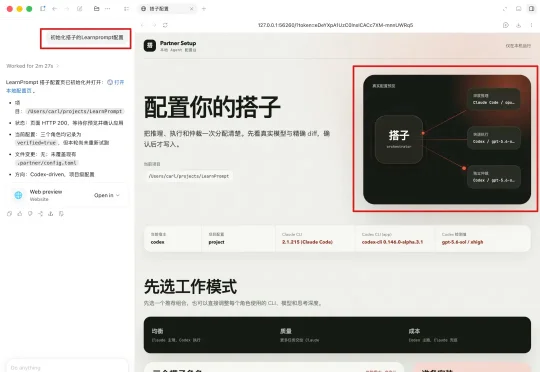
烧了一万块API后,我找到了同时适用于Fable5和GPT5.6的AI工作流
烧了一万块API后,我找到了同时适用于Fable5和GPT5.6的AI工作流就是上个月我开源的让Claude Code和Codex搭配使用的Skill搭子的1.4版,当时的定位是把Claude Code出计划然后直接在当前对话调用Codex,不需要复制黏贴,由Fable5自己写交接文档自己从CodeX那读取输出。
来自主题: AI资讯
8907 点击 2026-07-30 10:43
 搜索
搜索
就是上个月我开源的让Claude Code和Codex搭配使用的Skill搭子的1.4版,当时的定位是把Claude Code出计划然后直接在当前对话调用Codex,不需要复制黏贴,由Fable5自己写交接文档自己从CodeX那读取输出。

经常用AI的人都知道,AI给出的答案质量,很大程度上取决于你提问的方式。这一点,几乎成了当下社交媒体的流量密码。打开各大平台,随处可见兜售各类Prompt的帖子,我们自己的收藏夹里也往往躺着几十套Pr
本文作者 Eric Provencher,在 OpenAI 负责 Codex 开发者体验(DX),此前是 Repo Prompt 的作者。原文是 OpenAI 官方文档中的 Prompting 指南,以下为逐段中英对照翻译
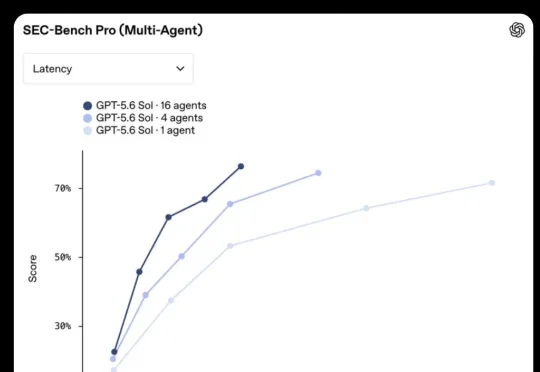
昨儿刚出的GPT-5.6,用不到一小时,就完成了一道存在了半个世纪的图论猜想证明。而这道题呢,来头也还真不小,就是大名鼎鼎的循环双覆盖猜想(Cycle Double Cover Conjecture)。
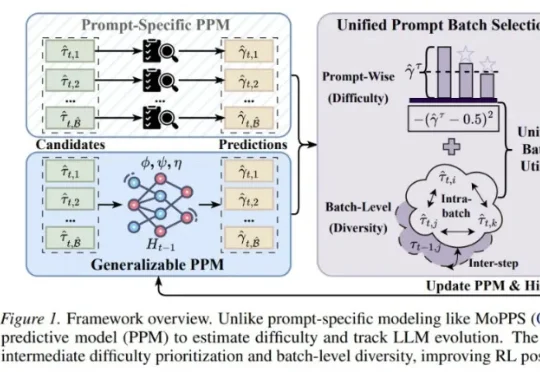
来自清华大学与腾讯的研究者提出了 Generalizable Predictive Prompt Selection(GPS)。GPS 的做法很直接:先训练一个小型、可泛化的 Prompt Predictive Model(PPM),让它预测不同 prompt 在当前模型下的难度;再根据难度和 batch 多样性选择训练样本,从而减少无效 rollout。
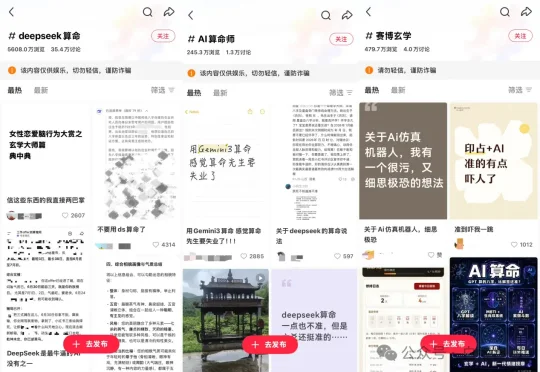
小红书上,#deepseek 算命、#赛博玄学等话题下,大量玄学爱好者聚集,分享不同占卜体系的prompt、交流 AI 算命心得,仅 #deepseek 算命一个话题,浏览量就达到 5608 万、讨论量 35.4 万;与此同时,更深度的 AI 用户开始在 GitHub 上自行开发占卜 Skills,搜索“astrology”“bazi”等关键词,可以看到相关项目最高 Star 数已达 3.9k。

现在的 AI Agent 动辄需要处理超长上下文,既要看系统提示词、工具说明,又要翻阅历史对话和检索文档。为了省钱、省算力并降低延迟,很多开发者会给系统加上 “提示词压缩”(Prompt Compression)模块,把冗长的上下文浓缩后再喂给大模型。

前段时间,我在网上刷到一本书,叫《人生设计课》,副标题是如何设计充实且快乐的人生。很有意思。说实话,按往常看到这种比较宏大的书名,像人生重启、职业发展等,我会默认是噱头直接划走。

整个周末我都在把额度刷刷刷满,剩下最后20%的时候在X上看到一个开发者发的一条长贴,他说他把Fable 5的行为模式,再结合Claude团队开源的Fable5提示语技巧,提炼成了一份协议,贴给Opus 4.8用,神人来的。

Prompt还没退场,Loop已经开始接管AI叙事。