# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Agentic AI 的 3 要素是:tool use,memory 和 context,围绕这三个场景会出现 agent-native Infra 的机会。
Agent 所获取到的信息质量是 agent 推理的起点,虽然 LLM 带来了 perplexity 为代表的 AI answer engine,提供了完全不同于传统搜索引擎的体验,但这些产品仍旧面向的是人类用户,产品逻辑是围绕人类行为设计的。
在我们 MCP 的研究中发现, GitHub MCP Servers 列表里使用场景最多的是搜索和数据检索,开发者们的偏好也反映出 agent-native 搜索的重要性。
Exa 要做的是 LLM 时代的 “Bing API”,为 AI agent 系统重新设计搜索,当 AI-native 应用或者 AI Agent 需要实现互联网信息搜索时,都可以调用 Exa 的 API 能力,因此,Exa 的核心受众是 B 端企业和开发者。在功能上,Exa 可以实现更复杂的语义搜索。比较有意思的是团队的技术愿景,公司认为,Exa 的架构让用户可以选择投入更多的计算资源、等待更长的时间,来获得更多、更完善的搜索结果。

按照场景和信息需求类型,搜索行为大致可以被分为四类:
• 第一类,高频快速查询,指的是一两步内就能完成的查询。Google 大部分的 query 还是以几个单词为主,用户得到答案后马上离开,不会进行深入的查询。对于这类查询 Google、Bing 还是最好的应用,新玩家几乎没有挑战的机会。
• 第二类,研究性质的深入查询,用户可以和搜索工具反复交流,获取知识。这一类搜索是 LLM 和 LRM 带来的新场景,对应的代表性产品形态分别是 Chatbot 和 Deep research。
• 第三类是个人偏好查询,搜索引擎需要根据用户的个性化信息和偏好才能给用户合适的推荐。大模型让新玩家有机会挑战传统玩家,核心原因是传统搜索只能支持简单查询,而大模型可以处理语义更复杂的查询,提供更精准、个性化的答案。但有几个落地难点,比如:大模型缺乏长记忆能力;个人偏好查询往往是快速查询,对响应速度要求较高;用户数据在云端处理还是本地处理等等。代表性产品有 AI 电商搜索领域的 Daydream、Constructor 等。
• 第四类是长尾查询。用户有不同的感兴趣的小众领域。
AI 在第二、第三类场景最具成为挑战者的潜力。未来,这些搜索场景极有可能是人与 AI agent 进行交互,agent 在理解意图后用 tool use 的方式进行搜集、验证、任务执行,我们已经在一系列 Deep Research 产品上看到雏形。因此,Agent 未来会替代人类成为网页信息搜索的主力“用户”。在 2 年前,OpenAI 前安全研究副总裁 Lilian Weng 就提出 search 是 agent tool use 中的重要部分,站在今天看,Agentic AI 的实现基础有 context、tool-use 和 memory,RL 环境给 tool-use 提供了 infra,search API 也是对 context 能力提升的工具。
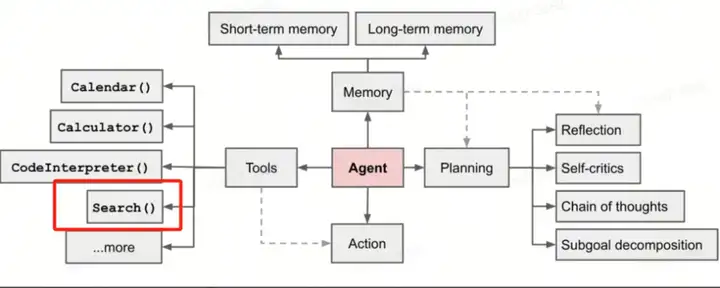
过去的搜索市场是对人类用户的竞争,未来的搜索将在为 agent 提供搜索的能力上展开竞争,这也是我们关注 Exa 的原因。目前是搜索引擎是围绕人用软件的逻辑去设计的,我们认为 AI agent 需要一套和人类不同的 search infra,原因有几个方面:
• AI 需要更复杂的查询。现有搜索引擎主要服务快速查询——用户 query 通常只是几个单词或短语,无法搜索含有多个复杂查询条件的 query。
• AI agent 需要正确且丰富的 context 才能发挥作用。然而传统快速查询的需求决定了用户只关心搜索结果的第一页,极少翻阅后续页面。这导致靠后的搜索结果大多是用户几乎不会打开的“垃圾内容”。但 AI agent 不仅只需要前几页。
• AI 需要高吞吐低延时做得更极致的搜索系统,人类一天搜索的次数可能比不上 AI 一分钟需要搜索的次数。
• 现有的搜索工具塑造了人们创建的内容,网站迎合的是搜索引擎而不是寻求内容的用户。大部分网站都根据 Google 的 ranking 算法进行了 SEO 和逆向工程,这样的搜索引擎搜出来的可能是关键字匹配的低质量内容,但 AI 的推理系统需要的是真正相关的知识。
基于以上原因,AI 需要新的 search infra。Perplexity 早期用的也是现成的搜索 API(如 Bing API),后来也开始自建嵌入模型,侧面说明传统的搜索无法满足 AI 产品的需求。
LRM 带来的第一个落地的 Agent 是 deep research。Deep research 是一个非常典型的 agentic RAG 架构,通过 dynamic planning、long horizon reasoning 以及 decision making 在复杂任务中实现检索-加工-验证-优化,检索的质量是 agent 推理的起点。
目前开发者对 MCP 的共识提高,我们统计 MCP 在 GitHub 提供的 154 个 MCP Servers 列表里,使用场景最多的是搜索和数据检索,大约有 34 个,主要用于实现网络搜索、爬取内容、语义检索、向量搜索等功能。MCP 不仅推动了 AI-native 的 search infra 标准化连接大模型时机的成熟,社区贡献的结果也反映了 search 对于 agent 的重要性。
2025 的关键词是 Agentic AI,在这个时间点关注 Agent Infra 是一个好的时间点,而信息检索是最高频的场景之一。
Exa 是 LLM 时代的 “Bing API”,为 AI 重新设计搜索系统,处理 AI 时代复杂的检索请求,为后续 AI 的推理和执行提供更好的知识。
Exa 把互联网的内容分类构建了自己的 embedding,核心目的是搜索最精确的内容、找到最相关的网站。Exa 的技术衍生出来的产品形态主要有两个:一个是 API, 为 B 端开发者提供的搜索 infra。另一个是 web 端产品 Websets,更加 to prosumer。 Websets 相当于把互联网变成一个可以用多种条件过滤的 Excel,用户用语义搜索就可以直接获得一个最需要的信息列表,未来也会以 API 的形式提供。Exa 的搜索技术适合用于构建 agentic RAG、构建研究 agent 等。
Exa 的主要收入来自 API,围绕不同场景,Exa 开发出了一系列 API 支持不同的功能。最核心的是 Search API, 用于语义搜索:用户输入自然语言,Exa 把自研的嵌入模型与传统的关键字搜索配合起来使用,实现寻找最相关的内容。输出的格式可以自由定制,例如选择标题、生成 highlight、正文、生成摘要、subpages、相关性得分等。
其它 API 还有:
• Get Contents API :可以理解为一个爬虫 API ,用户输入一串 url,即可爬取多个网页内的各种内容。
• Answer API :可以对搜索的结果进行智能问答。
• Find Similar Links API :可以返回与用户输入的 url 内容相似的网站。
API 主要的使用对象是 B 端或者开发者,这些人在构建 AI-native 应用的过程中会利用到 Exa 的这些 API,为了匹配这些场景需求, Exa 在速度、scale 和实时性上都做了专门的优化:
1)速度方面 latency 在 300ms,每秒可以输入 100+ queries。作为对比, Google 的 latency 普遍被认为大概在几十至几百毫秒。
2)规模方面,每次可以支持返回数千个结果。
3)实时性方面,每两分钟更新 index 库,持续添加新的链接。
4)infra 方面 Exa 在 LangChain,LlamaIndex,CrewAI,OpenAI 等都做了 integration 上的优化。
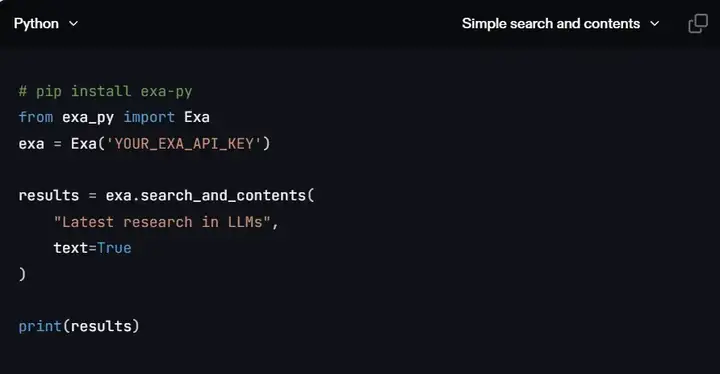
search 功能 API 使用示例
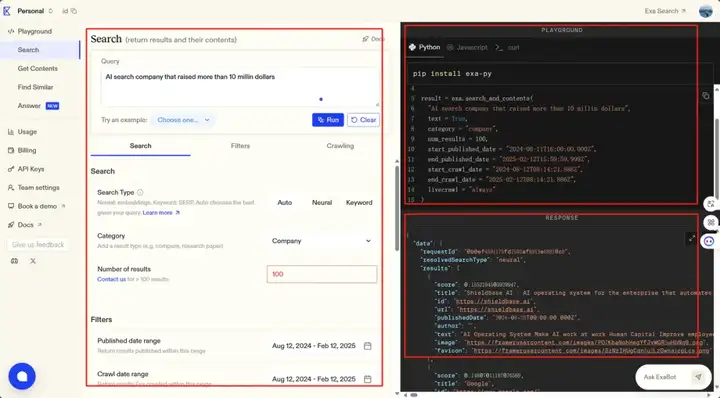
search 功能的可视化示例
不过,Exa search API 价格比传统解决方案要高很多,Exa search API 提供 100 个结果需要 $25。相比之下 Bing Search API 每 1000 次调用价格在 $10~25。因此 Exa API 的价格大概是 Bing 的 10x。
Websets 是搜索能力衍生出来的产品,用户用语义搜索就可以直接获得一个完整的信息列表,Websets 在 Web 端基本形态如下图。公司透露 Websets 的能力未来也会以 API 的形式提供。
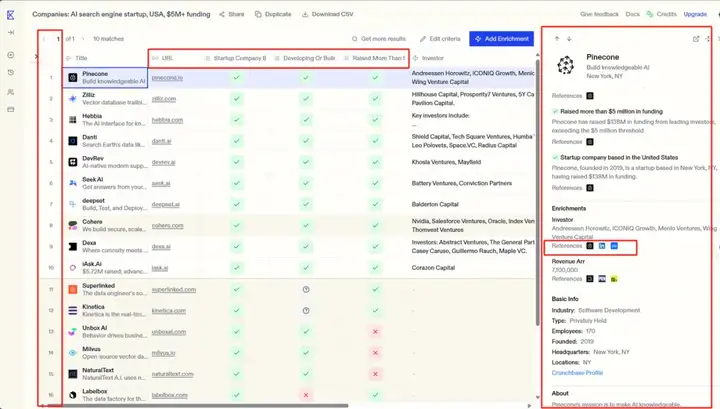
Websets 的产品形态。这里的 query 是:
help me find AI search engine startup in the USA with over $5M funding.
从功能和形态来看, Websets 都很像通用版的 Clay:
Clay 主要做销售线索的 data enrichment,B 端用户可以 Clay 的数据库中筛选出一个 company list 或 people list,然后 Clay 用 waterfall 式的搜索办法从数据合作商中搜索对应的销售线索,例如邮件、电话,和地址。Clay 最新的估值是 12.5 亿美金,ARR 约 3700 万美金。
但 Websets 能力范围大于 Clay:
1)用户可以搜索任意的 categories,除了 sales 领域,常用的场景还有投资研究、学术搜索,以及招聘等。
2)用户可以用自然语言添加任何筛选方式,Websets 从整个互联网搜索。而不是像 Clay 只有固定的筛选方式,其主要从合作商数据库搜索。
3)用户可以添加任意希望填充的指标;而 Clay 只能用既定的指标。
相比于 Clay 做的是 domain-specific 的数据,作为开放版本的 Clay——Websets 最容易受到质疑的就是准确性。而准确性是 Websets 的核心卖点。Exa 从 0 开始对互联网做了一套 embedding vector(尽管不是整个互联网),因此 Websets 的搜索结果能给出非常准确的 reference。
另外,在产品层面,每次用 Websets 进行探索性搜索的时候,用户可以选择先生成几行进行 preview。这样一来,Websets 在投入更多计算资源之前能够确认这是用户需要的 dataset。
在 Exa 的内部基准测试中,Websets 比 Google 和 OpenAI Deep research 能找到多 10 倍的正确结果。
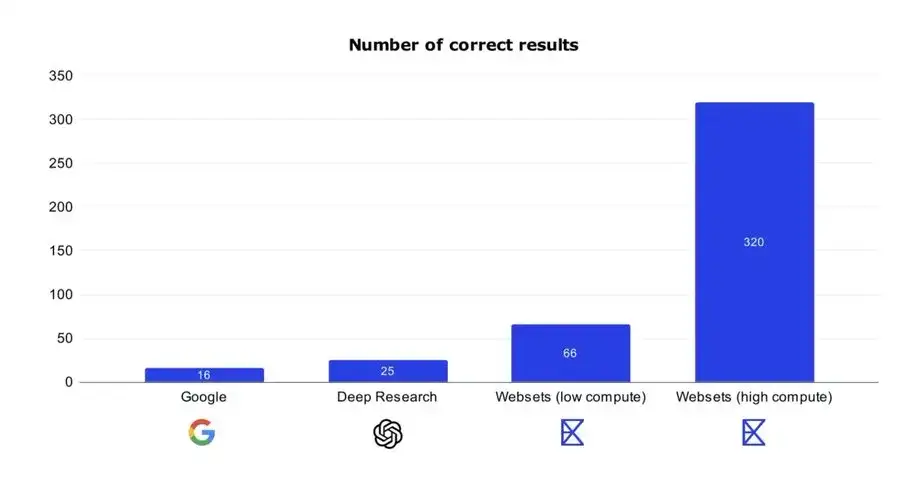
Google vs OpenAI's Deep Research vs Websets (low compute) vs Websets (high compute) in Exa's benchmark of complex queries.
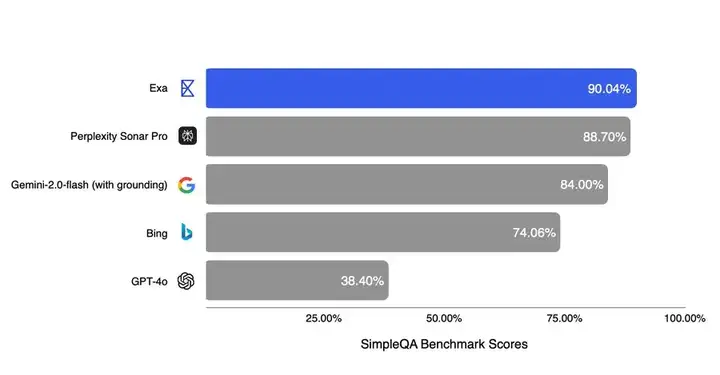
SimpleQA 是 OpenAI 发布的一个基准测试,
可衡量LLM回答简短问题的能力。
Websets Pro 定价为 $800/月,是目前 OpenAI Deep research 的 4x。 处理速度上 Exa 每秒 100+ query,Bing 的 TPS 在 100~250 左右,Exa 目前没有领先。

Search API pricing
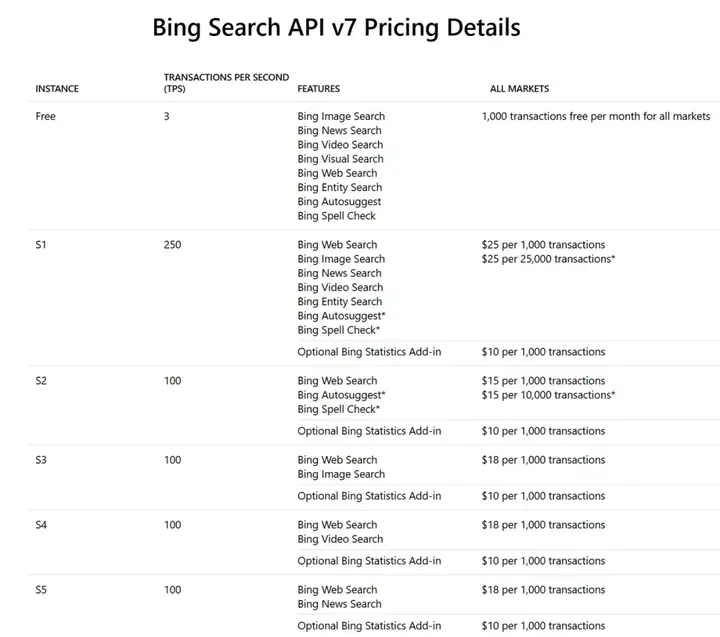
Bing Search API pricing(部分)
Exa 的主要收入来自 API,API 的使用对象主要是构建 AI-native application 的用户;或者是搜索强度大的行业,例如销售、投资研究。有 VC 客户透露他们每天几乎连续使用 Exa 8 小时以上,用于各种不同类型的查询。Exa 的 API 为客户做了非常多强大的 agents。
因此 Exa 也为这些场景做了 demo 来展示。这些 demo 底层的核心还是 Exa API 的三个关键能力:1)语义理解;2)自研的搜索系统搜索最相关的内容;3)较低的 latency。
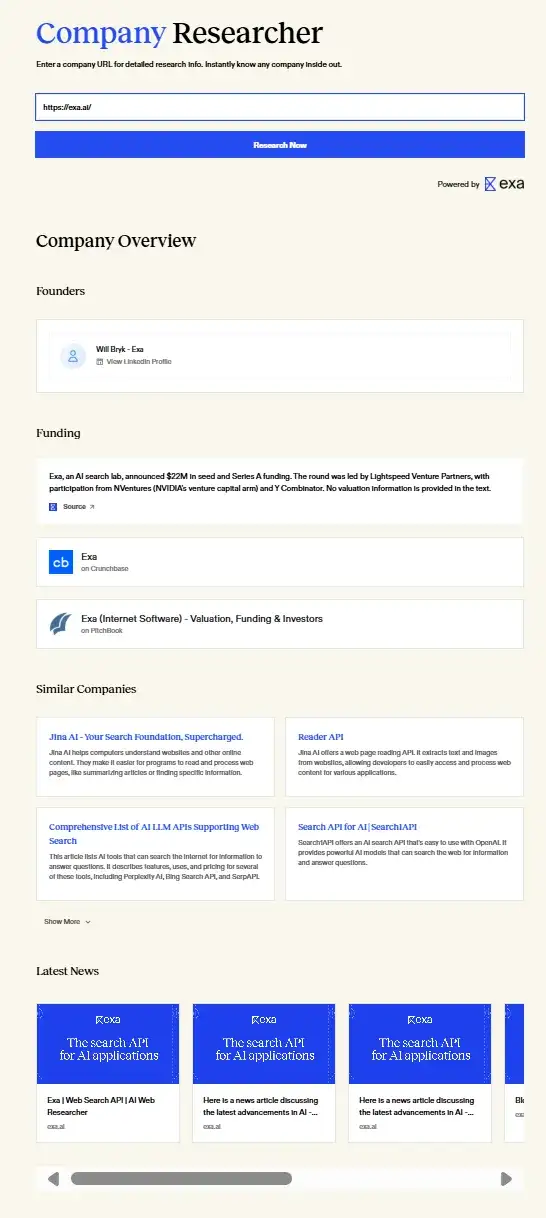
• Company research agent
Exa 有很多用户是投资公司,他们使用 Exa 来辅助投研。分析师在研究初创公司时,第一步一定是相对标准化的信息搜集:整理融资记录、团队背景、公司新闻和关键里程碑、并通过 YouTube、X 等社交媒体搜索创始人言论和社区对产品的讨论,如果是技术类产品,则还需要去 GitHub 和 Google Scholar 查技术更新。
虽然内容并不复杂,但这些信息分散在不同的网站、平台上,因此是一个很耗时的工作,Exa 提供的这个 demo 相当于一个预定义的 agent,提高了分析师在信息搜集环节的效率。
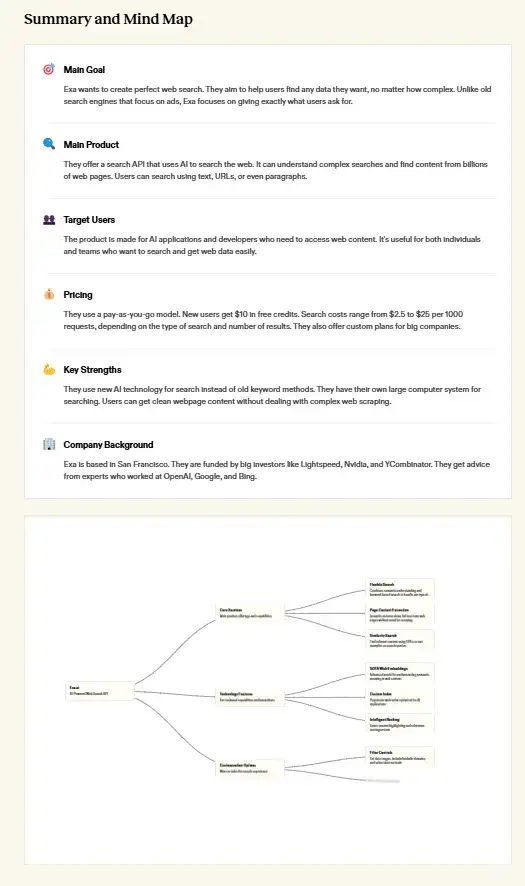
• 超级写作补全 agent
和 coding agent 相比,LLM 时代仍缺乏实用性强的写作 agent。写作比 coding 更开放,agent 难以 100% 预测、理解用户的写作意图,因为实用性受限。Exa 这个写作 agent 的 PMF 差异化在于以搜索为核心,在理解句子后自动补全并附上参考,节省作者的搜索时间。
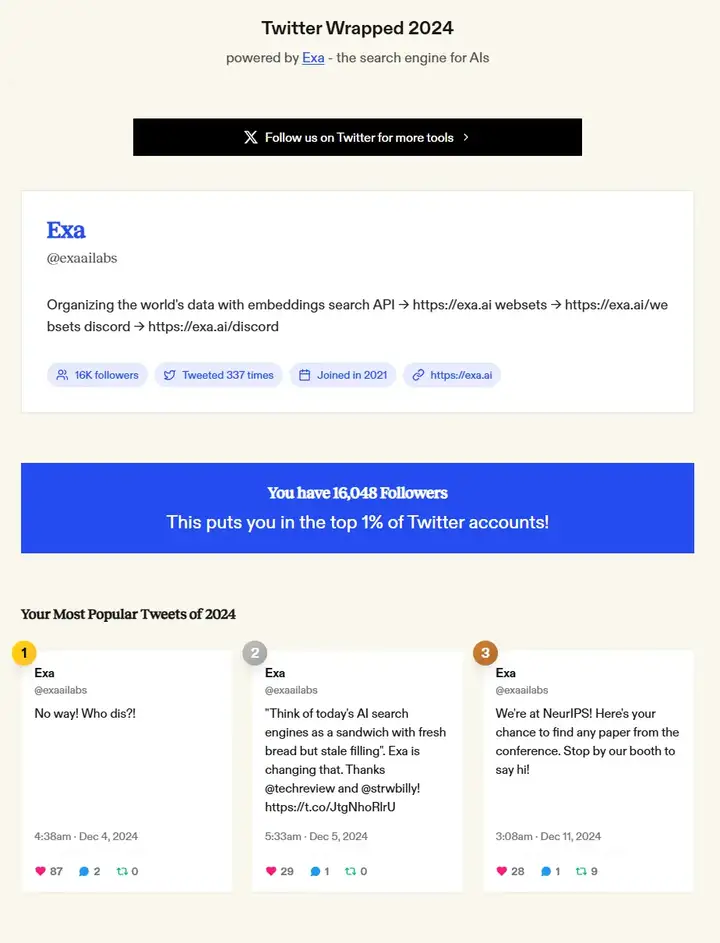
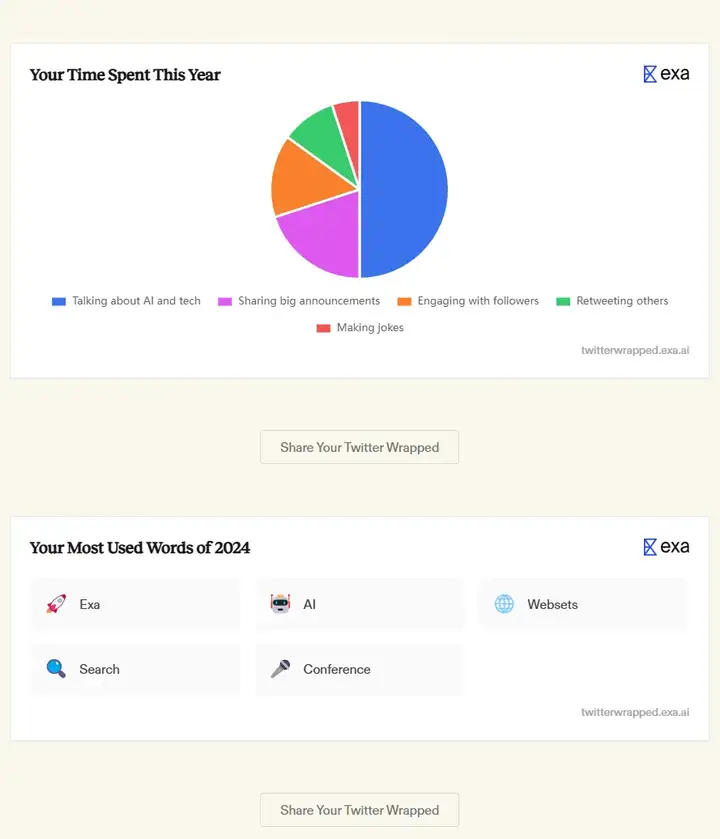
• Twitter Wrapped
几乎每个 to C 的 App 都开始流行“年度使用报告”,基于内部数据为用户提供年度总结。Exa 的这个 demo 可以从外部用 search agent 的方式对 twitter 做分析和总结,类似的 agent 可以迁移到不同的平台和应用,其价值在于跨平台的搜索分析能力。
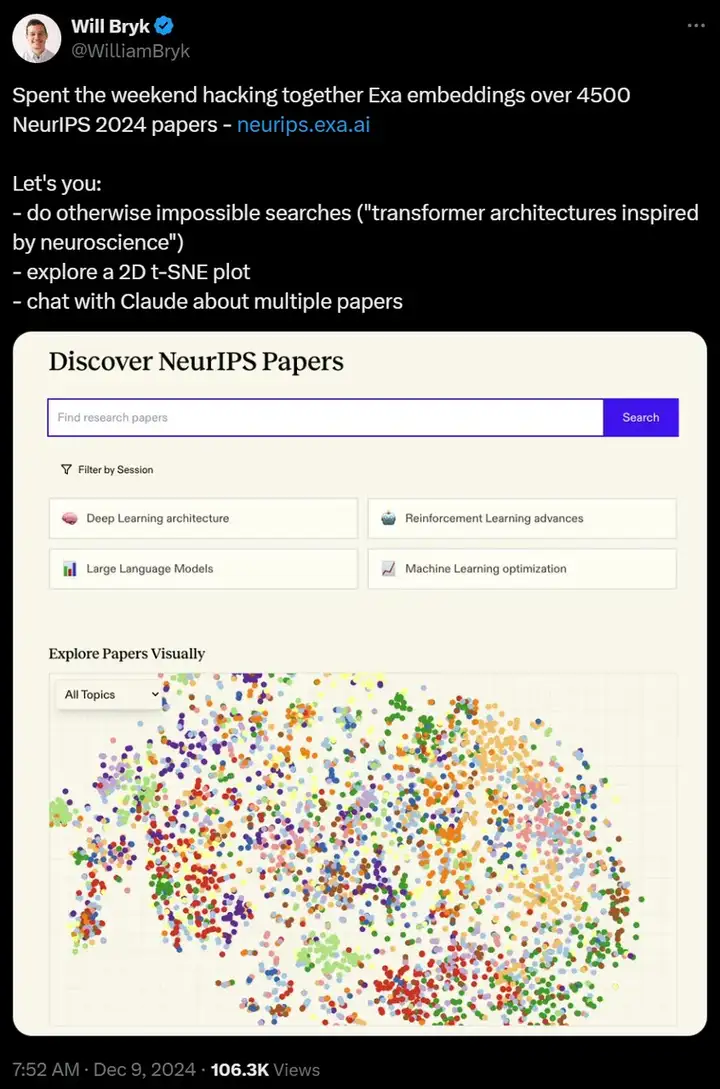
• 学术论文 search agent
这个 Agent 是 Exa 的 CEO 用不到两天的时间内,对 4500 份论文做的一个 search agent,可以以可视化的方式展示 Exa 是如何对论文进行 index、分类,以及相似性搜索。
除了官方发布的一些 demo 之外,Exa 在 twitter 上的热度很高,经常有用户分享他们如何用 Exa 的 API 构建有趣的 demo,例如 YouTube search agent, twitter search agent,电商购物 search agent。
有趣的是,Exa 还用自己的产品为自己找客户,比如在 Websets 上搜索”曾经发布关于探索性搜索文章的公司“。因为关注这个领域的公司就是他们的潜在客户。
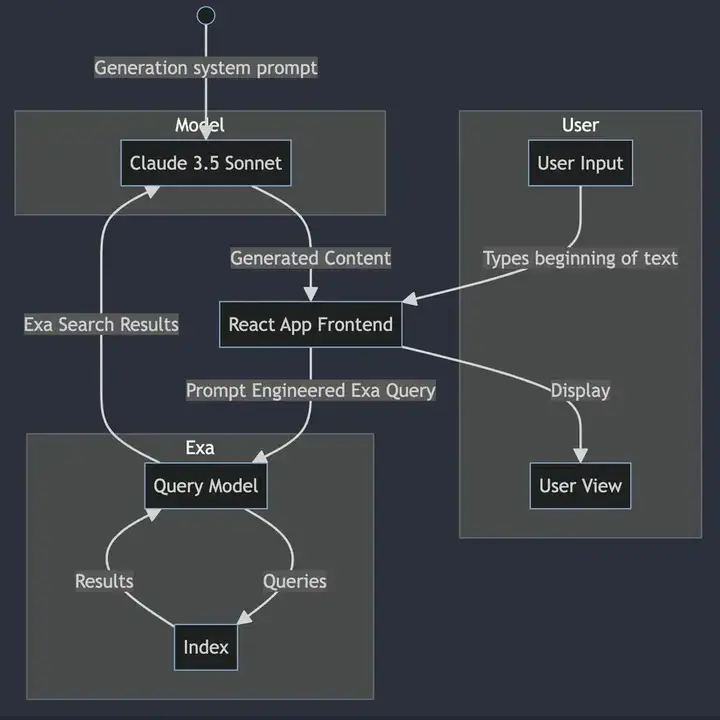
作为一个初创公司 Exa 没有足够的资源对整个互联网构建索引,所以团队战略性地先选择对互联网的部分内容索引,以此作为搜索系统的基础。基本的工作流程是:选择文档进行爬取、解析,存储在云服务器上;然后需要对文档构建嵌入,构建矢量数据库,作为后续搜索的基础。
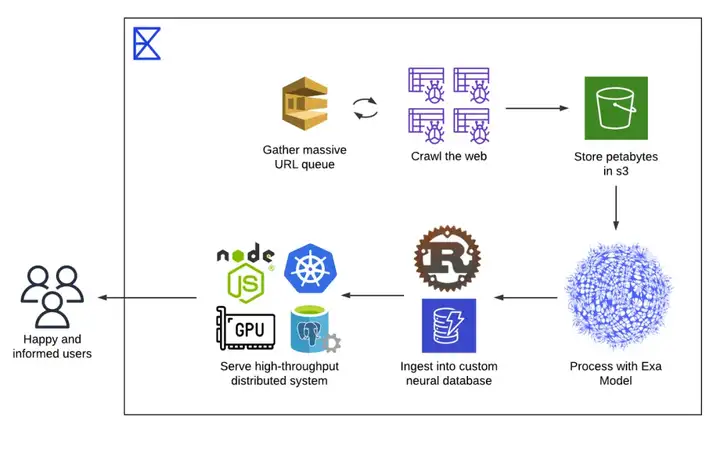
系统的基本流程
这样的战略其有效性在于:实际上用户大部分的查询都是常见的查询,一个小型的知识系统是可以回应大部分问题的,这类似于“二八效应“。剩下的内容可以用更简单的方式解决,比如利用现有的 API 快速查询。
不过这也带来实操上的难点:例如如何选择”优质“的网页构建索引?在这方面 Exa 团队先定义了一系列重点关注的类别,例如学术、新闻、人物等等,然后再逐渐迭代。

部分 Exa Index 的类别
在模型方面,Exa 基于端到端的神经网络和 transformer 来查询索引,这样做尤其胜任模糊语义和多层语义的查询。模型的工作原理是:当用户输入 URL,Exa 会爬取并解析其主要内容,模型根据文本风格、域名及核心观点等因素,预测相似讨论的网页。
用 Transformer 直接做搜索系统输出链接则需要记住整个互联网非常困难。所以 Exa 在 transformer 的基础上改进模型并不断迭代架构,把 next token prediction 变成了 next link prediction 和 next document prediction,让搜索系统实现预测最相关的网页。
CEO 认为,基于 transformer 的架构为 Exa 的搜索系统带来了另外一个差异价值:投入的计算资源越多,查询结果可以不断变得更全面、更精准。Exa 官方也给出了一个实验证明:当其让模型花更多的 test time compute 进行搜索,模型就能得到更多的匹配结果。Websets 的能力正是建立在这样的模型之上:一份包含上千个结果的 Websets 列表可能需要一个小时来响应,但这样用户能够得到一份完美的结果。
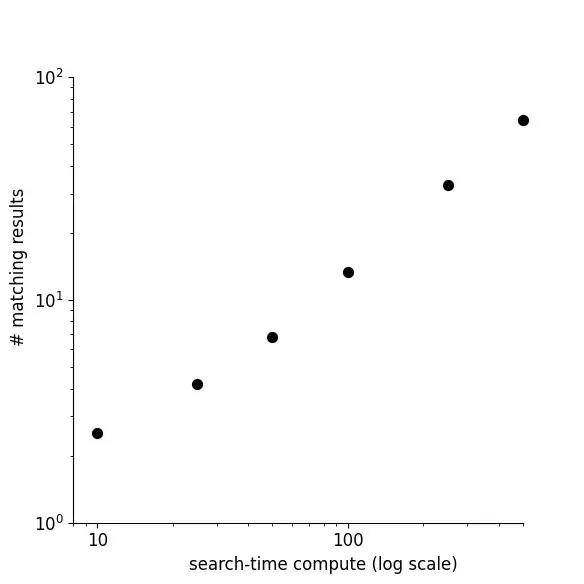
With Websets, Exa discovered a new scaling law, but for search. The more compute your search uses, the more comprehensive the results.
因此,公司自始就重视计算资源,比如种子轮融的 500 万美金花了一半买计算资源,公司部署的 AftaCluster 是该行业最早基于 NVIDIA 的 H200 GPU 的 AI 和 HPC 的集群之一。

Exa 团队是在 ChatGPT 发布就一年前建立的,联合创始人 Will Bryk 和 Jeff Wang 是 Harvard 的室友。
Will Bryk 在 Harvard 学习 CS 和物理,曾在 SpaceX 工作,并在 Cresta 有两年的工作经验。
Jeff Wang在 Harvard 学习 CS 和哲学,毕业后在 Plaid 担任了两年的工程师。
Exa 的搜索系统是从头构建了爬虫系统、嵌入模型、向量数据库、AI 处理系统,以高吞吐量、低延迟的方式提供服务。这里每个技术部分 Google 都有上百数千人的团队,而对应 Exa 每个部分只有 1~2 人。Exa 目前核心技术团队不到 20 人,来自清华姚班、Palantir,Apple,Adobe、量化交易等等,人数虽少但每一个都有独当一面的能力。
未来 LLM 会成为所有 agent 的底层,LLM 需要搭配不同的工具才能成为完善的 AI agent。例如 LLM 启用 Figma 可以用于设计,LLM 启用 Exa 则可以完成搜索。由于把 LLM 连接到实时互联网基本已经成为 agent 的刚需,所以 Search API 是 LLM 必备的工具。
Exa 的技术相比于现有的 search API 有两个差异点:
1)传统的搜索 API 主要用于快速搜索,难以满足复杂的查询,Exa 可以实现更复杂的语义搜索。
2) Exa 的架构让用户可以选择投入更多的计算资源、等待更长的时间,来获得更多、更完善的搜索结果。这个技术点在 Websets 中很好地展示了产品层面的差异化、独特性,并且符合很多工作场景的需求,比如:销售人员 mapping 潜在客户;分析师 mapping 投资标的、竞品;求职者 mapping 工作机会、学者 mapping 领域内的论文等等。人们做类似的 mapping 原本都需要花费大量的搜索时间,现在都可以把它交给 Websets。
Exa 的 Websets 本身也是一个定义得很好的 agent 形态,RL 最擅长在 verifiable environment 中不断增强能力解决一个端到端的问题,Websets 根据用户的 criteria 构建出一个表格是很容易 verify 搜索结果是否符合用户定义的标准的。
作为面向 Agent 的 search engine,Exa 常常被拿来和 Google、LLM,Deep research 进行对比。
首先,Exa 不会颠覆 Google,它做的是 Google search 做不了的事情。
举个最直观的例子,如果在 Google 搜索 “AI start ups with VC funding based in California” ,根据关键字匹配的逻辑,返回的结果通常是某个博主写的“Top 10 AI companies in California”之类的博客。相比之下,Exa 可以根据相关性的逻辑返回一个个具体的公司。
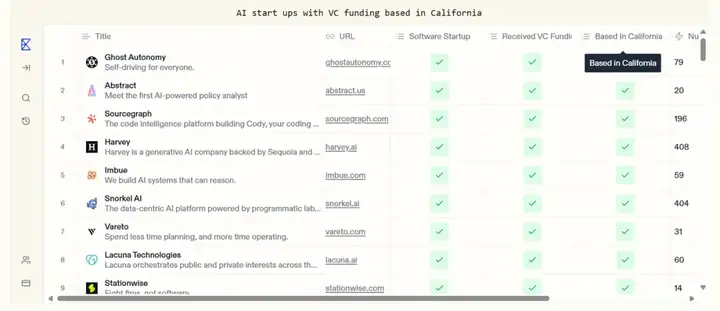
Exa 的回答
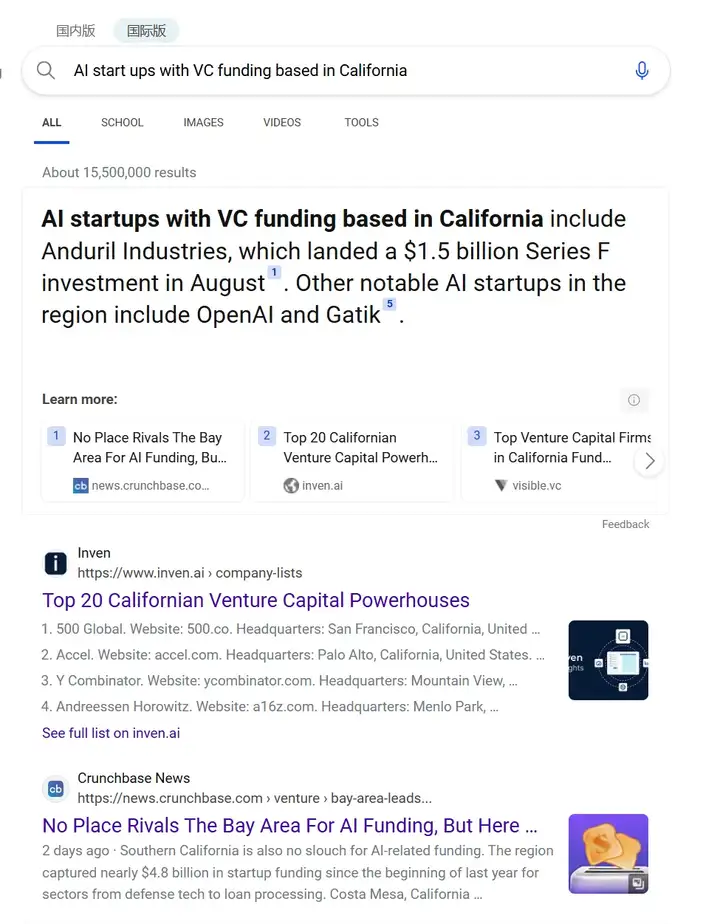
Bing 的回答
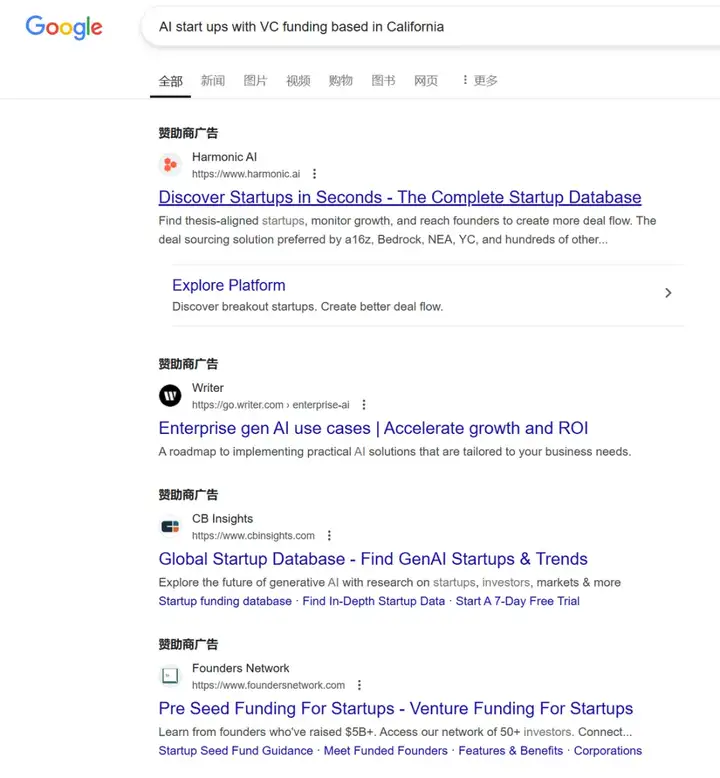
Google 的回答(Google 的广告是最多的)
另外对比现在的搜索市场。Google 收入上限通常受限于广告变现能力,例如 Google 每千次浏览可能赚 1 美分左右,因此每页浏览的语言模型推理成本必须远低于此收入才能盈利。目前 LLM 的竞争让其成本急速下降,这也为重新设计 AI-native 的搜索算法打开了可能的窗口。
Exa 不和 LLM 竞争,而更像 LLM 的补充工具。作为 agent infra, Exa定位是在 LLM 的能力之上构建实时的、最相关的 search engine,将 LLM 的智能与互联网的知识链接起来。
从 deep research 的角度看竞争, deep research 能不能实现 Websets 的能力?我们认为 Exa 的 Websets 是比 deep search 定义更清晰的 agent。这里用一个测试例子来说明 Exa 和 deep search 的差异点。我们给出的 prompt:“act as a recruiter, help a AI-native startup look for 10 software engineers with Rust programming experience who are currently in San Francisco”,以下分别是 Exa、Grok3 deep research 和 ChatGPT deep search 的输出结果:
这三个产品中,只有 Exa 输出了一系列符合要求的联系人:
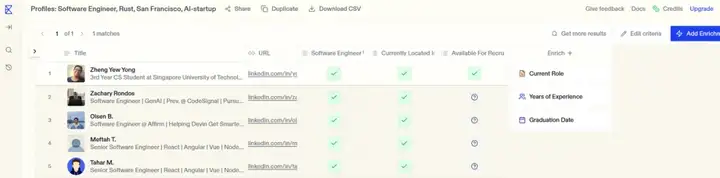
Grok 3 deep search 的输出的是 HR 应该以什么步骤、什么渠道发布 job description:
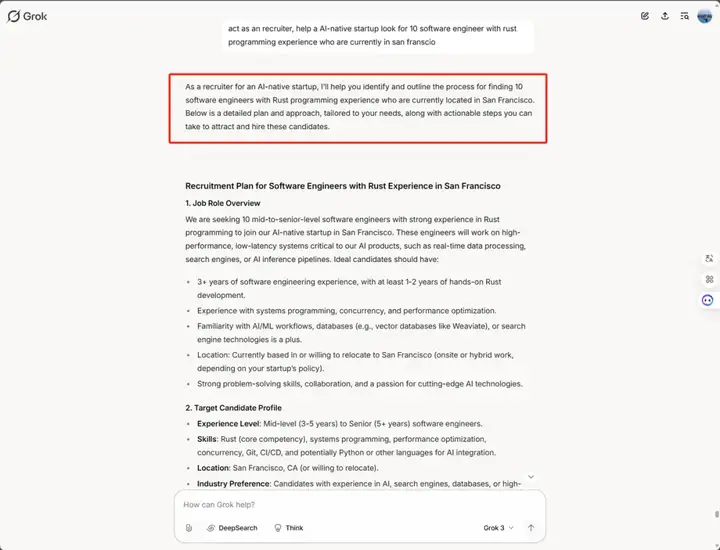
ChatGPT deep search 输出的是 10 份招聘信息:
Deep research 专注搜索+推理研究,Exa Websets 更专注搜索。论智能、论速度、论研究能力,Exa 其实都不是 ChatGPT 和 Grok 3 deep research 产品的对手。Exa 的差异位在于利用 built from ground up 的 index、vector,用自研的模型提供最相关的搜索。因此 Exa 更有可能成为 Deep research 产品底层的信息 infra。
在“AI搜索”的语境中,Exa 的竞争对手并不是 perplexity 等 AI 搜索产品,而是其他围绕 context 场景提供价值的 Agent Infra,其中的典型代表是 Brave Software。Brave Software 的产品包括浏览器 Brave Browser、搜索产品 Brave Search,插件助手 Leo AI 等。
Brave 成立于 2015 年,CEO Brendan Eich 是 JavaScript 的创造者,曾是 Mozilla 的联合创始人。
2025 年 2 月推出的 Mistral 的聊天机器人平台 Le Chat 就使用的是 Brave 的搜索 API 获取实时网页结果。3 月下旬 Claude 推出了网页搜索功能,目前不清楚由哪个搜索引擎提供支持,但根据 TechCrunch 信息,Claude 有可能在使用 Brave Search 作为搜索引擎。
融资方面,Exa 2021 年成立,2021 年 8 月份是在 YC accelerator 拿了 13 万美金;随后 9 月份融了 500 万的种子轮,投资者有 Lombardstreet Ventures, TSVC, Pioneer Fund,Helium-3 Ventures,Atypical Ventures, Pi Campus, Soma CAPItal 和 SLVC。2024 年 7 月,公司进行了 2200 万美金的 A 轮融资,由 Lightspeed 领投,英伟达, YC,WndrCo 和 Haystack 跟投。估值方面并未透露。
经营方面,Exa 主要通过 API 创收,将其出售给拥有 AI 应用的企业或需要内部构建 agent 的公司,例如金融、销售行业,用例涵盖了非常广泛的领域。公司在 2024 年 7 月 A 轮融资时透露:目前用户数量在数千家,收入在过去几个月内增长了 3 倍。如果我们按 1000* 800/月*12月来估算,ARR 至少 960 万美金,但考虑企业的合同都是高度定制化的,所以实际收入应该更多。
文章来自于“海外独角兽”,作者“拾象”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
