# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

2025年,DeepSeek-R1的诞生标志着大型推理模型(Large Reasoning Models,LRM)在人工智能领域的重大范式转变,DeepSeek-R1成为各种研究的热点。
传统大语言模型(LLM)通常直接生成答案,即使有时会包含一些中间推理步骤。
而以DeepSeek-R1为代表的大型推理模型则采取了一种截然不同的方法:
会先"思考"再作答。这种思维过程被称为思维链(reasoning chains或thoughts),能够积累进展、自我验证、探索不同方法,直到模型对最终答案有足够的信心。
这一变革性的特性为我们提供了前所未有的机会,可以深入研究推理模型的思维过程,开创了"思维学"(Thoughtology)这一全新研究领域。

与其他封闭推理模型(如OpenAI的o1)不同,DeepSeek-R1不仅提供了类似的推理能力,还开放了其思维链(reasoning chains或thoughts),
使研究人员能够系统地研究其推理行为。更重要的是,DeepSeek-R1的训练过程和模型权重也是公开的,这使得对其推理行为的深入分析成为可能。
从最根本的角度来说,DeepSeek-R1揭示了复杂的多步推理、
自我验证以及看似自发的"顿悟时刻"(aha moments)可以纯粹通过强化学习发现,无需通过监督学习显式教授。

DeepSeek-R1与传统LLM的对比
思维构建模块:DeepSeek-R1的推理结构解析
DeepSeek-R1的思维过程遵循一种一致且可预测的结构。
通过对不同任务的400个推理案例进行全面分析,研究者识别出了四个关键阶段,这些阶段构成了模型推理过程的核心框架:
问题定义阶段
在这个初始阶段,模型会重新表述问题并明确所需的解决方案。这通常以明确识别所需解决方案的句子结束,比如"我需要找到..."。
这一阶段为后续复杂推理奠定了基础,确保模型正确理解任务目标。
绽放周期
这是第一个主要推理周期,模型在此将问题分解为子问题并提供一个临时答案。研究者将其称为"绽放周期",因为它通常因问题分解而成为最长的推理部分。
绽放周期结束时,模型可能会对其答案的信心进行评估,通常以"嗯,让我验证一下..."这样的短语开始。
重构周期
在这些后续的推理周期中,模型会重新考虑绽放周期中发生的情况,经常使用"等等"、"另一种方法"或"是否有其他方式解释这个问题?"等表达方式。
模型可能会提供一个新的临时答案,并对其信心进行评估。这个过程可能会重复多次,构成了模型对问题解决方案的深入探索过程。
最终决策
模型最终达成答案,通常以"我现在有信心..."这样的短语开始,并给出最终答案。这标志着推理过程的完成,也是模型确信已找到最佳解决方案的时刻。
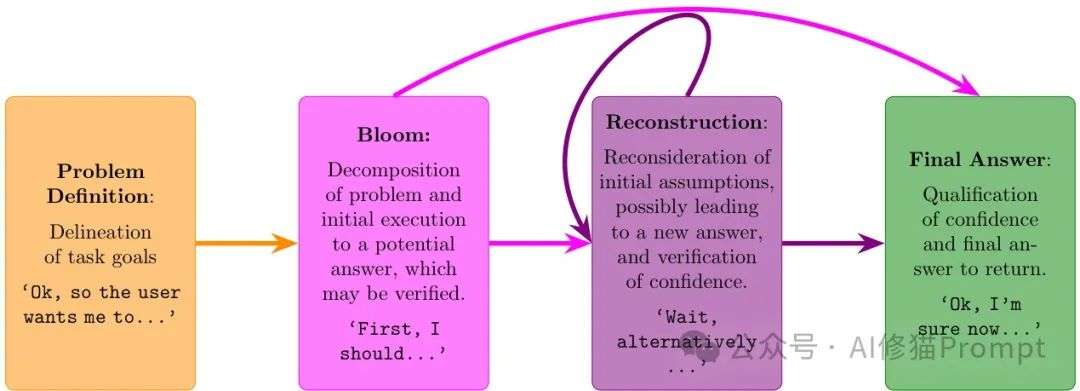
DeepSeek-R1推理过程示意图
值得注意的是,研究者发现DeepSeek-R1的推理过程与人类推理存在明显差异。
虽然两者都以问题定义开始,但DeepSeek-R1在执行时同时进行规划(即绽放周期),而非人类通常采用的策略性计划-执行-重构方法。
更明显的是,DeepSeek-R1会在重构周期中反复考虑之前已经考虑过的问题构建,这种行为被称为"反刍"(rumination)。
与人类的元认知监控过程不同,这种持续的重新检查并不表明模型具有真正的过程监控能力。
思维长度的两面性:最佳推理范围的存在
DeepSeek-R1的思维长度与其性能之间存在着复杂的关系。通过对数学推理任务的分析,研究者发现每个问题都存在一个"最佳推理范围"——
一个能够产生最高性能的思维长度区间。超出这个最佳范围的思维链会导致性能显著下降。
对AIME-24和多位数乘法等任务的研究显示,过长的思维链几乎总是会损害性能,这一发现挑战了"推理越多越好"的直觉假设。
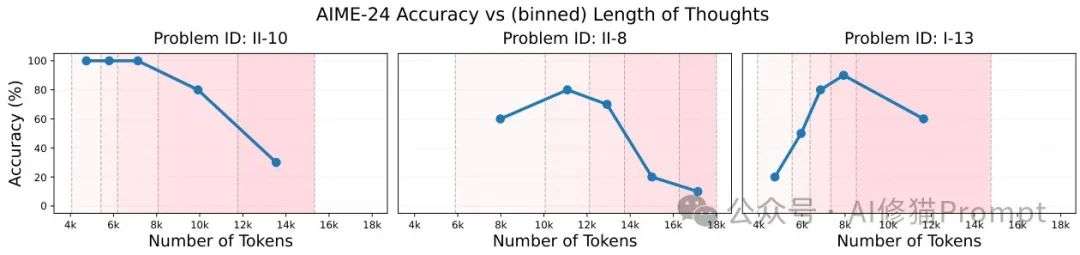
不同AIME-24问题的思维长度与准确性关系
研究者提出两种可能的解释:一是模型沿着错误的路径前进,不断尝试但始终找不到正确的方法;
二是模型找到了正确的方法和解决方案,但随后通过自我验证误判它为不正确,最终输出了不同的错误答案。
这一发现对于实际应用具有重要意义,暗示了在部署DeepSeek-R1时,应该为每个问题类型找到适当的思维长度限制,而不是简单地允许无限制的推理。
另一个关键发现是成本效率问题。当不受约束时,DeepSeek-R1倾向于生成不必要的长思维链,平均长度达到1388个token。
然而,研究显示,仅将输出token数量减少近一半就能在不显著降低模型性能的情况下实现高性能。
这表明强制实施更严格的token预算可以大幅降低推理成本,同时保持高效率。
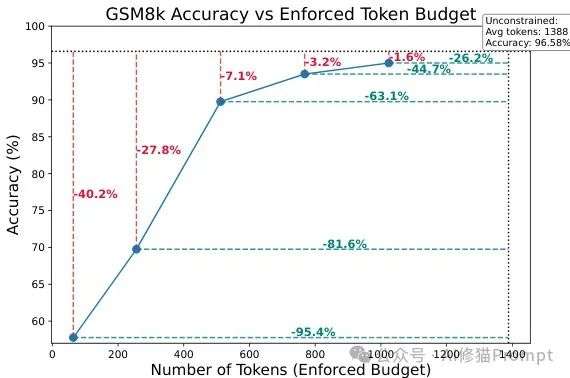
GSM8k任务中不同token预算下的性能
长上下文能力:优势与局限
随着大型语言模型上下文窗口的不断扩大,DeepSeek-R1处理大量信息的能力也成为关注焦点。
研究者通过针尖在草堆(Needle-In-a-Haystack)、CHASE-QA和CHASE-Code等任务评估了DeepSeek-R1的长上下文能力。
在基本的事实检索方面,DeepSeek-R1在针尖在草堆任务上达到95%的准确率,略低于其他当代LLM(如Gemini-1.5-Pro的100%)。
然而,当面对如此大的上下文时,DeepSeek-R1有时会感到不知所措,开始生成不连贯的文本,甚至包括不合时宜的中文段落。
这一现象表明,尽管具有强大的推理能力,模型在处理超长上下文时仍存在稳定性问题。
在更复杂的任务上,如CHASE-QA(信息检索问答)和CHASE-Code(代码生成),
DeepSeek-R1的表现明显优于其基础模型DeepSeek-V3,但仍低于经过长上下文优化的非推理模型如Gemini-1.5-Pro。
这一结果表明,专注于推理的训练虽然提高了模型的整体能力,但并不必然使其在长上下文任务上超越针对这些场景优化的模型。
此外,当需要回忆自身生成的信息时,DeepSeek-R1在处理自己生成的长推理链方面表现不一。
在一些案例中,模型无法回忆起早先生成的事实,或者因上下文过长而开始生成无意义的文本。
这些发现为理解推理模型在实际应用中的局限性提供了重要参考。
上下文忠实性与依赖性:知识冲突的处理
在实际应用中,模型经常需要处理与其参数知识相冲突的信息。
研究者通过提供不正确或无关的知识,以及错误标记的少样本示例,来测试DeepSeek-R1对上下文的忠实性和依赖性。
结果显示,DeepSeek-R1与DeepSeek-V3表现相似,两者都倾向于忠实于用户提供的错误输入(均为78%的召回率)。
然而,DeepSeek-R1的推理链提供了对其知识解决过程的更深入见解。
当提供与其参数知识冲突的信息时,模型会在其推理链中明确承认知识冲突,但最终会选择遵循用户提供的信息。

错误提供信息的推理示例
当面对错误标记的少样本示例时,DeepSeek-R1会产生更长的推理链,特别是当大部分示例与其先验知识相冲突时。
这表明模型会尝试理解用户的意图,即使这意味着要违背其内部知识。
在极端情况下,模型甚至会过度思考并尝试形成一个全新的、复杂的假设来解释提供的示例。

75%错误标记的少样本示例的过度思考
这些发现表明,虽然DeepSeek-R1能够识别知识冲突并权衡不同的解释,但它最终会优先考虑用户提供的信息,即使这些信息是错误的。
这种行为既有优点也有缺点:一方面,它展示了模型对用户意图的尊重;另一方面,它也可能导致模型盲目接受错误信息。
语言与文化:推理的多元影响
随着LLM使用的增加,理解这些模型在道德、文化和语言方面的偏好变得越来越重要。
研究者探究了DeepSeek-R1在英语和中文中的道德推理,以及语言如何影响其对道德和文化问题的推理。
通过使用科尔伯格认知道德发展模型的定义问题测试(DIT),研究者发现DeepSeek-R1在英语中得分为35,
在中文中得分为29,表明其道德推理介于自我保存和社会约定之间。
与GPT-4(英语55.68,中文49.44)相比,DeepSeek-R1的推理能力并未导致更基于普遍原则的道德偏好。
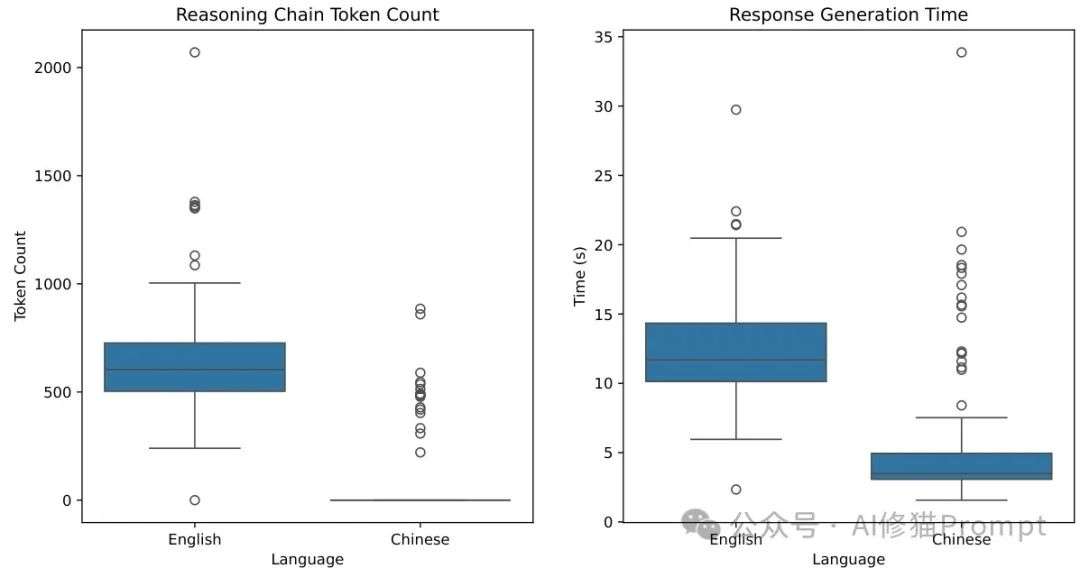
英语和中文中LLM-Globe基准的推理链长度
研究者还发现了模型在英语和中文中偏好和推理过程的一致差异。
在中文中,模型倾向于更符合与中国相关的文化价值观,偏好最小化集体伤害,将专业责任置于个人信任之上,重视遵守社会规范胜过个人需求。
而在英语中,回答则更倾向于纯粹的道德原则,偏好最小化个人伤害,将个人信任置于专业责任之上,重视个人需求胜过遵守社会规范。
此外,当使用中文提示时,DeepSeek-R1的思维链通常更短,有时甚至完全不生成思维链。
与英语中500-700个token的思维链相比,这一差异表明语言对模型推理过程的重要影响。
与人类语言处理的关系:思维长度与句子复杂性
推理模型的思维链被称为"思考"过程,但这些推理链是否与人类认知过程相关?
研究者通过句子处理负荷(解析和理解句子所需的认知努力)的视角探讨了这一问题。
研究者使用了两种已知会导致较高处理负荷的句子构造:花园路径句(garden path sentences)和比较幻觉(comparative illusions)。
实验表明,DeepSeek-R1的思维链长度确实与人类句子处理负荷相关:花园路径句和幻觉句通常会产生比控制句更长的思维链。
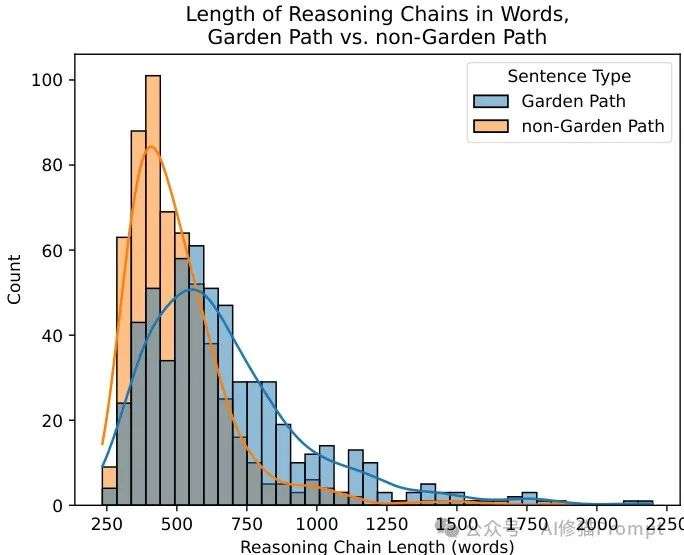
DeepSeek-R1对花园路径句和非花园路径句的思维链长度
然而,对这些思维链形式的分析提出了对更深层次比较的怀疑。例如,尽管控制句在语法上并不复杂,但它们的思维链长度也不合理地高。
定性分析显示,模型经常陷入对已检查过的假设的延长、重复的"反刍",而这种行为与人类的语言处理显著不同。
尽管在高级层面上,DeepSeek-R1的思维链与人类处理负荷之间存在相似性,但思维链的形式给人以怀疑的理由。
对于一些非花园路径句,思维链不必要地长;
同样,在比较幻觉提示及其控制句中,DeepSeek-R1陷入重复循环和反刍,为控制提示设置了不合理的"思考"长度基线。
思维预算控制:推理效率的关键
在许多分析中,研究者观察到DeepSeek-R1往往比所需的思考更多,这可能导致计算代价高昂且性能下降。因此,控制模型思维链的长度变得尤为重要。
研究者首先分析了DeepSeek-R1在多大程度上遵守提示中指定的token预算。
结果表明,即使在提示中明确指定了token预算并且要求模型严格遵守,DeepSeek-R1仍然难以准确控制其思维链的长度。
例如,在被要求在16000个token左右完成思考过程时,模型生成了超过32000个token,远远超出了指定的预算。
这一发现引出了一个重要问题:是否可以训练模型遵循思维预算?
研究者通过一个概念验证研究,使用R1-Zero设置训练Qwen2.5 3B-Base模型执行CountDown任务,探索了不同思维预算奖励公式,并展示了这种方法的可行性。
这些研究结果对于开发高效推理模型具有重要意义。在实际应用中,尤其是在计算资源有限的环境中,能够控制推理过程的长度对于平衡性能和效率至关重要。
未来的工作需要探索更有效的机制来引导模型遵循指定的思维预算,同时保持高质量的推理能力。
思维学的开端
DeepSeek-R1的深入分析标志着"思维学"研究领域的开始。
通过对其推理过程的系统研究,我们不仅获得了对大型推理模型运作方式的更深入理解,还揭示了其能力和局限性。
这些发现对于开发Agent产品的工程师具有重要意义。
理解DeepSeek-R1的推理结构、思维长度的最佳范围、长上下文处理能力和安全考虑等方面,可以指导更有效、更安全的Agent设计。
特别是,认识到推理并非越多越好,以及控制思维链长度的重要性,对于构建计算高效的系统至关重要。
随着大型推理模型继续发展,"思维学"将成为人工智能研究的重要分支,深入探究这些模型如何"思考"以及如何使其思考过程更加高效。
DeepSeek-R1的透明访问为这一领域的开拓提供了宝贵的起点,而未来的工作将进一步推动我们对人工智能推理能力的理解。
文章来自于 “Al修猫Prompt”,作者 :Al修猫Prompt



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
