# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
作者:Shunyu yao (OpenAI)
链接:https://ysymyth.github.io/The-Second-Half
摘要:我们正处于人工智能的中场。
数十年来,人工智能主要致力于开发新的训练方法和模型。这一策略成效显著:从国际象棋和围棋击败世界冠军,到在 SAT 和律师资格考试中超越大多数人类,再到在国际数学奥林匹克竞赛(IMO)和国际信息学奥林匹克竞赛(IOI)中获得金牌。在这些载入史册的里程碑背后——深蓝(DeepBlue)、阿尔法狗(AlphaGo)、GPT-4 以及一系列以“o”开头的模型——是人工智能方法的根本性创新:搜索、深度强化学习(RL)、扩展和推理。随着时间的推移,事情不断变得更好。
那么,现在有什么突然不同了呢?
用三个词来说:强化学习(RL)终于奏效了。更准确地说:强化学习终于实现了泛化。经过几次重大转折和一系列里程碑式的成就,我们找到了一个可行的方案,利用语言和推理来解决广泛的强化学习任务。即使在一年前,如果你告诉大多数人工智能研究人员,一个单一的方案能够应对软件工程、创意写作、IMO 级别的数学、鼠标和键盘操作以及长篇问答——他们会嘲笑你的幻想。这些任务每一个都极其困难,许多研究人员在他们的整个博士学习期间都专注于其中的一个狭窄领域。
然而,这一切都发生了。
那么,接下来会发生什么呢?人工智能的下半场——从现在开始——将把重点从解决问题转移到定义问题。在这个新时代,评估将比训练更重要。我们不再仅仅问:“我们能否训练一个模型来解决 X 问题?”而是问:“我们应该训练人工智能去做什么,以及我们如何衡量真正的进步?”要在下半场取得成功,我们需要及时转变思维方式和技能组合,这些可能更接近产品经理的思维方式。
要理解上半场,看看它的赢家。你认为到目前为止最有影响力的 AI 论文是哪些?
我尝试了斯坦福大学 224N 课程的测验,答案并不令人惊讶:Transformer、AlexNet、GPT-3 等等。这些论文有什么共同点?它们提出了一些训练更好模型的基本突破。但同样,它们通过在一些基准测试上展示一些(显著的)改进来发表论文。
然而,有一个潜在的共同点:这些“赢家”都是训练方法或模型,而不是基准测试或任务。即使是可以说是最具影响力的基准测试——ImageNet,其引用次数也不及 AlexNet 的三分之一。在其他地方,方法与基准测试的对比甚至更加悬殊——例如,Transformer 的主要基准测试是 WMT’14,其研讨会报告的引用次数约为 1300 次,而 Transformer 的引用次数超过了 16 万次。
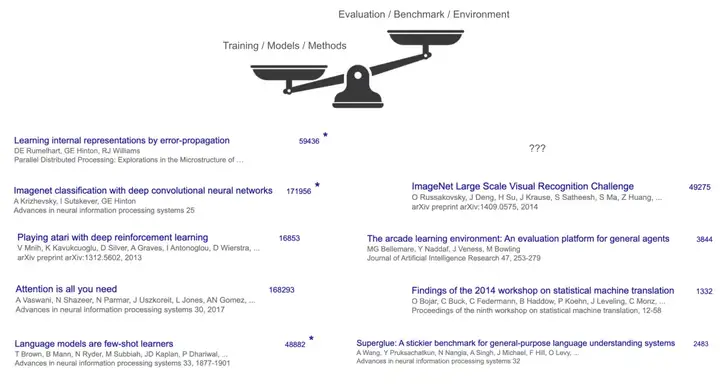
这说明了上半场的游戏:专注于构建新的模型和方法,而评估和基准测试是次要的(尽管为了使论文体系运转起来是必要的)。
为什么呢?一个很大的原因是,在人工智能的上半场,方法比任务更难、更令人兴奋。从头开始创建一个新的算法或模型架构——想想像反向传播算法、卷积网络(AlexNet)或 GPT-3 中使用的 Transformer 这样的突破——需要非凡的洞察力和工程能力。相比之下,为人工智能定义任务往往感觉更简单:我们只是把人类已经做的事情(比如翻译、图像识别或国际象棋)变成基准测试。没有太多洞察力甚至工程能力。
方法也往往比单独的任务更通用、更广泛适用,因此它们特别有价值。例如,Transformer 架构最终推动了计算机视觉(CV)、自然语言处理(NLP)、强化学习(RL)以及许多其他领域的进步——远远超出了它最初证明自己的单一数据集(WMT’14 翻译)。一种伟大的新方法可以在许多不同的基准测试中不断改进,因为它简单且通用,因此其影响往往超越了单一任务。
这种游戏已经持续了几十年,并激发了改变世界的想法和突破,这些突破通过各个领域不断上升的基准测试表现体现出来。那么,为什么游戏会改变呢?因为这些想法和突破的积累在解决任务方面创造了一个有效的方案。
方案是什么?它的成分,毫不奇怪,包括大规模语言预训练、规模(数据和计算)以及推理和行动的理念。这些听起来可能像是你在旧金山每天都能听到的流行语,但为什么称它们为方案呢?
我们可以通过强化学习(RL)的视角来理解这一点,强化学习通常被认为是人工智能的“终局”——毕竟,从理论上讲,强化学习保证能在游戏中获胜,而且实际上很难想象没有强化学习的超人类系统(例如阿尔法狗)。
在强化学习中,有三个关键组成部分:算法、环境和先验知识。长期以来,强化学习研究人员主要关注算法(例如 REINFORCE、DQN、TD-learning、actor-critic、PPO、TRPO……)——即智能体学习的智力核心——而将环境和先验知识视为固定或最小化的。例如,Sutton 和 Barto 的经典教科书几乎只关注算法,而几乎不涉及环境或先验知识。

然而,在深度强化学习时代,很明显环境在实证上很重要:算法的性能往往高度依赖于其开发和测试的环境。如果你忽略环境,你可能会构建一个只在玩具环境中表现出色的“最优”算法。那么,为什么我们不首先确定我们真正想要解决的环境,然后找到最适合它的算法呢?
这正是 OpenAI 最初的计划。它构建了 gym,一个用于各种游戏的标准强化学习环境,然后是 World of Bits 和 Universe 项目,试图将互联网或计算机变成一个游戏。一个不错的计划,不是吗?一旦我们将所有数字世界变成一个环境,用聪明的强化学习算法解决它,我们就拥有了数字通用人工智能(AGI)。
一个不错的计划,但并没有完全奏效。OpenAI 在这条道路上取得了巨大进展,使用强化学习解决了 Dota、机械手等问题。但它从未接近解决计算机使用或网络导航的问题,而且一个领域中的强化学习智能体也无法转移到另一个领域。缺少了什么。
直到 GPT-2 或 GPT-3 出现后,才发现缺失的部分是先验知识。你需要强大的语言预训练,将一般常识和语言知识提炼到模型中,然后可以对其进行微调,使其成为网络(WebGPT)或聊天(ChatGPT)智能体(并改变世界)。事实证明,强化学习中最重要的部分可能甚至不是强化学习算法或环境,而是先验知识,而这些先验知识可以通过与强化学习完全无关的方式获得。
语言预训练为聊天创造了良好的先验知识,但并不是同样适用于控制计算机或玩电子游戏。为什么呢?这些领域与互联网文本的分布相差较远,而简单地在这些领域进行监督微调(SFT)/强化学习泛化效果很差。我在 2019 年注意到了这个问题,当时 GPT-2 刚刚问世,我在其基础上进行了 SFT/RL,以解决基于文本的游戏——CALM 是世界上第一个通过预训练语言模型构建的智能体。但这个智能体需要进行数百万次强化学习步骤才能在一款游戏中不断改进,而且无法转移到新游戏中。尽管这正是强化学习的特性,对于强化学习研究人员来说并不奇怪,但我发现这很奇怪,因为我们人类可以轻松地玩一款新游戏,并且在零样本的情况下表现得更好。然后我迎来了人生中第一次顿悟时刻——我们之所以能够泛化,是因为我们可以选择做的不仅仅是“走到柜子 2”、“用钥匙 1 打开箱子 3”或“用剑杀死地牢怪物”,我们还可以选择思考诸如“地牢很危险,我需要武器来战斗。没有可见的武器,也许我需要在锁着的箱子或柜子里找到一个。箱子 3 在柜子 2 里,我先去那里把它打开”之类的事情。
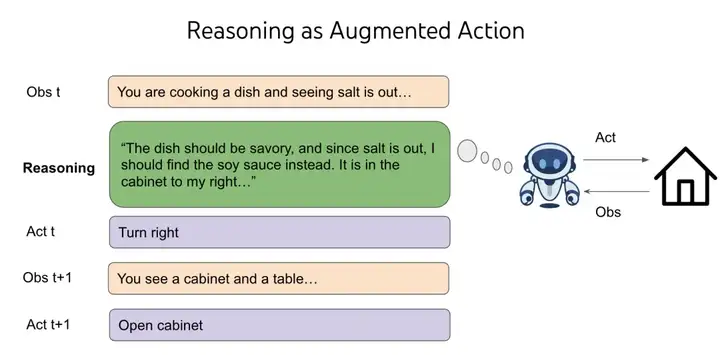
思考,或者说推理,是一种奇怪的行动——它并不直接影响外部世界,然而推理的空间是开放的、组合上是无限的——你可以思考一个单词、一个句子、一段完整的文章,或者 10000 个随机的英文单词,但你周围的世界并不会立即改变。在经典的强化学习理论中,这是一个糟糕的交易,使得决策变得不可能。想象一下,你需要在两个盒子中选择一个,其中一个盒子里有 100 万美元,另一个是空的。你期望获得 50 万美元。现在想象我在其中增加了无数个空盒子。你期望获得的金额就变成了零。但是,通过在任何强化学习环境的动作空间中加入推理,我们利用语言预训练的先验知识来实现泛化,并且我们可以在不同的决策中使用灵活的测试时计算。这是一件非常神奇的事情,我为没有在这里完全讲清楚而道歉,我可能需要再写一篇博客文章专门来解释它。你可以阅读 ReAct 以了解智能体推理的原始故事,并阅读我当时的想法。目前,我的直观解释是:即使你增加了无数个空盒子,你在生活中见过各种游戏中的这些盒子,选择这些盒子为你在任何给定游戏中选择装有钱的盒子做好了准备。我的抽象解释是:语言通过智能体中的推理实现泛化。
一旦我们有了正确的强化学习先验知识(语言预训练)和强化学习环境(将语言推理作为动作),事实证明强化学习算法可能就是最不重要的部分了。因此我们有了 o 系列、R1、深度研究、计算机使用智能体,还有更多即将出现的东西。真是一个讽刺的转折!长期以来,强化学习研究人员一直非常关注算法,而几乎没有人关注环境,更不用说先验知识了——所有强化学习实验本质上都是从零开始的。但我们花了数十年的时间走弯路,才意识到也许我们的优先级完全搞反了。
但正如史蒂夫·乔布斯所说:你不能向前连接这些点;你只能向后连接它们。
这个方案完全改变了游戏。回顾上半场的游戏:
这个游戏正在被破坏,因为:
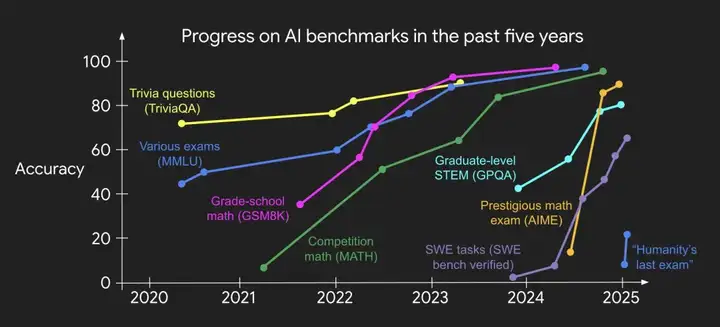
那么,在下半场还剩下什么呢?如果不再需要新方法,而更难的基准测试也会越来越快地被解决,我们应该做什么呢?
我认为我们应该从根本上重新思考评估。这意味着不仅仅是创建新的、更难的基准测试,而是从根本上质疑现有的评估设置并创建新的设置,以便我们被迫发明超越现有方案的新方法。这很难,因为人类有惯性,很少质疑基本假设——你只是把它们当作理所当然,而没有意识到它们是假设,而不是定律。
为了说明惯性,假设你发明了历史上最成功的评估之一,基于人类考试。在 2021 年,这是一个非常大胆的想法,但 3 年后它已经饱和了。你会怎么做?最有可能的是创建一个更难的考试。或者假设你解决了简单的编程任务。你会怎么做?最有可能的是找到更难的编程任务来解决,直到你达到了国际信息学奥林匹克竞赛(IOI)金牌水平。
惯性是自然的,但问题是:人工智能已经在国际象棋和围棋中击败了世界冠军,在 SAT 和律师资格考试中超越了大多数人类,并在国际信息学奥林匹克竞赛(IOI)和国际数学奥林匹克竞赛(IMO)中达到了金牌水平。但世界并没有发生太大变化,至少从经济和国内生产总值(GDP)的角度来看。
我称这为效用问题,并认为这是人工智能最重要的问题。
也许我们会很快解决效用问题,也许不会。不管怎样,这个问题的根源可能出人意料地简单:我们的评估设置在许多基本方面与现实世界的设置不同。举两个例子:

这些假设“一直”就是这样,而在人工智能的上半场,在这些假设下开发基准测试是没问题的,因为当智能水平较低时,提高智能通常会提高效用。但现在,通用方案在这些假设下保证有效。因此,下半场的新游戏方式是:
这个游戏很难,因为它不熟悉。但它令人兴奋。虽然上半场的参与者在解决视频游戏和考试,但下半场的参与者可以通过构建有用的产品来建立价值数十亿甚至数千亿美元的公司。虽然上半场充满了渐进式的方法和模型,但下半场在一定程度上过滤了它们。通用方案会轻易击败你的渐进式方法,除非你创造出打破方案的新假设。然后你就可以进行真正具有变革性的研究。
欢迎来到下半场!
这篇博客文章是基于我在斯坦福大学 224N 课程和哥伦比亚大学的演讲撰写的。我使用 OpenAI 深度研究来阅读我的幻灯片并起草初稿。
文章来自微信公众号 “ 深度学习自然语言处理 “,作者 OpenAI姚顺雨



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
