# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
CUDA 迎来 “Python元年”!
今年,英伟达可谓是全力押注,明确表示要确保 Python 成为 CUDA 并行编程框架中的“一等公民”。
多年以来,英伟达为 GPU 开发的 CUDA 软件工具包始终缺少原生 Python 支持,现如今这种情况终于有所转变。在近期的 GTC 大会上,英伟达宣布其 CUDA 工具包将为 Python 提供原生支持并全面与之集成。也就是说,开发人员能够使用 Python 直接在 GPU 上执行算法式计算。
据悉,2025 年被英伟达视为“CUDA Python 元年”,这一观点已经在公司内部达成共识,并成为 GTC 大会的核心主题之一。这次发布标志着 Python 在整个生态系统中的地位进一步提升,而英伟达也在这一领域投入了大量资源。
对于程序员们来说,此举无疑影响巨大。尽管 CUDA 最初是基于 C 和 C++ 开发的,但如今程序员们无需掌握这些编程语言,也能使用该工具包进行开发。
过去,尤其是早期,甚至直到一两年前,英伟达主要依赖 C 和 C++ 这类面向系统编程的底层语言作为其主要的编程接口。开发者们通常需要在此基础上构建 Python 库,实现更高级别的应用。
事实上,许多开发者已经构建了这样的 Python 库,例如广受欢迎的 PyTorch。它作为一个强大的 Python 接口,底层连接着高性能的 C++ 代码(用于 CPU)和 CUDA C++ 代码(用于 GPU)。这些库的广泛应用,甚至在某些方面超越了英伟达自家提供的解决方案,赢得了更多的关注。
还有 OpenAI 的 Triton 等项目,它允许开发者用 Python 编写代码——其实是一种特定风格或子语言(domain-specific language),然后通过编译器把这些 Python 风格代码转化为 GPU 可运行的内容。
这些项目表明,在 GPU 编程的 Python 化方向上,已经有许多开发者先行一步,他们甚至比英伟达行动更快。不过,英伟达也注意到了这一趋势,开始加大了投入。
在去年 GTC 大会上,CUDA 架构师 Stephen Jones 指出,“在过去几年中,我非常关注 Python。当我审视 Python 开发者的生态时,我发现我的上层用户规模会呈现出爆炸式增长。我的核心用户不再是一百万,而是一千万级别。因此,这意味着,底层的改进,都将通过 Python 生态系统,在上层用户群体中产生更为广泛而深远的影响。”
同时,Jones 也特别关注了 Triton 项目,“Triton 提供了一种全新的方式,让开发者能够使用 Python 编写自定义的 GPU 内核。其语法类似于 NumPy 函数,但底层却能生成高度优化的 CUDA 内核。该项目充分利用了英伟达的编译器技术和底层优化工具链。”
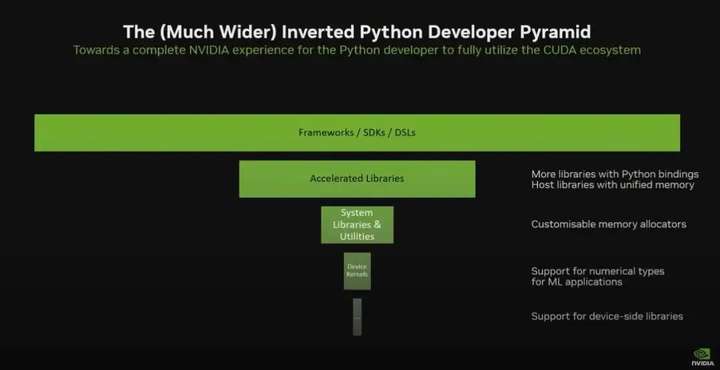
因此,英伟达认为,为了充分发挥 Python 在 GPU 计算中的潜力,必须在技术栈的各个层面进行投入。他们的整体愿景,也是 CUDA 团队的愿景,是为 Python 开发者提供完整的 NVIDIA 体验,即让整个 CUDA 生态系统都能通过 Python 编程语言进行访问和使用。
这是一个生态扩展的过程。NVIDIA 并不是放弃 C++,而是在扩大整个开发者圈层,尤其是对 Python 社区的支持上,他们正在显著加码。
在今年的 GTC 大会上,Stephen Jones 强调,Python 中的 CUDA 应该保持 Python 的自然风格,让程序员们可以使用自然的 Python 接口和脚本模型,轻松创建运行在英伟达 GPU 上的 AI 程序。Jones 还指出,Python CUDA 绝不仅仅是将 C 代码转换为 Python 语法。它必须要让 Python 开发者们感到自然且亲切。
今年英伟达对 Python 的投入和接口更新,不只是开发体验上的改善,更是 NVIDIA 在构建一个更加开放、多层次开发者生态系统方面的又一次进化。
例如,CuTile 是一个比传统 CUDA 更高层级的抽象(目前还没有正式发布),虽然底层仍依赖部分 C++ 实现,但开发者所接触的接口已完全是 Python。这意味着,开发者无需直接接触 C++,即可利用这些接口进行开发。
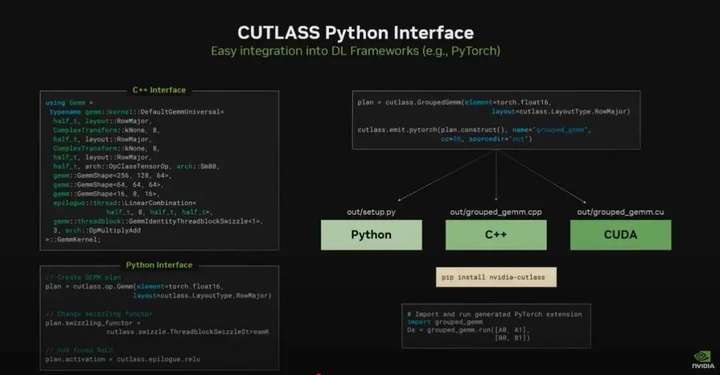
另一个例子是新的 Python 接口版本的 Cutlass。Cutlass 原本是一个专注于 GPU 高性能矩阵运算的 C++ 库。而现在英伟达推出了一个全新的 Python 接口版本,完全不需要写 C++。开发者可以直接在 Python 里构建算子,甚至进行一些低级别的优化,同时保留原有性能。
可以把它理解为英伟达正在打造一个金字塔:最底层是核心的 CUDA C++,适合极致性能的系统开发者;中间层是像 Triton 或 Python Cutlass 这种面向专业开发者的高性能 Python 接口;而顶层则是 PyTorch、这样更面向 AI 构建者和产品工程师的抽象层。
这种分层的方式非常重要,开发者可以先利用顶层工具快速进行原型设计,当需要更高的性能或更强的定制能力时,再逐步深入到更底层的接口,覆盖了不同层级的开发者。从某种意义上说,这是一种“民主化”GPU 编程的过程。它让那些熟悉 Python、但不一定懂底层系统编程的人,也能参与进来,从而加速整个生态的发展。
布道师 Charles Frye 认为,“这对 AI 开发者、研究者,甚至初创公司来说都是一个巨大利好。你不需要一个专门的 CUDA 工程师团队才能充分发挥 GPU 的性能。你可以用熟悉的工具,用更快的速度迭代、调优和部署你的模型或应用。”
“总的来说,我觉得这次 GTC 上 Cutlass 4 和相关 Python 接口的发布,标志着一个真正的转折点——从‘GPU 编程是专家游戏’,到‘人人都可以上手’的转变正在加速进行中。”
而且,据 The New Stack 报道,英伟达在将 Python 提升为 CUDA 并行编程框架核心语言的同时,也在积极招募程序员,以期在项目中支持包括 Rust 和 Julia 在内的更多编程语言。
CUDA 项目涵盖库、SDK、编译器、主机运行时、工具以及预打包的软件和算法。英伟达已经将部分组件添加至整个 Python 式 CUDA 技术栈内。
英伟达的关注重点,是在无需脱离 Python 环境的前提下实现 GPU 加速。Jones 解释道,CUDA Python 不能只是内核产品,而需要在整个技术栈内匹配完整且流畅的执行流程。
Jones 强调,“除了编写内核并将其纳入 PyTorch 之外,我们还必须能够调用 Python 库及所有其他组件。”
实际上,由于项目是围绕即时(JIT)编译构建而成,因此不存在编译器层,从而大大减少了技术栈 GPU 树中的依赖项数量。
Jones 表示,“保持所有各层之间的互操作性,将极大提高生产力并实现对 Python 的端到端使用。”
最初,英伟达先是构建了基础 Python 绑定(其中包括运行时编译器)与 cuPyNumeric(Python 中使用最就我 计算库 NumPy 的替代方案)等 Python 库。cuPyNumeric 仅变更了一条导入指令,即可将 NumPy 代码从 CPU 上运行转变为 GPU 上运行。
去年,英伟达构建了 CUDA Core,Jones 称其是“对 CUDA 运行时的 Python 式重构,确保其自然而然实现 Python 原生化。”
CUDA Core 提供 Python 执行流程,且高度依赖于 JIT 即时编译。
Jones 强调,“我们要做的不是放弃命令行编译器之类的要素,而是将一切融入到流程当中”,并补充称这大大减少了技术栈 GPU 树中的依赖项数量。
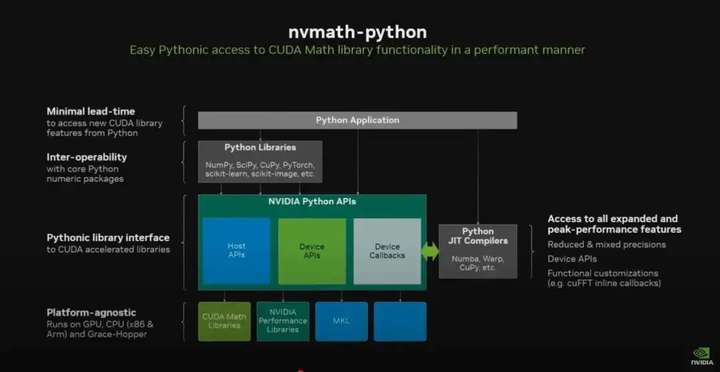
英伟达还开发了一套名为 NVMath Python 的库,其具备用于主机端和设备端库调用的统一接口。Jones 指出,这种将库调用加以融合的设计带来了巨大的性能提升。
该公司还构建了能够直接通过 Python 代码访问加速 C++ 库的多个新库。
Jones 解释道,“由于新成果建立在我们多年积累的底层基础架构之上……因此我们并不需要用 Python 做重新实现。只需要确保将其链接到经过微调的 C++ 底层代码,因此产生的性能影响几乎可以忽略不计。”
英伟达还添加了用于分析器和代码分析器的工具。
Python 大大降低了编码难度,确保程序员不必分心于底层硬件。为了更好地达成这个目标,英伟达决定添加一个在 GPU 上执行,且与更高级别抽象相一致的编码层。这套编程模型就是 CuTile,最初为 Python 式 CUDA 开发,随后又针对 C++ CUDA 提供了扩展。

CuTile“从本质上来讲更契合 Python 特性”,因为如今 Python 程序员更多关注数组而非线程(关注线程更接近 C++ 的特性)。开发人员不可能像变魔术一样直接把 Python 代码导出到 GPU 上,来直接获得加速性能。CUDA 需要先将问题拆分成成千上万个较小的块,然后在 GPU 上分别做处理。这些块被拆分成更小的 tiles,由其运行起成千上万个线程以实现单一元素处理。各线程组合起来,就形成了一项操作。
这种并行处理线程级单一元素的能力,赋予了 GPU 强大的计算性能。
但英伟达认为 GPU 执行不该始终局限于线程级别。相反,处理也可以在 tiles 层级上实现中途完成,这也是 CuTile 编程模型的意义所在。
CuTile 能够高效将数组映射至相对不太细粒度的 GPU 上,使得代码更易于理解和调试。Jones 表示,“重要的是,在根本上继续保持相同的性能。”
Tiles 中的数据可以构造为向量、张量或者数组,而编译器则能够更好地将整个数组操作从线程块映射至 GPU。
Jones 解释道,“编译器通常比程序员们做得更好,因为它能深刻理解开发者在做什么……而且熟悉 GPU 的运行细节。”
不同于 C++,Python 在设计上并不强调细粒度。
Jones 在总结时再次称赞了 OpenAI 的项目,“目前有很多相关成果,OpenAI Triton 就是个典型用例。我认为这些项目都特别契合 Python 程序。“
参考链接:
https://www.youtube.com/watch?v=Ml5lAtCSHxY
https://thenewstack.io/nvidia-finally-adds-native-python-support-to-cuda/
https://www.youtube.com/watch?v=pC0SIzZGFS
chttps://x.com/blelbach/status/1902113767066103949/photo/3
文章来自于“InfoQ”,作者“核子可乐、Tina”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
