# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
利用字节团队魔改的FLUX模型,可以直接把多个参考主体放进一张图了。

字节团队以FLUX为基础模型,提出了新的生图模型UNO,统一了图像生成任务中不同输入条件的处理。
无论是单主体进行风格变换,还是不同物体的融合,UNO都能直接搞定。

字节团队认为,UNO主要解决的是参考驱动的图像生成中的两个主要挑战——数据可扩展性和主体可扩展性。
传统方法在从单主体数据集扩展到多主体数据集时面临困难,且大多数方法仅关注单主体生成,难以应用于多主体场景。
为了解决这一问题,团队提出了“模型-数据共同进化”的新范式,能够在增强模型能力的同时,不断丰富可用的训练数据。
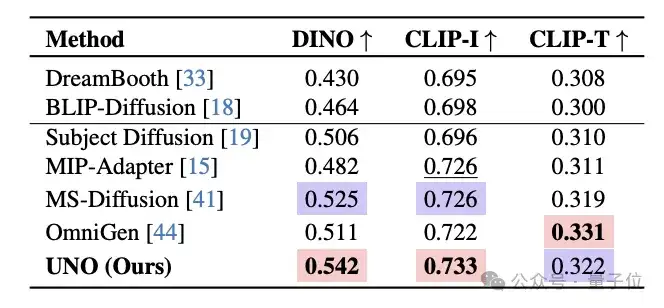
多主体参考生图测试中,UNO的DINO和CLIP得分均达到了SOTA水平。
网友评价说,UNO看上去是一个巨大的飞跃,如果真的能搞定多主体参考,将会大幅激发定制化AI智能体的潜力。
另外,团队还在HuggingFace上提供了在线试玩,但前提是拥有HF的GPU额度。
如开头所述,UNO将单纯的文生图,以及单/多主体参考这些不同的任务都整合到了一个模型当中。
具体来说,除了直接的文生图之外,它可以把多张参考图当中的物体进行组合。

当然三个物体也照样能很好地组合,官方提供的在线Demo当中最多可以上传四张参考图。
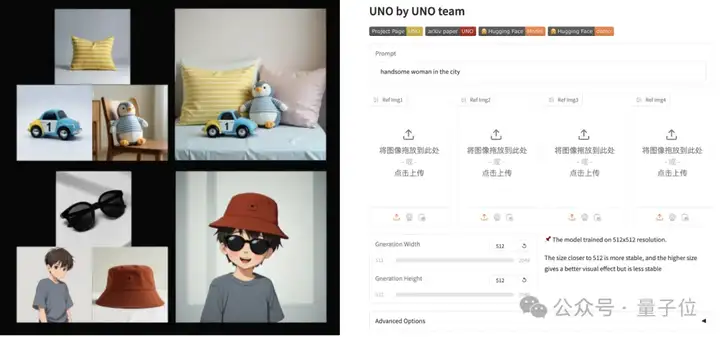
也可以对参考主体中的人物特征进行保持,生成不同场景的人物图像。

同时对于人物而言,也可以在保留基本特征的条件下进行风格转换,包括被GPT-4o带火的吉卜力风也能拿捏。

应用场景方面,官方给出了虚拟试穿和产品设计这两组示例。

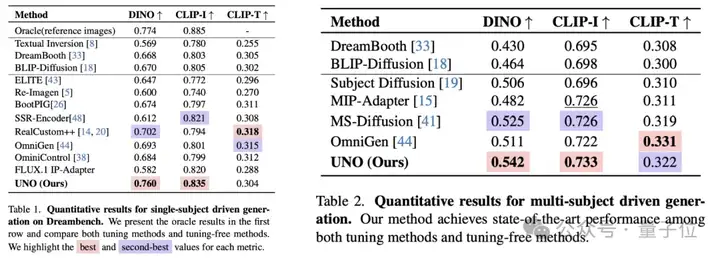
对于UNO的单主体生成能力,团队使用了DreamBench进行了测试,使用了三个主要指标——
DINO分数、CLIP-I分数(这两个用于评估主体相似度)和CLIP-T分数(用于评估文本忠实度)。
多主体生成测试则采用了一个特别设计的测试集——从DreamBench中选取了30种不同的双主体组合,包括非生物体和生物体的组合。
最终,UNO的测试成绩无论在单主体还是多主体任务中都处于领先水平。
研究团队还进行了用户研究,邀请了30位评估者(包括领域专家和非专家)对300个图像组合进行评估。
结果,UNO在所有评估维度上都获得了较高评分,特别是在主体相似度和文本忠实度方面的表现最为突出。
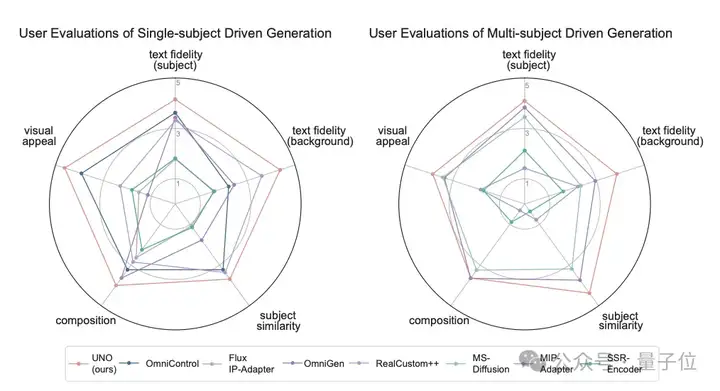
此外,团队还展示了UNO和一些SOTA级模型的效果对比,可以直观感受一下区别。


UNO采用了这一种“模型-数据共同进化”的新范式,核心思想是用较弱的模型生成训练数据,训练更强的模型。
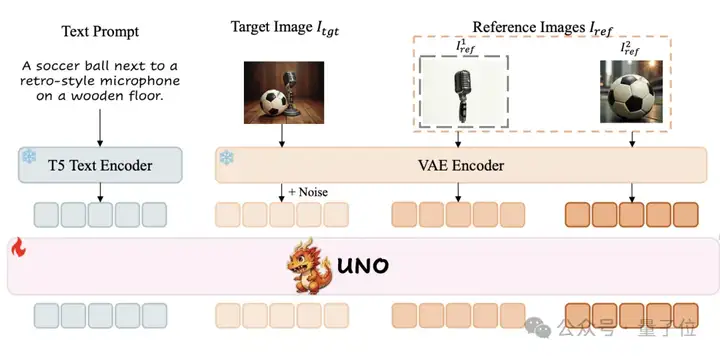
在模型架构方面,UNO以开源模型FLUX.1 dev为基础,继承了其文生图基础能力和多模态注意力机制,采用了通用定制化模型框架。
具体来说,该框架采用渐进式跨模态对齐策略,将训练过程分为两个连续阶段——
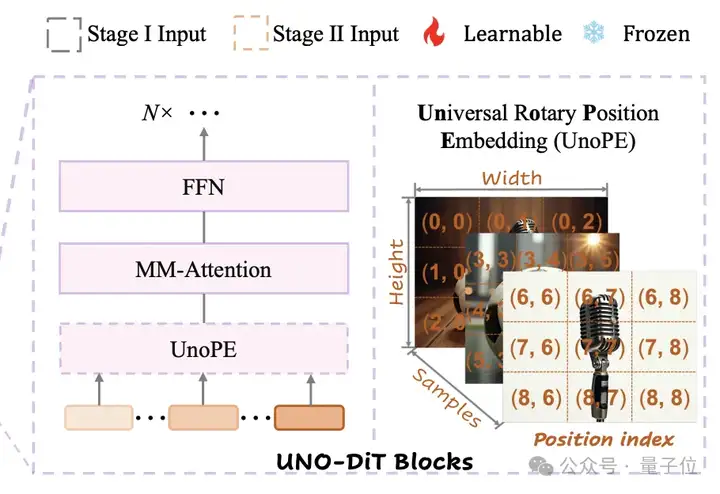
此外研究团队提出了通用旋转位置嵌入(UnoPE)技术,通过为文本和图像标记分配特定的位置索引,来调控多模态标记之间的交互。
UnoPE采用从噪声图像标记最大维度开始的对角线位置编码方式,并通过调整位置索引范围来防止生成图像过度依赖参考图像的空间结构,有效缓解了在扩展视觉主体控制时容易出现的属性混淆问题。
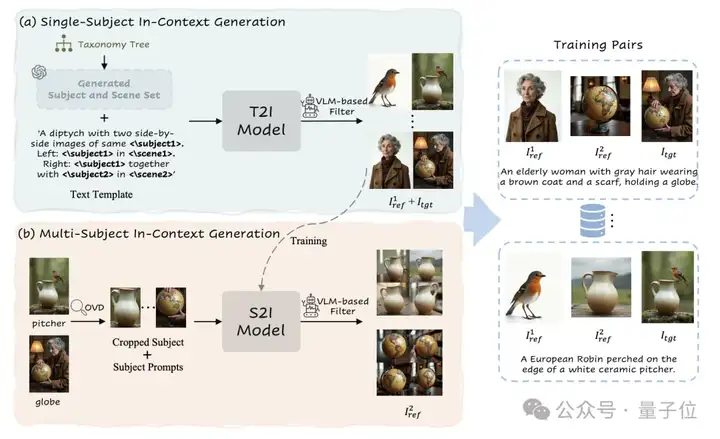
数据方面,团队利用Diffusion Transformer固有的上下文生成能力构建了数据合成框架。
团队首先构建了一个包含365个顶层类别的分类树,这些类别来自Object365数据集。
在每个类别下,还包含了更细粒度的分类,涵盖年龄、职业和着装风格等维度。
然后利用大模型在每个类别中生成丰富多样的主体和场景描述,这些输出与预定义的文本模板结合,可以为文生图模型生成数百万个文本提示。
最终,研究团队设计了一个渐进式的合成管道,从单主体生成开始,逐步过渡到多主体上下文生成。
论文显示,UNO的作者字节智能创作团队。
据介绍,该团队是字节的AI&多媒体技术中台,研究方向包括计算机视觉、音视频编辑、特效处理等技术。

之前字节提出的用于提升图像生成模型“美感”的VMix,也是来自智能创作团队,并且作者与这次的UNO基本相同。

本次UNO的项目负责人是Fei Ding,是Vmix的通讯作者,之前还参与过Realcustom++、Dreamtuner等项目的工作。

UNO的第一作者Shaojin Wu、通讯作者黄梦琪,之前也都参与过Vmix。
黄梦琪目前是中科大博士在读,2023年起至今一直在字节实习,预计今年毕业,导师是毛震东教授。
另外,字节招聘网站显示,智能创作团队目前正在招聘AIGC技术专家、多模态算法专家等岗位。

论文地址:
https://arxiv.org/abs/2504.02160
项目主页:
https://bytedance.github.io/UNO/
文章来自于“量子位”,作者“克雷西”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
