# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
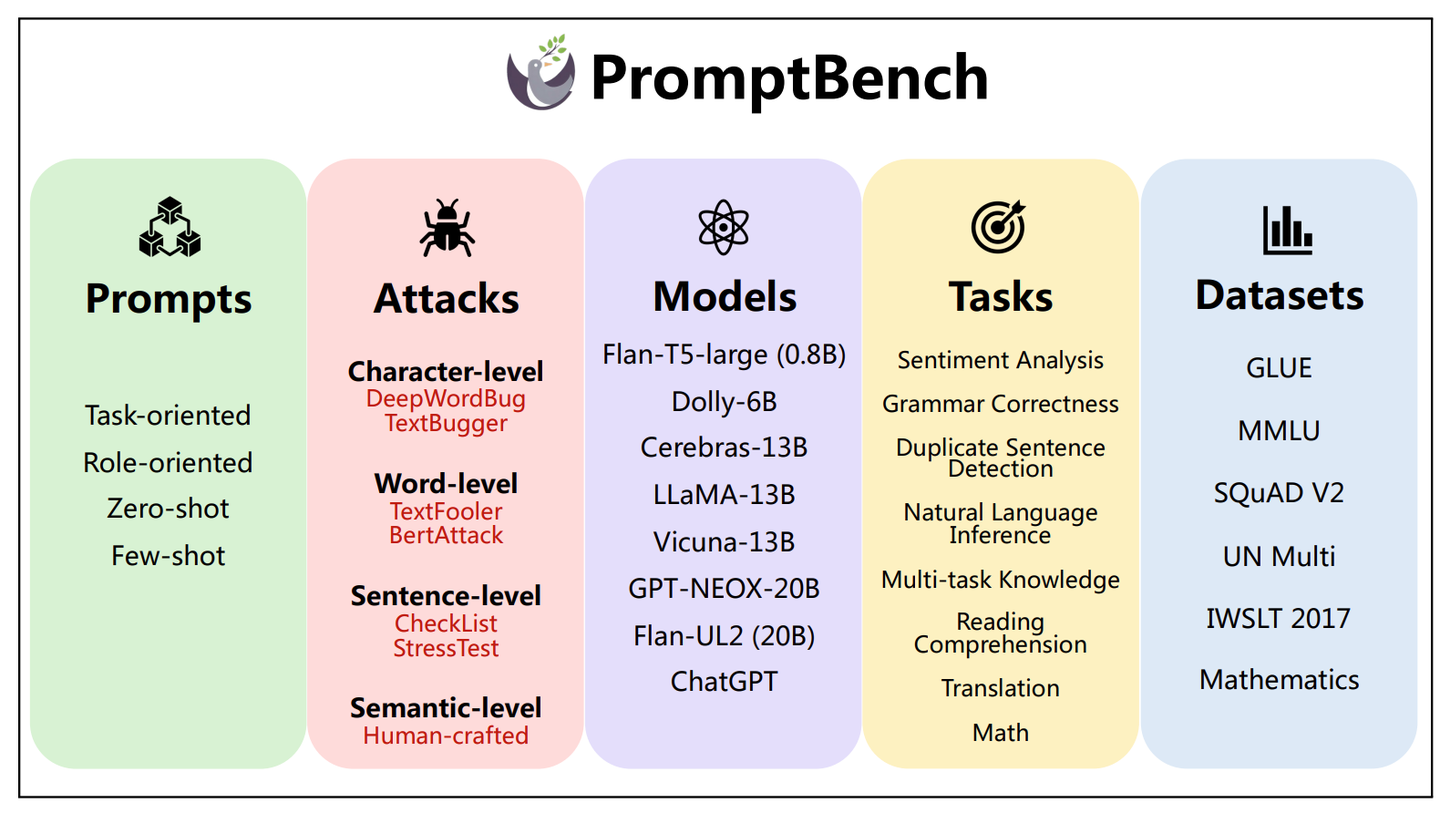
PromptBench已全面升级为大模型评测的代码库,最大限度地方便大家进行相关研究:pip install promptbench is all you need!
https://github.com/microsoft/promptbench
https://promptbench.readthedocs.io/en/latest/
作为连接人类与大模型的桥梁,大模型对 「Prompt (提示词)」 究竟有多敏感?同样的prompt,可能写错个单词、写法不一样,都会出现不一样的结果。到底该如何写合适的提示词?为了尝试回答这些问题,我们构建了 「PromptBench」,深入探究了大模型在处理对抗提示(adversarial prompts)的鲁棒性。此外,我们利用Attention「可视化分析」了对抗提示的输入关注分布,并且对不同模型产生的对抗提示进行看「迁移性分析」,最后对鲁棒提示和敏感提示的词频进行了分析,以帮助终端用户更好地写作prompt。

文章第一作者为微软亚洲研究院实习生朱凯捷,通讯作者为王晋东,其他作者分别来自中国科学院自动化研究所、卡内基梅隆大学、北京大学、西湖大学以及杜克大学。
大语言模型(简称LLMs)在各种任务中都表现得非常出色,无论是情感分析、问题回答还是逻辑推理,它们都能表现出惊人的性能,「甚至GPT4在诸多领域已经超越大部分人类」。
Prompt(提示词)是连接人类和LLMs的一座桥梁,帮助我们以自回归(Auto-regressive)的方法进行上下文学习(In-context Learning)。但是,我们发现 「LLMs通常对Prompt非常敏感」。例如,稍微改变一下示例的顺序,或者在文字中加入一点点的拼写错误,或者使用不同的词语但意思相同,都可能导致LLMs给出完全不同的结果。
虽然现在LLMs已经在学术界和工业界得到了广泛的应用,但是大家在评估LLMs的性能时,往往忽略了提示的鲁棒性。研究者们已经从多个角度对LLMs进行了评估,包括自然语言处理能力、伦理问题、鲁棒性和教育应用等等。在鲁棒性评估方面,比如我们的前一篇文章[1]就从对抗鲁棒性和分布外泛化的角度对一些主流的LLMs进行了评估,用到了一些现有的对抗文本的数据集(AdvGLUE等)。
然而,这些工作均未关注到「提示的鲁棒性」。「由于提示通常只与具体的任务相关」,它对同一任务的不同数据集、同一数据集内的不同样本都是通用的,因此,它的鲁棒性对LLMs的表现至关重要。
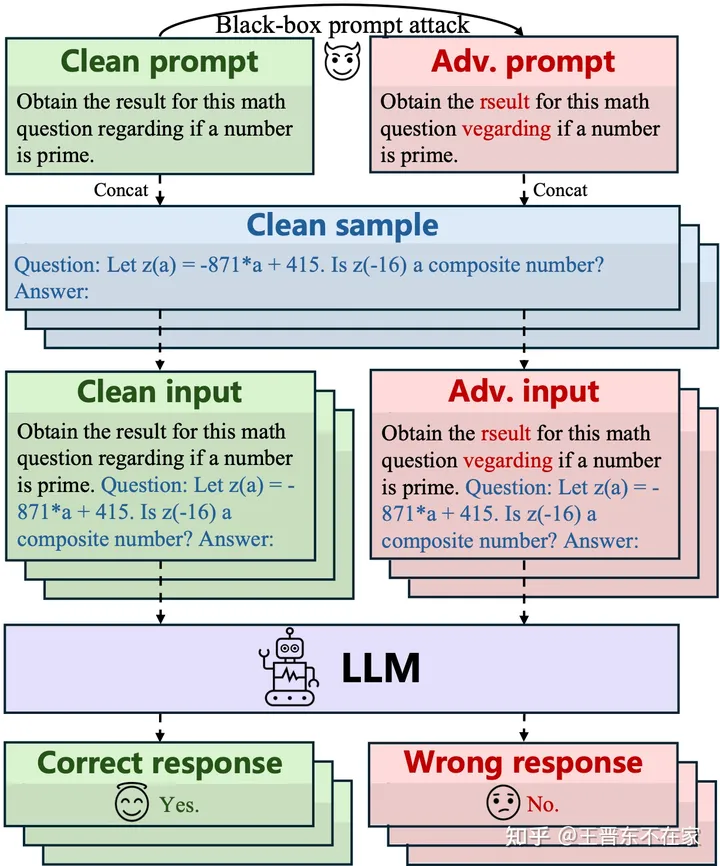
要了解提示攻击,先要更好地理解什么是提示。
在本研究中,我们将LLMs的输入定义为“提示+样本”([P, x]),其中提示P是我们给出的指令,样本x则是输入数据。例如,提示P可以为:“对这段文字的情感进行分析,并分类为‘积极’或者‘消极’:”,而样本x则为:“今天我很开心”。 二者结合为LLMs的输入:“对这段文字的情感进行分析,并分类为‘积极’或者‘消极’:今天我很开心”。 在各种LLMs的应用中,提示都是必不可少的部分,而样本“x”则可有可无。例如,输入给大模型的指令可以为:“帮我续写红楼梦后40回”,这里x就是被省略的。同时如我们在上面提到的,提示对同一任务「通用」,所以,一个不够鲁棒的提示可能会导致LLMs在安全相关的应用中的输出各种奇怪的文字(胡言乱语阶段)。
那么什么是Prompt attack呢?首先,我们需要了解NLP的文本对抗攻击(Textual Adversarial Attack)概念。简单而言,给定一个数据集D={(xi,yi)}i∈[N],文本的对抗攻击就是尝试通过对数据集力的每个样本xi进行微小的扰动,让LLMs在这些扰动后的样本上表现的糟糕,即:argmaxδ∈CL[fθ(x+δ),y],其中C为扰动的约束范围。
在我们的研究中,我们的提示攻击专注于找到「对抗提示,而不是数据集内的样本」。其定义如下:
「提示攻击(Prompt Attack)」 :在给定一个LLM fθ、一个数据集 D 和一个干净的提示 P,找到一个最坏的扰动δ,使得该扰动添加至 P 后,模型在扰动后提示和数据集上的预测上表现糟糕。即:
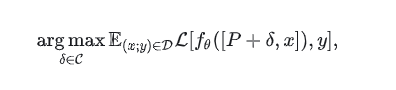
其中是添加到干净提示 P上的扰动,C则是扰动的约束范围。注意到,提示攻击和Universal Adversarial Perturbation(UAP)[2]和Universal Adversarial Trigger(UAT)很相似。本质上,提示也是一种“Universal”的东西,它与数据集 D里的所有样本结合输入至LLMs中。
考虑到大模型计算梯度的效率以及黑盒性(没错,说的就是你,ChatGPT),我们采用「黑盒攻击算法」(Black-box attacks)。我们的攻击涵盖了四个不同的层次,包括从简单的字符操作到复杂的语义修改。
CV领域中的对抗攻击要求生成的对抗样本人眼几乎难以察觉(imperceptible)。同样的,我们的提示攻击生成的「对抗提示也要求处于人类可接受的范围」。因此我们在攻击提示时,加强了对各个attack的语义约束(参考代码)。这也是为什么我们要使用黑盒攻击算法,因为黑盒通常操作于Word层面,而白盒攻击则操作在Token(Subword)层面,很有可能攻击后两个token组合的单词没有实际含义。同时,我们选取了五个志愿者(小白鼠)进行了一次人工测试,结果显示这些生成的提示至少有70%被人接受,这说明我们的攻击是现实的、有意义的。
我们选取了8种不同的NLP任务,包括:情感分析(SST-2)、语法错误识别(CoLA)、重复语句检测(QQP、MPRC)、自然语言推理(MNLI、QNLI、RTE、WNLI)、多任务知识(MMLU)、阅读理解(SQuAD V2)、翻译(UN Multi、IWSLT 2017)和数学(Mathematic)。
我们初步选取了8个模型进行测试,从小到大分别是:Flan-T5-large (0.8B)、Dolly-v1-6B、Cerebras-13B、LLaMa-13B、Vicuna-13B、GPT-NEOX-20B、Flan-UL2 (20B)、ChatGPT。经过我们测试, Dolly-v1-6B、Cerebras-13B、LLaMa-13B、GPT-NEOX-20B在部分数据集上的表现十分差劲(0%的准确率,详情请见我们的文章,Appendix D.2) ,因此,它们也就没有必要再进行攻击了。最终Flan-T5-large (0.8B)、Vicuna-13B、Flan-UL2 (20B)、ChatGPT胜出,获得被提示攻击的权利(bushi)。
本研究总共考虑「4种不同类别的提示」。首先根据提示的目的性,分为Task-oriented和Role-oriented,然后分别在Zeroshot和Fewshot两个不同的场景下进行测试。下图是4种不同种类的提示的一个示例。

考虑到各项任务的多样化评价指标以及模型和数据集的不同基线性能,绝对性能下降可能无法提供有意义的比较。因此,我们引入了一个统一的指标,即\emph{性能下降率}(PDR)。PDR量化了提示攻击后的相对性能下降,为比较不同的攻击、数据集和模型,我们提出了一个「规范化的衡量标准」,称为「性能下降率(Performance Drop Rate, PDR)」 ,其定义为:
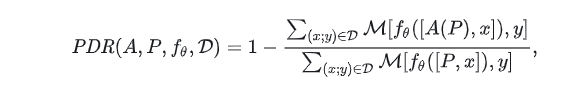
其中A是应用于提示P的对抗攻击,M[⋅]是评估函数:对于分类任务,M[⋅]是指示函数1[y^,y],当y^=y时,该函数等于1,否则等于0;对于阅读理解任务,M[⋅是F1分数;对于翻译任务,M[⋅]是Bleu指标。需要注意的是,负的PDR意味着对抗提示偶尔可以提升大模型的性能。
而平均性能下降率(Average PDR)则跟具体计算任务有关,我们会在主要结果中分别进行介绍。
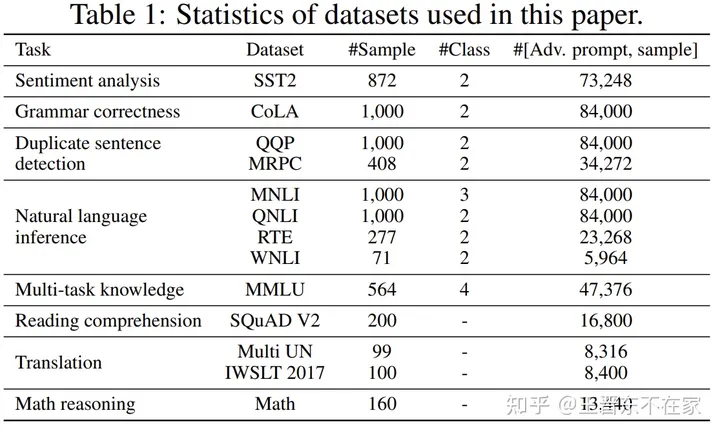
表1总结了在13个数据集上的7个攻击的APDR。其APDR的计算公式为
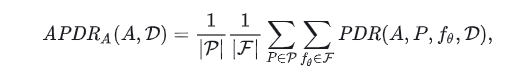
其中P是4种类型的提示的集合,F是4种模型的集合。
我们的研究结果得到了几个关键的结果。首先,「不同种类的攻击的有效性差距很大」,其中word-level的攻击最强,导致所有数据集的平均性能下降33%。字符级别的攻击排名第二,导致大部分数据集的性能下降20%。值得注意的是,语义级别的攻击与字符级别的攻击几乎具有相当的效力,这强调了微妙的语言变化对LLMs性能的深远影响。相反,句子级别的攻击威胁最小。此外,我们观察到在数据集之间,甚至在涉及相同任务的数据集中,APDR都有显著的变化。例如,对MMLU的StressTest攻击只导致性能下降3%,而在MRPC上则导致20%的下降。此外在QQP数据集中,StressTest攻击反而 「提高」了模型的鲁棒性。最后,同一种类的攻击方法对不同提示的攻击结果有较大的差异,从而产生了显著的标准差。需要注意的是,虽然字符级别的攻击可以通过语法检测工具来检测,但词级别和语义级别的攻击强调了对LLMs的鲁棒语义理解和准确的任务描述/翻译的重要性。
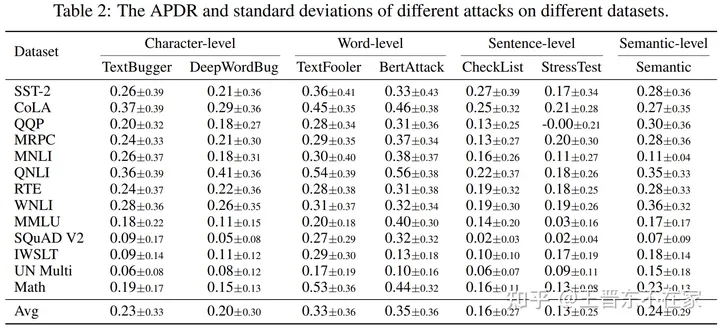
下表总结了4个LLMs在13个数据集上的APDR。 APDR的计算公式为
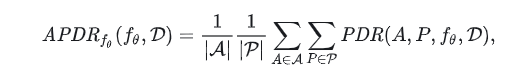
APDRfθ(fθ,D)=1|A|1|P|∑A∈A∑P∈PPDR(A,P,fθ,D),其中P是4种类型的提示的集合,A是13个攻击的集合。
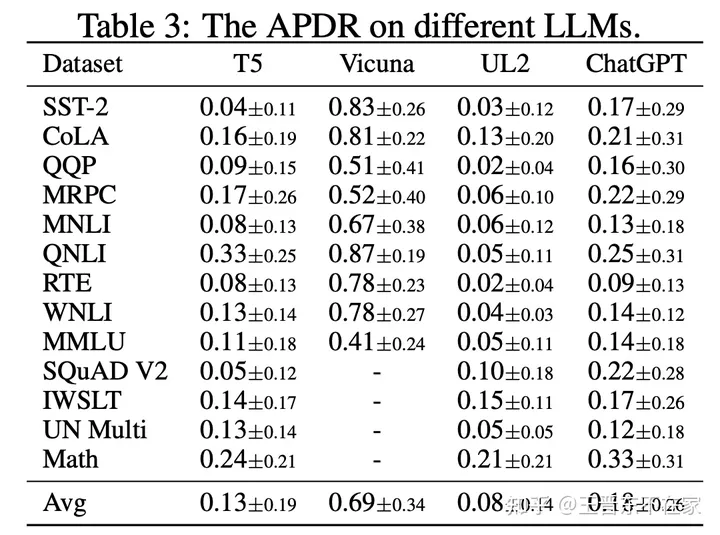
结果表明,UL2的鲁棒性明显优于其他模型,其次是T5和ChatGPT,Vicuna的鲁棒性最差。UL2、T5和ChatGPT的鲁棒性在各个数据集中都有所不同,UL2和T5在情感分类(SST-2)、大部分NLI任务以及阅读理解(SQuAD V2)的攻击中表现出较好的鲁棒性。具体来说,UL2在翻译任务中表现出色,而ChatGPT则在某些NLI任务中表现出很好的鲁棒性。然而,Vicuna在所有任务中都表现出对攻击的高度敏感性。需要注意的是,模型鲁棒性和大小之间似乎没有明显的关联。模型鲁棒性的差异可能源于采用的特定的微调技术。例如,UL2和T5都是在大型数据集上进行微调的,ChatGPT是通过RLHF微调的,它们的鲁棒性都优于Vicuna。这些发现鼓励我们进一步研究微调策略以提高鲁棒性。
下表总结了4种类型的提示在13个数据集上的APDR。 APDR的计算公式为
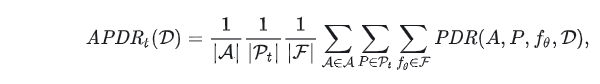
其中Pt是某种类型t的提示的集合,A是13个攻击的集合,F是4种模型的集合。
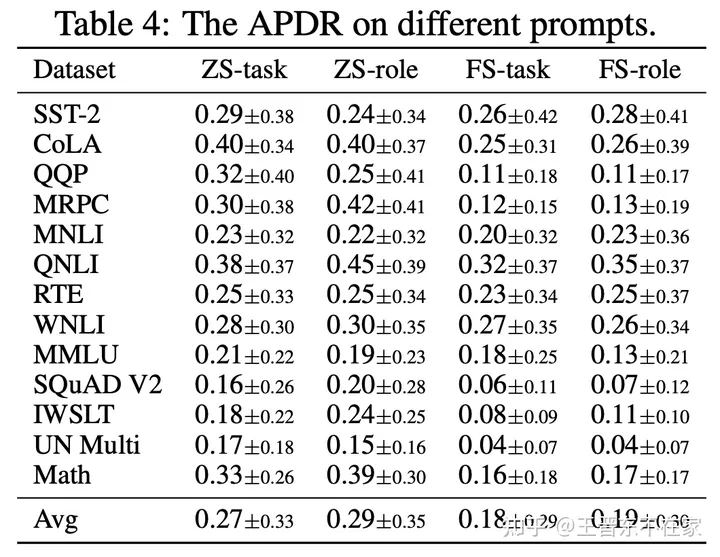
可以看到,少样本提示的鲁棒性在所有数据集上都要优于零样本提示。此外,虽然Task-oriented的提示在总体鲁棒性上稍微优于Role-oriented提示,但两者在不同的数据集和任务中都表现出各自的优点。Role-oriented提示在SST-2和QQP数据集中表现出更强的鲁棒性,而Task-oriented提示在MRPC、QNLI、SQuAD V2和IWSLT数据集中表现出更强的鲁棒性。
为了进一步的理解对抗提示,我们分析了对抗提示为什么会导致错误输出。我们发现,对抗提示的错误输出分为两部分,第一部分是“错误分类”:即模型的输出仍然处于预设的Label set内,只是分类错误。第二部分是“无意义的回复”:即模型在“胡言乱语”,表明它已无法理解我们的输入以及指示了。更进一步的,我们对输入进行可视化(Attention
Visualization,类似于Grad-cam),我们实现了两种不同类型的输入可视化,分别是“Attention by Gradient”和“Attention by Deletion”,其中“Attention by Deletion”不需要获取模型的梯度(代码见我们的Github,算法见论文Appendix F)。这两者得到的结果类似,在此我们只展示“Attention by Gradient”的结果,如下所示。

可以看出:
迁移结果如图所示。总的来说,我们观察到,虽然对抗提示在一定程度上表现出可转移性,但与前面图XXX相比,其影响相对较小。具体来说,源模型的对抗提示在目标模型中得到的APDR与源模型的原始APDR相比,要小很多。此外,APDR的标准差往往大于其均值,这表明不同对抗提示的迁移性十分不一致。一些敌对提示可以成功地转移,导致性能下降,而其他的可能会出人意料地提高目标模型的性能。一个典型的例子是从UL2到Vicuna的BertAttack转移,结果是−0.70(3.18)
的值,这暗示在接受这些敌对提示的影响时,Vicuna的性能出乎意料地提高了。这些现象共同说明了不同模型的鲁棒性是十分复杂的。相比之下,T5和UL2对ChatGPT的迁移性相对较好。这表明了我们可以通过在像T5这样的小型模型上训练,产生对抗提示,以攻击如ChatGPT这样的黑盒模型。这可以用于未来的鲁棒性研究。

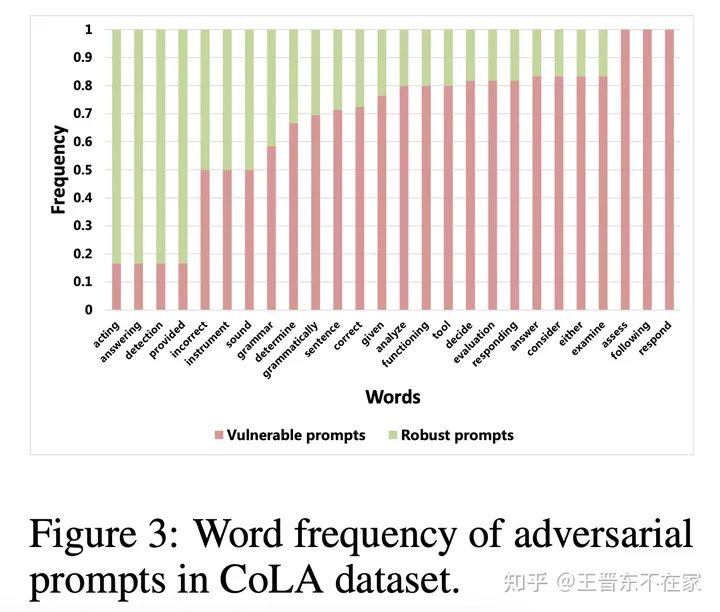
识别可能影响鲁棒性的提示中的频繁出现的模式对于研究人员和终端用户都至关重要。我们对此进行了初步的词频分析。
我们将提示分为两类:一是易受攻击的提示,即会导致性能下降超过10%
的那些提升;二是鲁棒的提示,即性能下降10%
或更少的提示。我们的分析揭示了更易受攻击或抵抗攻击的词语。例如,在CoLA任务中,含有“acting”、“answering”和“detection”的提示似乎较不易受攻击。但含有像“analyze”、
“answer”和“assess”这样的词的提示似乎更易受攻击(参见图)。然而,这种情况并非对所有数据集都成立,例如,在MRPC数据集中,由于词频几乎相等,很难判断出哪些词语是鲁棒的(参见图)。
这项研究表明,一些词语和语言模式更易受到敌对扰动的影响,从而影响LLMs的性能。这样的结果可以为未来LLMs鲁棒性的研究提供信息,指导非专家用户写出更好的提示,并帮助开发针对对抗提示的防御策略。
鉴于前文所述的观察,这里讨论一些可能的对策。
[1] Wang, Jindong, et al. "On the robustness of chatgpt: An adversarial and out-of-distribution perspective." arXiv preprint arXiv:2302.12095 (2023).
[2] Moosavi-Dezfooli, Seyed-Mohsen, et al. "Universal adversarial perturbations." Proceedings of the IEEE conference on computer vision and pattern recognition.
文章来自于知乎 “王晋东不在家”,作者 “王晋东不在家”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
