# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
视频理解的CoT推理能力,怎么评?
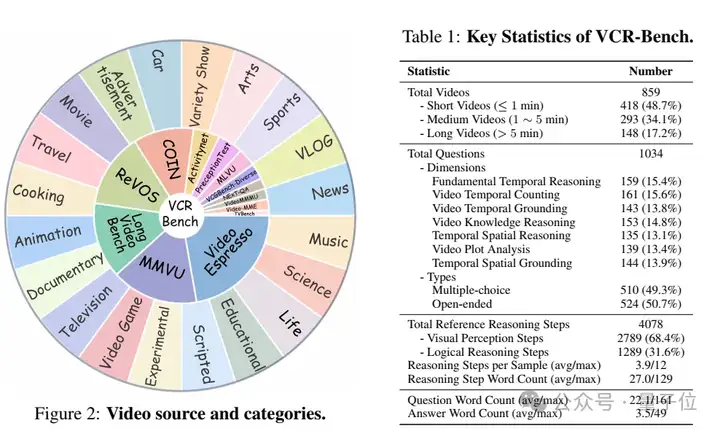
中科大等团队提出了评估基准——VCR-Bench,里面包含七个独立评估维度的任务框架,每个维度针对性地考察模型的不同能力(如时空推理、因果推断等)。为确保评估的全面性和可靠性,每个维度都设计了100余条高质量样本。
结果发现当前多模态模型在视频复杂推理任务上表现普遍不佳——
最优模型o1仅获得62.8的CoT得分和56.7%的准确率,大多数模型两项指标均低于40分,且闭源模型优于开源模型,大模型优于小模型。
具体来看。
在多模态研究领域,视频数据因其丰富的语义信息和全面的场景细节,为构建复杂的思维链(Chain-of-Thought,CoT)推理任务提供了理想载体。
然而,当前多模态研究社区面临一个关键挑战:
缺乏系统化的评估方法来验证模型在视频理解中的CoT推理能力,这严重制约了视频复杂推理任务的研究进展。
针对这一研究空白,中科大等的研究团队创新性地提出了首个面向视频CoT推理过程的多模态评估基准(Benchmark)。

该基准通过建立标准化的评估体系,显著提升了视频理解任务中推理能力的验证效度。
此项工作自发布以来获得了学术界的高度关注,
在HuggingFace的4月11日Daily Papers评选中荣登榜单第二位,展现了其重要的学术价值和应用前景。
研究者认为,当前视频理解领域的评测基准主要存在两个关键性局限:
首先,现有方法普遍仅关注模型输出的最终结果,而忽视了对推理过程的评估。这种评估方式可能导致”假阳性”现象——即便模型在理解或推理环节存在错误,仍可能通过猜测或巧合获得正确的最终答案。
其次,现有基准缺乏对模型推理能力的多维度解构,无法精准识别模型在复杂推理任务中的能力瓶颈(如视觉感知不足与逻辑推理缺陷的区分)。
这两个局限性严重制约了对视频理解模型真实推理能力的科学评估。而针对这些问题所提出的VCR-Bench,则能够很好的实现视频CoT过程评估,填补现有不足。
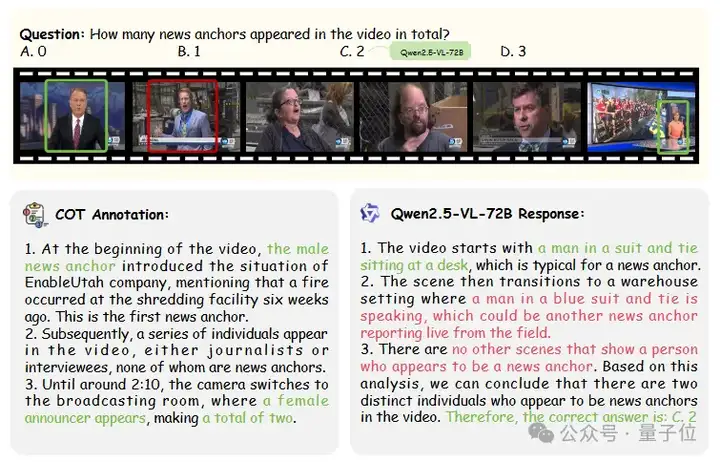
△图1结果评估的局限性
具体而言,研究团队首先构建了包含七个独立评估维度的任务框架,每个维度针对性地考察模型的不同能力(如时空推理、因果推断等)。
为确保评估的全面性和可靠性,每个维度精心设计了100余条高质量样本,最终形成包含859个精选视频和1034组问答对的大规模数据集。
这种多维度的评估体系能够对模型的综合推理能力进行全面诊断,不仅覆盖了视频理解的各个关键环节,还能有效揭示模型在不同能力维度上的强弱项。

△图2不同维度样例
其次,对于数据集中的每一条样本,研究团队不仅提供了标准问答对,还额外标注了经过人工验证的详细CoT推理步骤作为参考标准。
在评估过程中,首先对被测模型生成的推理内容进行结构化解析,将其分解为离散的推理步骤。随后,基于预先定义的能力维度框架,包括视觉感知(perception)和逻辑推理(reasoning)两大类别,对这些步骤进行分类标注。为保障评估的客观性,采用GPT-4o作为自动评分器,通过比对模型生成的推理步骤与人工标注的黄金标准,分别计算步骤类别的召回率(Recall)和精确率(Precision),最终以F1分数作为模型CoT得分。这一评估方案既保证了评分的可解释性,又能有效反映模型在不同推理维度上的真实表现。
最后,采用GPT4o从模型的输出内容中提取出最终结果,并于正确结果进行匹配,从而得到模型在VCR-Bench上推理的结果准确性。
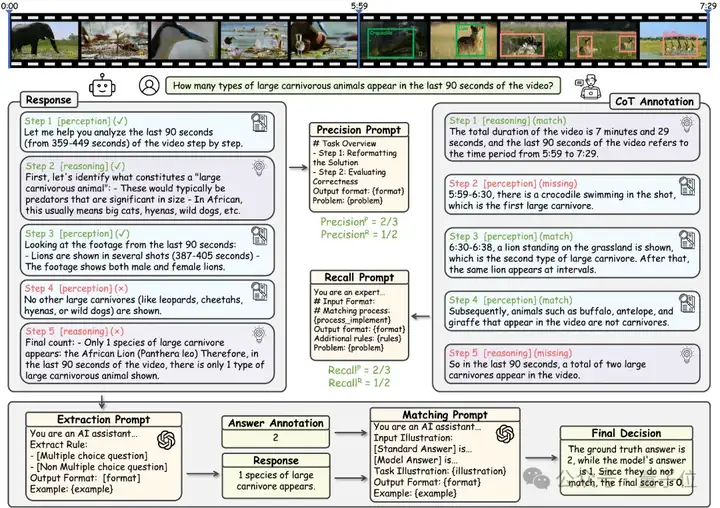
△图3VCR-Bench的评估过程
研究者在VCR-Bench上进行了大量实验,验证了其评估体系的有效性,并得到了多条富有启发意义的结论:
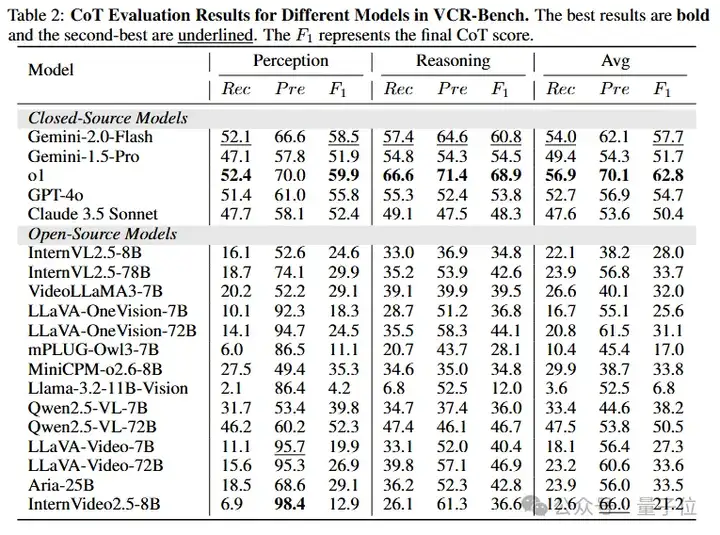
△图4不同模型在VCR-Bench中的CoT得分
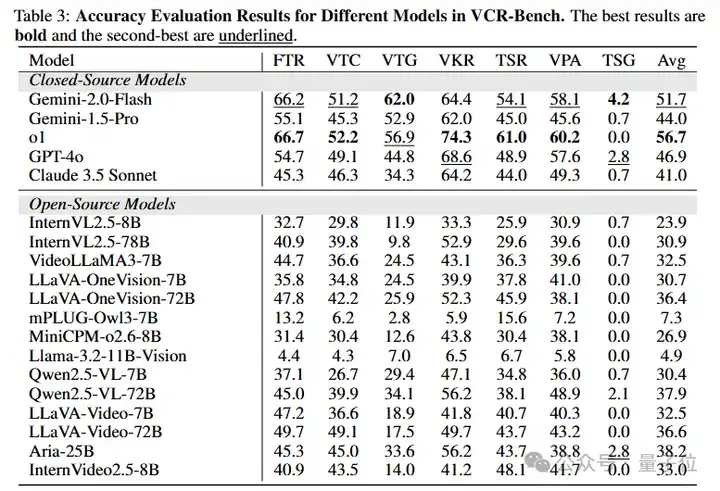
△图5不同模型在VCR-Bench上的准确率结果

△图6TSG任务样例
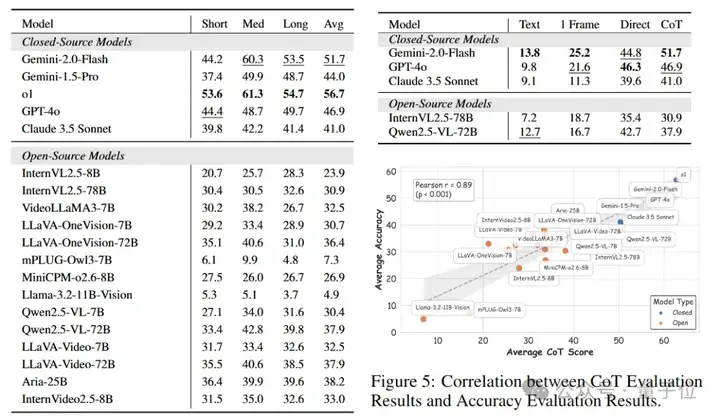
△图7更多实验结果展示。
(左侧:模型在不同时长视频上的准确率;右上:模型在不同实验设置下的准确率;右下:模型CoT得分与准确率的相关性统计)
Paper: https://arxiv.org/abs/2504.07956
Project Page: https://vlm-reasoning.github.io/VCR-Bench/
Dataset: https://huggingface.co/datasets/VLM-Reasoning/VCR-Bench
Code: https://github.com/zhishuifeiqian/VCR-Bench
文章来自于“量子位”,作者“VCR-Bench团队”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
