# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能技术日新月异的今天,语音合成(TTS)领域正经历着一场前所未有的技术革命。
最新一代文本转语音系统不仅能够生成媲美真人音质的高保真语音,更实现了「只听一次」就能完美复刻目标音色的零样本克隆能力。
这一突破性进展的背后,是大规模语音数据的积累和大模型技术的快速发展。
同时在技术前沿,DeepSeek 系列凭借其 GRPO 算法(群体相对策略优化),正以强化学习引领大语言模型(LLM)研究的新趋势。
目前,强化学习已扩展至自回归 TTS 系统。
然而,由于非自回归架构与大型语言模型(LLMs)存在根本性的结构差异,
此前非自回归 TTS 系统尚未出现成功的强化学习集成案例,这一技术难题仍有待可行的研究解决方案。
近日,腾讯PCG社交线的研究团队针对这一挑战提出了 F5R-TTS 系统,
首创性地通过将模型输出转化为概率表征,打通了非自回归 TTS 模型强化学习的「任督二脉」。

F5R-TTS 通过模型架构创新,有效融合了强化学习。这项研究的主要贡献体现在三个方面:
1.概率化输出转换:研究团队创新性地将 flow-matching 的 TTS 模型输出转化为概率表征。
这一转换使得强化学习在非自回归模型中的应用成为可能,为后续的优化奠定了基础。
2.GRPO 优化方法:首次成功将 GRPO 方法应用于非自回归 TTS 模型,
采用词错误率(WER)和说话人相似度(SIM)作为奖励信号,有效引导模型优化方向。
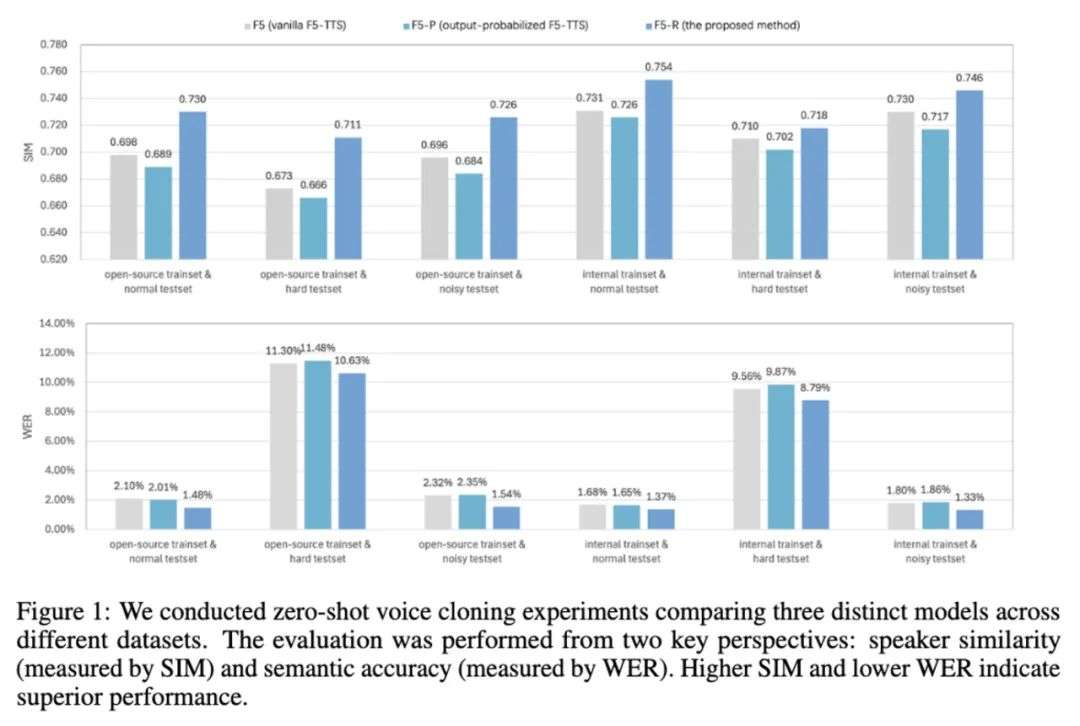
3.零样本语音克隆验证:在零样本语音克隆场景中,F5R-TTS 模型展现出显著优势。
相较于传统非自回归 TTS 基线模型,在可懂度(WER 相对降低 29.5%)和说话人一致性(SIM 相对提升 4.6%)两方面均实现显著提升。
F5R-TTS 的训练流程分为两个关键阶段:第一阶段基于 flow-matching 损失函数进行预训练;第二阶段采用 GRPO 算法对模型进行精细优化。
这种两阶段训练策略既保证了模型的初始性能,又通过强化学习实现了针对性优化。
概率化改造:强化学习的基础
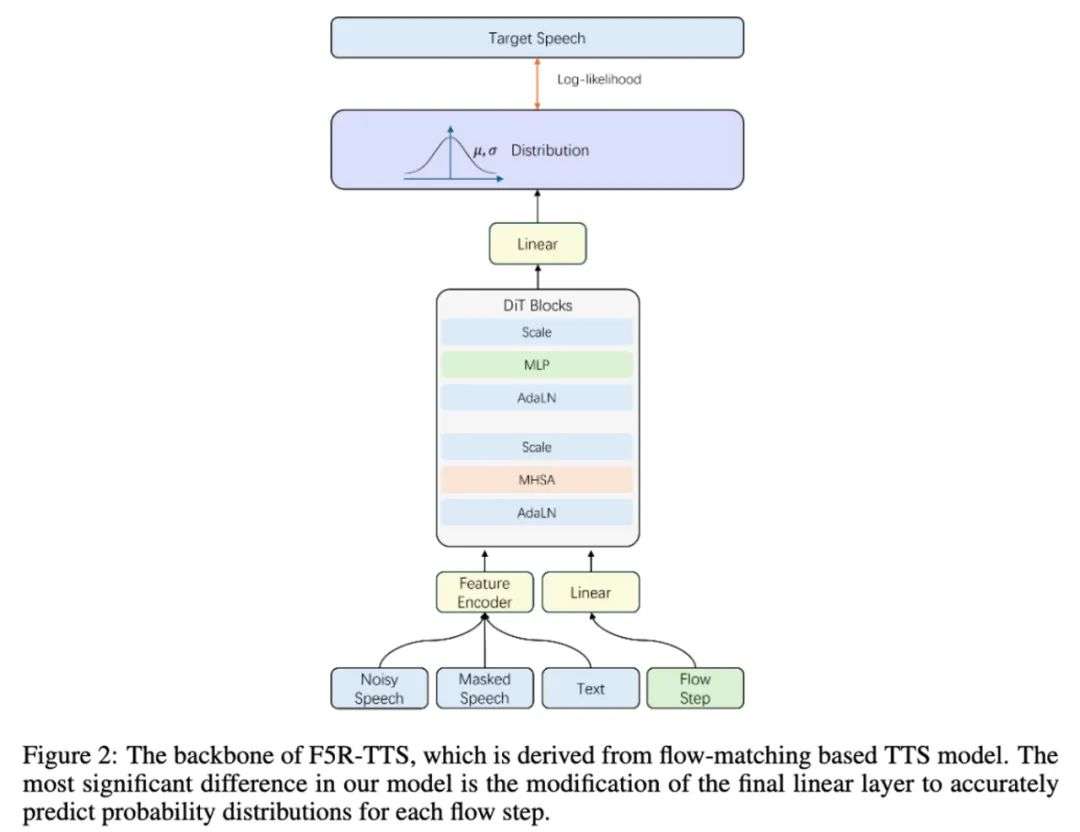
我们选用了当前效果领先的非自回归 TTS——F5-TTS 作为骨架。为了使非自回归模型适配 GRPO 框架,F5R-TTS 进行了关键的概率化改造。
具体而言,模型被设计为预测每一步输出时的分布概率,而非直接预测确定性的输出值。
这一改造使得模型输出具有了概率分布特性,为强化学习中的策略梯度计算提供了必要条件。
在第一阶段预训练中,目标函数仍采用 flow-matching 的形式,其核心思想是将标准正态分布 x0 的概率路径匹配到近似真实数据 x1 的分布上。
模型在最后一层预测高斯分布的均值与方差,并通过优化参数以最大化 x1 −x0 的对数似然函数。这一过程可以形式化为以下目标函数:
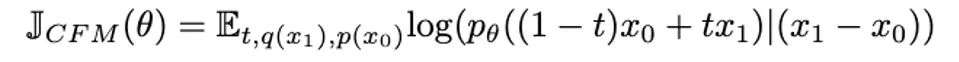
简化后,模型使用下式作为预训练的目标函数
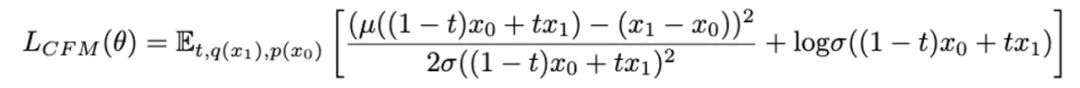
GRPO 强化
在 GRPO 阶段,预训练模型作为策略模型进行微调,同时以预训练参数初始化参考模型。
具体实现上,策略模型的前向运算需要执行类似推理过程的采样操作 —— 从标准高斯分布初始输入开始,逐步计算每一步的输出概率分布,并进行采样。
采样结果既用于计算奖励信号,也需要与参考模型输出比较以计算 KL 散度损失,确保优化过程的稳定性。
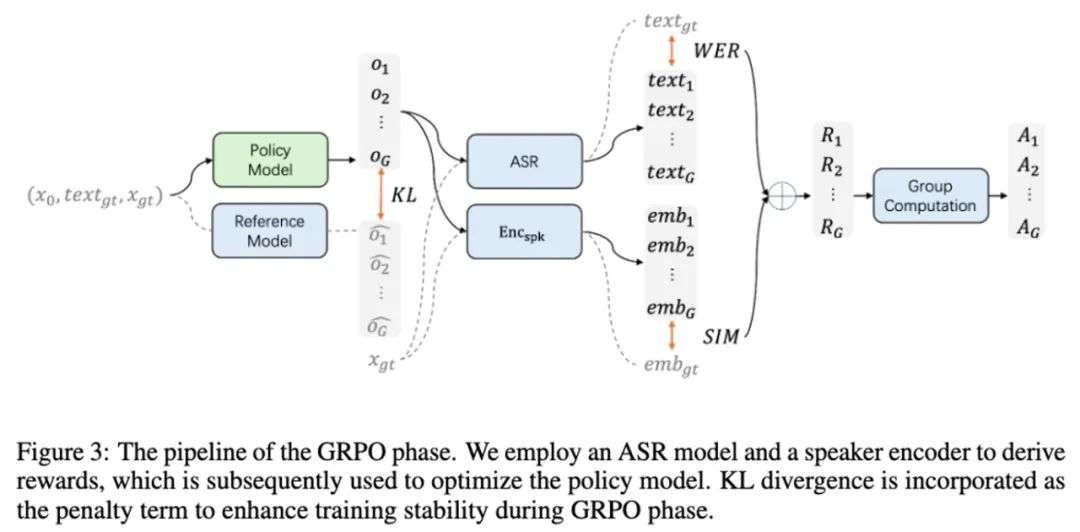
奖励函数的设计是 GRPO 阶段的核心。
研究团队选择了词错误率(WER)和说话人相似度(SIM)作为主要奖励指标,分别对应语音克隆任务中最关键的两个方面:语义准确性和音色保真度。
最终,GRPO 阶段的目标函数定义如下:
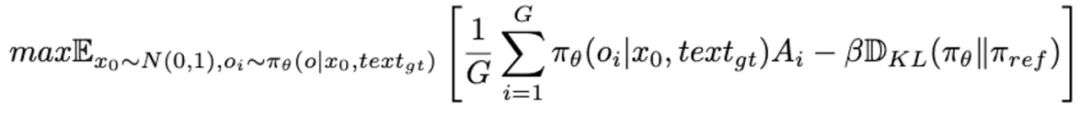
实验
研究团队设计了全面的实验来验证 F5R-TTS 的有效性。实验设置包括:

研究团队首先采用 t-SNE 技术对说话人相似度进行二维空间可视化。
结果如图 4 显示,对比其他方法,F5R-TTS 模型的合成结果能够更准确地按照目标说话人实现聚类。
这一可视化结果直观地证明了 F5R-TTS 模型在说话人相似度方面的优越表现。
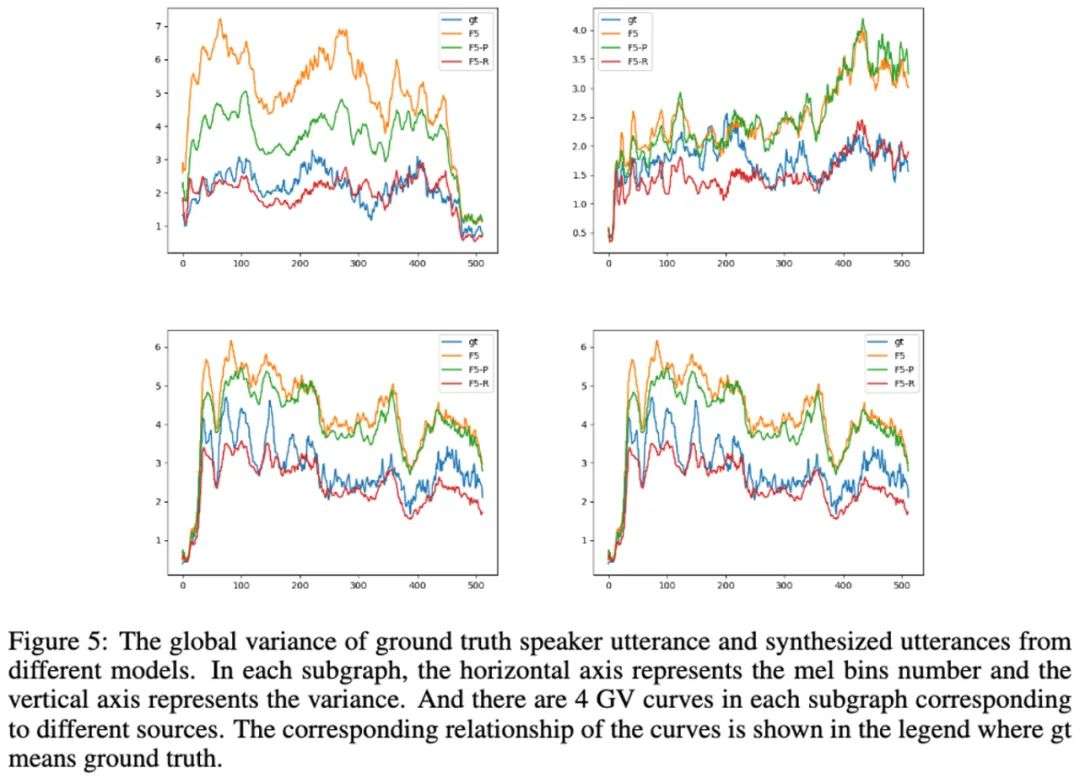
其次,采用全局方差(Global Variance, GV)指标进行频谱分析。
如图 5 所示,F5R 模型的曲线与真实语音的曲线吻合度最高,再次验证 F5-R 模型的合成语音在频谱特性上与真实语音具有更高的相似性。
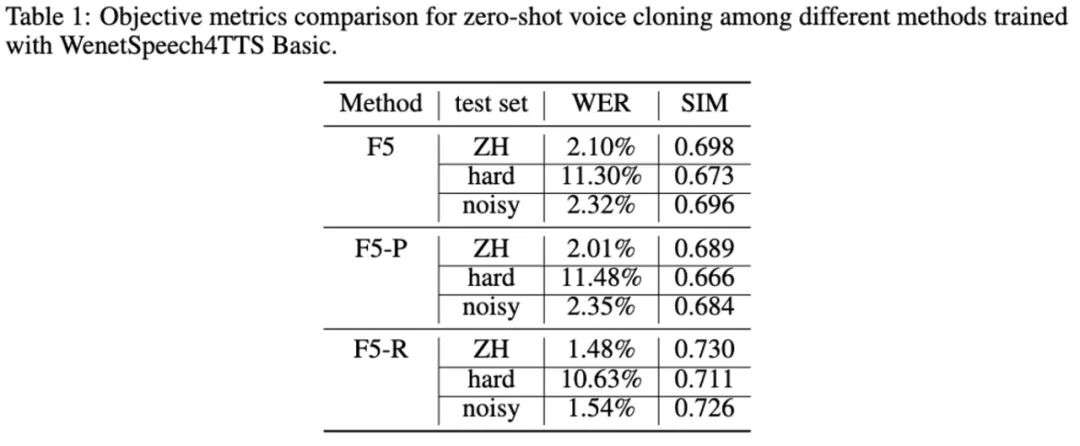
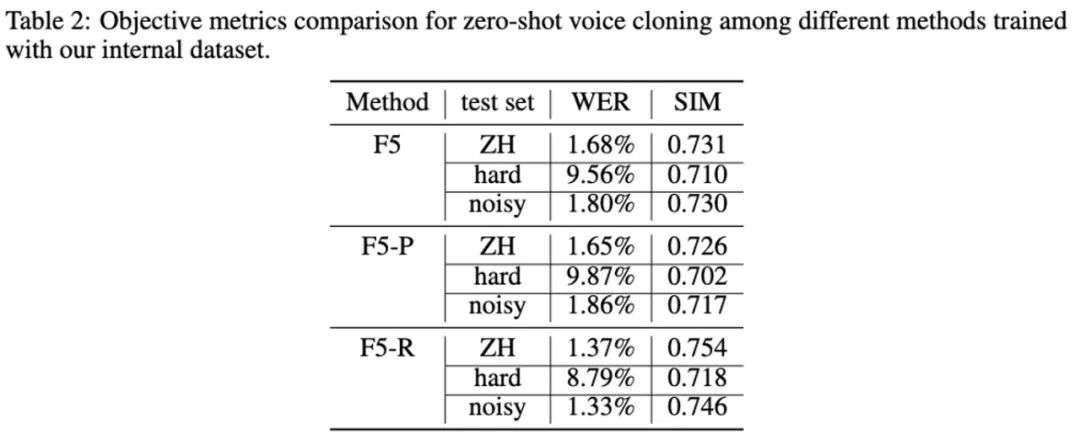
客观测评指标表明,采用 WER 和 SIM 作为奖励信号的 GRPO 方法,使 F5R-TTS 相较于基线在语义准确性和说话人相似度两个维度均获得提升。
在说话人相关奖励的引导下,F5R 能够通过上下文学习更精准地克隆目标说话人的声学特征。
值得注意的是,在困难测试集上,F5R 在 WER 指标上的相对优势更为显著 —— 这得益于 WER 相关奖励组件有效增强了模型的语义保持能力。
另外,为验证所提方法的泛化能力,实验还用在内部数据集上进行了重复验证,结果表明 GRPO 方法在不同数据集上都能持续提升模型性能。
同时,三个模型在困难测试集上的性能均出现下降,这表明文本复杂度的增加通常会导致模型稳定性降低。该现象将成为后续优化研究的重要切入点。
未来展望
F5R-TTS 首次成功将 GRPO 整合到非自回归 TTS 系统中,突破了非自回归模型难以应用强化学习的技术瓶颈。
实验证明该方法能同时提升语义准确性和音色保真度,为零样本语音克隆提供了更优解决方案。
文章提出的概率化输出转换策略为其他生成模型的强化学习优化提供了可借鉴的思路。
这项研究不仅推动了语音合成技术本身的发展,也为其他生成式 AI 模型的优化提供了新思路。
展望未来,研究团队计划从三个方向继续深入探索:
1.强化学习算法扩展:探索将 PPO、DDPO 等其他强化学习算法整合到非自回归语音合成系统的可行性,寻求更高效的优化路径。
2.奖励函数优化:设计更精细、多层次的奖励函数,进一步提升模型在自然、个性化和表现力等方面的效果。
3.大规模数据验证:在更大规模、更多样化的训练数据上验证方法的扩展性,探索数据规模与模型性能的量化关系。
随着技术的不断成熟,期待未来出现更加自然、个性化和富有表现力的语音合成系统,为智能交互、内容创作、辅助技术等领域带来全新可能。
文章来自于微信公众号 “机器之心”,作者 :机器之心



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
