# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Llama 4诞生不过3天,反手就被超越了。
刚刚,英伟达官宣开源「超大杯」Llama Nemotron推理模型,共有253B参数,基于Llama-3.1-405B微调而来。
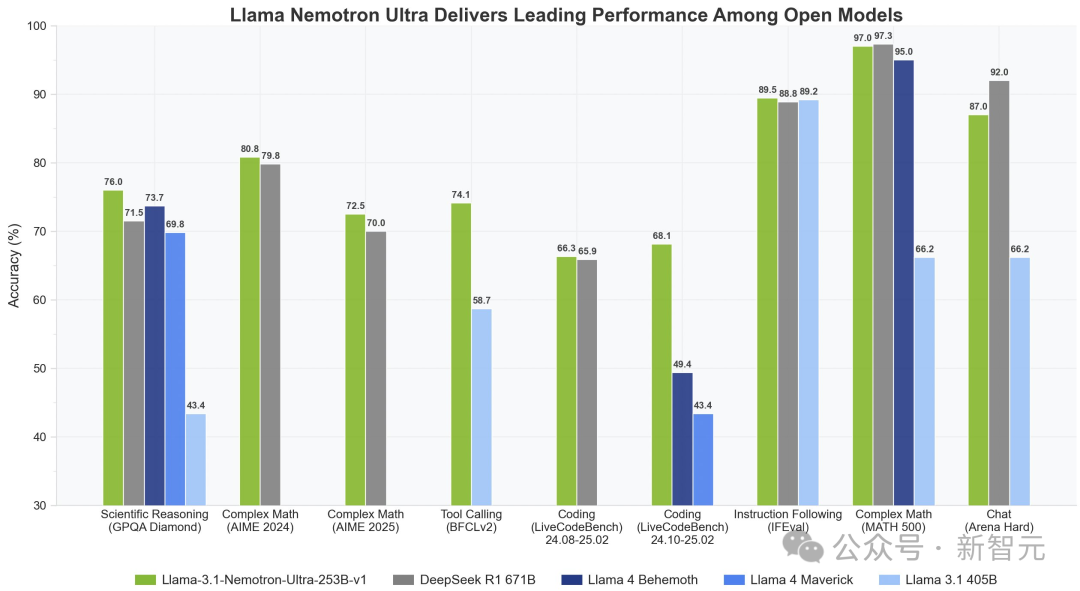
在多项基准测试中,Llama Nemotron一举击败了两款Llama 4模型。而且仅用一半的参数,性能直逼DeepSeek R1。
尤其是,在复杂数学推理AIME(2024/2025)、科学推理GPQA Diamond、编码LiveCodeBnech中,新模型取得SOTA。
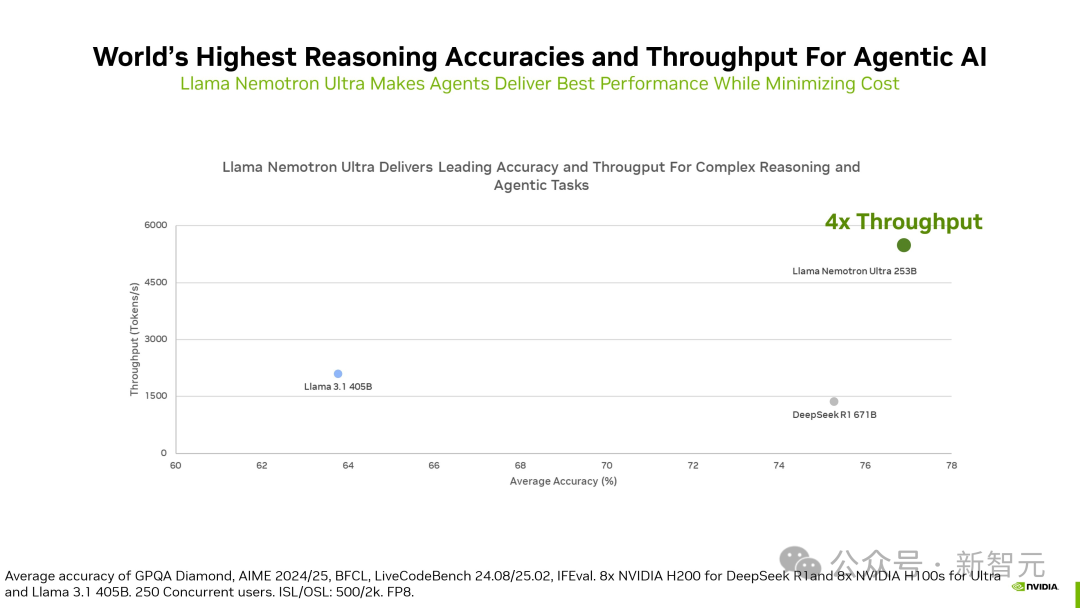
相比DeepSeek R1 671B,它的推理吞吐量提升了4倍。
Llama-3.1-Nemotron-Ultra-253B-v1经过后期训练,专注于推理、人类聊天偏好和任务,如RAG(检索增强生成)和工具调用。
它能支持128Ktoken的上下文长度,且能够在单个8xH100芯片节点上进行推理。
这个模型之所以能达到如此强的推理性能,是因为在模型精度和效率之间取得了良好平衡,让效率(吞吐量)直接转化为成本节省。
通过采用一种新颖的神经架构搜索(NAS)方法,研究者大大减少了模型的内存占用,
从而支持更大的工作负载,并减少了在数据中心环境中运行模型所需的GPU数量。
现在,该模型已准备好支持商用。
今年3 月,英伟达首次亮相了Llama Nemotron系列推理模型。
它一共包含三种规模:Nano、Super 和 Ultra,分别针对不同场景和计算资源需求,供开发者使用。
Nano(8B)基于Llama 3.1 8B微调而来,专为PC和边缘设备而设计。
如下图,Llama Nemotron Nano在GPQA Diamond、AIME 2025、MATH-500、BFCL、IFEval、MBPP和MTBench等多项基准测试中,展现出领先性能。
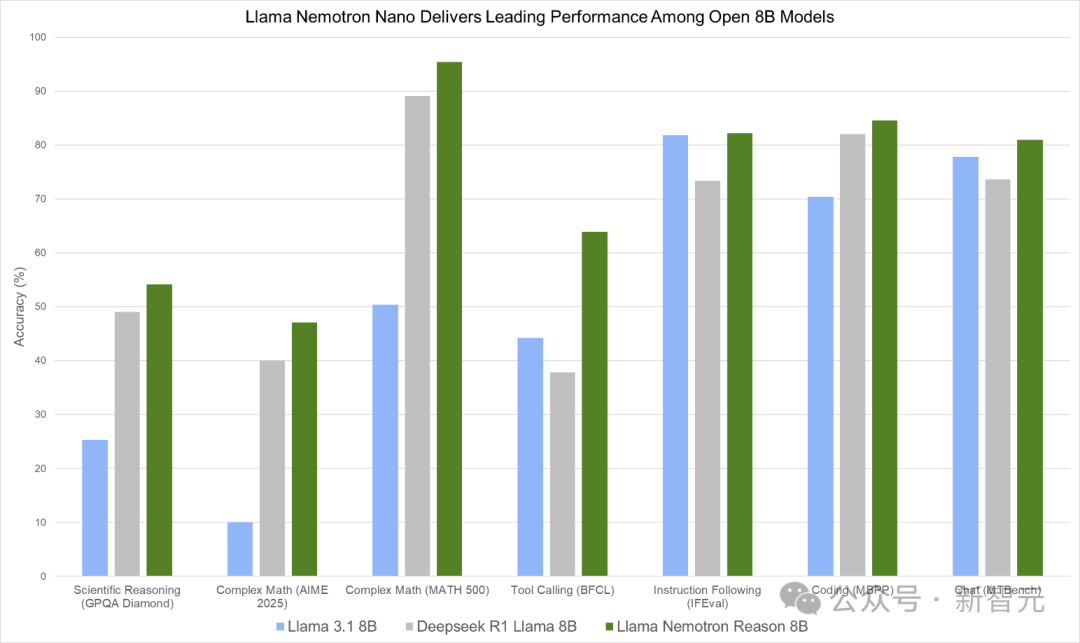
图 1. Llama Nemotron Nano在一系列推理和智能体基准测试中提供同类最佳性能
Super(49B)是从Llama 3.3 70B蒸馏而来,针对数据中心GPU进行了优化,便可实现最高吞吐量下的最佳准确性。
下图显示,Llama Nemotron Super在GPQA Diamond、AIME 2024/2025、MATH-500、MBPP、Arena Hard、BFCL和IFEval等多项基准测试,取得了最优性能。
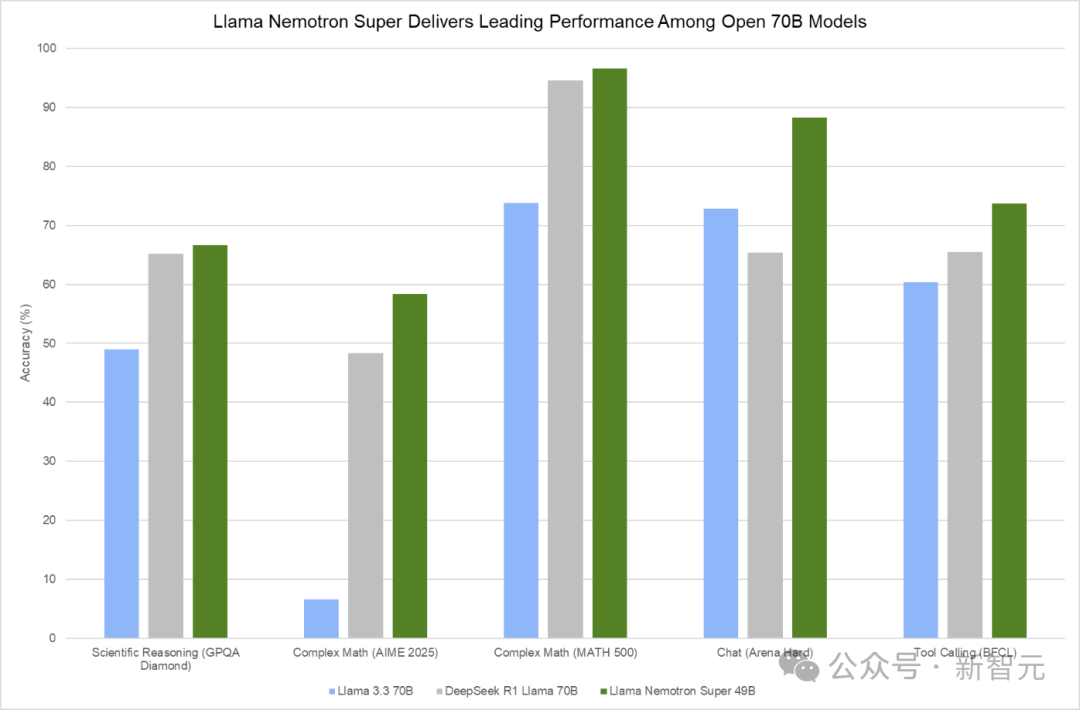
图 2. Llama Nemotron Super在一系列推理和智能体基准测试中提供领先性能
Ultra(253B)是从Llama 3.1 405B蒸馏而来,专为多GPU数据中心打造最强智能体而设计,
图表显示,采用FP8精度的Llama Nemotron Ultra 253B在GPQA、Complex Math、BFCL、LiveCodeBench以及IFEval上表现出色。
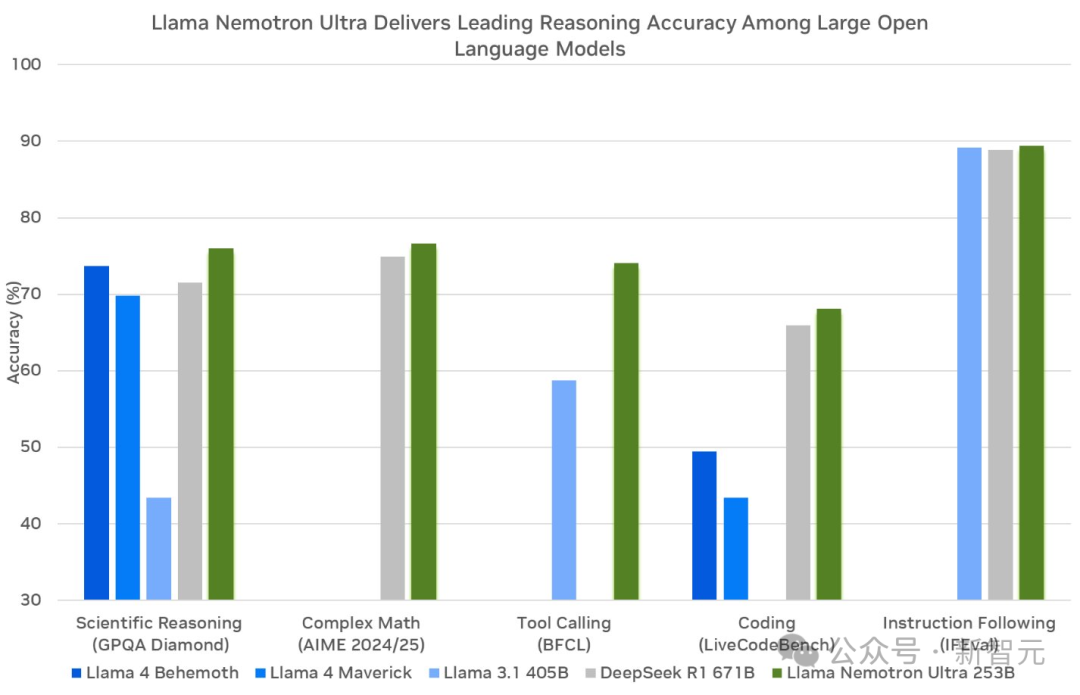
图3. FP8精度的Llama Nemotron Ultra提供同类最佳的推理和智能体基准测试性能
Llama Nemotron家族模型均是基于开源 Llama构建,并采用英伟达审核后的数据集合成数据,因此全部可以商用。
秘密武器:测试时Scaling
英伟达是如何训练出性能如此卓越的模型的?背后的关键,就在于「测试时scaling」(或称推理时scaling)和「推理」。
测试时scaling这项技术,会在模型推理阶段投入更多计算资源,用以思考和权衡各种选项,来提升模型响应质量,这就使得模型在关键下游任务上的性能得以提升。
对问题进行推理是一项复杂的任务,而测试时投入的计算资源,正是使这些模型能达到前述需推理水平的关键因素。
它能让模型在推理期间利用更多资源,开辟更广阔的可能性空间,从而增加模型建立起必要关联、找到原本可能无法获得的解决方案的几率。
尽管「推理」和「测试时scaling」对智能体工作流如此重要,但有一个共同问题,却普遍困扰着如今最先进的推理模型——
开发者无法选择何时让模型进行推理,也就是说,做不到在「推理开启」和「推理关闭」之间自由切换。
而Llama Nemotron系列模型则攻破了这一难题,用「系统提示词」来控制推理开关!
如何构建?
Llama 3.3 Nemotron 49B Instruct以Llama 3.3 70B Instruct为基础模型,经历了一个广泛的后训练阶段后,不仅模型尺寸减小,还让原始能力保留甚至增强了。
三个后训练阶段如下。
1. 通过神经架构搜索 (NAS) 和知识蒸馏进行蒸馏。
2. 监督微调:使用了由英伟达创建的600亿Token 合成数据(代表了所生成的 3000万样本中的400万),
以确保在「推理关闭」和「推理开启」两种模式下内容的高质量。在此阶段,团队利用了NVIDIA NeMo框架,有效且高效地扩展了后训练流程。
3. 强化学习:这个阶段是利用NVIDIA NeMo完成的,模型的对话能力和指令遵循性能得以增强,从而在广泛的任务中都能提供高质量的响应。
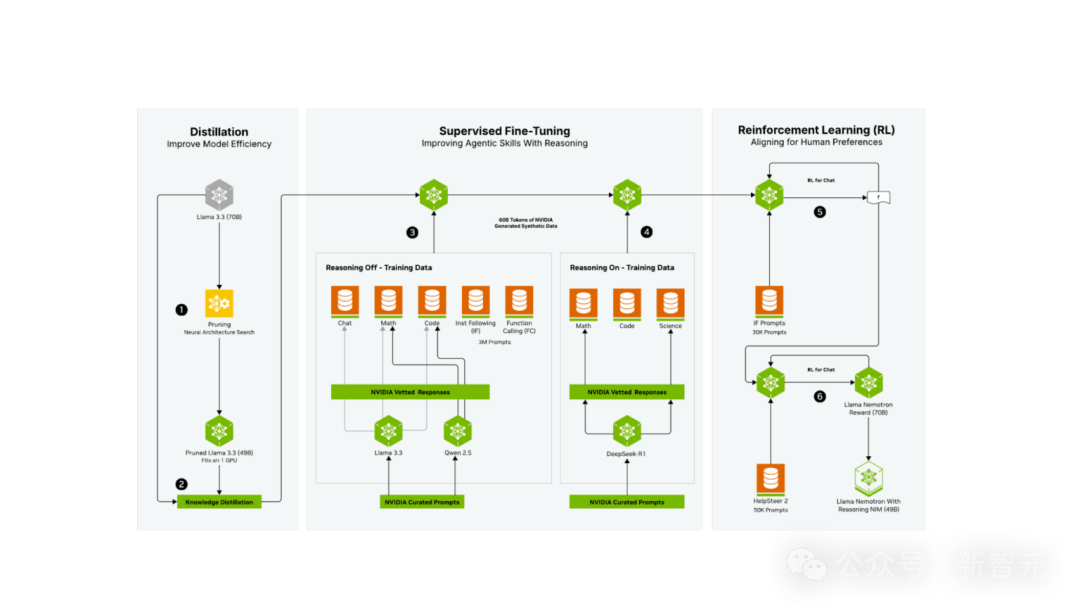
第一个阶段(步骤1和2)已在神经架构搜索 (NAS) 技术报告中详细阐述。
简而言之,该阶段可被视为通过多种蒸馏和NAS方法,依据特定的旗舰硬件,将各模型的参数量「调整至合适尺寸」,从而达到预选的最优值。
模型后训练的第二个阶段(步骤3和4)则涉及由合成数据驱动的监督微调,目的在于实现几个关键目标。
首要目标,就是提升模型在多种任务上的非推理性能。
后训练流程的这一环节(步骤3)利用了团队精选的提示词,通过基线模型 (Llama 3.3 70B Instruct) 以及Qwen2.5 7B Math和Coder模型生成合成数据。
这些数据随后经过团队的精选与审核,用于增强模型在聊天、数学和代码任务上的「推理关闭」模式下的性能。
同时,团队也投入大量精力,确保在此阶段,「推理关闭」模式下的指令遵循和函数调用性能达到同类最佳水平。
第二个目标(步骤4)是通过在精选的DeepSeek-R1数据(仅限数学、代码和科学领域)上进行训练,打造出同类最佳的推理模型。
每一个提示词和响应都经过严格筛选,确保在推理能力增强过程中仅使用高质量数据,并辅以NVIDIA NeMo框架的支持。
这就能确保团队可以选择性地从 DeepSeek-R1中蒸馏出它在优势领域所具备的强大推理能力。
「推理开启」/「推理关闭」两种模式的训练(步骤3和4)是同时进行的,两者唯一的区别在于系统提示词。
这意味着,最终生成的模型既能作为推理模型运行,也能作为传统的LLM运行,并通过一个开关(即系统提示词)在两种模式间切换。
这种设计,使得组织机构能够将单个尺寸适宜的模型同时用于推理任务和非推理任务。
最后一个阶段(步骤5和6)则采用了强化学习来更好地对齐用户意图与期望。
模型首先利用REINFORCE算法和基于启发式的验证器,针对指令遵循和函数调用这两个任务进行RL以提升性能(步骤5)。
随后,采用RLHF技术,结合HelpSteer2数据集和NVIDIA Llama 3.1 Nemotron奖励模型,对最终模型进行面向聊天应用场景的对齐(步骤6)。
最终,这些后训练步骤打造出了同类最佳的推理模型,并且通过提供在两种范式(推理与非推理)间切换的机制,
确保了模型在函数调用和指令遵循方面的性能不受影响。
模型则能高效支持智能体AI工作流中的各个,同时还能保持针对旗舰级英伟达硬件优化的最佳参数量。
Llama Nemotron融合了DeepSeek-R1等模型强大的推理能力,以及Llama 3.3 70B Instruct具备的强大世界知识与对可靠工具调用及指令遵循,
最终打造出在关键智能体任务上表现领先的模型。
结果显示,Llama Nemotron 49B准确性最高,且吞吐量提升达5倍。
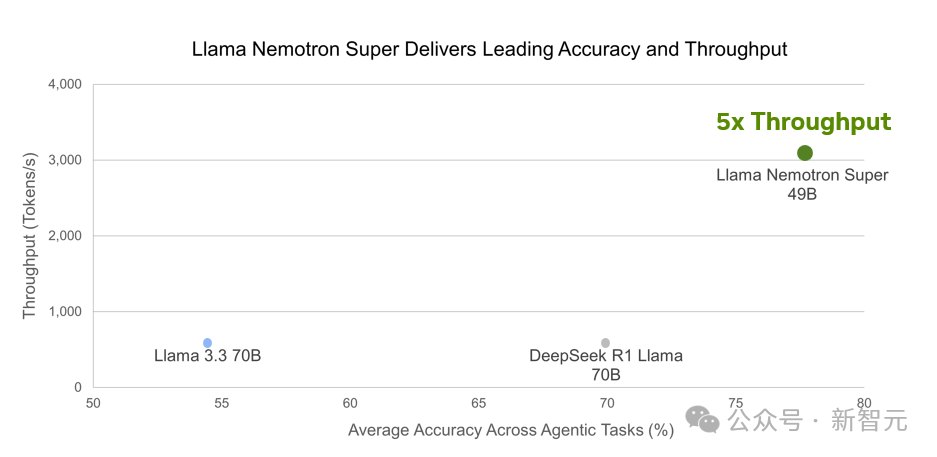
图 5. Llama Nemotron Super为智能体任务提供了最高的准确性和吞吐量,从而降低了推理成本
Llama Nemotron Ultra总参数量仅为253B,但其推理性能已达到甚至超越DeepSeek-R1等顶级开放推理模型。
与此同时,凭借优化的模型尺寸实现了显著更高的吞吐量,并保留了优秀的工具调用能力。
这种卓越推理能力与毫不妥协的工具调用能力的结合,使其成为智能体工作流领域的同类最佳模型。
除了应用Llama Nemotron Super的完整后训练流程外,Llama Nemotron Ultra还额外经历了一个专注的RL阶段,旨在进一步增强其推理能力。
结果表明,相较于DeepSeek-R1 671B,Llama Nemotron Ultra的吞吐量提升高达4倍,
并且在GPQA、AIME 2024、AIME 2025、BFCL、LiveCodeBench、MATH500和IFEval的等权重平均准确性方面取得最高分。
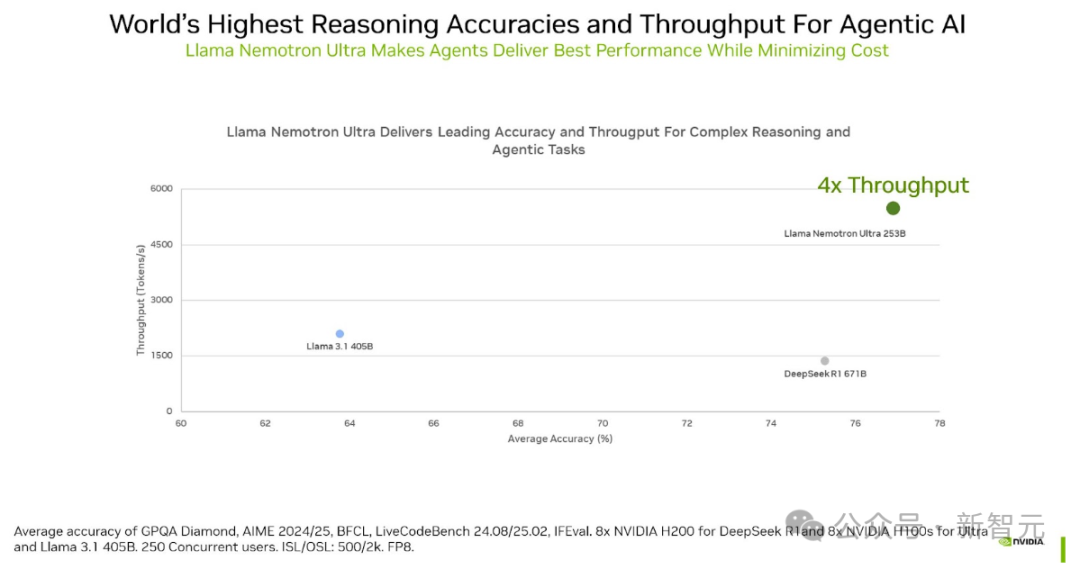
图6. Llama Nemotron Ultra同时提供卓越的准确性和惊人的吞吐量
由Llama 3.3 Nemotron 49B Instruct驱动的多智能体协作系统,在Arena Hard 基准测试中,拿下了惊艳的92.7分。
传统的测试时计算scaling方法,大多聚焦于那些有明确答案的问题,比如数学题、逻辑推理、编程竞赛。
现实中,许多重要任务缺乏可验证的解决方案,比如提出创新研究思路、撰写学术论文,或是为复杂的软件产品开发有效的交付策略。
这些问题,往往更具挑战性,也更贴近实际需求。
Llama Nemotron测试时计算scaling系统正是为此而生,它模仿了人类解决复杂问题写作模式,通过以下几个步骤实现:
1. 集思广益:针对问题初步构思一个或多个解决方案。
2. 获取反馈:就初步方案征求朋友、同事或其他专家的意见。
3. 编辑修订:根据收集到的反馈对初步方案进行修改。
4. 择优选取:在整合修订意见后,选出最具潜力的最终解决方案。
这种方法使得测试时计算scaling技术能够应用于更广泛的通用领域任务。
要形象地理解这个多智能体协作系统,可以将其类比为一个团队协同工作,为一个没有标准答案的开放式问题寻找最佳解决方案。
与之相对,「长思考」则好比训练单个人深度、持久地钻研一个问题,最终得出一个可以对照标准答案进行验证的结果。
因此,多智能体系统强大之处在于,不仅提升解决复杂问题效率,还能通过协作挖掘更多可能性。
参考资料:
https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1
https://developer.nvidia.com/blog/build-enterprise-ai-agents-with-advanced-open-
nvidia-llama-nemotron-reasoning-models/
https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1?ncid=so-twit-273200
文章来自于微信公众号 “新智元”,作者 :编辑部 HYZ




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
