# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在的大模型都有一个「理想」,那就是将各种模态大一统,一个模型就能生文、生图、生视频,可以称之为「全干模型」!
GPT-4o发布了自己原生的多模态绘图能力着实火了一把,OpenAI还给模型起了一个新的名字「全能模型」。
统一的多模态模型旨在整合理解(文本输出)和生成(像素输出),但在单个架构内校准这些不同的模态通常需要复杂的训练方案和仔细的数据平衡。
在刚刚发布的一项研究中,来自Meta和纽约大学的研究人员探索了一种简单但尚未得到充分探索的、用于统一多模态建模的替代方法。

论文地址:https://arxiv.org/pdf/2504.06256
项目主页:https://xichenpan.com/metaquery/
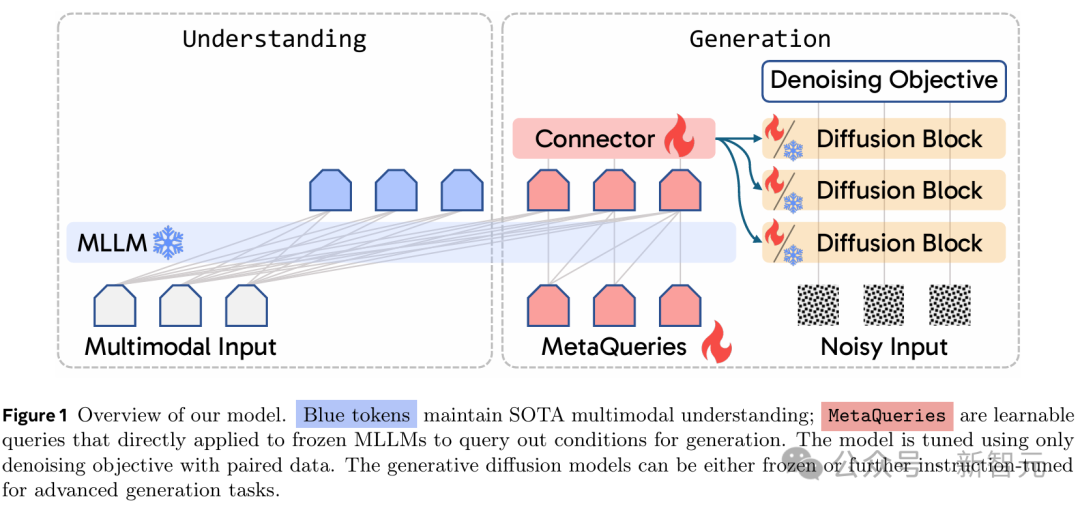
新的方法MetaQuery桥接了冻结的(Frozen)多模态大语言模型(MLLM)骨干和扩散模型(DiT)。
实验表明,MetaQuerie实现了所有曾被认为需要MLLM微调才能具备的能力,同时其训练过程也更为简便。
简而言之就是,具备理解能力的MLLM可以直接和负责生成图片的DiT进行SOTA水平的多模态生成。

一个巨大的人形,由蓬松的蓝色棉花糖制成,踩在地上,咆哮着冲向天空,身后是湛蓝的天空

一个穿着裤子和夹克的生锈旧机器人在超市里骑滑雪板

一只亮蓝色鹦鹉的羽毛在灯光下闪闪发光,显示出它独特的羽毛和鲜艳的色彩
指令微调

同一个机器人,但在「我的世界」

同样一种车型,但在纽约

同一个碗蓝莓,但俯视图
推理和知识增强生成

最高的建筑主宰着这座被称为光之城的城市的天际线

新月之夜的夜空

这个在春季节日中备受赞颂的花,是寿司发源国所特有的
桥接MLLM与DiT,实现大一统
通常来说,创建一个「既要又要」的模型——既要最先进的多模态理解能力,同时又要强大的生成图像能力——有些困难。
目前的一些方案依赖于精细微调基础多模态大语言模型(MLLM)来处理理解和生成任务。
但这个过程涉及复杂的架构设计、数据/损失平衡、多个训练阶段以及其他复杂的训练方案,
若不靠考虑这些,优化一种能力可能会损害另一种能力——「按下葫芦又起了瓢」。
如何有效地将自回归多模态大语言模型(MLLM)中的潜在世界知识转移到图像生成器中?
说来也简单,将生成任务交给扩散模型,将理解任务交给大语言模型——「让凯撒的归凯撒」。
换句话说,不是设法从头开始构建一个单体系统,而是专注于在专门针对不同输出模态的最先进的预训练模型之间有效地转移能力。
为了实现这一点,研究团队让MLLM冻结(Frozen),以便可以专注于它们最擅长的事情——理解,同时将图像生成委托给扩散模型。
即使在这种冻结条件下,只要有合适的架构桥梁,MLLM固有的世界知识、强大的推理能力和上下文学习能力确实可以转移到图像生成中。
这样的系统可以解锁协同能力,其中理解为生成提供信息,反之亦然。

戴着墨镜的英国短毛猫
MetaQuery将一组可学习的查询直接输入到冻结的MLLM中,以提取用于多模态生成的条件。
实验表明,即使没有进行微调或启用双向注意力,冻结的LLM也能充当强大的特征重采样器,为多模态生成产生高质量的条件。
使用MetaQueries训练统一模型仅需要少量图文对数据,即可将这些提示条件连接到任何条件扩散模型。
由于整个MLLM在理解方面保持不变,训练目标仍然是原始的去噪目标——就像微调扩散模型一样高效和稳定。
相比训练单个自回归Transformer骨干来联合建模的统一模型,MetaQuery选择使用token→Transformer→扩散→像素的范式。
这一思路,可能与同期的GPT-4o图像生成系统所体现的理念相似。
通过将MLLM的自回归先验与强大的扩散解码器相结合,
MetaQuery直接利用冻结MLLM在建模压缩语义表示方面的强大能力,从而避免了直接生成像素这一更具挑战性的任务。
统一所有模态的前景并非止步于并行处理多模态理解和文本到图像的生成。
更深层次的协同作用值得期待——一种能够利用MLLM的高级能力(如推理、内部知识、多模态感知和上下文学习)来增强生成的能力。

比如生成一个和「9条命」相关的动物——通过推理,得出是九命的是猫妖
概括来说就是,MetaQuery方法能够无损地为仅具理解能力的多模态大语言模型(MLLM)赋予多模态生成能力,同时保持其原始架构设计和参数不变。
具体到架构层,研究人员首先使用随机初始化的可学习查询Q∈R^(N×D)来查询获取用于生成的条件C。
其中,N是查询的数量,D是查询的维度(与MLLM的隐藏维度相同)。
为简单起见并保持兼容性,继续对整个序列使用因果掩码(causal masking),而不是专门为查询Q启用全注意力(full attention)。
然后将条件C输入一个可训练的连接器(trainable connector),从而与文本到图像扩散模型的输入空间对齐。
这些扩散模型可以是任意类型,只要它们具有条件输入接口即可。需要做的,就只是将模型的原始条件替换为生成的C。
虽然模型目前专注于图像生成任务,但也可轻松扩展至其他模态,如音频、视频、3D等。
架构涉及两个核心设计选择:使用可学习查询(learnable queries)和保持MLLM骨干冻结(frozen)。
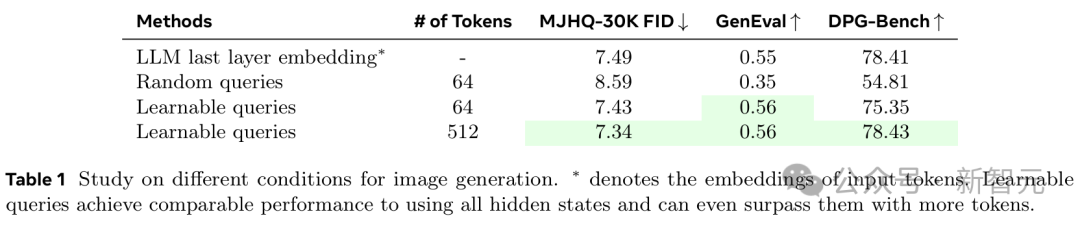
目前,很多模型会使用(M)LLM输入Token的最后一层嵌入(last layer embedding)作为图像生成条件。
但这与统一建模中的许多期望任务并不兼容,如上下文学习或生成多模态、交错的输出。
而且,随机查询(random queries)虽然能产生不错的FID分数,但它们在提示词的对齐方面表现不佳。
如表1所示,仅使用N=64个Token的可学习查询,即可实现与这些模型相当的图像生成质量。当N=512个Token时,性能则直接超越了最后一层嵌入方法。
· 冻结 MLLM
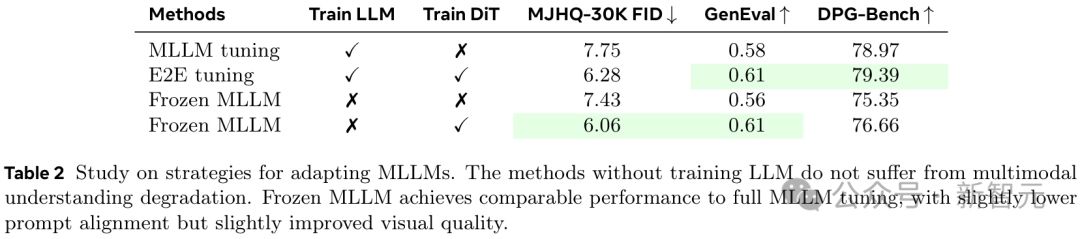
现有的统一模型通过训练MLLM来联合建模p(文本, 像素),但这样会让训练过程更复杂,甚至会降低模型的理解性能。
相比之下,MetaQuery可在原始MLLM架构和参数不变的情况下,保留SOTA的理解能力。
如表2所示,虽然可调的参数显著更少,但冻结MLLM能够实现与MLLM全量微调相当的性能,其提示词对齐能力略低,但视觉质量略有提高。
训练方案
接下来,团队进一步研究了MetaQuery两个主要组件的关键训练选项:可学习查询(learnable queries)和连接器(connectors)。
如图2所示,对于文本到图像生成任务,视觉质量在64个Token后开始趋于收敛,而更多的Token能持续带来更好的提示词对齐效果。
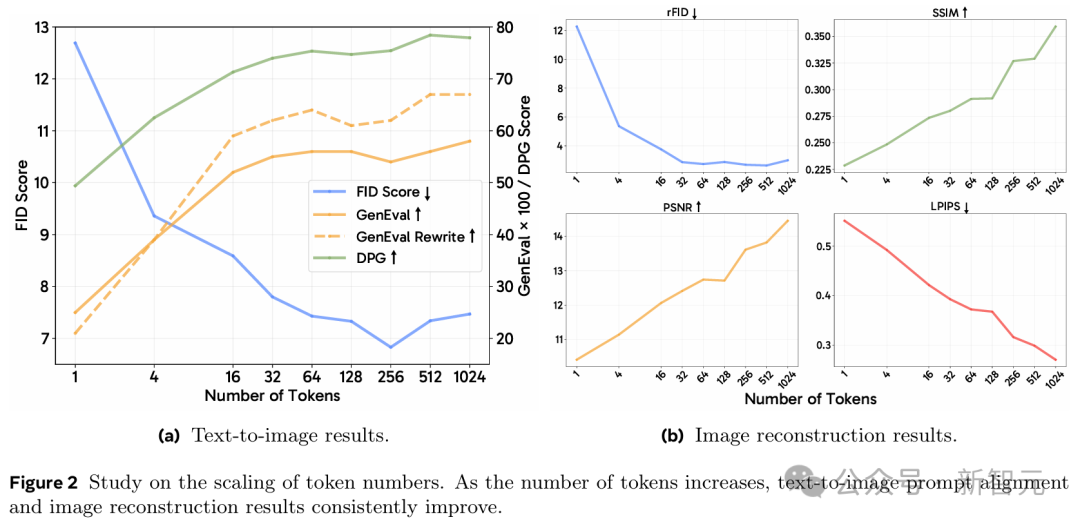
对于长标注(long captions)来说,这一点更为明显,因为随着Token数量的增加,使用重写提示词(rewritten prompts)的GenEval分数增长得更快。
而对于图像重建任务,更多的Token则能持续提高重建图像的质量。

· 连接器设计
在这里,团队研究了两种不同的设计:编码器前投影(Projection Before Encoder, Proj-Enc)和编码器后投影(Projection After Encoder, Enc-Proj)。
如表3所示,Enc-Proj比Proj-Enc实现了更好的性能,同时参数更少。
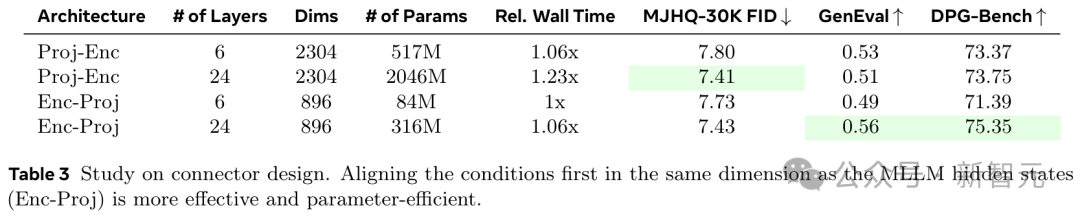
值得一提的是,研究人员使用的是与Qwen2.5相同的架构,并为连接器启用了双向注意力(bi-directional attention)。
模型训练
MetaQuery的训练分两个阶段:预训练和指令微调。
其中,每个训练阶段都保持MLLM冻结,并微调可学习查询、连接器和扩散模型。
MLLM骨干则有三种不同的规模:Base(LLaVAOneVision 0.5B)、Large(Qwen2.5-VL 3B)和X-Large(Qwen2.5-VL 7B)。
所有模型的Token数量都为N=256,并采用具有Enc-Proj架构的24层连接器。
研究人员在2500万个公开可用的图文对上对我们的模型进行了8个epoch的预训练,学习率为1e-4,全局批大小为4096。
学习率遵循余弦衰减策略,并设有4000步的预热期,之后逐渐降低至1e-5。
· 指令微调
受MagicLens的启发,研究人员使用网络语料库中自然出现的图像对来构建指令微调数据。
这些语料库不仅包含丰富的多模态上下文,
其中的图像对也展现出了更有意义的关联(从直接的视觉相似性到更微妙的语义联系),从而为指令微调提供了极好且多样化的监督信号。

接着,研究人员开发了一个数据构建流程,用于挖掘图像对并利用MLLM生成开放式指令来捕捉它们图像间的关系。
每组中,与其他图像平均相似度最低的图像被指定为目标图像,而其余图像则作为源图像。这个过程总共产生了240万个图像对。
实验
如表4所示,这个模型家族在理解和生成任务上都展示了强大的能力。
得益于允许利用任意SOTA冻结MLLM的灵活训练方法,所有不同规模的模型在所有理解基准上都有着相当不错的表现。
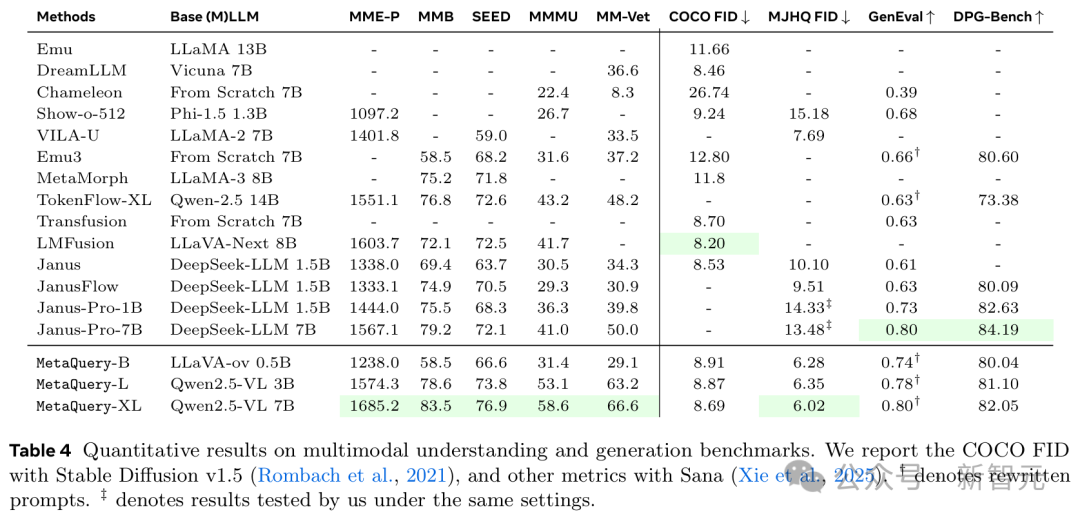
在图像生成方面,MetaQuery在MJHQ-30K上实现了SOTA视觉质量,并在GenEval和DPG-Bench上与SOTA提示对齐结果非常接近。
鉴于MetaQuery使用冻结MLLM,就可以自然地连接任意数量的扩散模型。
由于基础的Sana-1.6B模型已经在美学数据上进行了微调,研究人员采用Stable Diffusion v1.5进行COCO FID评估。
结果表明,在将其适配到强大的MLLM后,可以获得改进的视觉质量。
这也为所有基于Stable Diffusion v1.5的统一模型(包括MetaMorph和Emu)建立了新的SOTA COCO FID分数。

在提示词对齐方面,MetaQuery在GenEval上也取得了有竞争力的性能,击败了所有基于扩散模型的方法,包括Transfusion和JanusFlow。
此外,研究人员还发现MetaQuery实现了比Janus-Pro好得多的世界知识推理能力。
如图6所示,MetaQuery可以在冻结MLLM的情况下轻松微调以执行图像重建任务。
其中,微调后的MetaQuery-B所生成的质量,与现有的最佳开源模型Emu2基本相当。

图像编辑
如图7所示,MetaQuery可以迁移其图像重建能力来执行图像编辑。
方法是保持MLLM骨干冻结,并在公开可用的图像编辑数据上仅对预训练的Base模型进行1000步微调。
定性结果表明,MetaQuery在这些图像编辑场景中表现有效。

在240万数据集上进行指令微调后,MetaQuery可以实现令人印象深刻的零样本学习主体驱动生成性能,
即使有多个高度定制化的主体也能生成连贯的结果(图8第一行)。
使用各种监督信号,经过指令微调的MetaQuery-B模型出人意料地解锁了超越复制粘贴的新颖能力,如视觉关联和标志设计(图8第二行)。
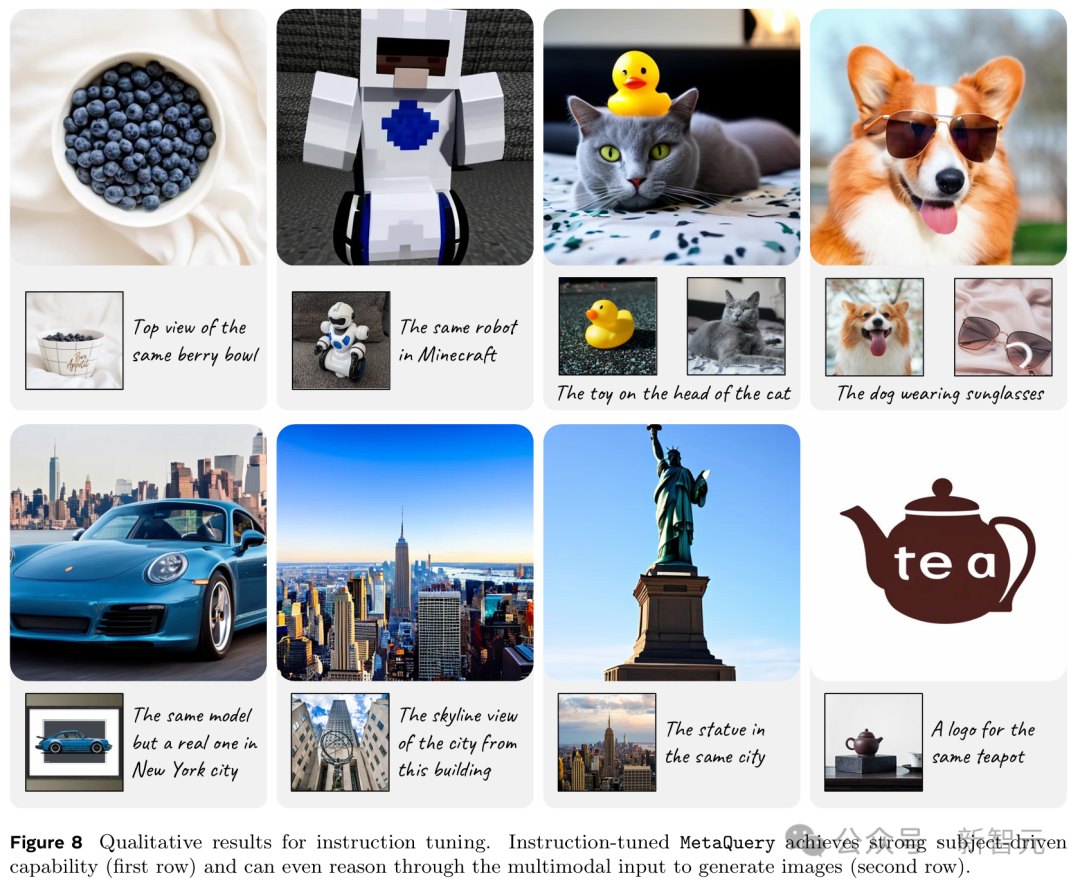
例如,在第一个案例中,模型识别出了输入的保时捷911汽车图像的具体型号,然后正确地为该型号生成了一个新颖的正面视图。
在第二个案例中,模型识别出洛克菲勒中心的输入图像,并构想出从洛克菲勒中心顶部的纽约市景观。
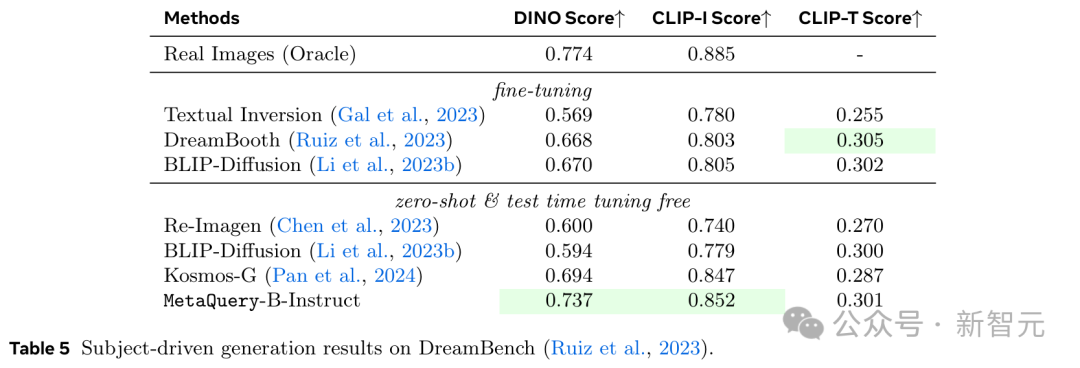
研究人员还遵循DreamBooth的方法,采用DINO、CLIP-I和CLIP-T分数在DreamBench数据集上对模型进行了定量评估。
如表5所示,MetaQuery-BInstruct模型达到了SOTA性能,优于像Kosmos-G这样为进行主体驱动生成而在构建的替换任务上明确训练的现有模型。
研究人员展示了可学习查询可以有效利用冻结LLM的能力。这使得模型能够更好地理解和遵循复杂提示词,包括那些需要世界知识和推理的提示词。
如图9所示,对于左侧的知识增强生成案例,MetaQuery-L可以利用来自冻结MLLM的世界知识并通过输入问题进行推理以生成正确答案。
对于来自CommonsenseT2I的右侧常识知识案例,LLM提供了更好的常识知识,并使MetaQuery能够生成与事实一致的图像。
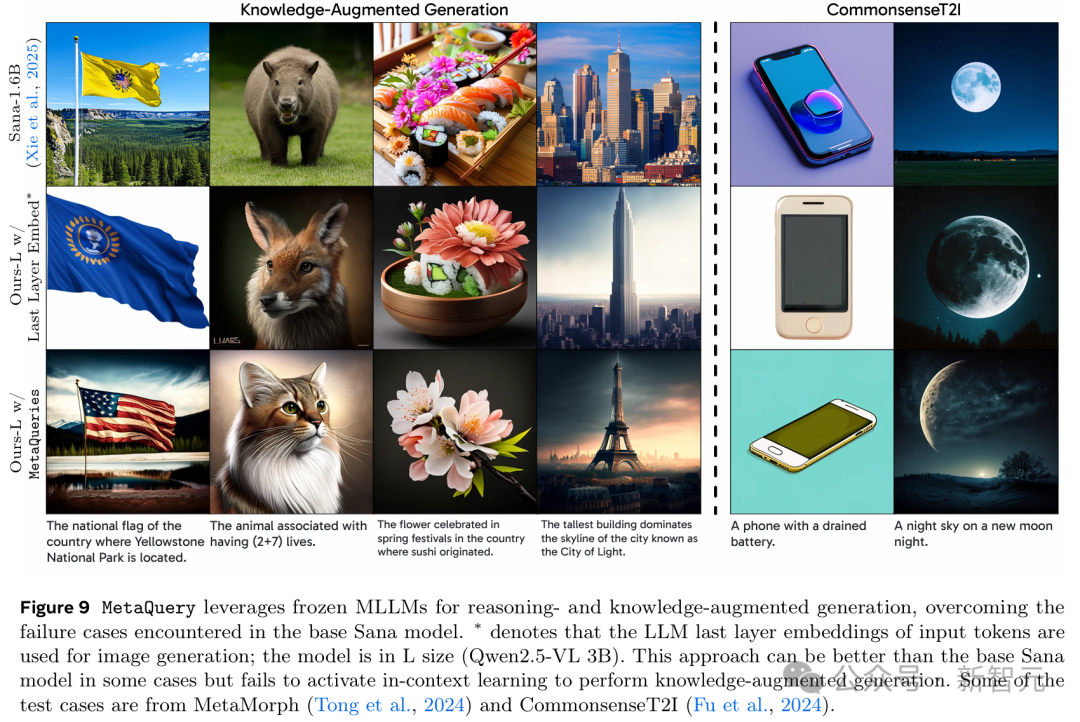
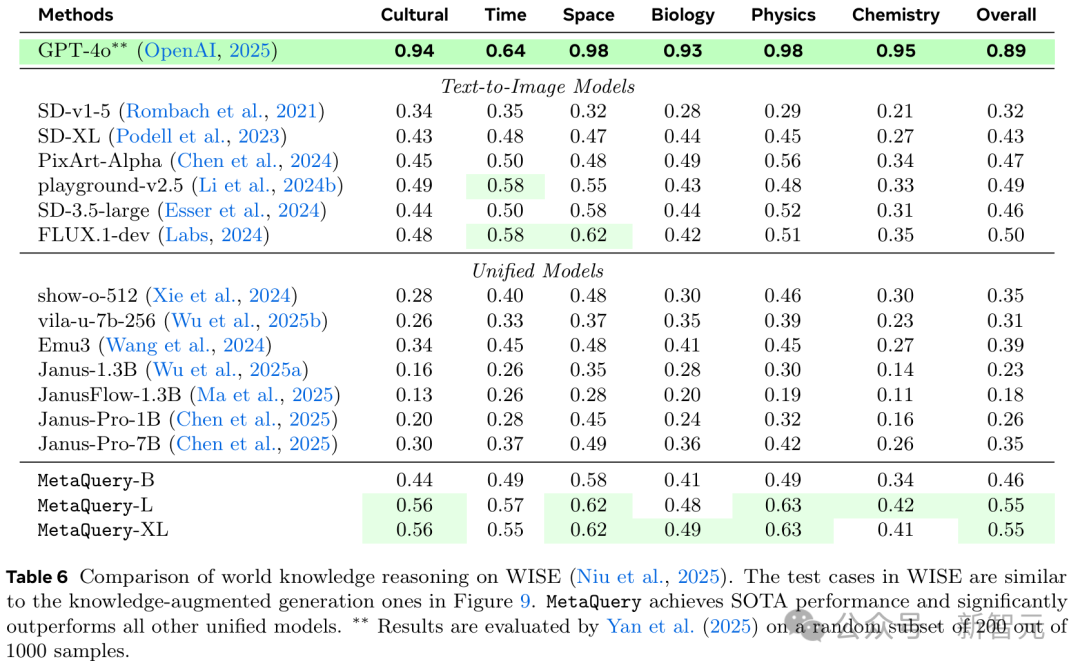
为了定量评估MetaQuery的世界知识推理能力,研究人员采用了WISE基准,该基准包含与图9所示的知识增强生成示例类似的测试案例。
如表6所示,MetaQuery达到了SOTA性能,显著优于所有其他统一模型。
值得注意的是,在这项工作之前,现有的统一模型难以有效利用强大的MLLM进行推理和知识增强生成,导致其性能劣于文本到图像模型。
MetaQuery是第一个成功将冻结MLLM的先进能力迁移到图像生成,并超越SOTA文本到图像模型性能的统一模型。
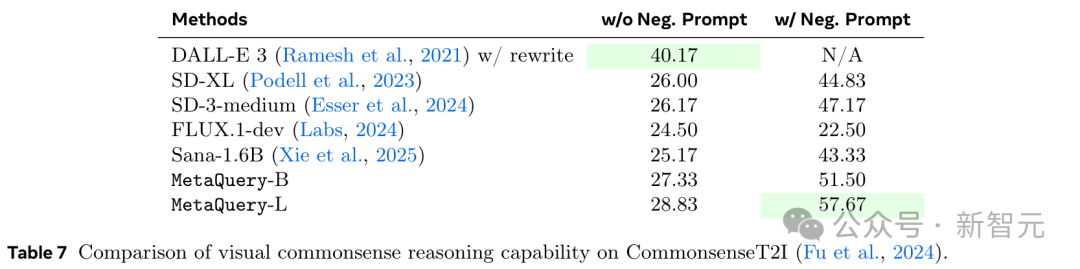
研究人员还在表7中对CommonsenseT2I基准上的MetaQuery的常识推理能力进行了定量评估。
为简单起见,他们遵循其原始实现,使用CLIP作为评估器。结果显示,MetaQuery显著提高了基础Sana模型的性能,达到了SOTA性能。
讨论
如表8所示,研究人员测试了不同LLM骨干对MetaQuery的影响,
包括预训练LLM(Qwen2.5-3B)、指令微调LLM(Qwen2.5-3B-Instruct)和指令微调MLLM(Qwen2.5-VL-3B-Instruct)。
实验结果表明,指令微调可以实现更好的(多模态)理解能力。但当用于提供多模态生成条件时,这些改进与图像生成性能是正交的。

最后一层嵌入方法本质上是将仅解码器的LLM视为文本编码器,这固有地限制了其上下文学习能力。
相比之下,MetaQuery与LLM原生集成,可以自然地利用上下文学习能力,使模型能够通过问题进行推理并生成适当的图像。
如表9所示,MetaQuery在WiScore和CommonsenseT2I基准上都显著优于最后一层嵌入方法。

MetaQueries,一个可以链接MLLM和DiT的简单接口,即使在MLLM被冻结时依然有效。
这种方法非常简单,但很好地实现了最先进的能力和SOTA级别的生成能力。
通过实现模态之间的转换,MetaQueries成功地将MLLM的知识和推理能力引导至多模态图像生成中。
这个方法很有效,但想要弥合与领先的专有系统之间剩余的差距可能仍然需要进一步的数据扩展。
最终,MetaQueries能为未来的统一多模态模型开发提供一个强大、易于获取的基线。
作者介绍

Xichen Pan是纽约大学库朗特学院计算机科学系的二年级博士生,由谢赛宁教授指导。
曾在Meta GenAI Emu团队,微软亚洲研究院,阿里巴巴集团,以及地平线Horizon Robotics等实习。
在上海交通大学获得了计算机科学学士学位,并获得了最佳论文奖。
Ji Hou (侯骥)

侯骥是Meta GenAI的一名研究科学家,致力于基础模型。
在此之前侯骥是Meta Reality Labs中的XR Tech的一名研究科学家,专注于3D场景理解。
在加入Meta之前,侯骥在TUM 视觉计算组攻读博士学位,在那里从事计算机视觉和3D场景理解的研究。在博士期间,曾经在FAIR实习。
侯骥对图像/视频/3D生成模型的研究和应用感兴趣,以及3D计算机视觉,例如3D重建、VR/AR、机器人和自动驾驶等。
Saining Xie(谢赛宁)

谢赛宁是纽约大学库朗计算机科学系的助理教授,同时也是CILVR研究组的成员。此外,还隶属于纽约大学数据科学中心。
曾是Facebook AI Research(FAIR)门洛帕克研究所的研究科学家。
在加州大学圣地亚哥分校计算机科学与工程系获得了博士和硕士学位,导师是Zhuowen Tu。
攻读博士期间,曾在NEC实验室、Adobe、Facebook、Google和DeepMind实习。在上海交通大学获得了本科学位。主要研究方向是计算机视觉和机器学习。
参考资料:
https://xichenpan.com/metaquery/
https://arxiv.org/abs/2504.06256
文章来自于微信公众号 “新智元”,作者 :编辑部 HXZ




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
