# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在很早之前,我们就报道了UAlink。
该联盟于2024 年 5 月由一群供应商成立,其中包括 AMD、AWS、博通、思科、谷歌、HPE、英特尔、Meta、微软和 Astera Labs,
他们认为世界需要一个 Nvidia NVLink 技术的开放替代方案,以允许创建运行大规模 AI 工作负载所需的联网 GPU 集群。
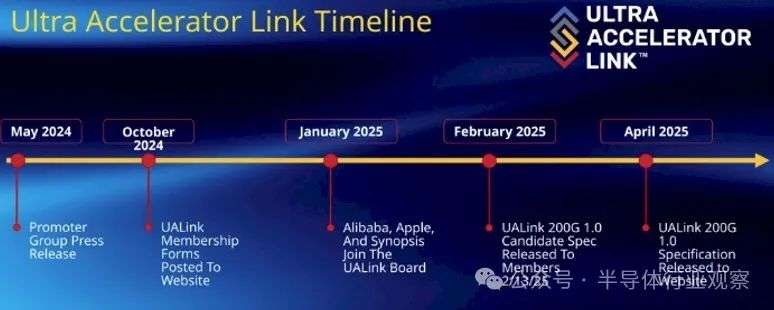
UALink 的会员们希望创建一个更便宜的替代方案,他们可以自行控制和部署超大规模,或者通过创建我们其他人购买的硬件从中获利。
他们还认为,世界已经准备好迎接一种可应用于多个供应商的 GPU 的网络标准,而不需要用户为每个加速器供应商创建专用的网络孤岛。
为了实现这些目标,UAC 还希望在大多数组织已经运营的以太网网络上开展工作。
在此前的文章《NVLink迎来劲敌:九大巨头,正式成立UALink联盟》中,我们对此有了深入的描述。
现在,这个标准的第一个版本,终于正式发布。
据官方介绍,这个名为UALink 200G 1.0 的规范定义了 AI 计算舱中加速器和交换机之间通信的低延迟、高带宽互连。
UALink 1.0 规范支持 AI 计算舱内最多 1024 个加速器实现每通道 200G 的扩展连接,为下一代 AI 集群性能提供开放标准互连。
UALink 联盟董事会主席 Kurtis Bowman 表示:“随着对 AI 计算的需求不断增长,我们很高兴能够提供一项必不可少的开放行业标准技术,
使下一代 AI/ML 应用能够推向市场。UALink 是唯一一款针对扩展 AI 的内存语义解决方案,它针对降低功耗、延迟和成本进行了优化,同时增加了有效带宽。
UALink 200G 1.0 规范带来的突破性性能将彻底改变云服务提供商、系统 OEM 和 IP/芯片提供商处理 AI 工作负载的方式。”
UALink 为加速器创建了一个交换机生态系统,为新兴的 AI 和 HPC 工作负载提供关键性能支持。
它使用读取、写入和原子事务实现跨系统节点的加速器到加速器通信,并定义了一组协议和接口,从而为 AI 应用程序创建多节点系统。
英特尔公司网络和边缘事业部高级副总裁兼总经理Sachin Katti在谈到这个新标准的时候表示:“UALink 是人工智能计算发展的重要里程碑。
英特尔很自豪能够共同领导这项新技术,并利用我们的专业知识来创建开放、动态的 AI 生态系统。
作为这个新联盟的创始成员,我们期待通过 UALink 标准带来新一波行业创新和客户价值。
这一举措扩大了英特尔对 AI 连接创新的承诺,包括在超级以太网联盟和其他标准机构中担任领导角色。”
UALink 为加速器创建了一个交换机生态系统,为新兴的 AI 和 HPC 工作负载提供关键性能支持。
它使用读取、写入和原子事务实现跨系统节点的加速器到加速器通信,并定义了一组协议和接口,从而为 AI 应用程序创建多节点系统。
据联盟总结说,UALink 的主要优势包括以下几点:
为一个舱内的数百个加速器提供低延迟、高带宽的互连;
提供简单的加载/存储协议,具有与以太网相同的原始速度和 PCIe 交换机的延迟;
专为实现 93% 有效峰值带宽的确定性性能而设计;
实现高效的开关设计,降低功耗和复杂性;
使用明显更小的芯片面积进行链路堆栈,降低功耗和采购成本,从而降低总拥有成本 (TCO);
提高带宽效率可进一步降低 TCO;
多家供应商正在开发 UALink 加速器和交换机;
利用成员公司的创新来将尖端功能纳入规范并将可互操作的产品推向市场;
UALink 联盟总裁 Peter Onufryk 表示:“随着 UALink 200G 1.0 规范的发布,UALink 联盟的成员公司正在积极构建一个开放的生态系统,以扩大加速器连接。
我们很高兴看到各种解决方案即将进入市场,并支持未来的 AI 应用。”
正如Dell'Oro Group 副总裁 Sameh Boujelbene 所说,AI 正以前所未有的速度发展,开启了具有新扩展定律的 AI 推理新时代。
随着计算需求激增和速度要求继续呈指数级增长,扩展互连解决方案必须不断发展,以跟上这些快速变化的 AI 工作负载要求。
我们很高兴看到 UALink 1.0 规范的发布,该规范通过在同一 AI 计算舱内为多达 1,24 个加速器实现每通道 200G 的扩展连接来应对这一挑战。
这一里程碑标志着我们在满足下一代 AI 基础设施需求方面迈出了重要一步。
其实当 UALink 小组成立时,其成员对于他们究竟会怎么做和做什么有些含糊其辞。
有人说 PCI-Express 和以太网不是合适的东西,因为已经做的事情简单而优雅,网络生态系统应该很容易采用和产品化。
制造 PCI-Express 交换机的公司(Astera Labs、Broadcom、Marvell 和 Microchip)将希望制造 UALink 交换机,
我们将其称为 UASwitch,以区别于计算引擎上的 UALink 端口。
具体到UALink 1.0 规范,则定义了一种用于加速器的高速、低延迟互连,支持每通道 200 GT/s 的最大双向数据速率,
信号传输速率为 212.5 GT/s,以适应前向纠错和编码开销。UALink 可配置为 x1、x2 或 x4,四通道链路在发送和接收方向上均可实现高达 800 GT/s 的速度。
一个 UALink 系统支持通过 UALink 交换机连接的最多 1024 个加速器(GPU 或其他),每个加速器分配一个端口和一个 10 位唯一标识符以实现精确路由。
UALink 电缆长度优化为 <4 米,在 64B/640B 有效载荷下实现 <1 µs 的往返延迟。这些链路支持跨一到四个机架的确定性性能。
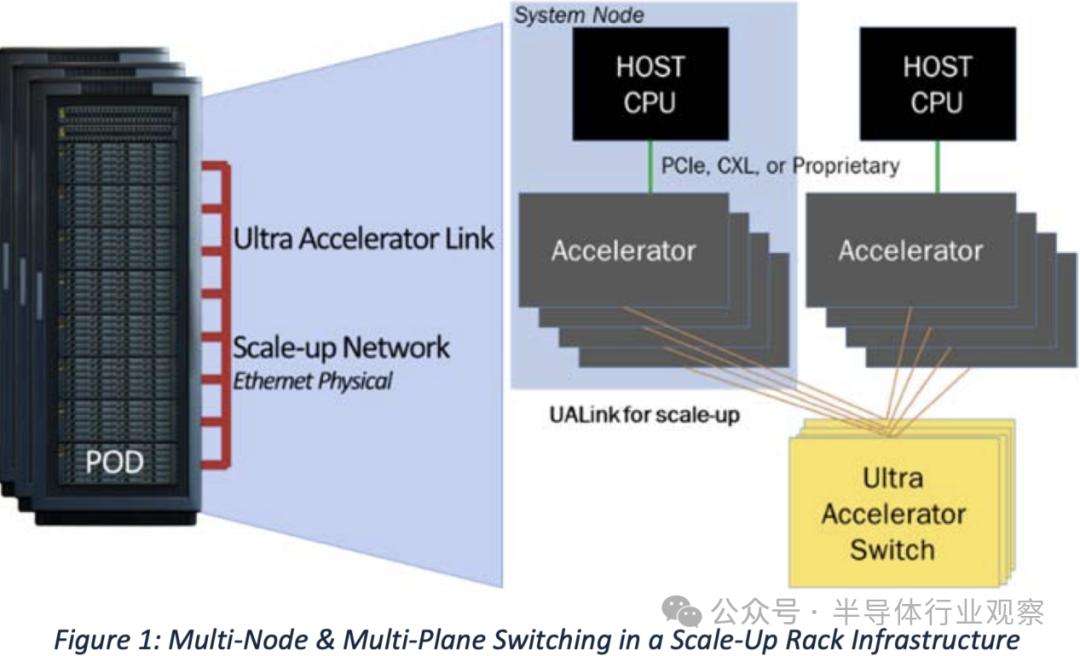
UALink 协议栈包括四个硬件优化层:物理层(physical)、数据链路层(data link)、事务层(transaction)和协议层(protocol)。
物理层使用标准以太网组件(例如 200GBASE-KR1/CR1),并包括使用 FEC 减少延迟的修改。
数据链路层将来自事务层的 64 字节 flit 打包成 640 字节单元,应用 CRC 和可选重试逻辑。该层还处理设备间消息传递并支持 UART 样式的固件通信。
事务层实现压缩寻址,在实际工作负载下以高达 95% 的协议效率简化数据传输。
它还支持直接内存操作,例如加速器之间的读取、写入和原子事务(atomic transactions),从而保留本地和远程内存空间之间的顺序。
由于它面向现代数据中心,UALink 协议支持集成的安全和管理功能。
例如,UALinkSec 为所有流量提供硬件级加密和身份验证,防止物理篡改,
并通过租户控制的可信执行环境(如 AMD SEV、Arm CCA 和 Intel TDX)支持机密计算。
该规范允许虚拟 Pod 分区,其中加速器组通过交换机级配置在单个 Pod 内隔离,以在共享基础架构上实现并发多租户工作负载。
而UALink Pod 将通过专用控制软件和固件代理使用 PCIe 和以太网等标准接口进行管理。通过 REST API、遥测、工作负载控制和故障隔离支持完全可管理性。
具体而言,从外到内,UALink 堆栈从稍微修改过的以太网 SerDes 开始,其信号速率为 215.5 GT/秒,
一旦考虑到编码开销,每个 UALink 通道的带宽就会减少到 200 Gb/秒:
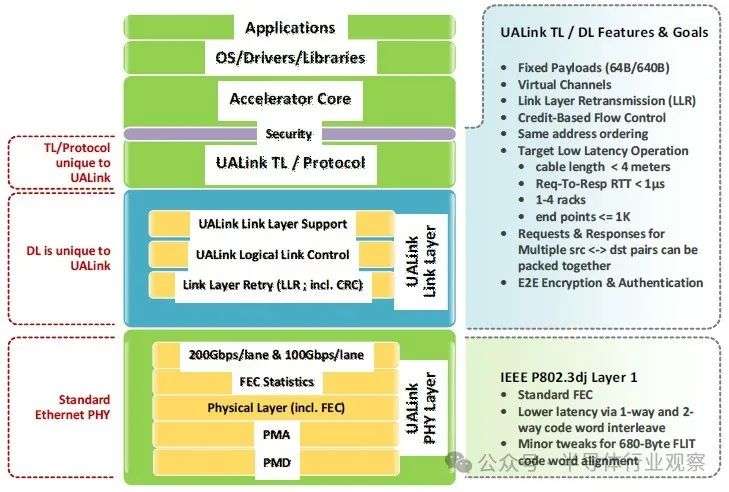
此以太网物理层具有标准前向纠错 (FEC) 并遵守 IEEE P802.3dj 规范。通过单向和双向代码字交织改善了延迟,并且略有变化以支持 680 字节 flit。
(flit 或流控制单元是链路级别的数据原子单位。)这是巧妙之处,PCI-Express 已随 6.0 规范发生变化并为 UALink 奠定了基础。
随着 PCI-Express 6.0 的推出,控制该标准的 PCI-SIG(主要由英特尔主导)不再仅仅实施标准 FEC(这会大幅增加 PCI-Express 数据传输的延迟),
而是转向混合使用流量控制和循环冗余校验 (CRC) 错误检测,这实际上提高了信号传输的可靠性,同时降低了延迟。
一些智能功能正在添加到 UALink 中,而内存结构不需要的大量功能并未包含在内。
“我们从 200 Gb/秒 SerDes 开始,”受雇主委托从事 UALink 工作的英特尔研究员 Peter Onufryk 表示:
“它每个端口有四个通道,速度为 800 Gb/秒,您可以聚合多个端口。您还可以在结构中使用多达 1,024 个加速器,因此它在我们所处的空间中可扩展性相当高。”
UALink 是一种简单的协议,因此它不是 PCI Express,但它针对扩展结构进行了优化,具有简单的内存读写和原子操作以及大型操作。
它消除了 PCI-Express 的排序限制,因此唯一的排序是在 256 字节边界内。但如果跨越,您可以重新排序。
“UALink 的思考方式是,它具有 PCI-Express 交换机的延迟、PCI-Express 交换机的功率、PCI-Express 交换机的面积,但具有以太网 SerDes。”
Peter Onufryk强调。
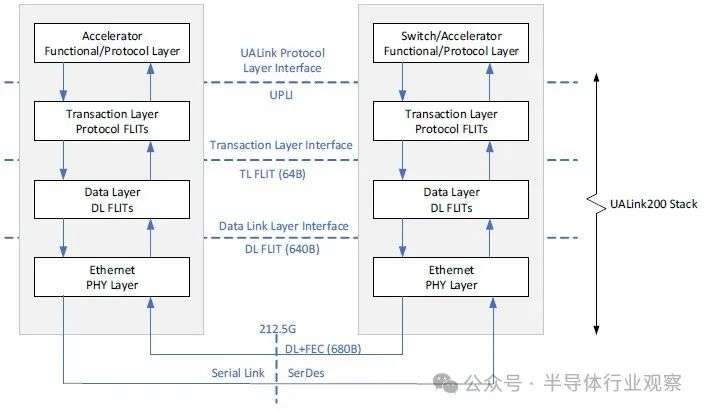
顺便说一句,1024 个计算引擎一致性限制仅限于 UALink 交换基础设施的单层。如果要添加更多层级(这会增加延迟),您可以为计算引擎构建更大的 NUMA 域。
UALink 1.0 规范支持每通道 100 Gb/秒和 200 Gb/秒的速度,前者用于构建 100 Gb/秒、200 Gb/秒和 400 Gb/秒的端口,
后者用于构建 200 Gb/秒、400 Gb/秒和 800 Gb/秒的端口。
我们不知道未来的 UASwitch 会有多少个端口,所以我们不知道它与任何现有的 NVSwitch 相比如何。
但显然,如果 Nvidia 能够整合端口以从设备中获取更多带宽,那么 UALink 的采用者也可以做到。
在UALink 1.0 的演示文稿中,有一句话很有趣,那就是——“专为确定性性能而设计,可实现 93% 的有效峰值带宽。”这是在之前的资料中没有看到过的。
UALink 成员在今年早些时候的演示中表示,UALink 的功耗仅为同等以太网 ASIC 芯片面积的一半到三分之一(每个端口),
并且每个内存结构加速器可节省 150 瓦到 200 瓦的功耗。更小的芯片尺寸意味着更便宜的芯片,更低的功耗意味着更少的电力和冷却消耗,从而降低整体 TCO。
这些演示还表示,UALink 端口到端口的跳变延迟将低于 100 纳秒。
Onufryk 表示,根据 PCI-Express 交换机的基数和品牌,PCI-Express 交换机的端口跳变延迟最低为 70 纳秒,最高为 250 纳秒。
在 21 世纪初的商用芯片时代,我们看到 10 Gb/秒以太网交换机的延迟为 350 纳秒到 450 纳秒,
而普通以太网交换机的延迟达到 1 毫秒甚至 2 毫秒的情况也很常见。与 InfiniBand 交换机 100 纳秒到 120 纳秒的延迟相比,这个延迟相当高。
UALink 联盟并未强制执行延迟限制,因此供应商可以自行决定。
AMD 架构与战略总监、UALink 项目联合负责人兼 UALink 联盟主席库蒂斯·鲍曼 (Kutis Bowman) 表示,
UALink 交换机的延迟时间在 100 纳秒到 150 纳秒之间“感觉合适”。
“就像任何事情一样,”鲍曼说。“一旦第一批Switch推出,他们就会想办法改进。
我们可能会看到一些不错的中端数据,然后,随着时间的推移,他们会把这个数字往左移。”
至于这些交换机的基数(即它们驱动多少条通道和端口,以及总带宽是多少),这也取决于 UALink 交换机制造商。
“我们已经指定了物理层,也指定了数据包如何根据ID路由,人们可以随心所欲地构建,”Onufryk说。
“这就像PCI-Express——有些人构建小型交换机,有些人构建大型交换机,他们都在努力找到正确的位置。”
从概念上讲,UALink 机架式机柜可能如下所示:
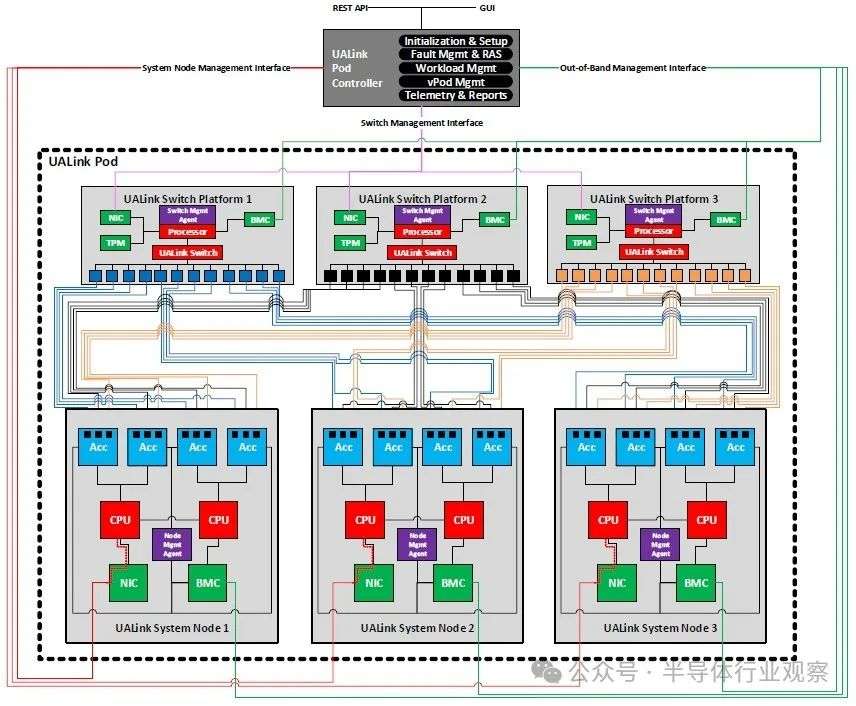
仅仅因为 UALink 1.0 协议能够支持 1024 个设备互连的加速器 NUMA 内存域,并不意味着人们会立即投入其中,开始构建能够扩展到如此规模的东西。
(不过,如果有人真的这么做了,那可就太有趣了。)
我们来看看 Nvidia 有多保守。
理论上,使用 NVLink 4 端口的 NVSwitch 3 结构可以在共享内存池中跨越多达 256 个 GPU,但 Nvidia 的商业产品仅支持 8 个 GPU。
借助 NVSwitch 4 和 NVLink 5 端口,Nvidia 理论上可以支持跨越多达 576 个 GPU 的内存池,
但实际上,仅在 DGX B200 和 B300 NVL72 系统中最多具有 72 个 GPU 的机器上提供商业支持。
并且 Nvidia 在其路线图上最大的域(至少现在)在单个内存映像中只有 576 个 GPU 芯片,每个插槽有 4 个 GPU 芯片,每个机架有 72 个插槽。
看起来,在某种程度上,UALink 可能具有扩大规模的优势,
但这很大程度上取决于支持 AI 处理的全网络在具有数百个共享高带宽内存的计算引擎的机器上运行得如何。
重要的是要意识到 UALink 并非 NVLink 的山寨版。尽管 NVLink 看起来像是 PCI-Express 和 InfiniBand 的结合体,但它们确实不同。
(而且 NVLink 和 NVSwitch 的出现早于 Nvidia 收购 Mellanox Technologies。)
Bowman 表示:“UALink 和 NVLink 之间存在差异。NVLink 是 x2 的,所以它们总是将两个通道组合在一起。
UALink 允许端口使用 x1、x2 或 x4,之后你可以组合端口,就像 Nvidia 可以组合 NVLink 端口一样。
所以它们之间存在一些差异,虽然这些差异很细微,但根据你试图构建的系统类型和所需的带宽,它们确实会有所帮助。
我们认为,单向 800 Gb,即双向 1.6 Tb,在这些 UALink 设备即将面世的时间段内,提供的带宽足够了。”
通常情况下,当一项网络规范发布后,首批使用该技术的设备投入使用大约需要两年时间。
但鲍曼表示,这一次只需要十二到十八个月,因为需求量非常大,而且每个制造 UALink 交换机的人都知道自己在做什么。
https://www.tomshardware.com/tech-industry/ualink-has-nvidias-nvlink-in-the-crosshairs-final-specs-support-up-to-1-024-gpus-with-200-gt-s-bandwidth
https://www.businesswire.com/news/home/20250408050548/en/UALink-Consortium-Releases-the-Ultra-Accelerator-Link-200G-1.0-Specification
https://www.nextplatform.com/2025/04/08/ualink-fires-first-gpu-interconnect-salvo-at-nvidia-nvswitch/
文章来自于微信公众号 “半导体行业观察”,作者 :半导体行业观察编辑部




