# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。
受到基于规则的强化学习(Rule-Based Reinforcement Learning)在 R1 上成功应用的启发,中科院自动化研究所与中科紫东太初团队探索了如何结合高质量指令对齐数据与类 R1 的强化学习方法,进一步增强图文大模型的视觉定位能力。该方法首次在 Object Detection、Visual Grounding 等复杂视觉任务上,使 Qwen2.5-VL 模型实现了最高 50% 的性能提升,超越了参数规模超过 10 倍的 SOTA 模型。
目前,相关工作论文、模型及数据集代码均已开源。

目标定位任务要求模型能够精准识别用户输入的任意感兴趣目标,并给出精确的目标框,对图文大模型的细粒度感知和空间理解能力提出了严峻挑战。当前,图文大模型通常将目标定位建模为文本序列预测任务,并通过大规模预训练和指令数据的监督微调,以 Next Token Prediction 实现对不同粒度目标描述的精准定位。尽管在指代表达理解等任务上已超越传统视觉专家模型,但在更复杂、目标密集的场景中,其视觉定位与目标检测能力仍与专家模型存在显著差距。
R1 的成功应用推动了对基于规则的任务级别奖励监督的探索,使模型摆脱了对人工偏好数据标注和奖励模型训练的依赖。值得注意的是,视觉定位指令数据本身具有精准的空间位置标注,并与与人类对精准目标定位偏好高度一致。基于这些优势,Vision-R1 通过设计类 R1 的强化学习后训练框架,在任务级别监督中引入基于视觉任务评价指标的反馈奖励信号,为增强图文大模型的细粒度视觉定位能力提供了创新突破方向。
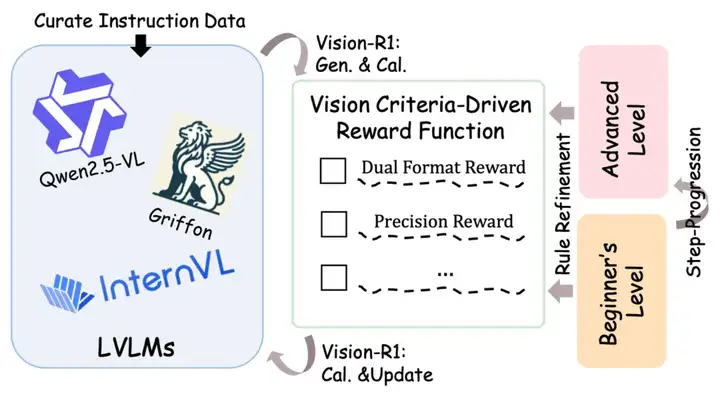
Vision-R1 关键设计示意图
在文本序列的统一建模和大规模数据的自回归训练下,图文大模型在目标定位任务上取得了显著的性能提升。然而,其进一步发展仍受到三大关键问题的限制:(1)密集场景中的长序列预测易出现格式错误,(2)有效预测目标的召回率较低,(3)目标定位精度不足。
这些问题制约了模型在更复杂视觉任务上的表现。在自回归 Token 级别的监督机制下,模型无法获得实例级别的反馈,而直接在单目标场景下应用 GRPO 训练方法又忽视了视觉定位任务的特性及 Completion 级别监督的优势。
为此,研究团队结合图文大模型在视觉定位任务中面临的挑战,提出了一种基于视觉任务评价准则驱动的奖励函数,其设计包括以下四个核心部分:
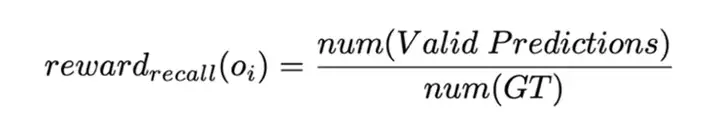
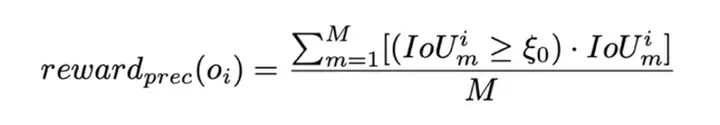
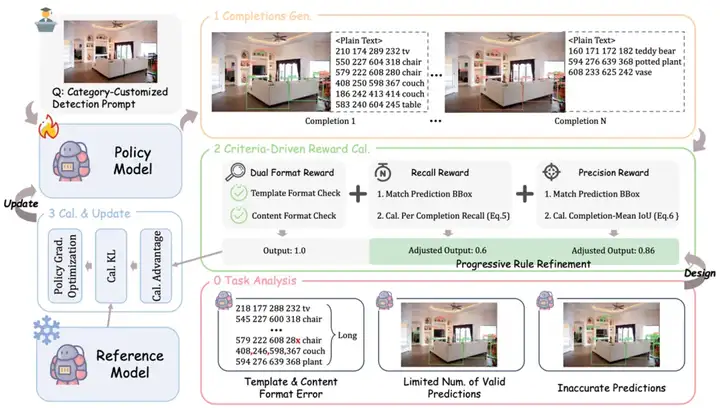
Vision-R1 整体框架
在目标定位任务中,预测高质量(高 IoU)的目标框始终是一个挑战,尤其是在密集场景和小目标情况下。这种困难可能导致模型在同组预测中奖励差异较小,从而影响优化效果。针对这一问题,研究团队提出了渐进式规则调整策略,该策略通过在训练过程中动态调整奖励计算规则,旨在实现模型的持续性能提升。该策略主要包括两个核心部分:
差异化策略:该策略的目标是扩大预测结果与实际奖励之间的映射差异。具体而言,通过惩罚低召回率(Recall)和低平均 IoU 的预测,并对高召回率和高 IoU 的预测给予较高奖励,从而鼓励模型生成更高质量的预测,尤其是在当前能够达到的最佳预测上获得最大奖励。这一策略引导模型在训练过程中逐渐提高预测精度,同时避免低质量预测的奖励过高,促进其优化。具体实现如下:
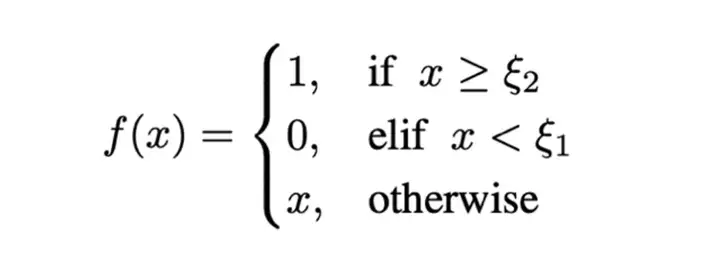
阶段渐近策略:类似于许多有效的学习方法,给初学者设定容易实现的目标并逐步提升奖励难度是一个常见且行之有效的策略。在 Vision-R1 中,训练过程被划分为初学阶段和进阶阶段,并通过逐步调整阈值 ζ 来实现奖励规则的逐渐变化。具体来说:
为全面评估 Vision-R1 的效果,研究团队选择了近期定位能力大幅提升的 Qwen2.5-VL-7B 模型和定位能力突出的 Griffon-G-7B 模型,在更有挑战的经典目标检测数据集 COCO 和多样场景的 ODINW-13 上进行测试,以展现方法对不同定位水平模型的适用性。
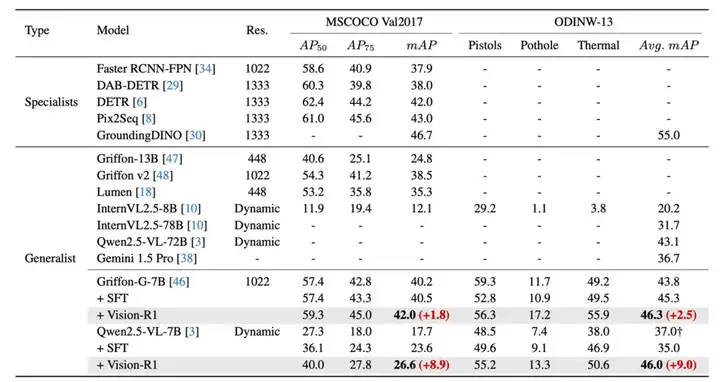
经典 COCO/ODINW 数据集上 Vision-R1 方法相较于基线模型性能的提升
实验结果表明,无论基础性能如何,与基线模型相比这些模型在 Vision-R1 训练后性能大幅提升,甚至超过同系列 SOTA 模型,进一步接近了定位专家模型。
研究团队还在模型没有训练的域外定位数据集上进行测试,Vision-R1 在不同模型的四个数据集上取得了平均 6% 的性能提升,充分论证了方法的泛化性。
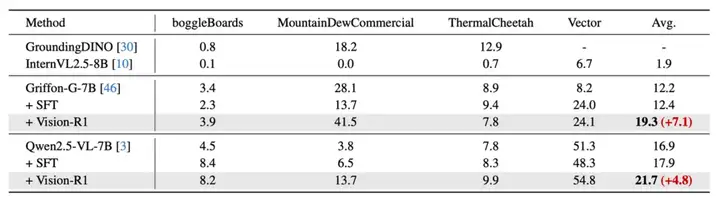
域外数据集上 Vision-R1 方法相较于基线模型性能的提升
研究团队进一步评估了模型在非定位等通用任务上的性能,以验证方法是否能在少量影响模型通用能力的情况下,大幅度提升模型的视觉定位能力。研究团队发现,Vision-R1 近乎不损失模型的通用能力,在通用问答、图表问答等评测集上模型实现了与基准模型基本一致的性能。
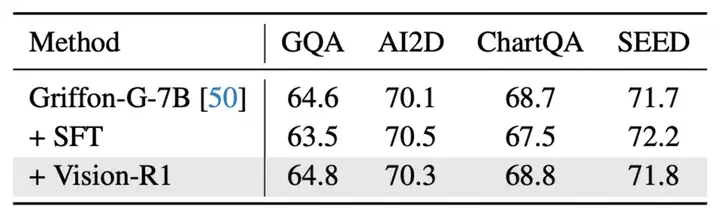
通用问答数据集上 Vision-R1 方法与基线模型性能的比较
研究团队提供了在 Qwen2.5-VL-7B 模型上使用 Vision-R1 后在多个场景下的目标检测可视化结果。如结果所示,Vision-R1 训练后,模型能够更好召回所感兴趣的物体,并进一步提升定位的精度。

Vision-R1 训练模型与基准模型检测结果可视化
文章来自于“机器之心”,作者“机器之心”。




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
