供了每个问题的模型性能详细分类,平均分数是通过四次评估运行计算得出的。
美国数学奥林匹克竞赛的每个问题满分为7分,每次运行的总最高分是42分。
该表还包括在所有问题和评估运行中运行每个模型的总成本。
成本以美元计算,各模型在所有题目上的最终得分取各评审所给分数的平均分呈现。
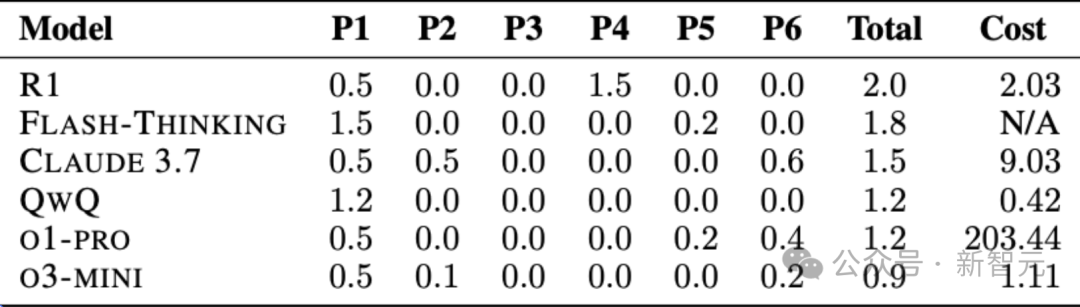
表1:评估核心结果。每道题目采用7分制评分,满分总计42分。表中分数为四次运行的平均值。
新的评估揭示了LLM在生成严谨数学证明方面的显著不足。
所有受测模型的最高平均得分均低于5%,这一结果表明现有模型在处理USAMO级别问题的复杂性和严密性方面存在根本性局限。
值得注意的是,在所有模型提交的近150份解答中,没有一份获得满分。
虽然USAMO的题目难度确实高于既往测试的竞赛,但所有模型在不止一道题目上的全军覆没,充分证明当前LLM仍无法胜任奥数级别的严格数学推理任务。
这一局限同时暗示,GRPO等现有优化方法,对于需要高度逻辑精密度的任务可能仍然力有未逮。
人类参赛者往往找不到正确解题方法,不过一般能判断自己的答案对不对。
反观LLM,不管做没做对,都一口咬定自己解出了题目。
这种反差,给LLM在数学领域的应用出了难题——要是没经过人工严格验证,这些模型给出的数学结论,都不太靠谱。
为了搞清楚LLM这一局限,按事先定义好的错误分类标准,对评分时发现的错误展开了系统分析。
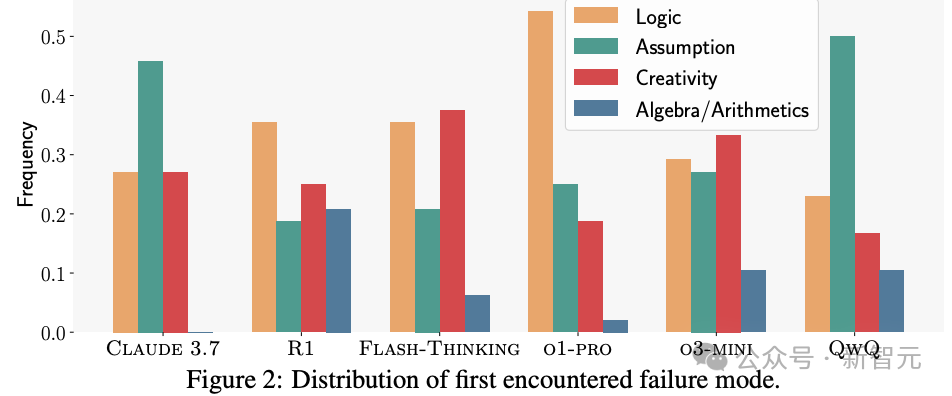
图2呈现了评审判定的错误类型分布。
在所有错误类型里,逻辑缺陷最为普遍。
LLM经常使用没有依据的推理步骤,论证时出错,或者误解前面的推导过程。
另外,模型还有个大问题:碰到关键证明步骤,就敷衍地归为「显然成立」或「标准流程」,不做论证。
就连o3-mini也多次把核心证明步骤标成「显然」,直接跳过。可这些步骤是不是严谨,对解题特别关键。
除了前面提到的问题,研究人员还发现,模型推理特别缺乏创造性。
好多模型在反复尝试解题时,总是沿用同一套(还可能错误的)解题策略,压根不去探索其他办法。
不过,Flash-Thinking模型是个例外。它在解一道题时,会尝试多种策略。但因为想做的太多,每种策略都没深入,最后也没能得出有效的结论。
值得一提的是,这些模型在代数运算上表现不错。
面对复杂的符号运算,不用借助外部计算工具,就能轻松搞定。
但R1模型的代数/算术错误率偏高,还需针对性优化。
共性问题
在评估过程中,评审专家还记录了模型的共性问题和显著的特征。
当下,像GRPO这类基于强化学习的优化技术,需要从清晰标注的最终答案里提取奖励信号。
所以,模型常常被要求把最终答案放在\boxed{}里。
但这一要求,在USAMO解题过程中引发了异常情况。大部分赛题其实并不强制框定最终答案,但模型却非要这么做。
以第五题为例,QwQ模型在解题时,自行排除了非整数解的可能,即便题目没这个限制。
它还错误地认定最终答案是2。
QwQ可把自己「绕晕」啦!
它想要一个整数答案,可实际上,答案明明是所有偶数整数的集合。

这一现象说明,GRPO等对齐技术在不经意间,让模型形成了「所有数学问题都要框定答案」的固定思维,反倒削弱了模型的推理能力。
模型有个常见毛病,喜欢把在小规模数值案例里观察到的模式,一股脑套用到还没验证的场景中。
在只求算出数值答案的题目里,这种方法或许还行得通。可一旦碰上需要严格证明的问题,它的弊端就暴露无遗。
模型经常不做任何证明,就直接宣称局部观察到的模式放之四海而皆准。
比如说,在问题2的求解过程中,FLASH-THINKING模型选择了一个具体的多项式进行验证,但随后却错误地将结论推广至所有多项式。
这种从特殊案例直接跳跃到普遍结论的做法,暴露了当前模型在数学归纳推理能力上的根本缺陷——
它们缺乏对「充分性证明」这一数学核心原则的理解,无法区分「举例验证」与「完备证明」的本质区别。

Gemini Flash-Thinking的盲目泛化
不同模型的解答在结构清晰度上差异显著。
1. 优质范例:o3-mini和o1-Pro的解答逻辑清晰、层次分明
2. 典型缺陷:Flash-Thinking和QwQ常产生混乱难解的应答,有时在同一解法中混杂多个无关思路
OpenAI训练模型在可读性上超厉害!这说明,专门针对解答连贯性开展训练,能大幅提升输出质量。
反观其他模型,在这方面明显不够上心。
参考资料:
https://files.sri.inf.ethz.ch/matharena/usamo_report.pdf
https://x.com/mbalunovic/status/1904539801728012545
https://maa.org/maa-invitational-competitions/
文章来自于微信公众号 “新智元”,作者 :KingHZ Aeneas



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
