# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
视频人物抠像技术在电影、游戏、短视频制作和实时视频通讯中具有广泛的应用价值,但面对复杂背景和多目标干扰时,如何实现一套兼顾发丝级细节精度及分割级语义稳定的视频抠图系统,始终是个挑战。
来自南洋理工大学 S-Lab 与商汤科技的研究团队最新提出了一个高效、稳定、实用的视频抠图新方法 ——MatAnyone。与传统无辅助方法不同,MatAnyone 提出一种基于记忆传播的「目标指定型」视频抠像方法:只需在第一帧通过人物遮罩指定抠像目标,即可在整个视频中实现稳定、高质量的目标提取。
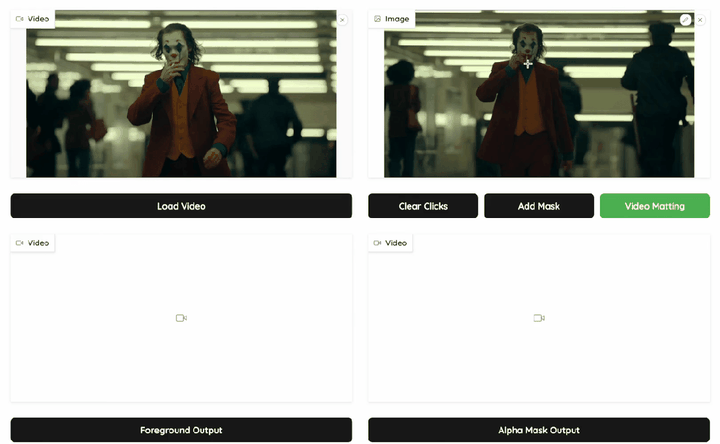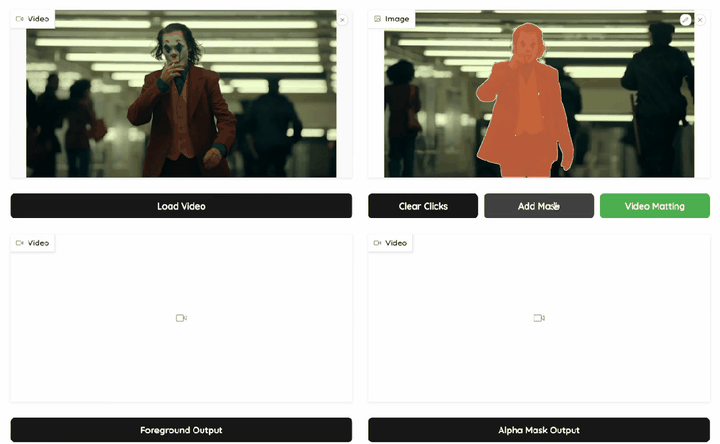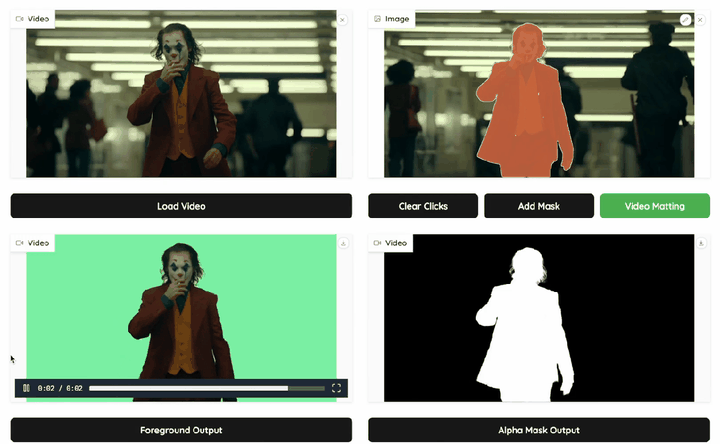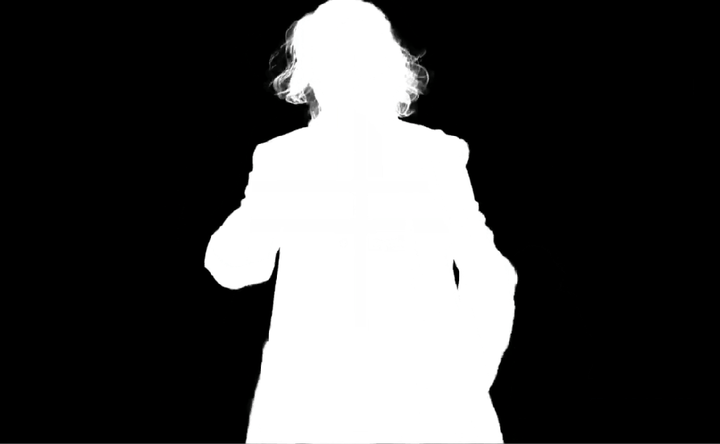

MatAnyone 一经发布在社交媒体上获得了大众的讨论和关注,其核心亮点总结如下:
仅需首帧目标指定,无需额外辅助信息,支持灵活定义抠图对象,满足多场景需求。
创新 “区域自适应记忆融合” 机制,有效保持目标一致性,实现长视频中的稳定人像跟踪。
融合真实分割数据与高质量新数据集,边界处理自然平滑,抠图效果更贴近真实。
目前主流的视频抠图方法根据 “除输入视频外是否有其他辅助输入” 这一条件可以分为两类:
无辅助型方法虽然方便,但是由于主体目标不明确,在真实使用场景中容易出现影响实际使用的错抠、漏抠等现象。
因此,为了让视频抠像技术能被更好地使用,MatAnyone 选择了辅助引导型的设定,并专注解决的是这样一个场景:
「设定主角,其他交给模型」:给定目标人物在第一帧的掩膜,后续的抠像自动锁定目标完成。无需逐帧修正,准确、自然、连贯地抠出整段视频。
这种设置既兼顾用户可控性,又具有更强的实用性和鲁棒性,是当前视频编辑领域最具潜力的落地方案之一。

任务对比:「视频抠图」比「视频分割」更难一层
虽然 “目标指定型” 的任务设定在视频目标分割(Video Object Segmentation, VOS)中已经被广泛研究,通常被称为 “半监督” 分割(即只给第一帧的掩膜),但视频抠图(Video Matting, VM)的难度却更进一步。
在 VOS 中,模型的任务为“是 / 否为目标前景” 的二值判断题;而在 VM 中,基于这个语义判断,模型还需预测目标前景在每个像素点上的 “透明度(alpha)”—— 这不仅要求核心区域的语义精准,更要求边界细节的提取(如发丝、衣角的半透明过渡)。

MatAnyone 正是在这一背景下提出了面向视频抠图任务的全新记忆传播与训练策略,在达到分割级语义稳定的基础上进一步实现了发丝级细节精度。
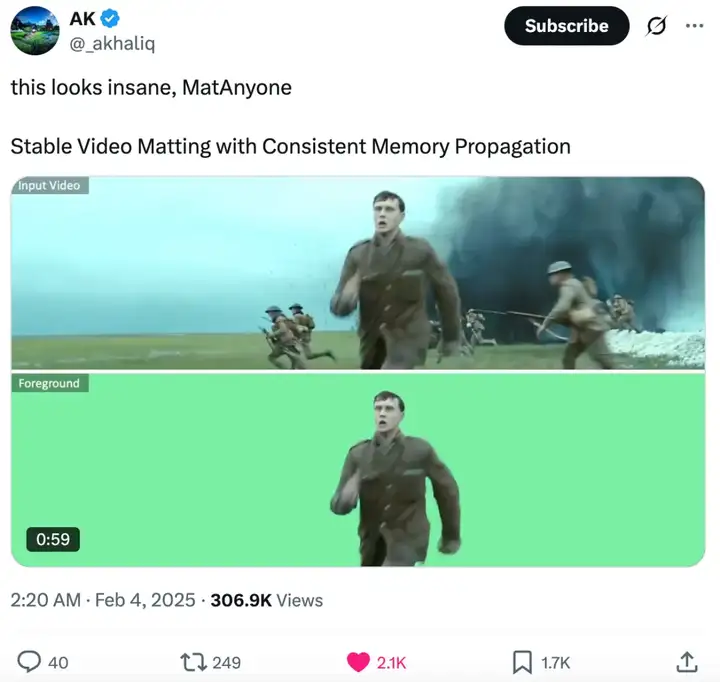
相比静态图像抠图,视频抠图面临更大的挑战,不仅需要逐帧生成高质量的透明通道( alpha matte),还必须确保前后帧之间的时序一致性,否则就会出现闪烁、跳变等明显视觉问题。为此,MatAnyone 借鉴视频分割中的记忆机制,在此基础上提出了专为视频抠图设计的一致性记忆传播机制(Consistent Memory Propagation)。
区域自适应融合记忆(Region-Adaptive Fusion)
模型会在每一帧中预测哪些区域与上一帧差异较大(如身体边缘),哪些区域变化很小(如身体主干),并分别处理:
边界细节增强,核心区域稳定
这种区域感知式的信息融合方式,在训练阶段引导模型更专注于细节边界,在推理阶段则提升了语义稳定性与时间一致性。尤其在复杂背景或人物交互频繁的场景下,MatAnyone 能够稳准地识别目标、抠出清晰自然的边缘效果,极大提升了视频抠图的可用性与观感质量。

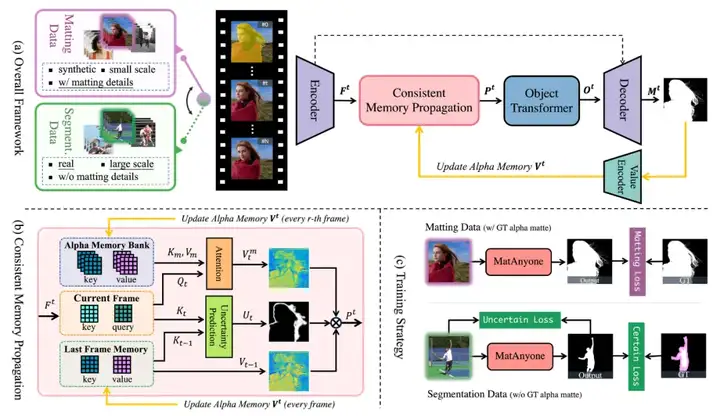
一直以来,「视频抠图」的一个核心难点始终是真实训练数据的缺失。相较于「视频分割」在真实数据上的标注成本,「视频抠图」所需要的带透明度标注的数据格外昂贵,这限制了模型在稳定性与泛化能力上的进一步提升。
在真实透明度数据稀缺的背景下,Video Matting 模型往往会引入大量真实分割数据进行辅助训练,以提升模型在复杂环境中的稳定性和泛化能力。
这种结构虽然能一定程度引入语义信息对抠图头的监督,但其不直接的监督方式导致语义信息在特征传播过程中被稀释,无法充分发挥分割数据对提升稳定性的优势。
这种方式极大提高了语义信息的共享效率,也最大程度地利用了真实分割数据对透明通道预测的泛化性和稳定性的提升。
具体操作上:
这一策略的核心优势在于:让分割数据 “真正服务于抠图任务本身”,而非仅仅提供辅助信号。
高质量的数据始终是训练稳定、泛化强的视频抠图模型的基础。针对现有数据集在规模、细节和多样性上的不足,MatAnyone 团队自建了两套关键数据资源:
这两套数据集为 MatAnyone 提供了扎实的训练基础与更贴近真实世界的验证标准,在推动模型性能提升的同时,也为未来视频抠图研究提供了更具挑战性的新 benchmark。

MatAnyone 在模型设计与推理机制上的灵活性,使其具备良好的任务泛化能力,能够适配多种实际视频处理场景(更多例子请移步主页):
通用视频抠图(General Matting):适用于短视频剪辑、直播背景替换、电影 / 广告 / 游戏后期等常见场景,仅需第一帧提供目标掩膜,后续帧即可自动完成稳定抠图,具备边界清晰、背景干净、跨帧一致性强的优势。
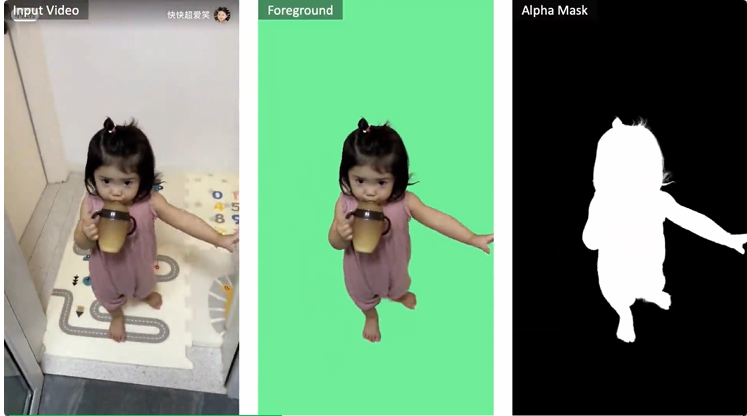
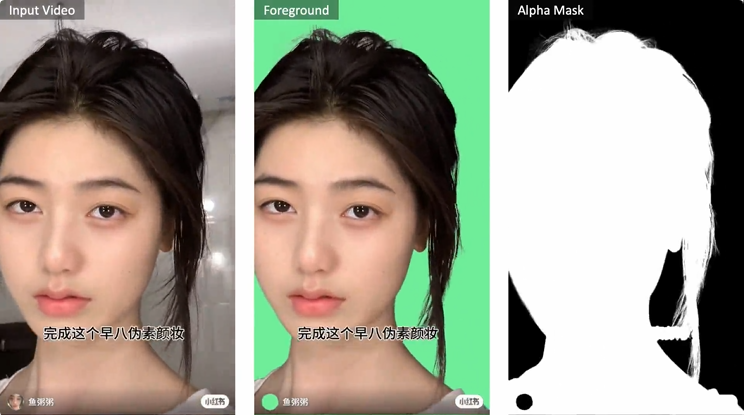

实例抠图(Instance Matting):面对多人物或复杂背景的视频内容,MatAnyone 支持通过第一帧掩膜指定目标对象,进行后续稳定追踪与抠图,有效避免目标混淆或漂移,适合虚拟人剪辑、人物聚焦等实例级编辑任务。
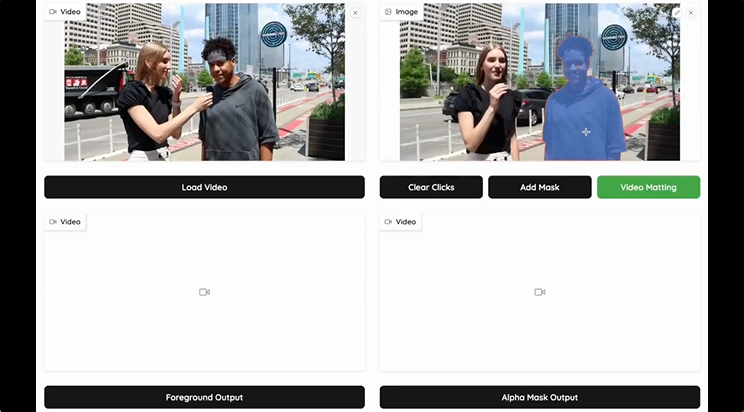
推理阶段增强(Iterative Refinement):对于高精度场景,如广告制作、影视后期等,MatAnyone 提供可选的首帧迭代优化机制,通过多轮推理精细化第一帧 alpha matte,从而进一步提升整段视频的细节还原与边界自然度。

为了系统评估 MatAnyone 在视频抠图任务中的综合表现,我们从定性与定量两个角度进行了对比实验,结果显示 MatAnyone 在精度、稳定性与视觉质量等多个维度均优于现有主流无辅助型及辅助引导型方法。
定性评估(Qualitative)
在真实视频案例中,我们展示了 MatAnyone 与现有方法 RVM、FTP-VM、MaGGIe 的可视化对比。结果表明,MatAnyone 能够更准确地提取目标人物轮廓,尤其是在人物动作剧烈或背景复杂的情况下,依然能保持头发、边缘衣物等细节的清晰度,并有效避免背景穿透与边界断裂等常见问题。同时,它也具备更强的实例区分能力,即使画面中存在多个显著人物,也能准确锁定目标对象并保持一致跟踪。


定量评估(Quantitative)
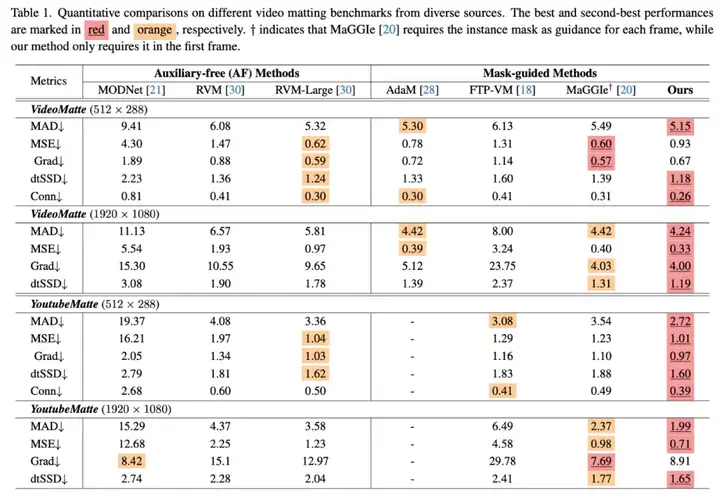
在合成数据集 VideoMatte 和自建的 YouTubeMatte 上,我们使用五个关键指标对各方法进行全面评估:
如 Table 1 所示,MatAnyone 在高、低分辨率的所有数据集上均取得最低的 MAD 和 dtSSD,表现出极高的语义稳定性与时间一致性;同时在 Conn 指标上也位居首位,验证了其在整体观感和边缘处理上的领先表现。
MatAnyone 是一套面向真实使用场景的人像视频抠图系统,专注于在仅提供首帧目标的前提下,实现语义稳定且边界精细的视频级抠图。根据「视频抠图」任务的特性,它引入了区域自适应的记忆融合机制,在保持语义稳定性的同时,精细提取了头发等细节区域。借助新构建的 VM800 高质量数据集与全新的训练策略,MatAnyone 显著提升了在复杂背景下的抠图稳定性。
面对真实训练数据的制约,「视频抠图」任务仍然像是在 “戴着镣铐跳舞”,当前的效果虽有显著突破,但仍有广阔的提升空间。未来,我们团队将继续探索更高效的训练策略、更泛化的数据构建方式,以及更通用的记忆建模机制,推动视频抠图技术在真实世界中实现更强鲁棒性与更广应用性。
文章来自于“机器之心”,作者“杨沛青”。




【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
