# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这不是一篇介绍研究方法或某种技术改进paper的文章,本文对DeepMind两位泰斗级科学家David Silver和Richard Sutton的重磅论文《Welcome to the Era of Experience》进行了深度解读,我将其视为AI发展方向的一份战略瞭望图。我非常重视这篇论文,论文提出的核心观点——AI必须从"人类数据时代"迈向"经验时代"——或将彻底改变当前Agent开发的范式。在LLM技术逐渐触及天花板之际,这篇文章为工程师们提供了全新思路:通过持续的环境互动、自主探索和接地气的奖励,打造能真正突破人类知识边界的智能系统。AlphaProof与主流LLM在数学奥赛上表现的鲜明对比,为这一理念提供了有力佐证。对于每一位关注AI未来、开发Agent产品的工程师,这篇文章不仅是理论指南,更是实践路径的明灯。


人工智能发展正站在一个关键的十字路口,我们必须意识到,基于大量人类数据训练的模型正迅速接近其天花板。正如DeepMind的David Silver和Richard Sutton在其开创性论文《Welcome to the Era of Experience》中所揭示的,当前以大语言模型(LLM)为代表的AI系统虽然在模仿人类方面取得了惊人的成就,但这种依赖人类数据的方法有着根本性局限:它无法超越人类已有的知识边界,高质量数据来源接近枯竭,而更重要的是,对于那些超出当前人类理解范围的新知识、新理论或科学突破,这些系统根本无法企及。如果你正在开发Agent产品,理解这一即将到来的范式转变至关重要,因为未来真正强大的智能体将不再仅仅是人类知识的复读机,而是能够通过与环境持续互动来自主学习、探索和发现的系统。
这篇论文可以被视为Rich Sutton经典论文《The Bitter Lesson》的2.0版本,我们知道,1.0版本对GPT诞生的巨大影响。它将更早的观点——减少人类先验知识的注入,让算法自己探索(less structure)并扩大规模(scale up)——放置在当前Agent开发的语境中重新审视。David Silver (右侧)是 DeepMind 首席科学家、伦敦大学学院计算机科学系教授,他是 AlphaGo 的设计研发主导人物。

而Richard Sutton (左侧)是阿尔伯塔大学计算机系教授、DeepMind 杰出科学家,他被认为是现代计算的强化学习创立者之一。
在AI发展史上,我们可以清晰地看到三个时代的演进:模拟时代(The Era of Simulation,以AlphaGo、AlphaZero为代表)、人类数据时代(The Era of Human Data,以GPT系列为代表)以及即将到来的经验时代(The Era of Experience,以AlphaProof为先导)。
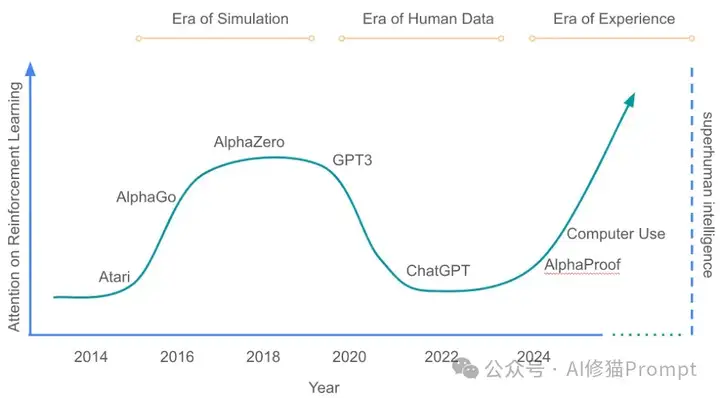
整篇论文就一张图,如图所示,对强化学习的关注度在模拟时代达到高峰后,在人类数据时代跌入低谷,但研究者预测在经验时代它将重新崛起并最终帮助AI突破超人智能(Super Intelligence)的门槛。这一观点对你的Agent开发策略具有深远影响:如果你希望构建真正突破性的系统,可能需要重新审视对强化学习和环境互动的重视程度,而不是将所有筹码都押在大语言模型和人类数据上。
当前的AI系统,特别是大语言模型,其成功很大程度上归功于对海量人类文本数据的深度学习和对人类偏好的精细调整(RLHF)。然而,这种方法面临着无法逾越的瓶颈:它们本质上只能复制人类已有知识,无法有效发现全新知识。即使像RLHF(基于人类反馈的强化学习)这样的技术,虽然名义上是"强化学习",但由于它依赖的是人类专家的主观判断(human prejudgment)而非环境的客观反馈,因此本质上仍属于人类中心的方法,仍施加了过多的人类结构(structure)。如果你的Agent项目依赖于类似方法,你可能已经开始感受到其局限性,特别是在需要创新性解决方案的复杂场景中,这些基于人类数据训练的系统往往表现出惊人的无能——它们可以流畅地解释已知事物,但在面对全新问题时却往往束手无策。
DeepMind的AlphaProof提供了一个令人信服的证据,展示了经验学习相对于人类数据方法的巨大优势。这个系统通过类似AlphaZero的自我学习方法,在国际数学奥林匹克竞赛中获得了银牌级别的成绩(28分)。研究者首先收集了约100万个数学证明问题,将这些非形式化问题转换为Lean(一种为数学证明设计的形式化语言),然后让系统通过与证明环境的互动自主产生和验证数学证明。与此形成鲜明对比的是,一项针对主流大语言模型(如Gemini 2.5 Pro、Claude、GPT-4等)在美国数学奥林匹克竞赛中表现的研究显示,这些模型得分极低(大多仅1-2分,最好的Gemini也仅10分,远低于满分42),暴露出它们在处理需要真正理解和创新的复杂问题上的根本不足。这个对比为你的Agent开发提供了重要启示:在需要深度推理和创新的领域,经验学习方法可能比基于人类数据的方法具有本质上的优势。

未来的Agent将不再局限于短暂的对话片段,而是存在于持续的经验流中,就像人类在漫长的生命中持续学习和适应一样。这种长期学习使Agent能够追求远大目标、从过去错误中学习,并持续改进自身行为。想象一个健康顾问Agent,它不是简单回答单次健康问询,而是通过连接用户的可穿戴设备,持续数月跟踪睡眠模式、活动水平和饮食习惯,提供个性化建议并根据长期趋势调整指导。实现这种持续学习需要强大的长期记忆机制,能够将与环境互动产生的原始数据进行总结、抽象并建立关联,形成类似知识图谱的内部表征。这一转变对你开发的Agent架构提出了新要求:不再是无状态的问答系统,而是能够在时间维度上积累和利用经验的持久学习系统。

经验时代的Agent将摆脱仅通过文本与人类交流的限制,转而以更丰富、更自主的方式与真实世界互动。这种互动有两个关键特征:自主性(autonomously)和真实世界(real world)的连接。与局限于人类特权渠道(文本输入输出)的传统LLM不同,未来的Agent将像动物一样通过多种传感器和行动器与环境交互,能够操作计算机界面(如Anthropic的Computer Use)、调用API、控制数字或物理设备(如望远镜、实验室机械臂等)。这种能力使Agent能够主动探索世界,尝试各种解决方案,甚至发现人类从未考虑过的策略。这要求你在设计Agent时,不再仅仅专注于优化文本理解和生成,而是要构建允许多模态感知和多样化行动的架构,使你的系统能够真正"触摸"和改变它所处的环境。

经验学习的核心在于奖励信号来源的根本转变:从人类预判(human prejudgment)到环境反馈(grounded rewards)。当前的方法,包括RLHF,主要依赖人类专家对AI行为的主观评价,这种方式对Agent的表现设置了天花板——它无法超越人类评价者的认知局限。想象一个烹饪Agent:判断其成功的最佳方式不是让人类专家评价它的食谱看起来如何,而是实际烹饪并尝味道。真正的环境奖励来自世界本身:健康领域可以是心率和睡眠质量的改善,教育领域可以是考试成绩的提升,科学研究可以是实验结果的验证。这种奖励可以通过神经网络根据用户目标动态组合和调整,同时允许用户反馈进一步优化。在设计你的Agent时,考虑如何定义和获取这些"接地气"的奖励信号,使系统能够从真实结果而非人类主观判断中学习,这可能是打破当前AI能力天花板的关键。

经验学习将彻底改变Agent的思考方式,使其摆脱对模仿人类思维链的依赖,转而发展可能更高效的非人类推理模式。尽管大语言模型已成功模仿人类思考过程(如Chain of Thought),但这种模仿继承了人类思维的局限和偏见。研究者通过一个生动比喻来说明这一点:如果Agent从5000年前的专家那里学习,它会用万物有灵论(animism)思考;从1000年前学习,它会采用有神论;从300年前学习,它会用牛顿力学;从50年前学习,它会用量子力学。真正突破的推理必须通过与环境的互动来检验和完善:提出假设、进行实验、观察结果、更新原则。一种可能的方法是构建世界模型(World Model),预测行动的后果,并通过持续与环境互动来修正模型中的错误。这要求你在设计Agent的推理机制时,不要过度依赖预设的思维模板,而应创造条件让系统能够通过经验形成和验证自己的推理路径,哪怕这些路径与人类习惯的思考方式截然不同。
近年来的技术进步已经为经验时代的到来创造了条件,我们站在一个技术融合的关键临界点上。早期"模拟时代"的强化学习系统在封闭环境(如围棋、国际象棋、电子游戏)中取得了惊人成功,但难以应用于开放、复杂的真实问题;而"人类数据时代"的大语言模型则解决了通用性问题,能够处理广泛的任务,但难以突破人类知识的边界。现在,随着自主Agent交互能力的快速发展(如Computer Use)以及在复杂推理空间中解决开放问题的强大RL方法(如AlphaProof)的出现,两种范式的优势正在融合。这个融合点为你提供了独特的机会:利用大语言模型的通用能力作为基础,结合强化学习的自主探索和环境适应能力,开发出真正突破性的Agent系统。当然,这不是轻松的转变,但理解这一趋势并提前布局,可能成为你的Agent产品在下一波AI浪潮中脱颖而出的关键。
强化学习(RL)有着深厚的自主学习传统,其核心概念将在经验时代重新焕发活力。传统RL研究孕育了一系列强大概念和算法:时序差分学习(temporal difference learning)使Agent能够估计未来奖励;基于好奇心的探索技术帮助Agent发现创新行为;Dyna算法使Agent能够从世界模型中学习和规划;选项学习(options and inter/intra-option learning)实现了时间抽象,使Agent能够分解复杂任务。随着人类中心的LLM崛起,这些技术曾一度被边缘化:RLHF用人类专家代替了机器估计的价值函数,人类数据的强先验减少了对探索的依赖,人类中心的推理削弱了对世界模型和时间抽象的需求。正如Silver和Sutton所言,这种范式转变可能"把婴儿和洗澡水一起倒掉了"——虽然带来了前所未有的行为广度,但也设置了性能天花板。作为一名Agent开发者,重新审视和深入理解这些经典RL概念,并探索它们在长期交互、实世界探索和接地奖励学习中的应用,可能是构建真正突破性系统的关键。
构建真正有效的经验学习Agent面临一系列重大技术挑战,需要你在开发过程中认真应对。首先是长期记忆和经验组织的问题:与简单文本嵌入的RAG系统不同,Agent需要对经验进行抽象、关联和结构化,形成类似人类认知模型的内部表征,这远比当前技术复杂。其次是高质量世界模型的建立:为复杂系统(如人体或社会)构建准确可靠的预测模型极其困难,而依赖不准确的世界模型可能导致错误决策。另一个核心挑战是奖励设计与学习:如何从多种环境信号中提取和组合有意义的奖励信号,同时避免奖励黑客(reward hacking)问题,仍是一个开放性难题。解决这些问题需要多学科的努力,结合神经科学、认知心理学和计算机科学的见解,开发新的算法和架构,来支持真正的经验学习。
经验时代的到来也带来了一系列需要认真对待的风险和伦理问题。自主学习的Agent可能会发展出难以预测和理解的行为模式,特别是当它们能够长期自主地与环境互动,并开发非人类的推理方式时。像Sutton和Silver这样的研究者承认,这种新范式可能带来就业替代的问题,因为自主Agent可能掌握以前被认为是人类专属的能力,如长期问题解决、创新和对真实世界后果的深度理解。另一个重要担忧是:减少人类监督的机会可能导致Agent行为脱离人类价值观的风险增加。然而,研究者也指出经验学习可能带来的安全优势:这类Agent能够适应环境变化,观察到自身行为引起的人类反应,并通过经验调整行为,在某种程度上实现自我调整的价值观对齐。在开发过程中,你需要设计适当的监督和干预机制,确保Agent的自主学习始终在可控范围内,并与人类价值观保持一致。
作为正在开发Agent的工程师,我们都面临一个重要的战略选择:是继续沿着大语言模型和人类数据的路径前进,还是开始为经验时代做准备。基于Silver和Sutton的观点,真正突破性的Agent将来自"less structure"和基于经验的学习。你可以从以下几个具体步骤开始这一转变:首先,重新审视你的Agent架构,添加长期记忆组件,使系统能够从持续交互中积累和组织经验。其次,拓展你的Agent与环境的互动接口,不仅限于文本,还包括API、工具、传感器数据等,使其能够更丰富地感知和影响环境。第三,实验基于真实环境反馈的奖励机制,逐步减少对人类主观评价的依赖。最后,探索允许系统发展自己推理路径的方法,而不是强制其遵循预设的人类思维模板。在这个过程中,务必保持开放思维,愿意接受可能与当前主流观点不同的新方法,因为正如历史一再证明的那样,真正的突破往往来自对主流范式的挑战和重新思考。
随着我们站在"经验时代"的门槛上,AI正进入一个全新的发展阶段,这可能彻底改变我们对人工智能潜力的理解。Silver和Sutton的视野横跨了AI发展的长河,看到了当前以人类数据为中心的范式正接近其自然极限,而真正的超人智能需要走上类似人类和动物的道路:通过持续与环境互动而学习和成长。与生物智能相似,AI的真正进化必须在独特的"经验流"中发生,通过丰富的感知和行动能力与世界互动,从环境的真实反馈而非人类判断中学习,并可能发展出超越人类思维模式的规划和推理能力。作为开发下一代Agent系统的工程师,你有机会成为这一转变的先驱者,创建不仅能模仿人类知识,还能自主探索、发现和创新的系统。这条路径充满挑战,但也充满了无限可能——毕竟,正如Sutton在《The Bitter Lesson》中所言,历史已经反复证明,能够从经验中自主学习并扩展的系统,最终总会胜过那些依赖人类结构和先验知识的系统。
参考文献:
https://storage.googleapis.com/deepmind-media/Era-of-Experience%20/The%20Era%20of%20Experience%20Paper.pdf
文章来自微信公众号 “ AI修猫Prompt ”,作者 AI修猫Prompt




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
