# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
论文的第一作者是香港中文大学(深圳)数据科学学院三年级博士生徐俊杰龙,
指导老师为香港中文大学(深圳)数据科学学院的贺品嘉教授和微软主管研究员何世林博士。
贺品嘉老师团队的研究重点是软件工程、LLM for DevOps、大模型安全。
大型语言模型(LLM)近期在软件工程领域取得了显著进展,催生了 MetaGPT、SWE-agent、OpenDevin、Copilot 和 Cursor 等大量研究成果与实际应用,
深刻影响着软件开发的方法论和实践。现有研究主要聚焦于软件开发生命周期(SDLC)的早期阶段的任务,
如代码生成(LiveCodeBench), 程序修复(SWE-Bench),测试生成(SWT-Bench)等等。然而,这些研究往往忽视了软件部署后的运维阶段。
在实际生产环境中,线上软件的故障可能导致服务提供商遭受数十亿美元的损失,这凸显了在根因分析(RCA)领域开发更有效解决方案的迫切需求。
为了探索 LLM 在这一领域的可行性,学术界和工业界的许多研究者已经开始进行相关研究。
然而,受限于运维数据的隐私性以及企业系统的差异性,目前基于 LLM 的根因分析研究缺乏统一且清晰的任务建模,也没有公开的评估数据和通用的评估指标。
这使得公平地评估 LLM 在根因分析方面的能力变得困难,进而阻碍了该领域的发展。
为了解决这一问题,微软 DKI 团队、香港中文大学(深圳)贺品嘉教授团队与清华大学裴丹教授共同提出了当前首个公开的、
用于评估 LLM 根因分析能力的基准评估集 ——OpenRCA。本文已被 ICLR 2025 接收。
OpenRCA 为基于 LLM 的 RCA 任务制定了清晰的任务建模和对应的评估方法,并提供了一组公开且经过人工对齐的故障记录和大量的运维可观测数据。
这为未来基于 LLM 的 RCA 方法的探索奠定了基础。

研究者发现,当前主流的 LLM 在直接解决 OpenRCA 问题时面临显著挑战。
例如,Claude 3.5 在提供了 oracle KPI 的情况下,仅解决了 5.37% 的 OpenRCA 任务。
当使用随机均匀抽样策略提取可能相关的数据时,这一结果进一步下降到 3.88%。
为了为解决 OpenRCA 任务指明可能的方向,研究者进一步开发了 RCA-agent,以作为一个更有效的基线方法。
在使用 RCA-agent 后,Claude 3.5 的准确率提升至 11.34%,但依然离解决好 OpenRCA 问题有着较大的差距。
任务建模
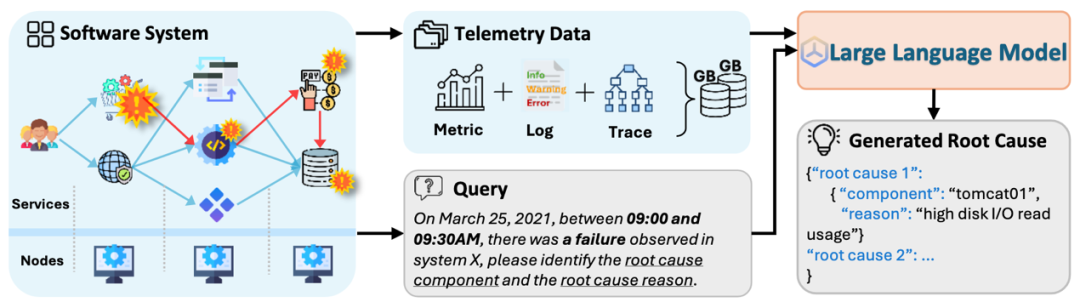
OpenRCA 将基于 LLM 的根因分析任务定义为目标驱动的形式:模型或智能体将接收由自然语言组成的查询指令,执行不同目标的根因分析任务。
根据查询指令,模型或智能体需要通过检索和分析当前系统中保存的运维可观测数据(包括指标、日志、调用链),
从中推理并识别出三种根因的组成元素(故障时间、故障组件和故障原因)中的一个或多个元素,并最终以 JSON 结构输出。
当输出中的所有元素与标签一致时,该样本被视为正例;否则,视为反例。OpenRCA 通过计算样本的平均预测正确率来评估方法的能力。
评估数据
为了确保所使用的软件故障记录和运维数据的质量,OpenRCA 将往年 AIOps 挑战赛系列中提供的大量来自企业系统的匿名运维数据集合作为数据源。
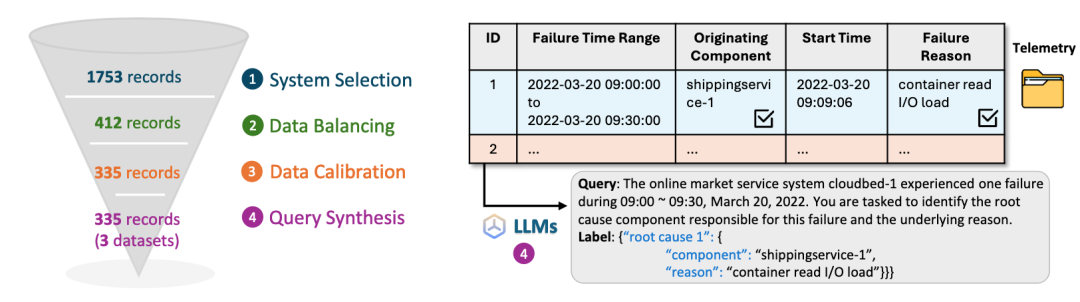
为保障数据质量的可靠性,研究者进行了包括四个步骤在内的人工数据处理和标签对齐。
具体来说,研究者排除了无法用于根因定位的系统观测数据,这些数据通常仅能用于粗粒度异常检测,而缺乏详细的故障记录,例如故障原因等信息。
接着,研究者整理了这些系统的数据,对不同系统间的样本数量进行了均衡化处理,并标准化了不同系统数据的目录结构,以便于模型的检索。
最重要的是,为保证问题的可解性,研究者手动验证了剩余数据中的故障是否可以通过相数据人工定位到故障根因。
研究者去除了满足以下任一条件的数据记录:(1)无法数据中识别根因;(2)故障期间数据缺失;(3)从数据推断出的根因与标签不一致。
最终,研究者根据不同的根因定位目标,使用 LLM 为每个故障案例生成了相应的查询指令,并将其对应的根因元素作为标签,构建了 335 个根因定位问题。
基线方法
为了评估当前 LLM 解决 OpenRCA 问题的能力,研究者构建了三种基线方法,其中两个是基于采样的 Prompting 方法,一个是基于简单的 ReAct 的 Agentic 方法。
Sampling-based Prompting
运维可观测数据规模庞大,而 LLM 的上下文窗口有限,因此直接输入全部数据并不现实。在传统根因分析中,常见的处理方式是采样。
研究者将所有数据(包括追踪、日志和指标)按每分钟一个值进行下采样,并对具体的指标类型进一步抽样以减少 KPI 序列的数量。
研究者采用了两种策略来执行这种抽样:
该方法简单实用,确保 KPI 类型的分布均衡。为保证可重复性,研究者对每种配置测试三次,并报告中位数结果。
即使用在基准构建中已经被工程师验证能够有效定位根因的 KPI 集合作为固定的输入。虽然这种方法在在实际场景中并不现实,但能体现采样的能力上限。
RCA-agent
尽管采样可缓解长上下文的问题,但运维数据中仍包含大量非自然语言(如 GUID、错误码等),LLM 处理此类信息的能力有限。
为此,研究者设计了 RCA-agent,一个基于 Python 的代码生成与执行反馈的轻量 Agent 框架,
允许模型使用数据检索和分析工具以提升模型对复杂数据的理解与操作能力。RCA-agent 由两部分组成:
每个步骤都会要求 Executor 完成单一原子化的任务,并根据返回结果来决策下一步。
所有代码与变量均缓存于内存中,直至整个任务完成。

主要实验
为了评测当前大模型解决 OpenRCA 问题的能力,研究者挑选了六个至少具有 128k token 上下文长度的模型,
如 Claude 3.5 sonnet, GPT-4o, Gemini 1.5 pro 等。结果显示:
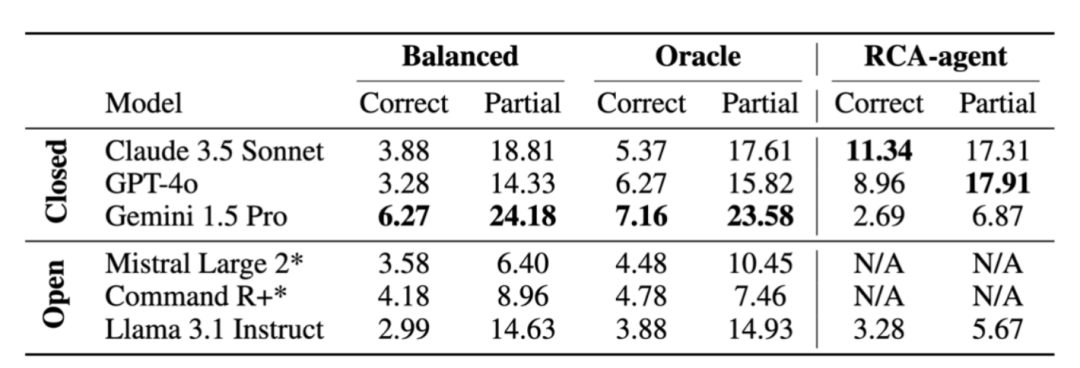
表 1 基线方法的准确率对
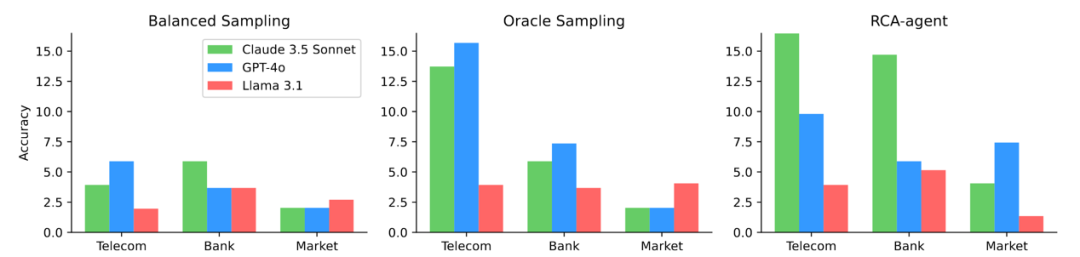
图 2 模型在各个系统上的准确率分布
通过进一步分析,研究者观察到当前模型倾向于使用更短的交互(6-10 步)来解决问题。然而,交互次数更多的情况下,问题的正确率通常更高。
其次,研究者发现模型的代码生成和代码纠错能力会大幅影响其在 RCA-agent 上的表现。
在仅考虑那些执行轨迹中出现过代码运行失败情况的例子中,Claude 3.5 sonnet 的正确率仅下降了 17.9% (11.34->9.31)。
而 Gemini 1.5 pro 则下降了 68.4% (2.69->0.85)。
这些发现可能的启发是,在以基于代码执行的智能体方法解决 OpenRCA 问题时,需尽可能使用代码能力更强的模型进行更长链条的交互和思考。
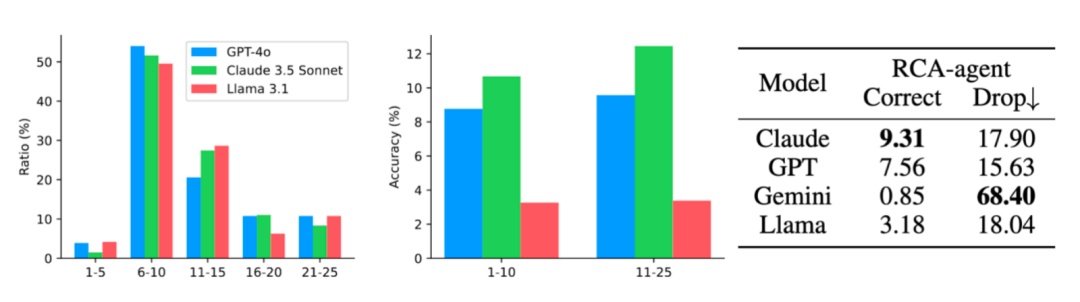
图 3:交互链条长度的分布;图 4:正确率随交互链条长度的分布;表 2:模型代码执行有错时的正确率
使用指南
OpenRCA 数据、文档、以及相关代码已开源在仓库中:https://github.com/microsoft/OpenRCA
要使用 OpenRCA 数据,需要首先将原始数据下载到本地。
每个子数据集下都有若干个以日期命名的运维数据目录,
以及一份原始数据记录 (record.csv) 和问题清单 (query.csv) 使用者需要让他们的方法能够访问对应的运维数据目录,来解决问题清单上的问题。
最后,使用者可以利用仓库中的评估脚本 (evaluate.py) 来评估其方法的结果正确性。
如果使用者希望公开他们的评估结果在 OpenRCA 的评测榜单上(https://aka.ms/openrca),
可以把他们方法的名称、原始结果文件、跑分、执行轨迹(如果有)、仓库连接(如果开源)发送到 openrcanon@gmail.com。
我们将在确认结果可信度之后尽快将结果更新在排行榜上。
结语
大模型在软件工程领域的研究仍然是一片蓝海。
本文聚焦于提供一个任务定义清晰且数据开放的代理任务数据集,来允许各种不同的大模型 RCA 方法使做公平对比。
本文的评测也仅局限于大模型本身的 RCA 能力上。
在实际应用中,还有许多可以进一步工程优化的点,如配置定制化工具来避免模型完全自由推理和编码产生的幻觉问题。
希望这篇论文能抛砖引玉,激发更多软件工程任务上的大模型研究的产生。
文章来自于微信公众号 “机器之心”,作者 :徐俊杰龙



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
