# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在信息检索系统中,搜索引擎的能力只是影响结果的一个方面,真正的瓶颈往往在于:用户的原始 query 本身不够好。
尤其在专业搜索场景(如文献、数据库查询)中,用户往往无法用精确、完整的表达描述他们的需求。
那么问题来了:能不能教大模型优化原始 query 的表达方式,从而让已有检索系统的能力被最大化激发?
来自 UIUC 的 Jiawei Han 和 Jimeng Sun 团队的一项最新工作 DeepRetrieval 就是针对这个问题提出了系统性解法,只需 3B 的 LLM 即可实现 50 个点以上的提升。

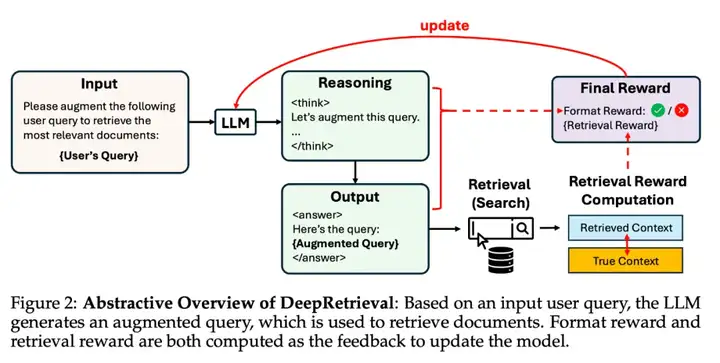
一句话概括:DeepRetrieval 是一个基于强化学习(RL)的 query 优化系统,训练 LLM 在不同检索任务中优化原始查询,以最大化真实系统的检索效果。
它不是训练一个新的 retriever,也不是让模型直接回答问题,而是:
在不改变现有搜索系统的前提下,通过优化原始 query,让「提问方式」变得更聪明,从而获取更好的结果。
更多有意义的讨论请读原文正文和附录的 Discussion 部分。
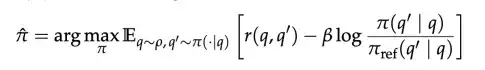
其中,π_ref 是参考策略(reference policy),通常指的是在强化学习开始之前的初始模型。β 是一个合适的 KL 惩罚系数,用于控制正则化的强度。KL 散度项的作用是惩罚当前策略与参考策略之间的过大偏离,从而在强化学习训练过程中保证策略更新的稳定性。
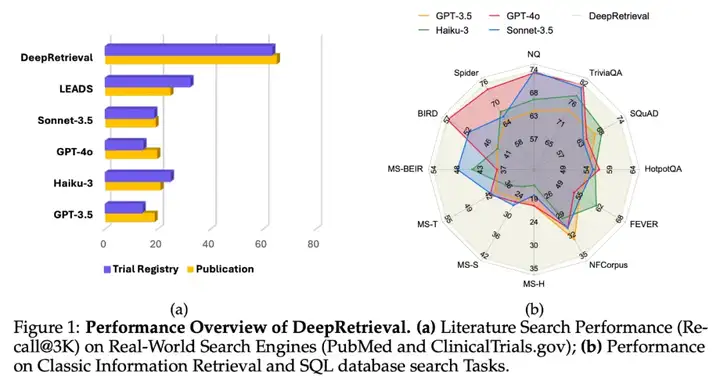
首先在真实的搜索引擎上进行实验,文中用到了专业搜索引擎 PubMed 和 ClinicalTrials.gov。无需改动搜索引擎或其它任何检索器,仅通过端到端地优化 query 表达,DeepRetrieval 就可以让结果获得 10 倍提升,远超各个商业大模型和之前的 SOTA 方法 LEADS(蒸馏 + SFT 方法)。
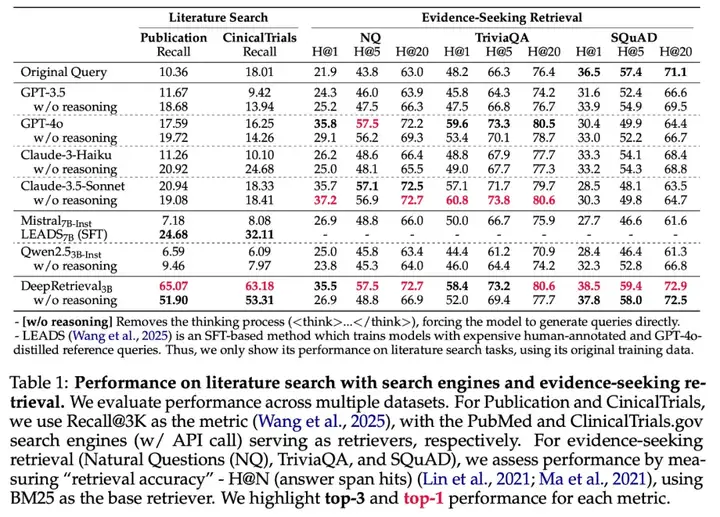
DeepRetrieval 在 Evidence-Seeking 检索任务上的优异表现令人瞩目。如表 1 所示,结合简单 BM25,这个仅有 3B 参数的模型在 SQuAD、TriviaQA 和 NQ 数据集上超越了 GPT-4o 和 Claude-3.5 等大型商业模型。
Evidence-Seeking 任务的核心是找到支持特定事实性问题答案的确切文档证据,在通用搜索引擎环境中,这一能力尤为关键。作者团队指出,将 DeepRetrieval 应用到 Google、Bing 等通用搜索引擎的 Evidence-Seeking 场景将带来显著优势:
作者团队表示会将这部分的延伸作为 DeepRetrieval 未来主要的探索方向之一。
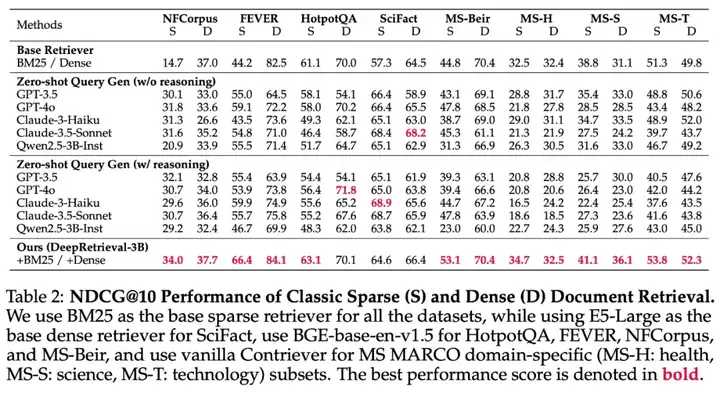
在 BM25 和 dense retriever 下,DeepRetrieval 提供了平均 5~10 点 NDCG 提升,并且:BM25 + DeepRetrieval 和多数 dense baseline 水平相当。
结合极快的检索速度(BM25 vs dense:352s vs 12,232s),展示了一个现实可部署、性能不俗的高效方案。
在 SQL 检索任务中,DeepRetrieval 摆脱了对 groundtruth SQL 的依赖,直接利用生成 SQL 的执行成功率优化模型,通过生成更精准的 SQL 语句,使得模型在 Spider、BIRD 等数据集上的执行正确率均超过对比模型(包括 GPT-4o 和基于 SFT 的大模型)。
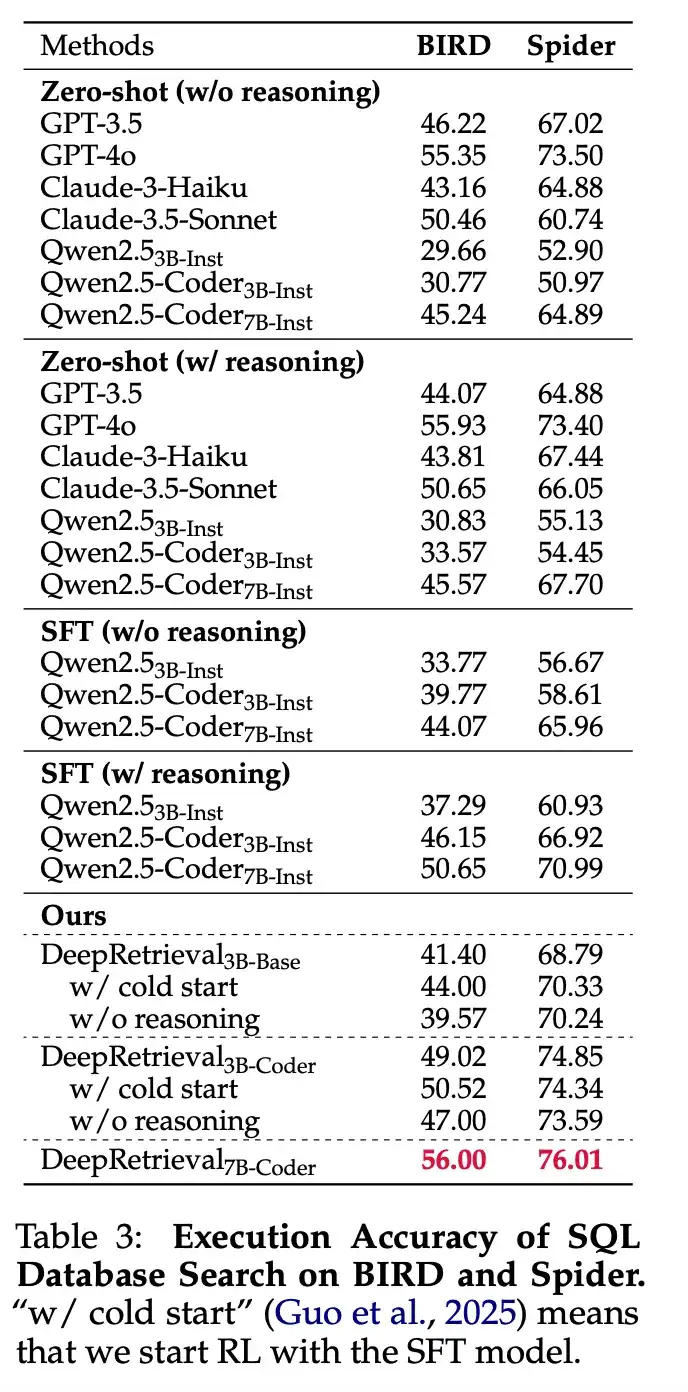
DeepRetrieval 的实验揭示了强化学习(RL)在搜索优化上相比监督微调(SFT)的独特优势。实验数据令人信服:在文献搜索上,RL 方法的 DeepRetrieval(65.07%)超过 SFT 方法 LEADS(24.68%)近三倍;在 SQL 任务上,从零开始的 RL 训练(无需任何 gold SQL 语句的监督)也优于使用 GPT-4o 蒸馏数据的 SFT 模型。
这种显著差异源于两种方法的本质区别:SFT 是「模仿学习」,试图复制参考查询,而 RL 是「直接优化」,通过环境反馈学习最优查询策略。SFT 方法的局限在于参考查询本身可能不是最优的,即使是人类专家或大模型也难以直观设计出最适合特定搜索引擎的查询表达。
论文中的案例分析进一步证实了这一点。例如,在 PubMed 搜索中,DeepRetrieval 生成的查询如「((DDAVP) AND (Perioperative Procedures OR Blood Transfusion OR Desmopressin OR Anticoagulant)) AND (Randomized Controlled Trial)」融合了医学领域的专业术语和 PubMed 搜索引擎偏好的布尔结构,这种组合很难通过简单模仿预定义的查询模板获得。
相反,RL 允许模型通过尝试与错误来探索查询空间,发现人类甚至未考虑的有效模式,并直接针对最终目标(如 Recall 或执行准确率)进行优化。这使 DeepRetrieval 能够生成高度适合特定搜索引擎特性的查询,适应不同检索环境的独特需求。
这一发现具有重要启示:在追求最佳检索性能时,让模型通过反馈学习如何与检索系统「对话」,比简单模仿既定模式更为有效,这也解释了为何参数量较小的 DeepRetrieval 能在多项任务上超越拥有更多参数的商业模型。
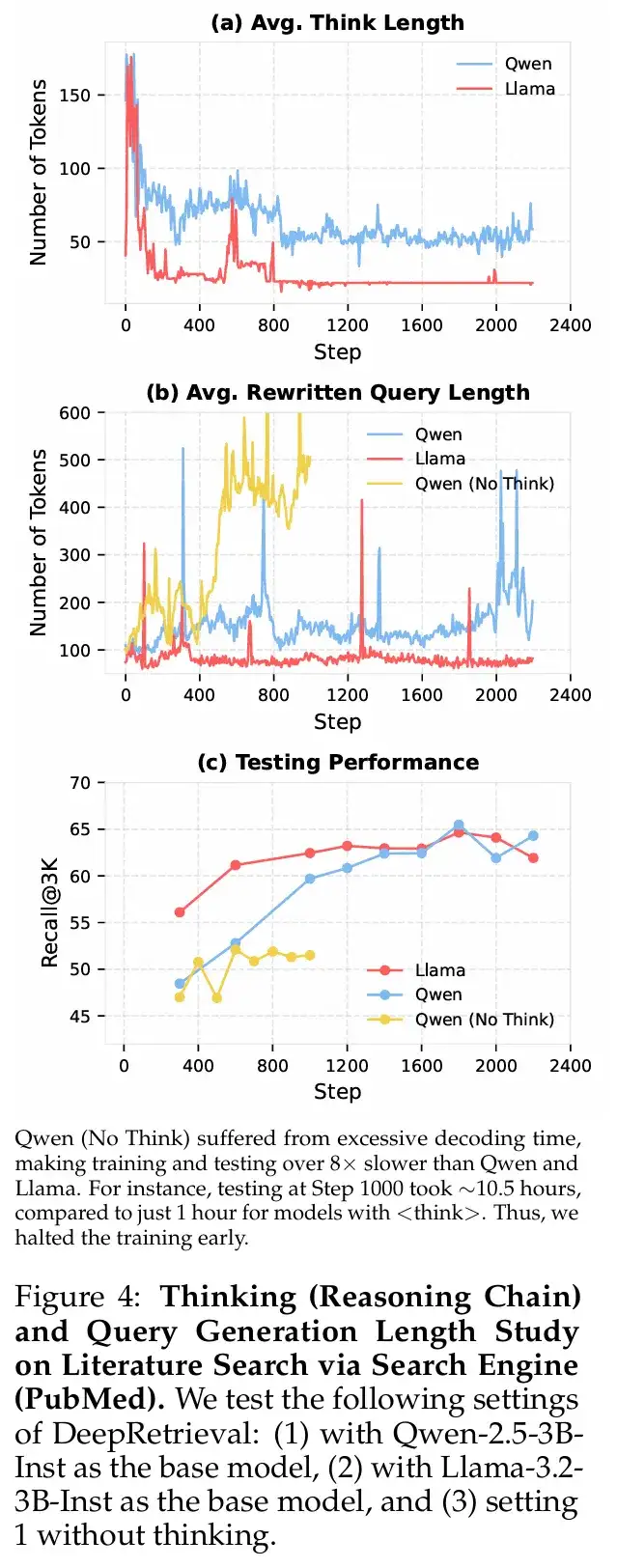
通过分析 DeepRetrieval 在训练过程中模型思考链和查询长度的变化,可以发现以下关键洞见:
与「aha moment」相反,DeepRetrieval 的思考链长度随训练呈下降趋势,而非增长。这与 DeepSeek-R1 报告的「aha moment」现象形成鲜明对比,后者的思考链会随训练进展变得更长。图 4(a) 清晰地展示了 Qwen 模型思考链从初始约 150 tokens 逐渐降至稳定的 50 tokens 左右,而 Llama 模型的思考链更短,甚至降至接近 25 tokens。
实验揭示了思考过程对查询长度的显著影响。无思考过程的模型容易陷入次优解,如图 4(b) 所示,Qwen 无思考版本生成极长查询(500-600 tokens),表现出过度扩展的倾向。相比之下,有思考过程的模型保持更为适中的查询长度,Qwen 约 150 tokens,Llama 约 100 tokens。有趣的是,不同模型采用不同长度策略,但能达到相似性能,表明查询生成存在多样有效路径。
思考过程对检索性能有决定性影响。图 4(c) 表明,具备思考能力的模型性能显著提升,有思考的模型 Recall@3K 能达到 65%,而无思考模型仅 50% 左右。此外,训练效率也明显提高,有思考的模型更快达到高性能并保持稳定。论文附录 D.1 的分析表明,思考过程帮助模型避免简单地通过增加查询长度和重复术语来提升性能,而是引导模型学习更有效的语义组织策略。
DeepRetrieval 展示了思考过程在信息检索中扮演「探索促进器」的关键角色。与数学或编程问题不同,检索任务不需要像「aha moment」那样的突然顿悟现象。相反,检索优化遵循「先详细思考,后逐渐精简」的模式,模型在内化有效策略后,不再需要冗长思考。这表明检索任务中思考链的主要功能是探索,一旦策略稳定便可简化。
这种分析表明,适当的思考过程设计对于构建高效的检索优化系统至关重要,能够在不增加模型参数的情况下显著提升性能,为未来的 LLM 应用于搜索任务提供了重要设计思路。
DeepRetrieval 的贡献在于揭示了一个常被忽视但至关重要的事实:检索效果的上限不仅在于检索器本身,更在于如何「提问」。
通过强化学习教 LLM 改写原始查询,DeepRetrieval 不仅摆脱了对人工标注数据和大模型蒸馏的依赖,还在多个任务上证明了改写 query 的巨大潜力。这项工作为搜索与信息检索领域带来了新的思考:未来的检索优化,不仅是提升引擎算法,更是如何让用户「问得更好」,从而激发出检索系统的全部潜力。
文章来自于“机器之心”,作者“机器之心”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
