# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025 年 3 月 11 日,语音生成初创公司 Cartesia 宣布完成 6400 万美元 A 轮融资,距其 2700 万美元种子轮融资仅过去不到 3 个月。
本轮融资由 Kleiner Perkins 领投,Lightspeed、Index、A*、Greycroft、Dell Technologies Capital 和 Samsung Ventures 等跟投。
Cartesia 还同时推出了其旗舰产品 Sonic 2.0,系统延迟从 90 毫秒缩短至 45 毫秒,为语音 AI 领域高效、实时且低成本的多模态交互提供了新动力。
Cartesia 的核心团队均来自 Stanford AI labs,包括 Karan Goel、Albert Gu、Arjun Desai、Brandon Yang 四位校友及其共同导师 Chris Ré。
团队共同的研究方向在于 SSM(状态空间模型)。
从 S4 到 Mamba 的 SSM 系列研究,以线性时间复杂度,为解决 LLMs 主流架构 Transformer 在上下文长度的固有局限提供了潜在解决方案,
意味着更快的生成速度、更高的计算效率,特别在文本之外的领域展现出巨大潜力,如音频和遗传学。
而在语音市场,从 GTM 到 CX 的 Sales Agent 及内容创作一直是我们长期关注的领域,
此前我们已经介绍过 decagon、11x.ai、sierra 等公司,其都离不开 voice model 的必要基建,这正是 Cartesia 所专注的方向。
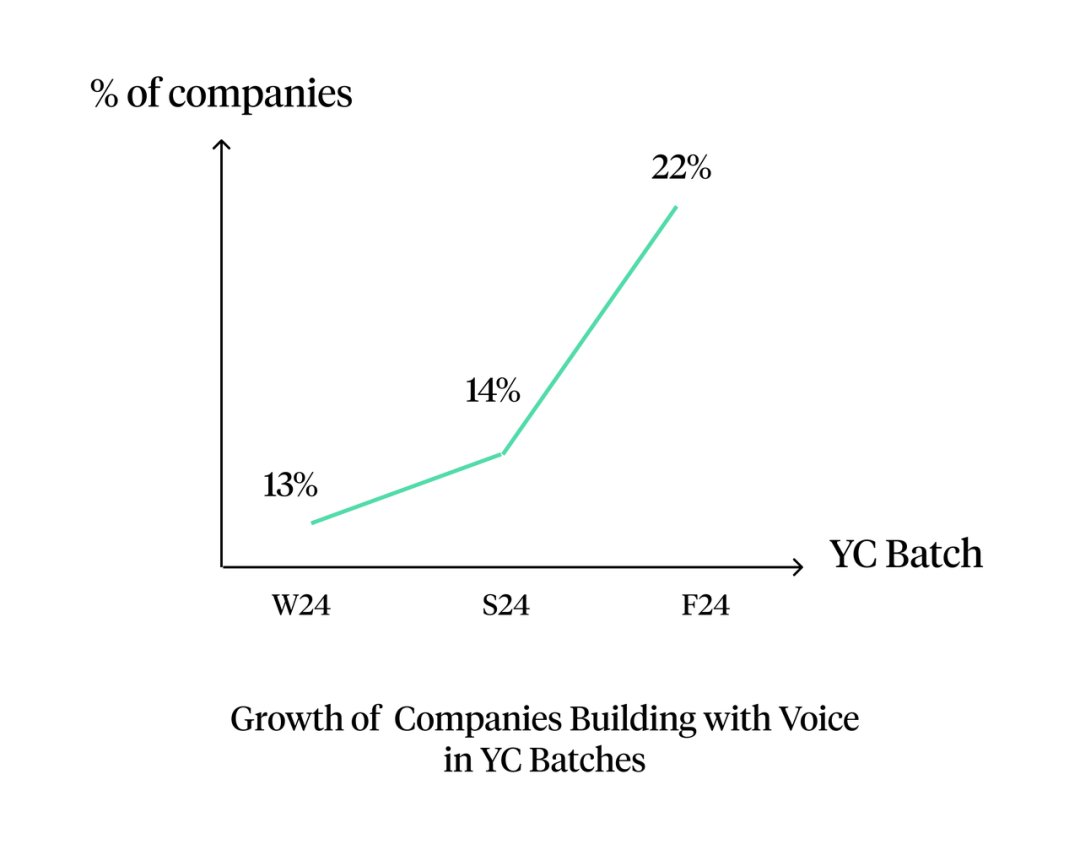
目前,Y Combinator 的冬季和秋季孵化项目中,voice-native 公司数量已增长了 70%,能够替代真人的 voice agent 依赖于高质量声音与精准克隆的 TTS 技术。
可以说,在 Gen AI 时代,场景多元的通用技术 TTS 非常重要。
凭借基于 SSM 架构的“高语音质量+低延迟”优势,以 Mamba 作为重要技术路线的 Cartesia 推出的 Sonic API、Sonic On-Device 等语音产品,
正在持续扩大其在语音市场的份额。本文是我们对 Transformer 到 SSM 等异类架构的复盘,也是对 Cartesia 多模态想象力到商业变现价值的讨论。
目录
01 从 Transformer 到 Mamba
02 Cartesia - Mamba 架构的代言人
03 团队及融资
04 市场
Post-transformer Architectures
Transformer 自诞生起,便快速发展为 LLM 时代主流架构。
无论独角兽 OpenAI GPT 系列、Anthropic Claude,还是开源阵营的 Meta LLaMA等,以及 2025 年崭露头角的 DeepSeek,均广泛使用 Transformer 架构。
然而,随着模型规模扩大,Transformer 二次复杂度的固有局限日益凸显。
其自注意力机制的计算与存储复杂度均为 O(n²),对于一个具有 L 层、隐藏维度 d 的标准模型,总时间复杂度更达到 O(L * n² * d)。
这一瓶颈直接限制了主流大语言模型的应用场景:
GPT-3、LLaMA、ChatGLM、BLOOM 等模型不得不将最大序列长度限制在 2048 或 4096 tokens,使得长文档处理、长音频转录等任务难以高效开展。
面对这一架构缺陷,业界发展出两条技术路线:
1)Transformer 框架内优化:通过 RAG、知识蒸馏、向量数据库等增强知识理解能力,
利用 MoE 等模型堆叠技术提升可扩展性,采用 LoRA 等低秩微调方法提高计算效率等。
2)Post-transformer architectures:自 2023 年起,LLM 领域的底层架构创新加速。
微软的 RetNet 、类 RNN 结构的 RWKV、 xLSTM 、基于层次化 CNN 的 UniRepLKNet ,以及基于 SSM 的 Mamba ,
都在中长序列建模、计算复杂度优化、注意力机制替代等方向取得突破。
其中,Mamba 备受关注。与 Transformer 的核心组件——完全注意力机制不同,Mamba 所代表的 SSM 架构是基于线性时间序列建模的低秩状态。
Transformer vs. Mamba:
融合而非替代
Mamba 于 2023 年 12 月由 Albert Gu 和 Tri Dao 提出,
与斯坦福 AI lab 的 Stanford Statistical Machine Learning (statsml) Group 的 SSM 研究体系息息相关,包括 HiPPO、S4 等研究成果。
Mamba 是在 S4 架构的基础上进一步优化,尤其通过 Selective Mechanism 提升计算效率,以及借鉴 FlashAttention 的并行扫描算法和面向 GPU 的硬件适配,
在保留 SSM 的循环计算特性基础上提升推理吞吐量,规避了传统卷积 SSM 的计算低效问题。
• SSM(State Space Model):状态空间模型起源于动态系统建模,广泛用于信号处理、控制系统等领域。
其核心思想是用状态向量描述系统的演化,使其能够有效建模长期依赖关系。
• HiPPO(High-order Polynomial Projection Operator):
2020 年斯坦福研究团队提出,通过多项式投影在状态空间中高效捕捉长距离依赖,为 SSM 和 S4 提供关键数学支撑。
• S4(Structured State Space Models for Sequences):
2022 年,由 Albert Gu、Karan Goel 和 Christopher Ré提出,基于结构化SSM,利用 HiPPO 矩阵捕捉长期依赖,计算复杂度为线性,适用于大规模长序列任务。
• FlashAttention:由 Tri Dao 领导的斯坦福团队提出,优化内存访问模式,降低显存占用,加速 Transformer 的自注意力计算,为 Mamba 的 GPU 适配提供基础。
与 Transformer 全局注意力不同,Mamba 以低秩状态表征序列信息,在长序列建模、计算效率与注意力机制替代方面展现出显著优势。
效率上看,同算力规模下,Mamba 具备Transfomer 5 倍的吞吐量。正如提出者 Albert Gu 所言,“Mamba 之名象征着极致速度、致命吸引力,以及核心机制 S4。”
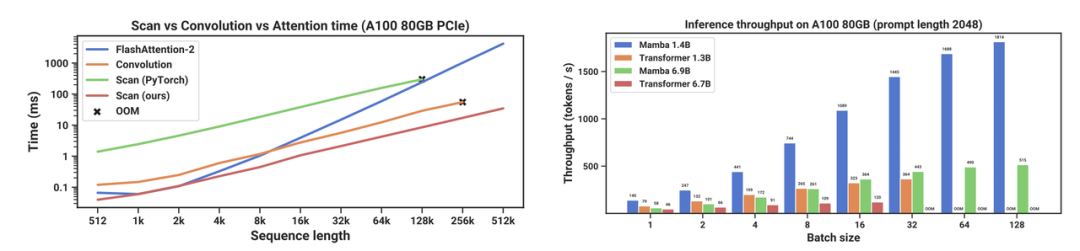
与 Transformer 相比,SSM 体系更多从物理学中得到灵感,包含更多的数学与系统理论。
Mamba 与 SSM 相关的研究也带着大量有趣的数学视角和值得探究的问题。
一方面,Albert Gu 和 Tri Dao 于 2024 年 5 月 31 日进一步发布状态空间对偶(SSD)框架的最新研究,包含了 SSM 和线性注意力之间的连接框架。
即 Transformers 与 Mamba 等 SSM 模型家族并非彼此孤立,两者实质上紧密关联,进一步揭示了 Transformer 与 SSM 之间的数学等价性。
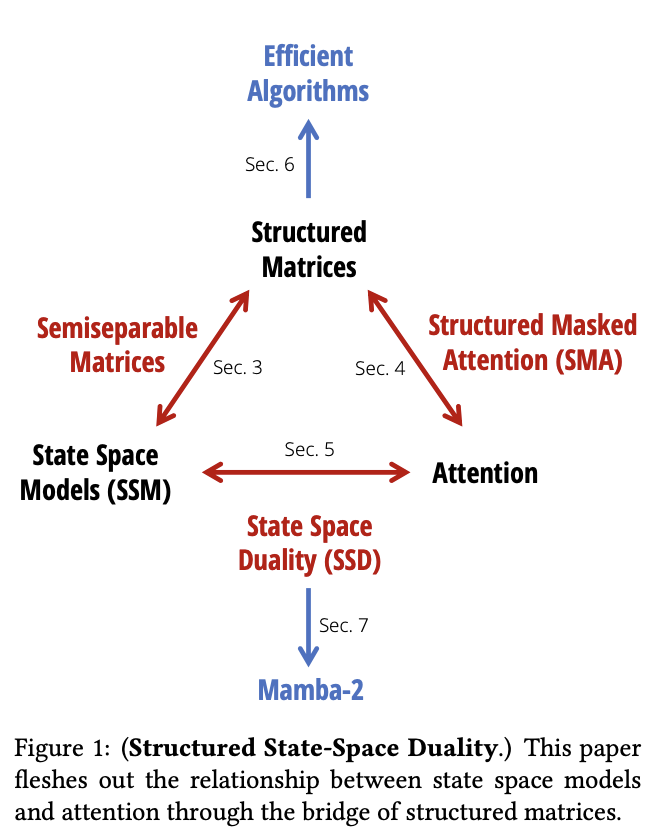
基于 SSD 新框架,团队设计了 Mamba-2 这一新架构,其核心层为 Mamba Selective SSM 的改进版本,状态数增加了 8 倍,训练速度提高了 50%。
另一方面,Hybrid-Mamba-Transformer 架构的业界关注与应用随其能力而提升。
近日发布的腾讯混元 T1、英伟达 Nemotron-H,均采用了 Hybrid-Mamba-Transformer 融合架构。
融合 SSM 的高效性与 Transformer 的强大建模能力,混合架构可能比单独使用其中任意一种模型更适配于终端任务,实现计算效率与表现力的平衡。
因而,从 Transformer 到 Mamba 的发展过程中,Mamba 并非简单替代方案,而是对 Transformer 注意力机制的融合与拓展。
追求更效率的算力利用与更快的速度,是 AI LLM 的必由之路。
Mamba 及 SS Architecture 开辟了 AI 发展的全新课题,带来一个 LM 性能潜在飞跃新可能、新思路、新方向。
或者,正如 Albert Gu 所说,“Even just the proof of concept”,也是一个对学界、开源、应用的良好信号。
Mamba 的应用之路
纯理论对比,Mamba 与 Transformer 似乎优劣分明, Mamba 具备线性复杂度、低延迟、低显存需求,但准确性可能低于 Transformer。
具体而言,Mamba 依靠 SSM 技术实现 O(N) 的线性计算复杂度,突破了 Transformer 在长序列任务上的性能瓶颈,具备更好的扩展性。
然而,由于其使用低秩注意力表达和递归状态更新,导致信息交互能力弱于 Transformer,存在丢失信息的风险,
在生成任务和某些 NLP 任务上可能会表现出较低的准确性。
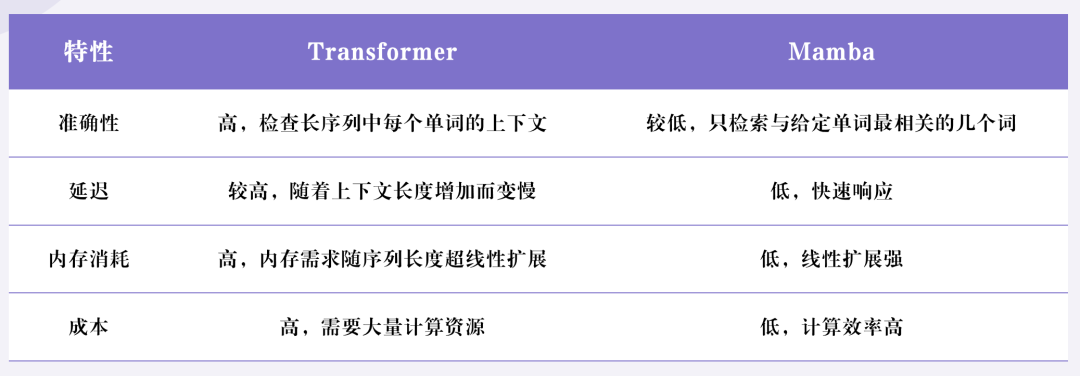
然而,在实践情况中,Mamba 应用并不如其理论上带来的波澜更大。
当 Mamba 和Transfomer 的比较放在当前技术堆栈的视角去考虑,Mamba 的应用仍面临诸多挑战:
• 迁移成本高,生态尚未完善。“Mamba 运行速度更快”理论上成立,但在实际工程中并非如此。
Transformer 经过多年优化,已形成成熟的技术生态,针对不同硬件和用例进行了深度适配,并具备完善的错误捕获机制。
而 Mamba 仍处于早期阶段,缺乏强有力的工具链和优化方案。
尤其对于开发者而言,迁移到 Mamba 需要投入大量时间进行训练、调试和适配,而现有 LLM 生态几乎完全基于 Transformer 进行剪枝、蒸馏和优化。
换句话说,团队需要花费大量资源训练一个 Mamba 模型,而结果可能还不如当前 Transformer 方案,这显然不是一个明智的决策。
• 规模化验证不足,Transformer 持续优化。
当前,大多数基于线性注意力或混合模型的研究尚未扩展至超大规模,
而 Transformer 经过多年积累,已通过知识蒸馏、强化学习等手段不断优化,保持高效推理与高准确率。
尤其是 2025 年初,多模态、高效的微型 Transformer 已崭露头角,在更小的计算资源下实现更快推理和更优性能,使 Mamba 的竞争力进一步受限。
此外,Gated Deltanet、RWKV7、TTT 和 Titans 等模型已在部分任务上超越 Mamba-2。
例如,RWKV7 针对小型模型进行了优化,在某些任务上甚至超越了 LLaMA3 和 Qwen2.5,而它们本质上也并未采用二次注意力机制。
• 缺乏杀手级应用,尚未证明独特性与可拓展性。25 年的 deepseek 让 MoE 架构出圈,23 年的 Chat GPT 让 Transformer 成为大众词汇。
然而,Mamba 目前仍未出现能够证明其独特价值的 Killer Model,缺乏一个能够真正展现其潜力的成功案例。
总的来说,Mamba 尚未经过广泛测试、可扩展性不确定且缺乏行业基础设施,仍需要更多的关注、研究、投入,以发挥更大的架构价值。
02.
Cartesia-Mamba 架构的代言人
Who is Cartesia
Cartesia 是一家应用 Mamba 在音频处理与生成的初创企业,成立于 2023 年 9 月。创始人之一 Albert Gu 正是 Mamba 的提出者。
其与 Karen Goel 等人均出身斯坦福大学 Stanford AI Lab 同一个博士研究小组。
从商业化角度来看,Cartesia 与 Mamba 相辅相成,相互促进:
一方面,对于 Mamba 而言,Cartesia 或许能填补其缺乏杀手级应用的空缺,成为一个成功的商业化尝试,从而推动 Mamba 在实际应用中的落地与验证。
另一方面,对于 Cartesia 而言,Mamba 在音频任务中的独特优势使其成为理想的技术基石。
SSM 在处理音频任务时,具备长时依赖建模、计算效率优化、连续信号处理等特点,使其天然适用于语音 AI 领域。
同时,尽管 Mamba 在理论上展现了出色的计算效率,但从 Transformer 迁移到 Mamba 仍然面临较高的成本,
这或许是其他公司难以直接采用 Mamba 进行语音任务的关键原因。
而 Mamba & SSM 资深研究者与 Cartesia 创始人双重身份的融合,也使得 Cartesia 成为 Mamba 商业化与大规模验证的潜在最佳实践者。

以 Real-time multimodal platform 为使命
Cartesia 的愿景是“Real-time multimodal intelligence for every device”,智能将无处不在。
这与 Mamba 的通用性和高效性高度契合。
Albert Gu 和 Karan Goel 在过去 4 年中共同致力于发展 SSM 架构,并将其扩展应用到文本、音频、视频、图像及时间序列数据等多模态领域,
并以毫秒级响应与更低的算力要求提供无缝的体验。
这也意味着,Cartesia 到长期愿景包含模型从数据中心依赖到边缘设备转移到可得性与通用性,
也包含从具有长期记忆的实时对话式人工智能到更多形式更多模态融合到实时通用智能的长期计划。
具体而言,尽管构建具备长时上下文的生成式模型仍然极具挑战,特别是在音频和视频等复杂多模态信号中,延迟和模型协调的复杂性难以控制,容易偏离预期。
Cartesia 在过去几个月构建了一种全新的 SSM 架构,使多流模型能够在多个模态的数据流上持续推理和生成。
这一突破使得端到端模型能够实现高效的流式推理,并在多模态任务中提供前所未有的精准控制。
一方面,通过端侧部署,Cartesia 用前沿的模型赋能客户,能够处理长时上下文的生成式模型现已在数千家客户的生产环境中运行,
涵盖个人创作者、初创企业及大型企业,助力下一代语音代理、数字媒体及智能助手的发展。
另一方面,通过模型的硬件效率和边缘计算能力的提升,Cartesia 计划将模型推向更接近数据采集的边缘设备,减少对数据中心的和大规模算力的依赖,
在普通本地设备上实现高效、实时、低成本的交互体验,包括了语音助手、游戏、音乐生成到跨模态交互等领域。
本质上,Cartesia 的核心驱动力,并非多模态本身,而是构建最通用、最基本的模块,进而自然推动多模系统的高效应用。
产品
现阶段 Cartesia 的产品与技术突破,主要应用集中在 Voice 领域。
在技术层面,Cartesia 的 End-to-End 语音生成模型采用 Multi-stream Architecture,能够对文本进行细粒度控制,以防止 hallucinations,
同时保持端到端生成的真实性。相比以往架构,该模型在处理复杂、冗长且重复的文本时表现更加稳定,能够准确跟随文本生成语音。
这一改进对 Voice agents 等对准确性要求极高的应用场景很有价值。
在产品层面,Cartesia 2024 年 5 月发布 Sonic,随后推出 Sonic On-Device,可在手机和其他移动设备上运行,适用于实时翻译等应用。
此外 Cartesia 还发布了 Edge(一个针对不同硬件配置优化 SSM 的软件库)和 Rene(一个紧凑型语言模型)。
2024 年 10 月 30 日,Cartesia 发布了 Voice Changer。
2025 年 3 月推出了 sonic 2.0 与 infill,Infill 输入填充文本,即可生成可平滑连接两个现有音频片段的音频。
这对于在现有语音片段之间插入新语音并保持自然过渡非常有用。
目前来看,Cartesia 长期将继续聚焦于语音领域的技术创新。
Sonic
Sonic 是 Cartesia 正式推出的首个商业化产品,一款高效极速的文本转语音(TTS)模型及 API。
Sonic 具备卓越的低延迟特性(仅 95 毫秒的模型延迟),能够生成极为自然、生动的语音,并支持 英语、中文、西班牙语等 7 种语言。
8 月 28 日,进一步发布了 Sonic Ondevice。
Sonic Onevice 是第一个超现实的生成语音模型,它支持设备上的低延迟实时流,并具有无限的声音和即时的语音克隆。
2025 年 3 月 11 日,Cartesia 进一步推出 Sonic 2.0,其建立在 Cartesia 团队新的状态空间模型架构之上,是目前速度最快、控制性最强的语音模型。
它的规模是 Sonic 的两倍,但运行速度更快,完整模型的延迟仅为 90 毫秒,而 Sonic Turbo 模型的延迟仅为 40 毫秒。
在测试中,与排名第二的提供商 Elevenlabs 相比,选择 Sonic 2.0 的人数是其 1.5 倍。
除了速度和质量之外,Sonic 2.0 还提供了前所未有的控制能力,可捕捉复杂的口音和丰富的音频音景。
Sonic 相较于传统 TTS 产品,在实时响应、音质、可扩展性和精准发音方面具备优势:
• 即时响应(Real-time Response):Sonic1.0 版本即可达到每种语言的首音频播放时间仅 95 毫秒,实现近乎即时的听觉反馈,显著提升用户体验。
• 极致拟真(Human-like Speech):语音自然流畅,具备人类般的表达能力,可支持与客户的互动,增强沉浸感。
• 大规模并发(Scalability):支持无限并发,即使在流量高峰期,也能保持稳定的性能和低延迟。
精准发音(Accurate Pronunciation):能够准确解析电话号码、付款信息等关键数据,确保语音交互的可靠性,适用于高要求的客户服务场景。
Sonic 的背后正是创新性的 SSM 架构,能够高效建模 高分辨率数据(如音频和视频),提供更优质、更低延迟的语音合成体验。sonic 有一系列技术突破:
• 音频质量优化:Sonic 经过参数匹配和优化,并在与主流 Transformer 模型相同的数据集上训练,整体音质显著提升。
• 核心指标领先:相较传统 TTS 模型,Sonic 困惑度降低 20%,单词错误率降低 2 倍,NISQA 质量评分提升 1 分。
• 高效推理能力:Sonic 具备更低的计算延迟,更快的推理速度,以及更高的吞吐量,全面提升用户体验。
Cartesia 还提供了 Web Playground 和 低延迟 API,用户可立即上手体验 Sonic 的强大功能,并快速集成至自己的产品或应用中。
无论是游戏开发、虚拟助手,还是多模态 AI 交互,Sonic 都能带来前所未有的实时语音体验。
Voice changer
2024 年 10 月 30 日,Cartesia 发布了 Voice Changer,一款智能变声模型,可将输入语音转换为目标声音,同时保留原声的语调、重音及表达特征。
Voice Changer 同样建立在 Cartesia 在 SSM 架构方面的开创性工作之上。
Voice Changer 在提供高度灵活的音色转换能力的同时,确保语音的自然度和表现力,为内容创作者、游戏开发者及企业提供高质量、个性化的音频解决方案。
Voice Changer 支持将任何音频剪辑的语音转换为不同的音色,同时保持原始音频的情感和表达,
也支持用户对音频的各个方面进行精细控制,包括情感、节奏和音调等。
Voice Changer 适用于多个领域。配音和旁白、游戏开发等创作场景中,Voice Changer 能够定制声音,提升沉浸感和互动性;
教育和培训,和客户服务、广告和营销等销售领域,Voice Changer 能够帮助品牌增强识别度,更好地传达品牌形象和信息。
商业模式
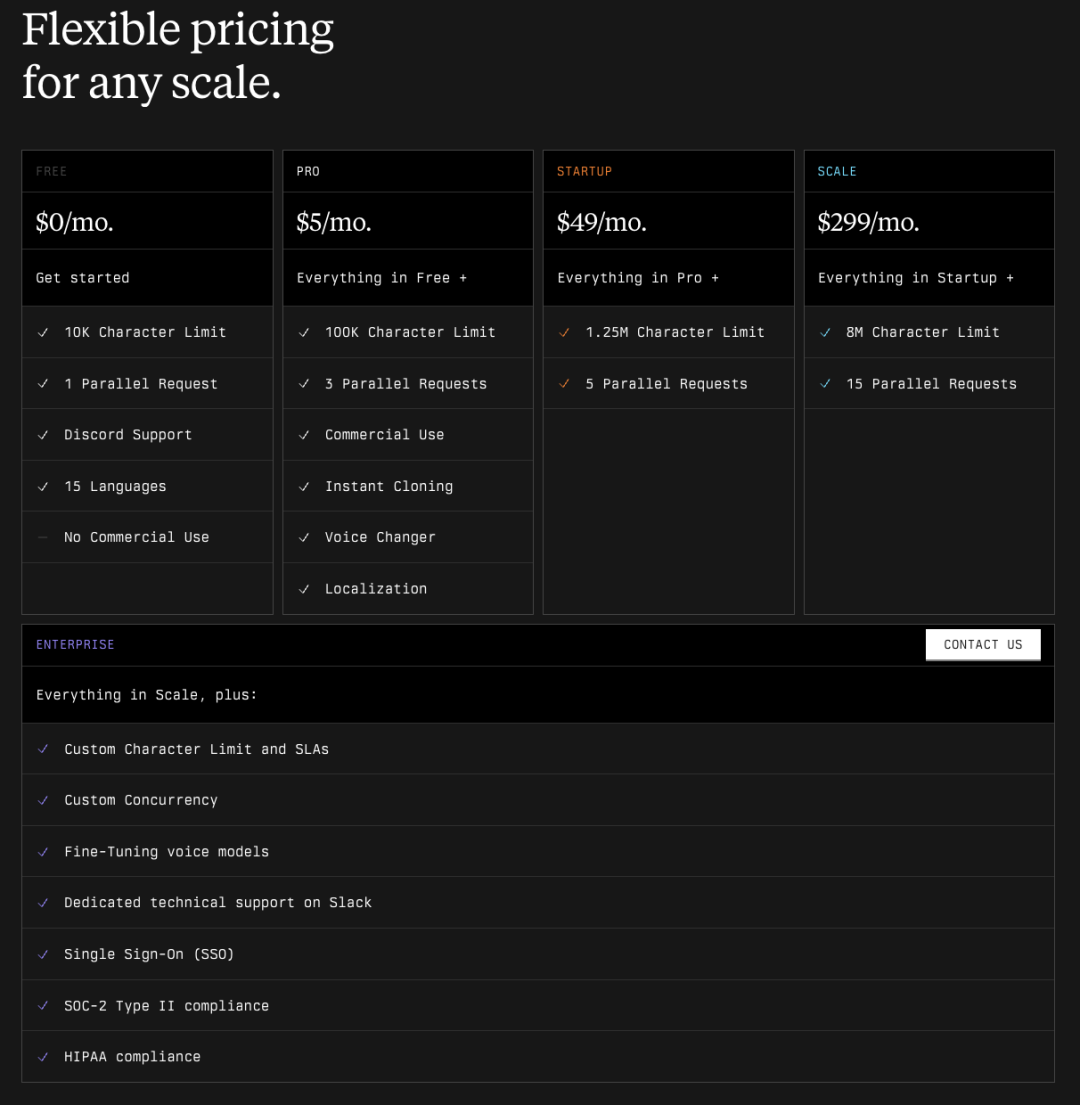
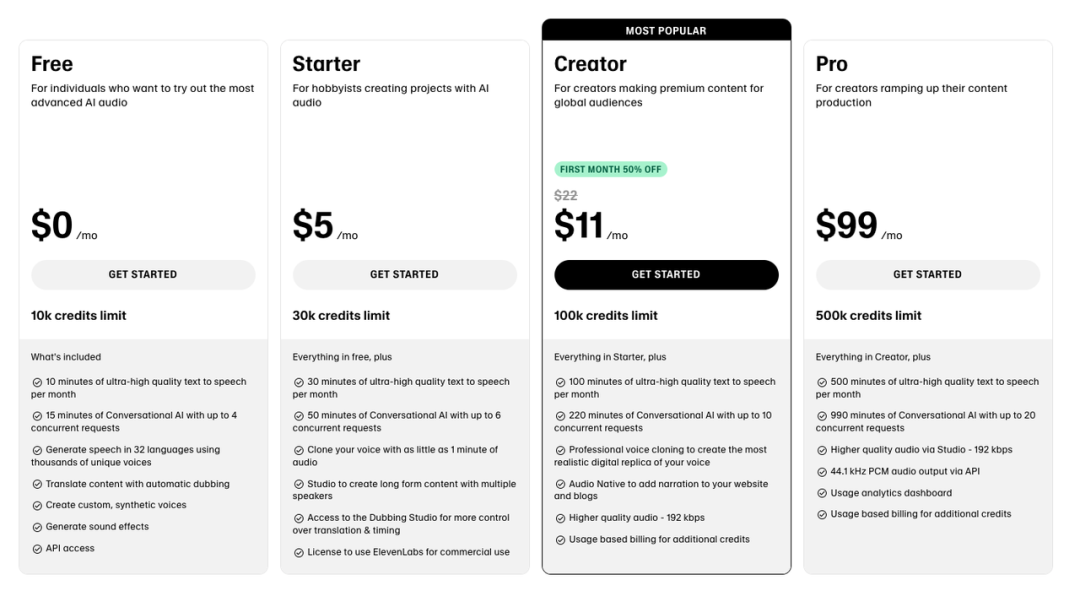
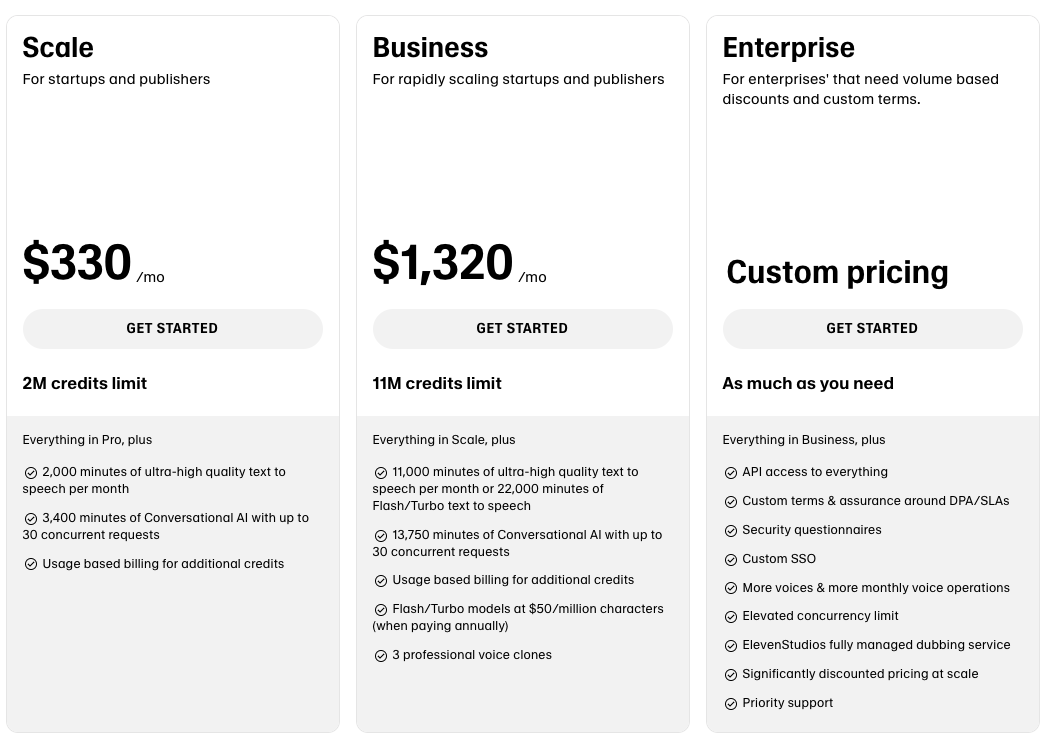
Cartesia 提供分层化定价方案,类似于 Elevenlabs 的定价方案,Cartesia 提供了标准产品与企业定制。
两者基本标准产品定价也基本相近。Cartesia 相同并发数订阅价格比 Elevenlabs 高,但单位字符成本低,且未明确限制文本语音转化时长。
但 Elevenlabs “creator”“pro” 定价方案都直接表明了 “for creator”,与其一直以来在内容创作领域的耕耘一致。
Elevenlabs 的持续分享创作者故事,涵盖新闻工作者、作家、YouTuber 如何利用语音技术跨越语言障碍、传递情感,并展示与机构的合作案例。
相比之下,尽管 Cartesia 同样服务中小创作者及个人用户,其主页则更侧重于展示垂直行业和明星企业的应用案例,以及技术平台的集成。
这些客户横跨各行各业,如:
• AI 数字员工 11x 通过将 Cartesia 的可靠、低延迟,又自然、富有表现力语音集成到数字员工 Julian 中,提升销售的说服性和实时性。
Cartesia在高端领域切中语音 Agent 的高质量音频要求,能够支撑起数十万次真实通话训练的全球市场推广拨号器
• 跨语言人才交互平台 Toby 使用 Cartesia 实现 200ms 以下超低延迟的 Real-Time 翻译,
多语言模型性能与英语一致,并且在 10 秒即可完成保留说话者特征的声音克隆。
• 视频通讯基础设施提供商 Daily.co 使用基于 SSM 的高性能实时模型 Cartesia 将语音首字节延迟控制在 180ms 内,支持 13 种语言的自然交互
• AI 游戏引擎 Ego 使用 Cartesia 实现 90ms 延迟,确保游戏体验,支持 14 种语言的情感表达的动态语音生成
• 对话代理平台 Vapi 使用 Cartesia 为其医疗保健客户,把之前的文本转语音提供商相比下继续通话的可能性提高了 4 倍。
目前,Cartesia 的旗舰模型 Sonic 已吸引了 10,000 多家客户,包括 Quora、Cresta 和 Rasa等。
作为底层模型参与多元行业的 Voice 构建一定程度上也契合Cartesia的长期愿景所需的学习曲线——
从语音出发,构建最通用、最基本的模块,或者说支持任何设备的多模模型。
Cartesia
Elevenlabs
03.团队及融资
团队
如前所述,Albert Gu 与 Karen Goel 来自 Stanford AI Lab 同一个博士研究小组。即 Stanford Statistical Machine Learning (statsml) Group。
斯坦福大学长期以来是 AI 研究的前沿阵地,在深度学习、强化学习和序列建模等领域培养了众多顶尖人才。
而 statsml Group 的研究在 SSM 领域奠定了重要基础。
除 Albert Gu 与 Karen Goel 外,Cartesia 的 Co-founder 还包括 2 位他们斯坦福大学的前同事 Arjun Desai、Brandon Yang 及其共同导师 Chris Ré。
几人研究兴趣并不完全一致,但汇聚于 SSM :
• Albert Gu 在斯坦福期间专注于序列建模,对 RNN 和 SSM 产生了浓厚兴趣,并提出了 HiPPO 和 S4,成为 SSM 领域的重要推动者。
离开斯坦福后,Gu 进入 CMU 任教,并出版了 Mamba 相关的系列论文。
• Karen Goel 最初研究 Reinforcement Learning,后在导师 Chris Ré 的指导下,逐渐转向序列建模,并与 Gu 合作研究 SSM。
两人人的研究最终汇聚于 S4,这是他们在斯坦福期间的重要成果之一。S4 证明了 SSM 在处理长序列数据上的优势,为 Mamba 模型的诞生奠定了技术基础。
• Arjun Desai,导师为 Chris Ré 与 Akshay Chaudhari,研究领域是信号处理、机器学习和数据系统,研究重点是信号处理和机器学习中的逆问题交集。
• Brandon Yang,同样在斯坦福人工智能实验室攻读计算机科学博士学位,
此前是 Snorkel AI 机器学习系统团队的技术主管经理、Google Brain 从事深度学习和计算机视觉研究、 Cadence Technologies 的联合创始人兼首席执行官。
斯坦福大学的研究环境、导师团队以及对序列建模的长期投入,使 SSM 体系得以发展,并在 Cartesia 找到了商业化的路径。

Cartesia co-founding team:
Brandon Yang, Karan Goel, Albert Gu, and Arjun Desai
融资
2025 年 3 月 11 日,Cartesia 宣布完成 6400 万美元 A 轮融资, Kleiner Perkins 领投,Lightspeed、Index、A*、Greycroft、Dell Technologies Capital、
Samsung Ventures*跟投。本轮融资后,Cartesia 的融资总额已达到 9100 万美元,而仅仅拥有 26 名员工。
Index Ventures 合伙人 Shardul Shah 认为 Cartesia 的使命是 “from data centers to devices”,
Mike Volp 指出 Cartesia 的 SSM 是“unlock the next wave of AI innovation”的最好架构。
04.市场
市场空间: 多场景、强落地的通用工具
聚焦到当下的语音市场,伴随着 llm 等技术的快速发展,语音生成已经渗透到各个领域,成为推动行业变革的新基建。
Y Combinator 的冬季和秋季孵化项目中,voice-native 公司的数量在这两个周期之间增长了 70%。
TTS 模型在标准化业务流程和交互式内容创作上有广泛应用。
以有情感、准确的 TTS 模型作为核心组成要素,AI Voice Agent 大大增加了服务容量,尤其是那些以往因人力不足而受限的领域有了全新的经济的解决方案,
例如 Sales Agent 和 Customer support Agent。
对于创作者来说,贴近真人的语音乃至灵活的戏剧化语音生成能力,使得教育、游戏、有声阅读、配音等领域有了新的超低成本的高质量助手。
作为 TTS 模型供应商,Cartesia 与其竞争者既可以直接向垂类赛道公司提供服务,也可通过 Voice/Video Agent 平台间接赋能行业生态,具备灵活的商业模式。
无论是直接服务还是间接支持,语音市场的增长空间巨大。需求方覆盖从大型企业到中小及初创公司。
首先,尤其是 Real-time Voice 用例极为丰富,包括:
• 客户支持与销售自动化:涵盖金融、医疗等高精准度要求的行业,提升服务效率与体验。
• 内容创作与游戏开发:助力个性化配音、虚拟角色语音、互动叙事等创新应用。
• 教育与培训:提供高质量语音内容,增强教学互动性。
与此同时,对 TTS 技术需求旺盛的行业,尤其是金融和医疗等垂直领域,对语音准确度的要求极高,并且拥有充足的预算。

综合这些因素,多场景、强落地的通用语音工具市场空间巨大。
2024 年 TTS 全球市场规模已达约 40 亿美元,并以高于 15%的 CAGR 高速增长,根据 Market.us 的数据,TTS 全球市场规模到 2033 年预计将达 146 亿美元。
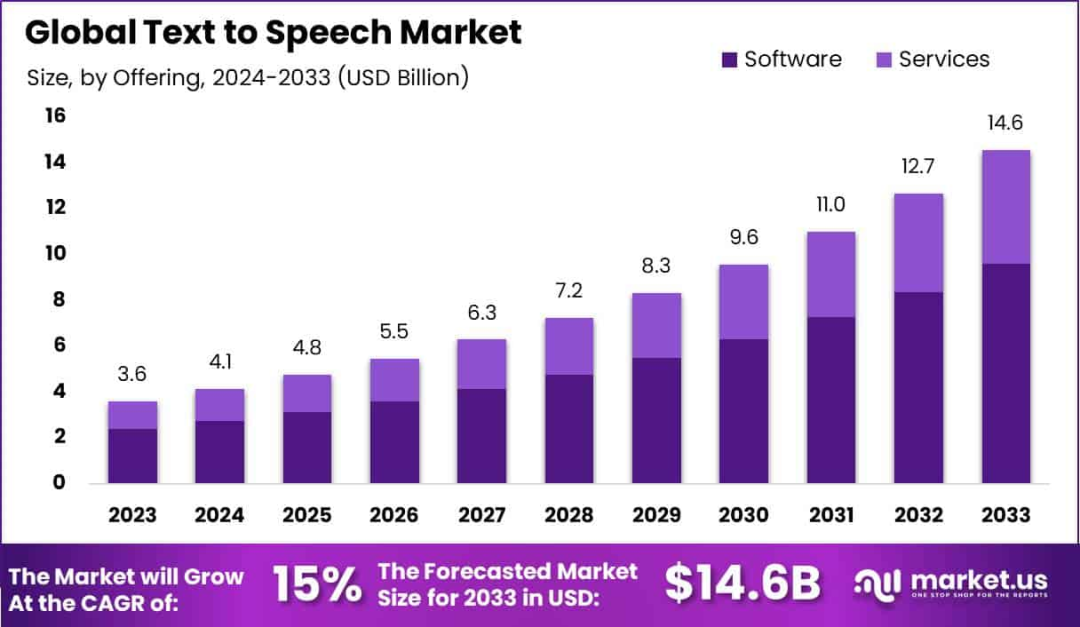
*各类市场调研机构数据略有差别,但量级基本一致,source:
https://market.us/report/text-to-speech-market/
竞争格局:从 google 到初创公司
Landscape
在语音生成市场中,无论是 2C 的创作者场景中,还是 2B 的 Voice Agent 场景,竞争者林立。
AWS、GCP 等大厂倾向于提供定制解决方案,也不乏企业选择 meta LLaMas 等开源模型自行调整并嵌入系统,
Elevenlabs、Deepgram 等创业公司也不断涌现,Cartesia 的竞争优势体现在哪里?
首先, 对于微软 Azure 、Google cloud、AWS 等,单纯 TTS 技术本身不是大厂的投资重点,他们更倾向于捆绑解决方案,
通过高昂捆绑售价以覆盖工程成本,其体系中 TTS 只是整个解决方案的一部分。
他们的优势在于企业级支持,比如 Google Cloud Platform(GCP)和 Azure 依托全球数据中心,提供成熟的服务支持而非 tts 精度打磨。
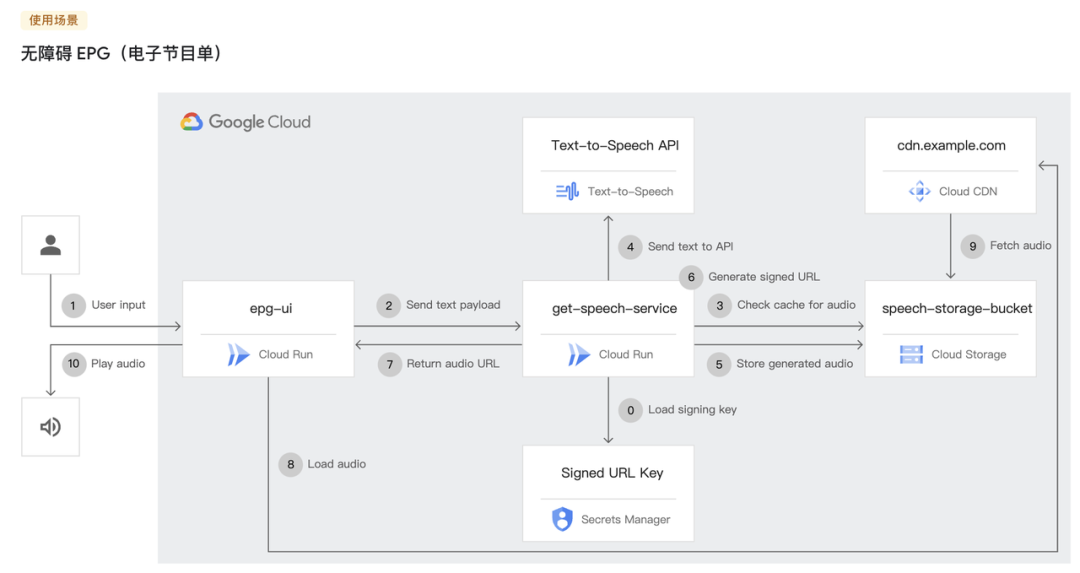
总的来说,即使是在呼叫中心这样标准较低的场合。
Azure、Google 和 AWS 等公司的成熟产品在输出质量和成本方面都令人失望,在灵活性和定制化上不及初创公司,给了初创公司抢占市场的空间。
另外还有像 OpenAI 、mata 的 llamas,具备强大的模型能力与泛化能力,但是并不意味着在 tts 领域有优势。
因为一些企业已经有比较完整的系统,他们需要的是集成难度低的 TTS 方案,功能强大,适合需要快速部署到原有系统的应用场景。
而不是一个需要大量调整的泛化模型。
同时,初创公司语音合成的自然度和表现力方面具有优势,且用户反馈中较少出现翻译错误或语音风格不一致的问题。
再者这些公司,适合预算有限的企业或个人开发者,同时允许用户自定义模型参数,优化推理速度,甚至针对特定行业术语进行微调。
不过在实际应用中,用户也会选择混合的解决方案,避免供应商锁定,使企业可以自由迁移,降低长期依赖的风险。
总体上看,初创公司正在通过低延迟、低成本和质量优化等不同策略争夺市场。
Deepgram vs. Elevenlabs vs. Cartesia
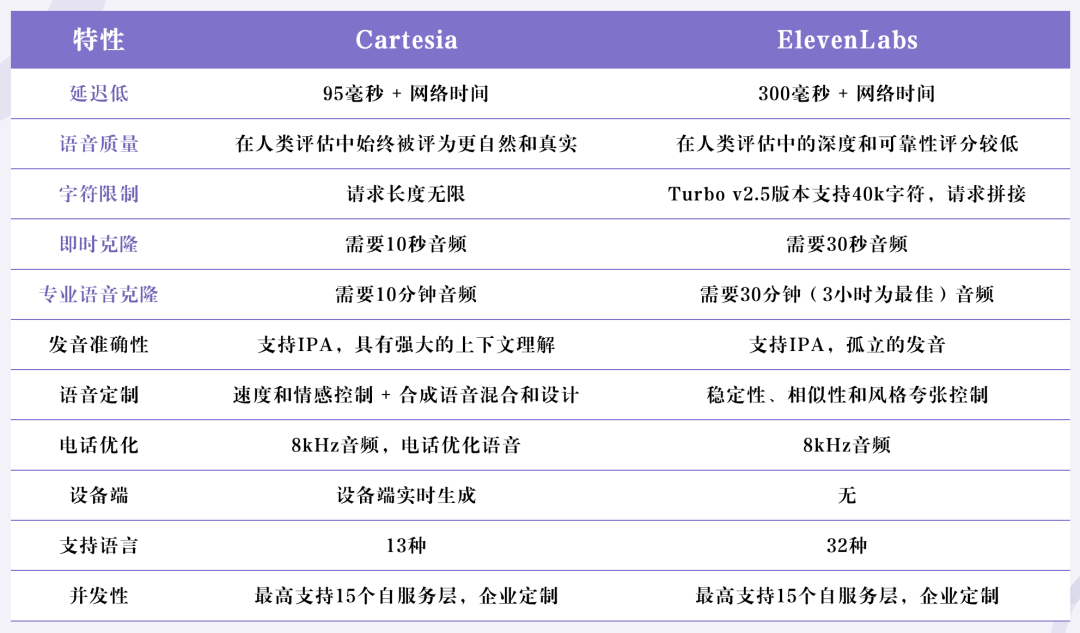
Elevenlabs、Deepgram 等语音初创公司与 Cartesia 有相似之处。但「语音质量+延迟程度」维度上,Cartesia 具备优势。
在人工评估中,Cartesia 更常被首选,NISQA 评级为 4.7,显示其语音清晰度、自然度和情感敏感度较高而 Elevenlabs,
在人工评估中较少被首选,NISQA 评级为 4.38,可能在深度和可靠性方面略逊一筹。
独立平台也得出了类似的评估结果。根据领先的数据标签提供商 LabelBox 的数据,在六家不同的提供商中,Cartesia 排名第一的概率为 27.93%,
而 Elevenlabs 仅为 10.68%。在 2024 年 9 月 LabelBox 的语音生成排名中,Cartesia 也拥有最高的 ELO 评级,Elevenlabs 位列第四,Deepgram 位列第六。
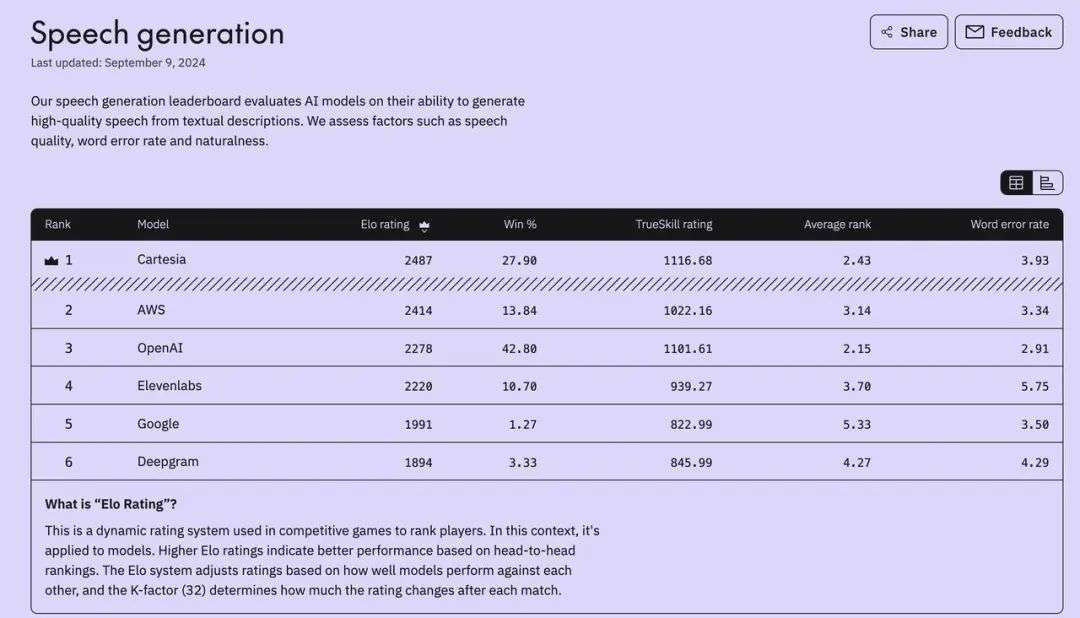
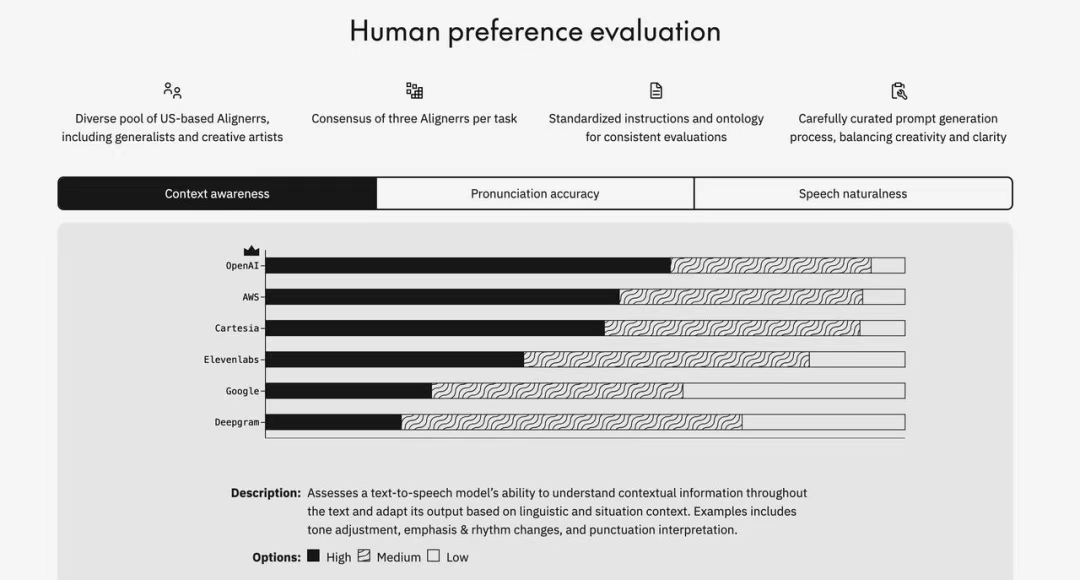
Cartesia 在领先的独立模型评估提供商 Artificial Analysis 的 Text-to-Speech Arena 上也拥有最高的胜率,为 75% 。
他们的 Text-to-Speech Arena 对不同的语音提供商进行了盲目的人类偏好测试。
在延迟上,Cartesia 使用状态空间模型(SSM)架构,实现 199 毫秒的首次音频时间(TTFA),适合实时对话。
而 Elevenlabs 的 TTFA 为 832 毫秒,对于企业客户可能提供更低的延迟,但自助服务层的延迟较高。
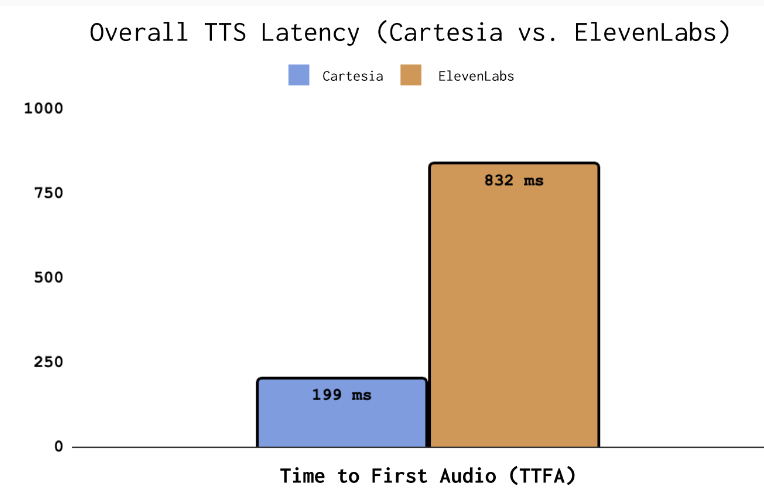
其他维度上,Cartesia 在长文本处理、发音准确度和语音克隆方面领先,支持无限上下文长度和 IPA,特别适合医疗保健等专业场景。
目前,3 家主要玩家形成一定程度差异化竞争态势。
特定情况下,Elevenlabs 可以 600-800ms 的较高延迟换取顶级音频质量,在内容创作领域独占鳌头。
而高延迟对实时场景影响较大,且价格相对较高,为竞品提供了切入机会。
Cartesia 则凭借 200ms 的低延迟、具竞争力的定价和快速迭代的克隆技术,市场份额持续增长。
Deepgram 则长期在 ASR(自动语音识别)领域领先,TTS 业务仍在扩展,专注极致的成本效益,
其 Aura 模型以最低的市场成本实现了 200ms 延迟,但输出语音更偏“机器感”难以满足内容创作需求,在音频质量上仍需提升。
对于 daily.co 这家语音和视频领域的专业代理商使用比例来说,Elevenlabs 约占 70%,Cartesia 占 20%,Deepgram 占 10%。
在当前阶段,基于传统Transfomer 架构构建并且在创作与 sales 领域耕耘已久的的 Elevenlabs ,依旧在市占率中处于领先地位。
未来趋势:架构与技术路线的选择与融合
语音生成技术正从传统 TTS 向端到端 Voice-to-Voice 交互演进,但这一转变并非简单的技术迭代。
尽管端到端方案在延迟上具有优势,其输出控制、企业级应用等方面仍面临挑战;
同时,语音 AI 需要不仅仅是音频生成,而是能够处理文本输入输出、结构化数据以及 API 调用,需要更自然、更智能的语音乃至多模态交互模式。
需求与技术现状的差距,导致不同玩家采取了差异化的技术路线:Deepgram 选择小参数量语音模型,通过工程优化实现高效交互;
开源生态基于 Meta Llama 探索与闭源方案的竞争;OpenAI 则押注超大规模算力。
而 Cartesia 基于 Mamba 架构提供了另一种可能:其多流 SSM 架构在保持高真实度的同时,有效解决了长上下文建模、控制性和幻觉等问题。
这样的突破不仅关乎语音生成,更指向未来实时多模态 AI 的新可能。
正如前文提到的 Hybrid Mamba Transfomer 架构,未来的竞争焦点似乎不在于单一技术的优劣,而在于如何在不同技术路线间找到最优平衡,
构建更全面、更智能的交互系统。
在这场变革中,Mamba 与 Cartesia 正共同前行。
文章来自于微信公众号“海外独角兽”,作者 :linlin



【开源免费】MockingBird是一个5秒钟即可克隆你的声音的AI项目。
项目地址:https://github.com/babysor/MockingBird
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
