# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前几天有朋友还在问我GPU租赁市场的情况,正好SemiAnalysis出了这篇文章:GPU云ClusterMA评级系统 | GPU租用指南。

这篇报告介绍了SemiAnalysis推出的ClusterMAX™ GPU云评级系统,
对100多家GPU云服务商从安全性、性能、价格、可靠性等维度进行分级(Platinum到UnderPerform),并指出当前GPU租赁市场已转向买方市场,
H100价格持续下降,建议用户优先选择高评级服务商(如CoreWeave)或高性价比选项(如Nebius)。
同时强调Blackwell GPU上市后,H100的租赁价值将大幅缩水,提供商需通过长期合约锁定收益。
GPU租赁市场的狂热已经消退,我们在2023年12月的GPU云经济报告中就预测过这一点,并在2024年10月发布的AI Neocloud解剖与策略报告中再次重申。
技术进步意味着计算成本会随时间下降,现在我们认为GPU租赁已经是买方市场,特别是Hopper和MI300级别的GPU。
市场上涌现了大量新玩家,目前有超过100家AI Neocloud和Hyperscaler提供租赁选择,但缺乏一个明确的"如何租赁GPU"指南或独立的GPU云评估标准。
过去12个月我们一直在构建GPU云ClusterMAX评级系统,简称ClusterMAX。我们独立测试并收集了尽可能多的GPU云服务商的客户反馈。
通过这次首次发布的GPU云评级,我们覆盖了90%以上的GPU租赁市场份额。希望下次评估时能纳入更多提供商,全面评估他们的服务质量。
这份评级并不是完整的GPU提供商清单。我们掌握的市场参与者名单要长得多,整个市场版图每天都在扩张,但很多neocloud还没准备好服务客户。
这正是ClusterMAX的价值所在——它是一个帮助用户应对复杂市场的工具。你可能更愿意把钱花在获得ClusterMAX评级的提供商身上。
我们的评级分为五个等级:Platinum、Gold、Silver、Bronze和UnderPerform。每个等级都有对应的评判标准,从最好到最差依次说明。
Platinum代表行业最顶尖的GPU云服务商,目前只有CoreWeave一家达到这个级别。它是目前唯一能可靠运营万级H100集群的非Hyperscaler。
有些Bronze级别的提供商已经在努力追赶,比如Google Cloud,我们预计下次评估时它可能跃升至Gold甚至Platinum级别。
企业客户主要从Hyperscaler和CoreWeave租赁GPU,很少选择新兴Neocloud。
Hyperscaler的GPU租赁价格普遍高于Neocloud巨头和新兴Neocloud,因为他们主要服务企业市场。Oracle在Hyperscaler中定价最低。
在技术实力强的GPU云中,Nebius提供最低的绝对价格和最优惠的中短期租赁条款,Crusoe也提供合理的定价和合同条款。
正如我们在2023年12月GPU云经济报告中首次讨论的,技术进步导致计算成本随时间下降,现在我们认为GPU租赁是买方市场。
上百家GPU云在争夺基本相同的客户群。
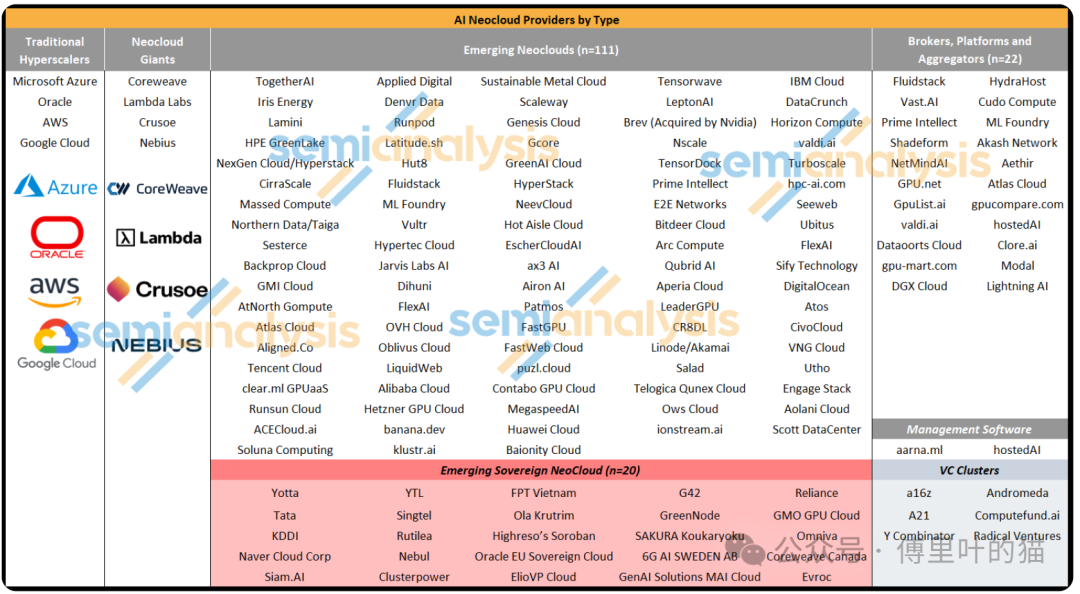
image-20250331204837008
DeepSeek的推出短期内稳定甚至推高了H200租赁价格,但中长期来看价格仍在下降。
Jensen Huang上周说:"当Blackwell开始大规模出货时,白送都没人要Hopper。"
从GPU运营商角度看,这提醒他们应该尽可能签订长期合约来规避计算价格快速下跌的风险。从客户角度看,他们可能更倾向于选择灵活的短期合约。
我们会在文章最后讨论GPU租赁定价、GPU的内部收益率(IRR)以及不同合约期限的最新市场费率。
1.SemiAnalysis开发了全球首个GPU云评级系统——我们将其命名为ClusterMAX™。我们从普通合理客户的角度对GPU云进行评级。
2.SemiAnalysis独立测试了数十家GPU云服务商,目前ClusterMAX覆盖了约90%的GPU租赁市场(按GPU数量计算)。
3.GPU云行业的整体标准目前非常低。ClusterMAX旨在提供一套指导方针,帮助提升整个GPU云行业的水平。
ClusterMAX的评估标准涵盖了大多数GPU租户关心的功能。
4.ClusterMAX分为五个等级:Platinum(铂金)、Gold(金)、Silver(银)、Bronze(铜)和UnderPerform(不合格)。
5.我们将每3-6个月定期更新ClusterMAX评级,以便反映各家GPU云的改进情况,并为客户提供最新的GPU租赁信息。
6.ClusterMAX Platinum代表行业标杆,目前只有CoreWeave一家GPU云达到这一级别。
7.CoreWeave是目前唯一一家非Hyperscaler(超大规模云服务商),但能够可靠运营10,000+ H100 GPU集群。
8.部分ClusterMAX Bronze级别的提供商(如Google Cloud)正在努力追赶。我们相信,在下一次评估时,Google Cloud有望达到ClusterMAX Gold甚至Platinum级别。
9.企业客户主要从Hyperscaler和CoreWeave租赁GPU,很少选择新兴Neocloud(新型GPU云服务商)。
10.Hyperscaler的GPU租赁价格高于Neocloud巨头和新兴Neocloud,因为Hyperscaler主要面向企业市场。
11.Oracle在Hyperscaler中提供最低的GPU租赁价格之一。
12.在技术能力强的GPU云中,Nebius提供最低的绝对价格和最灵活的短/中期租赁条款。Crusoe也提供合理的定价和合同条款,同时具备强大的技术能力。
13.正如我们在2023年12月的《GPU云经济学报告》中首次讨论的,技术进步意味着计算成本会随时间下降,现在GPU租赁市场是买方市场。目前有100多家GPU云在争夺相同的客户群体。
14.DeepSeek的推出短暂稳定甚至推高了H200租赁价格,但从中长期来看,价格仍在下降。
15.NVIDIA CEO黄仁勋(Jensen Huang,他自称“首席收入破坏者”)上周表示:“Blackwell开始大规模出货时,Hopper(H100)甚至可能白送都没人要。”
从GPU运营商的角度来看,这提醒他们应尽可能签订长期合约,以防范计算价格快速下跌的风险。
而从客户的角度来看,他们可能更倾向于短期合约以获得灵活性。
16.我们将在文章末尾讨论GPU租赁定价、GPU的内部收益率(IRR)以及不同合约期限的最新市场租金。
GPU Cloud ClusterMAX™评级系统旨在评估和比较超过100家GPU提供商的能力,为机器学习社区提供清晰的参考标准。
该系统通过独立测试和客户反馈,覆盖了市场上90%的GPU租赁量,目标是帮助用户选择最适合的GPU云服务,同时推动行业整体服务质量的提升。
评级分为五个等级:Platinum、Gold、Silver、Bronze和UnderPerform。每个等级对应不同的服务水平和能力,从技术专业性到价格竞争力均有明确区分。
Platinum代表行业最高标准,目前仅有CoreWeave一家达到。CoreWeave在安全性、网络性能、自动化管理等方面表现卓越,
能够可靠运营超大规模集群(如10k+H100),并提供全托管Slurm和Kubernetes解决方案。
其独特的节点生命周期控制器和健康检查系统显著提升了集群的稳定性和效率。
Gold级别的提供商在多数关键指标上表现优秀,但仍有改进空间。例如Crusoe在用户体验和支持服务上表现突出,近期推出了托管Slurm解决方案;
Nebius则以最低价格著称,但用户界面和自动化管理仍需优化;Oracle Cloud在企业级安全和性价比上表现均衡,但Slurm支持仍依赖人工协助。
Silver级别的服务满足基本需求,但在高级功能或性能上存在短板。AWS通过EFAv3网络提升了性能,但仍不及InfiniBand方案;
Lambda Labs是按需实例的市场标杆,但实例启动速度较慢,技术细节也有待完善。
Bronze级别的提供商勉强达到基本要求,但问题较多。
Google Cloud长期因网络性能不足受到诟病,虽然a3-ultra实例有所改进,但多数客户仍在使用落后的a3-mega配置。
其他Bronze提供商通常因功能缺失或体验不佳而未能进入更高等级。
UnderPerform级别的提供商存在严重问题,如缺乏基本安全认证(SOC2/ISO 27001)、技术能力不足或提供误导性信息。
这类服务不仅无法满足专业需求,还可能带来安全风险。
评级系统将持续更新,未来计划纳入更多提供商并细化评估维度,例如对不同规模集群的支持能力、区域覆盖以及新兴硬件(如B200/GB200)的适配性。
通过定期重新评估,ClusterMAX™将动态反映市场变化,为用户提供最新、最全面的决策参考。
NVIDIA CEO黄仁勋在上周的发言中直言不讳:"当Blackwell开始大规模出货时,H100可能白送都没人要"。
这番言论呼应了我们早在2023年12月发布的GPU云经济报告中的预测。
从技术演进的角度看,计算成本随时间下降是必然趋势,现在H100租赁市场已明显转向买方市场。
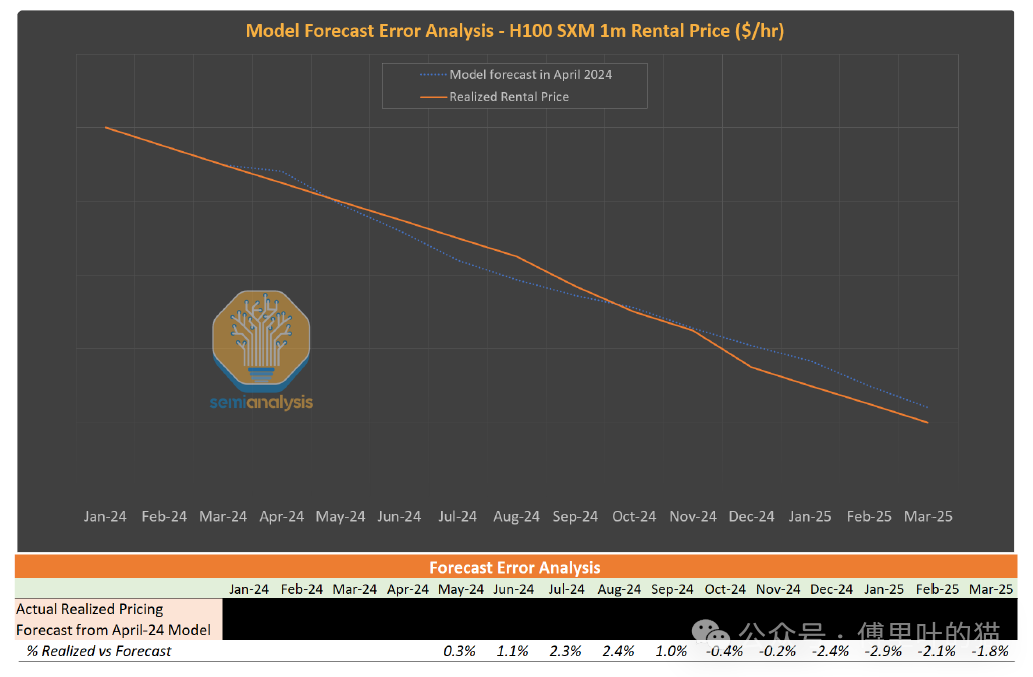
image-20250331205635112
我们的定价模型显示,H100 SXM的租赁价格在2024年持续走低,主要受三个因素驱动:
首先是H100产能提升带来的供应增加;其次是买家将战略重心转向Blackwell架构;最后是新进入者持续涌入市场。
实际价格走势与我们在2024年4月建立的预测模型高度吻合,误差率仅2-3%。
价格预测模型的核心逻辑基于三个维度:首先是全球AI加速器的装机量数据,我们通过供应链分析跟踪每个GPU型号的出货情况;
其次是AI集群的总拥有成本(TCO),包含服务器硬件、网络设备、电力等资本支出和运维成本;
最后是计算吞吐效率,通过实测训练FLOPS和推理吞吐量(token/秒/GPU)来评估。
以GB200 NVL72与H100的对比为例:GB200在推理成本上比H100低75%,训练成本低56%。
这意味着如果GB200定价2.2美元/GPU/小时,H100必须降至0.98美元才能保持竞争力。这种新一代硬件带来的成本优势,会持续拉低整个市场的计算成本基准。
从商业策略来看,黄仁勋的"首席营收毁灭者"称号恰如其分——NVIDIA通过快速迭代使旧产品贬值,这要求GPU云服务商采取两种应对策略:
对运营商而言,应该尽可能签订长期合约锁定收益;而对终端用户来说,短期灵活合约更能享受技术迭代红利。
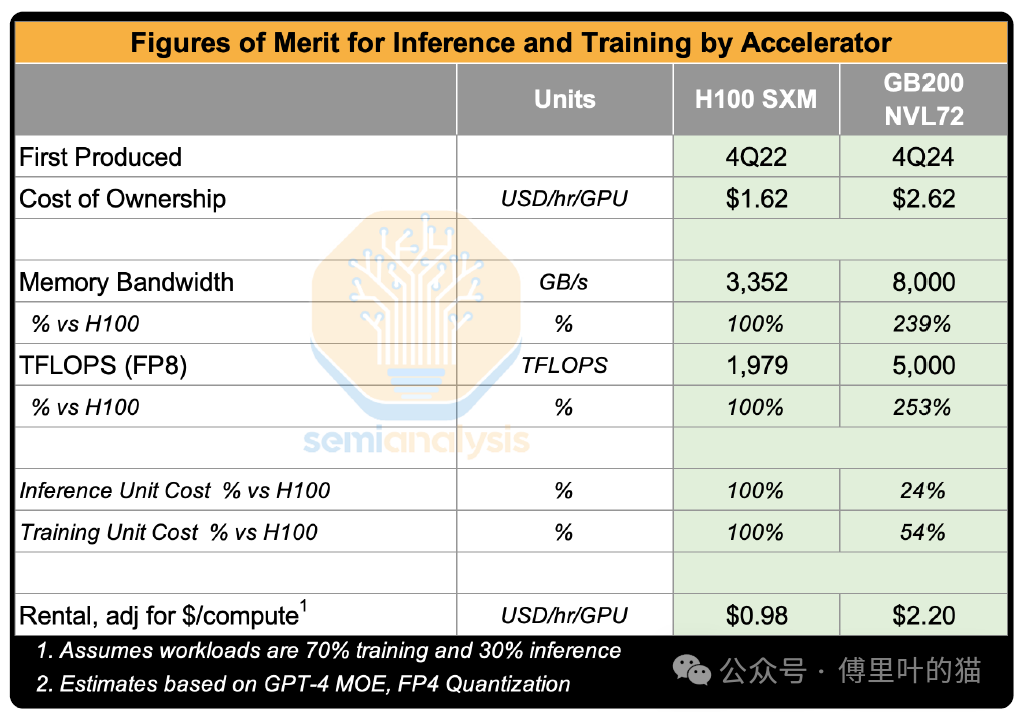
image-20250331205646560
当前市场已经出现明显分化:H100的三年期合约几乎消失,一年期合约成为主流。部分激进供应商如Nebius甚至推出首1000小时1.5美元/小时的促销价。
这种价格竞争态势印证了我们的核心观点:计算效率的提升必然导致旧硬件租赁价格的持续走低。
ClusterMAX™评级系统的设计目标是评估和比较超过100家GPU提供商的能力,为机器学习社区提供清晰的参考依据。
评估过程中重点关注GPU租户最关心的核心需求,
包括安全性、生命周期管理、技术专业性、可靠性、调度系统、存储性能、网络性能、健康监控、定价模型以及技术合作伙伴关系。
安全性是评估中的首要因素,GPU租户通常存储价值数百万美元的专有模型权重,这些数据是生成式AI公司的核心资产。
训练和推理过程可能涉及用户隐私数据,尤其在欧盟地区,GDPR法规对数据泄露有严厉处罚。
行业中存在大量新兴Neocloud尚未通过基本的安全认证,部分甚至出现在AMD联盟合作伙伴列表中却缺乏SOC2或ISO 27001认证。
租户网络隔离是安全架构的基础。在以太网环境中需要通过VLAN或DPU实现租户隔离,而在InfiniBand网络中则依赖分区密钥(PKeys)。
顶级GPU云如CoreWeave、OCI、AWS和GCP已实现DPU级别的租户隔离。
InfiniBand网络还需配置六类安全密钥:子网管理器密钥(SM Key)防止未授权子网管理器接入,
管理密钥(M Key)保护网络配置,拥塞控制密钥(CC Key)防止网络拥塞攻击,聚合管理密钥(AM Key)保护SHARP聚合功能,
以及虚拟网络密钥(VS Key)。
容器隔离方案需要特别注意。早期CoreWeave采用多租户共享Kubernetes集群的模式已被淘汰,因其存在容器逃逸风险。
当前标准是每个租户独占物理服务器或通过虚拟机实现严格隔离。
已知的NVIDIA容器漏洞(如2024年9月Wiz披露的CVE-2024-0132)会导致攻击者跨容器访问数据,因此仅依赖容器隔离的方案被视为不安全。
生命周期管理体现技术专业性。从售前阶段的技术咨询、合同中的明确交付时间,到集群预部署时的数据迁移支持都至关重要。
核心流程包括:集群自动化交付(避免人工错误)、高温烧机测试(持续3-4周)、节点故障自动转移(90秒内替换故障节点)以及公平的停机补偿机制。
顶级提供商如CoreWeave会公开测试流程,其KubeCon演讲展示了完整的验收标准。
调度系统直接影响用户体验。90%的推理工作负载使用Kubernetes,50%的训练任务采用Slurm。优秀提供商应提供开箱即用的托管调度系统,集成关键功能:
Slurm的Pyxis插件支持容器化环境,拓扑感知调度(topology.conf)优化NCCL性能,以及MPI集成。测试发现未配置拓扑感知会导致NCCL性能下降20-30%。
存储性能的评估重点在于解决两大痛点:随机卸载卷问题(通过autofs自动挂载解决)和小文件性能问题(LOSF)。
优化后的存储系统在1024GPU规模下应保持稳定,PyTorch导入时间不应随节点增加而显著延长。
Crusoe的测试数据显示其存储方案在规模化场景下仍保持线性性能。
网络性能通过NCCL/RCCL测试验证,重点关注16MiB-512MiB的实际工作负载消息大小。
网络架构差异显著影响性能:InfiniBand NDR(如CoreWeave)优于Spectrum-X以太网(如Oracle),而启用SHARP能进一步提升性能。
测试发现GCP的8x400GbE a3-ultra网络因单跳域仅4节点(Oracle为32节点),导致跨域通信性能劣于预期。
健康监控系统包含被动监控(实时检测XID错误、PCIe总线故障、链路抖动)和主动诊断(每周自动运行dcgm diag、NCCL测试、TinyMeg2静默数据损坏检测)。
CoreWeave的监控面板能关联GPU SM活动度与故障事件,例如当PCIe故障导致TFLOP/s下降时自动标记问题节点。
定价模型需平衡灵活性与成本。按需实例适合开发场景(2.99/GP**U/小时),Spot实例适合可中断任务(1.0-2.0),长期合约(1−3年)适合稳定负载。
Nebius通过ODM服务器将毛利压缩至21.5/小时(首1000小时)。Oracle在Hyperscaler中定价最低,因其完整的企业级功能集成。
技术合作伙伴关系影响服务质量。NVIDIA云合作伙伴(NCP)通常表现更好,Jensen Huang投资的五家GPU云中有四家达到Gold以上评级。
AMD需提升合作伙伴标准,其部分联盟成员甚至缺乏基础安全认证。采用SchedMD商业支持的Slurm能显著提升用户体验。
在评估GPU云提供商的技术专业性时,生命周期管理是核心考量之一。
技术专长的影响从销售阶段就开始了,包括营销清晰度、透明的定价、合理的服务协议草案以及顺畅的预部署支持。
经验丰富的GPU云通常会在销售过程中配备技术工程师提供咨询,确保平滑的销售和部署体验。
部署前的准备阶段至关重要,领先的GPU云允许用户提前将数据迁移到集群中,显著缩短"实现价值的时间"。
提供商应收集足够的信息并提出关键问题,以避免意外障碍。部署过程本身需要高度自动化,确保集群按时交付且无人工错误。
交付的集群应完成烧机测试,测试流程和验收标准最好公开在官网或会议演讲中。实例重启后所有系统应自动恢复,无需手动操作如重新挂载网络文件系统。
在主要工作阶段,由于GPU的故障率高于传统CPU服务器,强大的支持服务必不可少。H100/H200可能出现软硬件故障,MI300x的故障率更高。
顶级GPU云会明确沟通故障情况、调试步骤和修复预计时间。对于1-2个GPU节点的故障,它们能在90秒内快速替换节点,确保客户无需等待排障。
公平的停机补偿也很重要,因为单个GPU服务器的不可用可能导致整个训练集群停摆。
最后是退出阶段,评估是否存在供应商锁定。Hyperscaler通常通过高出口费阻止客户迁移,而大多数Neocloud不收取数据迁移费用。
大多数客户在训练和推理任务中对调度系统的需求不同:
顶级GPU云提供商(如CoreWeave)提供开箱即用的托管Slurm和Kubernetes,大幅缩短用户从部署到实际训练的时间。
例如,Meta和Jane Street等公司即使拥有强大的内部技术团队,仍选择CoreWeave的托管Slurm,以减少基础设施管理负担。
然而,部分提供商的Slurm解决方案存在明显缺陷:
OpenAI是少数例外,因其对AGI安全的极端要求,选择完全自建调度系统。
高效的存储解决方案对训练和推理至关重要,主要涉及两类需求:
用户常见痛点包括:
优化后的存储(如Crusoe的测试数据)在扩展至多节点时仍保持稳定性能。
存储性能直接影响训练效率:
部分新兴GPU云因成本考量使用低效存储方案,导致客户实际训练效率远低于理论值。
选择GPU云服务时,必须对NCCL/RCCL网络性能进行全面验证。
提供商应提供开箱即用的测试脚本,确保用户能独立验证网络性能,特别是在实际训练中常见的16MiB至512MiB消息大小范围内。
网络性能的实际表现不仅取决于标称带宽(如400G),还与网络是否无阻塞、是否采用InfiniBand或以太网、使用的NIC和交换机型号以及配置优化密切相关。
例如,采用ConnectX-7 NIC的网络通常表现最佳,而经过良好调优的Spectrum-X以太网(如OCI的部署)也能接近InfiniBand性能。
InfiniBand在启用SHARP(网络内聚合)时表现最优,但目前全球仅CoreWeave、Azure和Firmus/Sustainable Metal Cloud三家提供商正确配置了SHARP。
网络拓扑对性能影响显著。即使是无阻塞网络,更大的单跳Rail优化Pod(如OCI的32服务器Pod)能减少跨Pod流量,从而降低拥塞。
相比之下,GCP的a3-ultra仅支持4节点Rail Pod,导致更高的跳数和性能损失。
此外,租户节点的拓扑感知分配(如Kubernetes拓扑或Slurm的topology.conf配置)可提升性能20-30%,即使在小规模或全集群负载下也有效。
对于以太网部署,交换机质量至关重要。采用Arista EOS等成熟网络操作系统的交换机性能显著优于白盒解决方案。
用户应关注提供商是否公开网络调优细节(如NCCL版本兼容性)。例如,OCI在NCCL 2.21.5后出现性能回归,需定制插件修复。
可靠性的核心在于明确定义的SLA,涵盖节点故障、网络中断(如链路抖动)、硬件/软件问题(如NCCL超时)等场景。
模糊的SLA可能导致提供商声称满足99%可用性,但实际因微秒级NIC抖动导致训练任务频繁挂起(需数分钟恢复)。
顶级提供商会明确服务补偿机制,包括积分返还条件和处理时效。
热备节点是减少宕机时间的关键。例如,CoreWeave能在90秒内替换故障节点,而无需用户等待排障。
对于训练任务,单节点故障可能导致整个集群停摆,因此快速恢复至关重要。
集群部署前的烧机测试是可靠性的基础。仅运行LINPACK不足以模拟实际负载,应使用更贴近ML训练的测试(如NCCL-tests、Megatron收敛测试)。
CoreWeave公开的烧机流程包括高温环境下持续3-4周的节点和网络压力测试,以筛选早期故障硬件。
监控与透明度方面,顶级提供商会提供实时仪表盘,展示节点健康状态(如GPU温度、NVLink错误、IB链路状态)。
例如,CoreWeave通过DCGM_FI_PROF_PIPE_TENSOR_ACTIVE估算TFLOP/s,并关联性能下降事件(如PCIe故障或IB链路抖动)。
用户还需关注存储挂载稳定性,避免因随机卸载导致数据不可用。
被动健康检查(如XID错误监控)和主动检查(每周自动运行dcgm diag、NCCL-tests、TinyMeg2防静默数据损坏)是顶级服务的标配。
缺乏这些功能的提供商(如部分Bronze级)需依赖人工干预,增加了运维复杂度。
GPU租赁的消费模式、定价与可用性是用户选择服务时的关键考量因素。
目前市场主要有三种消费模式:按需(On-demand)、抢占式(Spot)和合约(Contract/Reserved)。
按需模式根据实际使用时长计费,灵活性最高但价格也最贵,典型价格为每小时2.99美元每GPU,适合开发、突发推理或业余项目。
抢占式模式价格更低(1.0-2.0美元每小时),但服务可能随时被中断,适合能容忍中断的批处理作业或推理负载,不适合训练任务。
长期合约模式锁定固定价格,期限从1个月到3年不等,适合稳定性要求高的场景,但随着H100/H200供应充足,1年以上的合约已大幅减少。
定价方面存在显著差异。Hyperscaler如AWS、Azure通常定价高于Neocloud,主要面向企业客户;
而新兴Neocloud如Nebius通过ODM服务器降低成本,提供极具竞争力的价格(如1.5美元每小时)。
值得注意的是,Nebius还推出首1000小时每月特惠价,吸引中小规模项目。Oracle在Hyperscaler中定价最低,平衡了企业级安全与成本效益。
可用性成为竞争焦点。顶级提供商如Nebius和Crusoe能在2天内快速部署128 GPU集群,而CoreWeave专注于服务长期租赁的大客户。
部分Neocloud采用"空闲容量转售"策略,以折扣价提供资源但保留7天内回收的权利。Hyperscaler如GCP和AWS则提供"容量块"预定服务,确保资源可用性。
从供应商角度看,长期合约更有利可图,能抵御技术迭代带来的降价风险;但对客户而言,短期合约更灵活,能享受新一代GPU的性能红利。
这种矛盾在Blackwell GPU上市后将更加凸显,正如NVIDIA CEO所言"Blackwell量产后H100将无人问津"。
区域价格差异也值得关注。印度政府通过拍卖机制将H100价格压至1.6美元每小时(1年合约),欧洲和亚太地区则因数据驻留要求通常比美国贵10-15%。
新兴GPU云数量已超100家,每月都有新进入者,进一步加剧价格竞争。
NVIDIA通过"NVIDIA Cloud Partner(NCP)"计划帮助符合要求的GPU云提供商获得技术支持与销售资源,确保其服务达到高标准。
获得NCP认证的提供商通常性能更优,例如CoreWeave、Nebius、Crusoe和Lambda Labs等,这些公司大多属于ClusterMAX™铂金或黄金级别。
Jensen Huang投资的GPU云公司包括TogetherAI、CoreWeave、Nebius、Crusoe和Lambda Labs,这些公司在用户体验和性能上表现较好。
相比之下,AMD投资的GPU云公司在用户体验上普遍较差,未能达到ClusterMAX™银级或更高级别。
部分"AMD Alliance Instinct Cloud Partners"甚至缺乏基本的安全认证(如SOC2),因此AMD需要加强合作伙伴的审核标准。
部分GPU云公司通过购买SchedMD(Slurm开发公司)的技术支持来优化资源管理,提升用户体验。
AMD应确保所有"Alliance Instinct Cloud Partners"达到SOC2安全认证,并在新合作伙伴加入前进行严格审核。
此外,AMD需改进Slurm对容器的支持,例如提供类似Pyxis的插件,以简化用户在Slurm环境中运行容器的流程。
目前AMD的内部脚本因缺乏这一功能而显得混乱。
NVIDIA应公开详细的InfiniBand安全配置文档,包括SMKey、MKey、PKey、VSKey、CCKey和AMKey等关键设置,帮助GPU云提供商正确配置网络安全性。
同时,NVIDIA应推动对所有使用InfiniBand的GPU云进行安全审计,确保最佳实践得到落实。
NVIDIA还需优化SHARP(可扩展分层聚合协议)的易用性,目前仅有少数客户能正确配置并从中受益。
建议NVIDIA默认启用SHARP,并简化部署流程,以便更多用户能在训练和推理任务中利用其性能优势。
此外,NVIDIA应对GCP、AWS和Oracle等超大规模云提供商的网络性能进行回归测试,避免新版本NCCL发布时出现性能倒退问题。
例如,自NCCL 2.21.5以来,某些云环境在升级后出现了性能下降。
目前唯一达到Platinum级别的GPU云服务提供商是CoreWeave。CoreWeave在多个关键领域展现出卓越能力,成为行业标杆。
CoreWeave是唯一能够可靠运营超大规模集群的非超大规模云服务商,其管理的H100集群规模超过10,000块GPU。
这种能力使其在技术复杂性和运维成熟度上远超其他新兴GPU云服务商。
在安全性方面,CoreWeave早期采用的多租户Kubernetes命名空间隔离方案(CoreWeave Classic)已被淘汰,转而采用更安全的单租户Kubernetes集群模式。
这种模式为每个租户分配独立的Kubernetes集群,有效防范容器逃逸漏洞带来的安全风险。
CoreWeave的集群生命周期管理极具特色。在集群部署阶段,所有节点都需通过严格的烧机测试,包括高温环境下的NCCL测试和ib_write_bw带宽验证。
任何不符合性能标准的节点都会被自动隔离检修。
集群运行期间,CoreWeave实施了全面的被动健康检查系统,持续监控GPU总线状态、PCIe错误、网络链路波动等关键指标。
同时,系统会每周自动执行主动健康检查,包括:
这些检查结果会实时反映在可视化仪表板中,客户可以清晰看到节点健康状态、温度变化对性能的影响,
以及各类告警事件(如PCIe故障导致TFLOP/s下降)的关联分析。
在调度系统方面,CoreWeave提供开箱即用的托管Slurm和Kubernetes解决方案。
其Slurm in Kubernetes(SUNK)架构允许客户在统一环境中调度训练和推理任务。该方案包含自动生成的拓扑配置,确保NCCL集体通信性能优化。
网络性能是CoreWeave的另一大优势。
作为全球少数几家正确配置InfiniBand SHARP(可扩展分层聚合协议)的服务商,CoreWeave能够实现网络内聚合计算,显著提升大规模训练的通信效率。
虽然目前仅有少数客户能充分利用这一功能,但这展现了其技术前瞻性。
CoreWeave的监控体系极为完善。除了基础指标外,还开发了NCCL性能分析插件,帮助客户识别通信瓶颈。
其节点控制器能自动隔离异常节点,并在90秒内提供热备节点替换,最大限度减少训练中断时间。
这些技术创新使得CoreWeave成为Meta、Jane Street等技术密集型企业的首选。其客户可以专注于模型开发,而无需耗费精力处理底层基础设施问题。
不过需要注意的是,CoreWeave主要面向长期租赁的大规模集群客户,短期租赁需求可能需要考虑Nebius或Crusoe等灵活性更高的服务商。
CrusoeCrusoe在过去七个月的表现令人印象深刻,其控制台UI简洁易用,显著简化了资源管理和部署。用户友好的仪表盘在GPU云市场中树立了高标准。
在遇到GPU总线错误时,Crusoe能自动检测问题并预留备用节点,同时指导用户完成迁移,这种健壮的故障管理提升了用户体验。
Crusoe最初缺乏完全托管的Slurm解决方案,用户需通过Terraform脚本手动设置Slurm集群,
但他们的白手套服务弥补了这一不足,工程师亲自处理Slurm部署,确保顺利运行。
最近在GTC上,Crusoe宣布了全新的托管Slurm产品“Auto Clusters”,承诺进一步简化用户工作流并消除手动部署的复杂性。
该产品还包含自动生成的Slurm拓扑配置,以优化NCCL性能,并在检测到不健康节点时自动替换。
Crusoe已提供完全托管的Kubernetes服务,用户可轻松部署和扩展容器化工作负载。
在监控和可靠性方面,Crusoe目前仅实施基本的被动健康检查,尚未引入自动化的每周主动健康检查(如dcgm诊断、nccl-tests等),
但他们表示这一关键功能正在积极开发中,将很快集成到托管Slurm和Kubernetes产品中,目标是达到CoreWeave的健康检查水平。
在定价和合同条款方面,Crusoe提供具有竞争力的中短期合同,适合初创企业和部分企业客户。
虽然价格和条款不如Nebius优惠,但对于追求简化UI和用户体验的快速发展的初创公司来说,Crusoe仍具竞争力。
NebiusNebius以市场最低价格著称,这得益于其强大的财务状况。
凭借数十亿美元的资产负债表且无债务负担,Nebius拥有充足的财务资源和灵活的业务发展空间。
例如,他们创新性地提供将H100合约无缝过渡到B200部署的服务,并通过在圣克拉拉大量投放广告来提升品牌认知度。
Nebius的关键策略之一是采用定制化原始设计制造商(ODM)机箱。
通过内部设计硬件并直接与ODM合作,Nebius绕过了传统OEM供应商(如戴尔或超微),将毛利率从典型的10-15%降至约2%,
大幅降低了初始硬件投资和持续运营成本(如电力消耗)。这种成本效率使Nebius在非Hyperscaler提供商中独树一帜。
然而,由于其前身为俄罗斯云服务商的背景,Nebius拥有一支技术精湛的工程师团队,但在用户体验方面仍显不足。
尽管Nebius的按需H100 SXM GPU价格低至每小时1.50美元(至少每月前1000 GPU小时),
许多用户仍倾向于选择Lambda Labs,主要因为Nebius的UI和用户体验过于复杂且不直观。
Nebius目前提供完全托管的Kubernetes解决方案,但尚未推出完全自动化的托管Slurm产品。
他们正在开发“Soperator”Slurm解决方案,包含基础的被动和主动健康检查,但尚未达到CoreWeave等行业领先标准的水平。
为提升竞争力,Nebius需进一步投资于全面的每周计划健康检查,并推出高级的Grafana仪表盘。
Oracle Cloud Infrastructure (OCI)OCI在测试中展现出强大的GPU体验,被广泛认为是四大Hyperscaler中性价比最高的选择。
其GPU服务通过OCI市场提供一键部署的“OCI HPC Stack”,涵盖Slurm和监控功能。
然而,OCI的Slurm解决方案目前并非完全托管,仍需一到两名OCI解决方案架构师提供支持。
OCI在监控和可靠性方面表现良好,其Slurm HPC Stack市场产品包含DCGM、Grafana监控和被动健康检查。
然而,OCI目前缺乏高级主动健康检查和自动化节点生命周期管理功能(如每周计划的nccl-tests、ib_write_bw等)。
OCI已确认这些功能正在开发中,预计在第二季度完成。
OCI的另一个亮点是其自动化拓扑配置(topology.conf),支持拓扑感知调度以提升网络性能,这是许多新兴GPU云提供商尚未重视的功能。
OCI的RoCE网络性能经过优化,与Spectrum-X以太网竞争激烈,但在某些NCCL版本上仍存在性能回归问题。
OCI的支持和服务团队以技术专业性和客户为中心的态度著称。
作为Hyperscaler,OCI还提供数据库、对象存储和CPU虚拟机等全套服务,无需客户在不同云平台间迁移数据。
此外,长期租赁OCI计算资源通常附带市场合作机会,帮助客户扩展业务。
在安全性方面,OCI表现出色,提供企业级标准,包括强大的租户网络隔离、VLAN隔离(RoCEv2结构)和PKEY隔离(InfiniBand结构)。
相比之下,许多GPU云提供商甚至缺乏SOC2或ISO27001认证等基本安全措施。
TogetherAITogetherAI在GPU云市场中表现突出,其集群服务本身已达到ClusterMAX™ Silver水平,但凭借卓越的支持和技术专长,最终被评为Gold级。
TogetherAI的团队由Flash Attention的发明者Tri Dao领导,其Together Kernel Collection(TKC)显著提升了客户性能。
TogetherAI提供直观的托管Slurm和Kubernetes解决方案,用户可通过仪表盘轻松部署。
作为NVIDIA的合作伙伴,TogetherAI能早期获取新硬件(如Blackwell GPU),并与NVIDIA合作开发优化内核。
然而,TogetherAI目前缺少Slurm环境中的Pyxis插件(容器管理),且缺乏全面的被动健康检查或每周计划的主动健康检查。
其默认的Grafana仪表盘也较为基础。建议TogetherAI参考CoreWeave的健康检查系统,并开发更详细的监控仪表盘。
目前,TogetherAI依赖其他GPU云提供商(如Applied Digital或Crusoe)的基础设施,导致问题解决可能因中间环节而延迟。
但TogetherAI计划在今年内部署自有硬件,以消除对外部供应商的依赖。
LeptonAILeptonAI由PyTorch联合创始人创建,不直接拥有GPU,而是提供ML平台软件层来管理GPU和健康检查。
用户可选择通过LeptonAI租赁GPU(他们从其他提供商处租用并加收少量费用),或直接从Nebius等提供商租用GPU,再购买LeptonAI的平台支持。
LeptonAI为训练任务提供类似Slurm的作业提交方式,用户只需稍作调整即可适配其平台。
其控制台仪表盘提供节点生命周期的可视化,仅CoreWeave的仪表盘更胜一筹。
在被动健康检查方面,LeptonAI运行其开源解决方案“gpud”,覆盖大多数被动检查项目。
此外,LeptonAI还支持手动主动健康检查(如DCGM诊断和nccl-tests),但未提供每周自动计划检查或参考性能数据。
LeptonAI的Beta功能包括零影响NCCL分析器,用户可通过勾选复选框启用,帮助可视化集体操作瓶颈并优化网络性能。
银级GPU提供商在性能、安全和价值方面表现尚可,但与金级或铂金级相比存在明显差距。
这些提供商通常能满足基本行业标准,但在高级编排集成、网络性能或总拥有成本(TCO)方面有所不足,导致客户体验不够理想。
银级提供商对客户反馈较为开放,并积极寻求改进,未来有望向金级或铂金级迈进。
AWS
AWS的GPU云基础设施在可靠性方面表现稳健,但其网络性能长期落后于InfiniBand和Spectrum-X以太网。
尽管AWS通过EFAv3网络改进(如p5en实例的16×200GbE H200)缩小了差距,但在实际NCCL测试中仍不及顶级方案。
AWS提供名为Hyperpod的托管Slurm和Kubernetes解决方案,简化了集群部署,但缺乏自动化的主动健康检查(如NCCL测试、TinyMeg2检测)。
此外,AWS的监控仪表板功能较为基础,建议参考CoreWeave的全面健康检查策略以提升可靠性。
Lambda Labs
Lambda Labs以按需GPU实例著称,尤其受开发者欢迎,但其用户体验存在明显短板。
例如,实例启动时间长达10分钟(Crusoe仅需30秒),且默认CUDA工具路径设置错误(应为/usr/local/cuda/bin/nvcc而非/usr/bin/nvcc)。
Lambda提供托管Kubernetes服务,但Slurm解决方案尚未完善,缺乏Pyxis插件等关键功能。
虽然其技术团队承诺改进,但目前仍缺乏自动化健康检查和高级监控仪表板。
Firmus/Sustainable Metal Cloud (SMC)*
SMC专注于可持续AI创新,采用浸没式冷却技术,宣称H100功耗低于风冷方案。
其在MLPerf训练中表现优异(如GPT-3 175B模型),但实际测试显示其GPU温度比标准风冷高10°C,导致性能降低1-2%。
SMC是少数支持InfiniBand SHARP的提供商之一,但客户因技术门槛未充分利用该功能。
主要问题包括:无自助部署选项、缺乏自动化健康检查,且未提供基础的Grafana仪表板。
Scaleway
Scaleway的Slurm和Kubernetes解决方案结合了VAST Data高性能文件系统,适合AI和HPC工作负载。
其技术团队对NVIDIA Pyxis插件等支持良好,但因使用镀金DGX Hopper机箱导致TCO较高。
Scaleway需改进之处包括:自助部署工具缺失、自动化健康检查未实现,以及基础监控功能不足(如GPU温度指标)。
其他银级提供商
部分银级提供商因功能不完善或近期才通过SOC2认证而被归入此类别。例如:
这一类别中的GPU云服务提供商虽然满足了基本要求,但在多个关键评估领域存在明显不足。
常见问题包括技术支持和专业知识参差不齐、网络性能较差、服务等级协议不够明确、与主流工具如Kubernetes或Slurm的集成有限,或者定价竞争力不足。
这些提供商通常需要进行重大改进才能提升可靠性和客户体验。
另一个导致GPU提供商落入这一评级层级的原因是过去几年提供的解决方案质量不佳。
部分提供商已经开始努力追赶,例如Google Cloud就是其中之一,
预计在未来3到6个月内,Google Cloud和其他一些提供商有望快速提升至ClusterMAX™ Gold或Platinum级别。
Google Cloud长期以来提供的GPU服务在网络性能和开箱即用功能方面表现不佳。自2023年4月起,Google Cloud一直处于"追赶"状态。
许多客户对其GPU服务表示不满,但Google Cloud Platform(GCP)正在积极听取反馈,快速改进并努力缩小与竞争对手的差距。
从历史背景来看,GCP最初的H100产品名为"a3-high",于2023年8月推出,每节点提供800Gbit/s的"Fastrak TCP"网络带宽。
当时,Oracle、Microsoft以及大多数Neocloud巨头和新兴Neocloud提供商都提供3.2Tbit/s的网络速度。这意味着GCP的网络带宽仅为竞争对手的25%。
大多数使用a3-high的GCP客户并不满意。我们将GCP GPU发展的这一阶段称为"完全不合格阶段"。
Google意识到了客户的反馈,随后推出了第二款改进的H100产品"a3-mega",将每节点的网络带宽从800Gbit/s提升至1.6Tbit/s"Fastrak TCP"。
虽然这是一个显著改进,但仍比Oracle、Microsoft、CoreWeave和AWS等竞争对手慢50%。
根据NCCL测试结果,在实际消息大小上,它们的性能是竞争对手的两倍慢。
在端到端训练性能上,由于网络NCCL性能慢两倍,导致在Llama 70B规模训练中MFU降低10%,在8x7B混合专家稀疏模型中MFU降低15-20%。
长期以来,这一产品不支持LL128协议,导致实际NCCL网络性能更差,需要用户设置复杂的环境变量才能让NCCL网络/调谐器插件正常工作。
此外,他们的Slurm方案存在漏洞且难以设置。我们将这一时期称为"追赶阶段",GCP显然在努力改进,但仍未达到竞争对手的水平。
GCP持续收集客户反馈,并于2025年1月推出了a3-ultra实例,最终每节点提供3.2Tbit/s的RDMA以太网网络与ConnectX-7网卡,有效提升了每节点的网络带宽。
这一更新使GCP更接近Oracle、Microsoft和CoreWeave等竞争对手的能力。在实践中,它们在实际NCCL集体网络性能上仍略逊一筹。
通过改用RDMA over Ethernet,GCP终于转向了行业更常用的GPU网络协议。
我们很高兴看到GCP最终采用了更符合行业标准的GPU网络设置,但这比竞争对手推出3.2Tbit/s RDMA网络产品晚了18个月。
我们将这一时期称为"几乎赶上阶段"。
需要注意的是,目前大多数GCP客户和GPU资源仍在使用A3-Mega,这意味着大多数客户仍然面临网络性能不佳的问题,使用A3-Mega时性能会降低10-20%。
到2025年中期,GCP将推出最新的A4 B200和A4X GB200实例,这些产品在纸面规格上将与AWS、Azure、OCI和其他提供3.6Tbit/s每GPU的Neocloud竞争。
GCP还将继续改进并推出新的软件功能,这些功能将树立行业标准。我们将这一时期称为"设定标准阶段"。
由于A3-High和A3-Mega的糟糕体验和性能,GCP在产品上失去了大量客户信任,这需要时间才能恢复。
我们相信到2025年中期,GCP将完成"追赶"阶段,很快将为行业树立标杆,并重新赢得客户信任。
我们认为Google GPU服务有望达到ClusterMAX™ Gold或Platinum级别。
2025年1月,我们联系了Google,向他们展示了我们的NCCL性能测试结果以及GCP客户向我们反馈的所有问题和投诉清单。
GCP团队非常重视这些反馈,并正在迅速解决问题。
他们首先承认A3-High和A3-Mega的网络性能不佳,这些产品构成了他们GPU资源的主体。
他们正在通过推出具有行业标准3.2Tbit/s每节点RDMA带宽的a3-ultra来解决这个问题。
对于即将推出的A4 B200和A4X GB200产品,它们将在纸面规格上与行业其他B200和GB200产品竞争。
A3-mega实例也缺少LL128协议,这意味着实际消息大小的NCCL性能受到影响。
2025年1月,他们向所有客户发布了修复程序,在a3-mega上启用LL128协议。A3-ultra默认支持LL128 NCCL协议,很高兴看到他们在新产品中有所改进。
A3-ultra的性能仍略逊于OCI以太网和Azure InfiniBand,但在端到端训练性能上,GCP仅比同类InfiniBand参考产品低1-2% MFU。
需要注意的是,GCP a3-ultra的每个rail组大小仍仅为4个节点,而在OCI、Azure和大多数Neocloud上为32个节点。
这意味着进行集体操作时需要更多跳数,导致更多拥塞和性能下降。我们将在NCCL深度解析文章中进一步解释这一点。
对于a3-mega,目前仍缺少NVLSTree NCCL算法。NVLSTree NCCL算法通过利用NVSwitch中的NVLS功能提升多节点网络集体性能。
他们目前正在努力实现这一功能。对于a3-ultra,他们已经默认支持NVLSTree & NVLS & RING & TREE & PAT算法,很高兴看到GCP在新产品中提供完整功能。
通过与GCP客户交流,所有人都抱怨需要花费精力正确设置NCCL环境变量并调试GCP网络/调谐器插件以确保其正常工作。
这会浪费昂贵的GPU时间,而客户却在调试NCCL环境变量,而在Azure和OCI上,NCCL开箱即用。
GCP承认这一反馈,正在研究如何简化这一体验。
客户还抱怨GCP不会自动为Slurm生成topology.conf文件以实现拓扑感知调度,而是让用户在sbatch脚本中手动进行拓扑排序。
GCP已接受这一反馈并在今年实施了修复。
第三个客户反馈是GCP目前没有全托管Slurm产品。GCP承认这一点并正在积极研究解决方案。
GCP目前有Cluster Toolkit,许多客户用它来管理集群,但目前没有基于GUI的设置选项,也不是托管服务,没有开箱即用的每周自动主动健康检查选项。
虽然Cluster Toolkit相比他们6个月前提供的非托管Slurm方案有了巨大改进,但仍缺少许多功能,比如托管服务。
第四个客户反馈是GCP正在通过指派专门工程师负责客户全生命周期支持来改进技术支持,从问题创建到解决全程负责。
目前GCP只是让一堆人参加电话会议,但客户真正需要的是他们的主题专家工程师"拥有"问题,从分类到热修复再到长期解决方案。
这种"让数十名产品经理和工程师"加入客户电话会议的问题不仅存在于GCP GPU服务,而是整个Google需要解决的问题。
需要注意的是,Google内部大多数团队都在TPU上进行GenAI训练和推理,因此GCP GPU体验与内部Google ML基础设施体验不同。
少数使用云GPU的Google内部团队之一是DeepMind的Isomorphic Labs。
尽管GCP客户与进行产品测试的GCP解决方案架构团队之间有紧密的反馈循环,但这种测试远不如AWS等公司全面,AWS以全面测试自家产品著称。
与OCI或CoreWeave不同,监控不是开箱即用设置的,尽管可以通过OpsAgent相对容易地设置监控仪表板,但远不如CoreWeave的高级Grafana仪表板和指标。
每个客户都想监控GPU,因此我们建议这应该开箱即用设置。
在健康检查方面,GCP确实在虚拟机上运行被动健康检查,但没有开箱即用的解决方案在空闲节点上运行每周计划的主动健康检查,不像CoreWeave和Nebius。
GCP确实有cluster-health-scanner,但它不是每周自动计划,也不是开箱即用的解决方案。
我们建议GCP花些时间和资金亲自试用Corewave SUNK产品,看看他们如何进行健康检查和监控。
GCP不仅是GPU云,还具有云服务的所有其他功能,如Bigtable、数据库、对象存储和并行文件系统产品,这些都是数据处理和网络爬虫所需要的。
作为一个完整的云,意味着你不需要将数据从"主要Hyperscaler云"复制(或流式传输)到Neocloud集群,所有数据都已经在那里。
在安全性方面,GCP的安全性是一流的,包括正确实施租户网络隔离和传输中加密。任何有严格安全要求的企业都应该选择Hyperscaler。
其他Bronze级别的提供商由于没有非测试版的Slurm和/或Kubernetes产品,
或者提供的Slurm和/或Kubernetes产品存在漏洞且未正确设置,而落入ClusterMAX™ Bronze级别。
我们已经向他们提供了反馈,大多数都接受了反馈,目前正在构建和推出Slurm和/或Kubernetes开箱即用产品。
一些ClusterMAX™ Bronze级别的提供商已经运行GPU云服务很长时间,但直到上个月才获得SOC2合规认证。
虽然我们很高兴他们现在有了SOC2合规认证,但由于他们刚刚获得认证,我们现在无法将他们评级更高。
值得一提的是,对于某些提供商,如DataCrunch的按需单节点产品,它非常适合开发工作。我们评估了DataCrunch的按需单节点产品,非常满意。
但遗憾的是,他们的生产集群不适合推理或训练。TensorWave也有测试版托管Slurm和托管Kubernetes产品,并正在开发被动和主动健康检查。
我们相信TensorWave的产品有潜力在下次评估时达到ClusterMAX™ Silver级别。
ClusterMAX™ UnderPerform Tier GPU Providers
这部分主要涵盖未能满足基本行业标准和关键评估指标的GPU云服务提供商。
这些提供商普遍存在显著问题,包括安全措施不足、可靠性差、技术支持有限以及误导性营销。
许多进入这一层级的提供商甚至缺乏基本的安全认证,如SOC2或ISO 27001。部分提供商虽然近期才获得SOC2认证,但由于时间较短,仍被归类于此。
安全是GPU租赁中的关键因素,用户通常存储价值数万至数百万美元的模型权重和专有数据,因此对安全要求极高。
在欧盟国家,数据泄露还可能面临GDPR的高额罚款。
一些提供商公开承认其服务存在安全和隐私风险,例如网络流量可能被第三方设备记录。这类公开声明进一步降低了用户信任。
Massed Compute是另一个典型例子,因其在互联网上大量发布AI生成的误导性SEO内容而进入此层级。
例如,搜索“H100 vs A100 L2 Cache”时,其错误信息(如声称H100 L2缓存为25MB)会出现在前列,这对技术社区造成负面影响。
这种行为不仅误导用户,还破坏了行业信息的准确性。
此外,部分提供商的网络驱动或GPU驱动配置不当,导致NCCL性能低下。
更严重的是,一些服务甚至未正确实现租户隔离(如VLAN或PKeys),存在潜在安全漏洞。
这些问题综合导致其服务无法满足基本的生产需求,仅适合开发或测试用途。
文章来自于微信公众号 “傅里叶的猫”,作者 :CC



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
