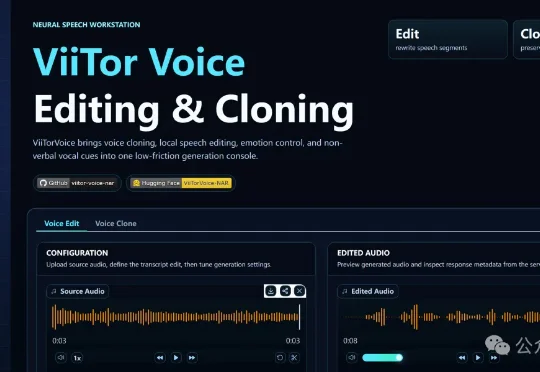
全球第一! 中国模型登顶榜首,首个可编辑AI语音来了
全球第一! 中国模型登顶榜首,首个可编辑AI语音来了全球第一!中国AI语音ViiTorVoice首创「局部编辑」神技:配音错字告别重录,像改Word一样修语音。内附姆巴佩、哈兰德爆笑实测,快来见证!这个凭空出世的中国模型,将 Qwen3-TTS、CosyVoice3、Fish Audio 等一众主流巨头挑落马下,径直登顶综合排名第一!
来自主题: AI资讯
8415 点击 2026-07-04 10:52
 搜索
搜索
全球第一!中国AI语音ViiTorVoice首创「局部编辑」神技:配音错字告别重录,像改Word一样修语音。内附姆巴佩、哈兰德爆笑实测,快来见证!这个凭空出世的中国模型,将 Qwen3-TTS、CosyVoice3、Fish Audio 等一众主流巨头挑落马下,径直登顶综合排名第一!
Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。
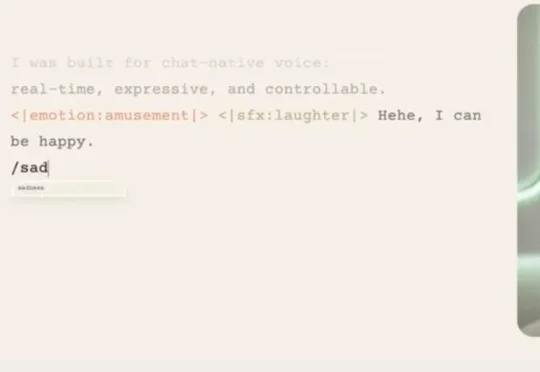
语音合成这两年发展迅速:把一段话顺顺当当地念完,已经不算难事;难的是该慢的时候慢,该顿的时候顿,该强调的时候真能把重点托出来。
没错,用的就是主打长程任务、模糊指令遵循,跻身国产Agent第一梯队的小米MiMo‑V2.5 Pro。小米最新发布的MiMo‑V2.5系列,包含Pro旗舰Agent、全模态基座、TTS语音合成、ASR语音识别四大模型,综合实力对标国际顶尖水准。

相似度超越Seed-TTS、MiniMax-Speech等知名模型。昨晚,美团LongCat团队发布了文本转语音模型LongCat-AudioDiT,并开源1B、3.5B参数量的版本。这一模型的最大特点,是彻底抛弃了梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音。通俗地说,这一模型直接根据声音本身的规律进行生成,“雕刻”出最原始的声音波形,从根源阻断数据转换的级联误差。

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大

占领OpenRouter调用量榜单第一的神秘模型Hunter Alpha,终于揭开神秘面纱—— 既不是GPT,也不是DeepSeek,而是来自小米的万亿旗舰模型MiMo-V2-Pro。

今日凌晨,小米MiMo大模型系列重磅三连更:旗舰基座大模型MiMo-V2-Pro、全模态Agent模型MiMo-V2-Omni、MiMo-V2-TTS,其最新发布的这三大模型都是为优化智能体能力打造。
ListenHub ASR 语音识别 API 全新上线,无限免费。 API 特点: 本地离线转录,无需 API Key,安装即可使用。专为 Agent 设计,方便你的 Claude Code 和龙虾🦞直接接入自动化工作流。
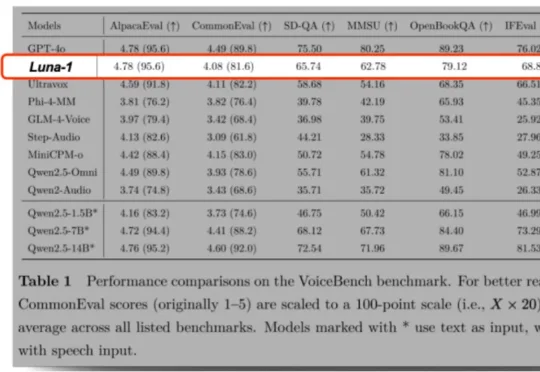
VUI Labs(宇生月伴)宣布完成数千万元天使+轮融资。本轮投资由同创伟业领投、老股东靖亚资本、小苗朗程持续加注,心流资本FlowCapital担任长期财务顾问。公司半年累计获得近亿元投资,所募资金