# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
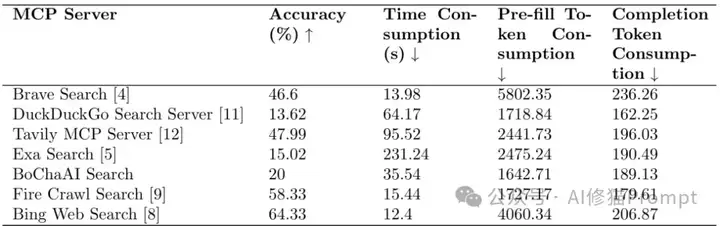
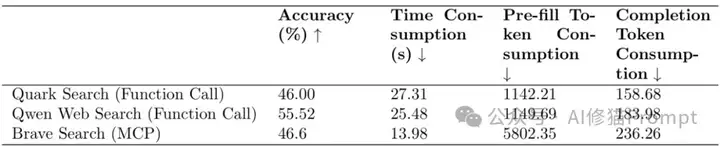
你是否正在投入大量资源开发基于MCP的Agent,却从未质疑过一个基本假设:MCP真的比传统函数调用更有优势吗? 2025年4月的这项开创性研究直接挑战了这一广泛接受的观点,其执行摘要明确指出:"使用MCPs并不显示出比函数调用有明显改进"。令人震惊的是,研究发现Qwen Web Search函数调用的准确率达到55.52%,实际上超过了包括Exa Search、DuckDuckGo、Tavily和Brave Search在内的多个MCP服务器!同时,不同MCP服务器之间的性能差异高达50%以上,从Bing Web Search的64%准确率到DuckDuckGo的仅13.62%。这项发布于GitHub的MCPBench评估框架,首次系统性地将MCP任务分为"数据获取"和"世界改变"两大类,并重点评估了前者。研究者在MySQL 9.2和PostgreSQL 15.8环境中进行了严谨测试,发现了提升MCP性能的关键:将复杂的参数构建(如SQL语句)从LLM移至服务端的声明式接口,在PostgreSQL实验中提升了惊人的22个百分点!无论你是正在选择MCP服务还是思考如何优化现有架构,这篇对既有假设的挑战不仅提供了全面的性能数据,还通过详实的案例研究(涵盖Frames、中文新闻、SQL_EVAL等多个数据集和多种服务实现)揭示了背后的设计原则。未来已来,一起来!

Model Context Protocol(MCP)作为一个开放协议,使AI模型能够通过标准化服务器实现安全地与本地和远程资源交互。在近几个月,已有数千个MCP被提出,同时OpenAI和阿里云等多个模型平台宣布在其LLM产品中支持MCP。你可能已经注意到MCP协议正在迅速普及,但作为开发Agent产品的工程师,你是否曾思考过不同MCP服务器的实际表现如何?它们在效率和效果上是否存在显著差异?更重要的是,MCP是否真的比传统的函数调用方式有明显优势?

研究者设计了一个名为MCPBench的评估框架,用于测试各种MCP服务器在准确性、时间消耗和令牌使用量方面的表现。
项目地址:https://github.com/modelscope/MCPBench
这一评估聚焦于两个关键任务:
(从互联网获取信息回答问题)
(从数据库中查询数据)
研究者确保所有MCP服务器都在相同的环境中使用相同的LLM和提示,以确保评估的公平性和可靠性。
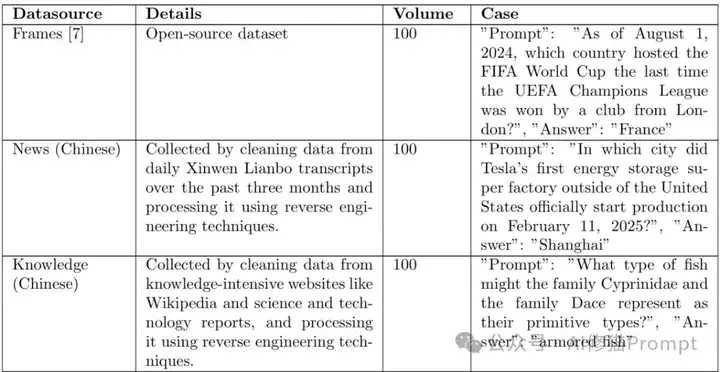
研究中的Web搜索任务要求LLM将问题重写为关键词或简短句子,然后使用工具搜索互联网并返回结果。为消除数据集偏差,研究者引入了多种数据源,包括中文和英文语言的各个领域,如下表所示的从Frames开源数据集(100条)、中文新闻(100条)和中文知识领域(100条)收集的数据。而数据库搜索任务则要求LLM通过数据库MCP服务器从数据库中检索数据,使用的数据源包括合成的汽车制造商数据源(355条)和基于Spider架构的SQL_EVAL数据集(256条)。
研究者从GitHub和Smithary.AI收集了多种MCP服务器,并选择了那些在2025年4月有较多调用记录的服务器进行评估。
这些服务器都提供Web搜索功能但使用不同的搜索引擎和数据处理方法。
它们提供与数据库交互的不同方式和接口。
研究采用了多维度的评估标准:
此外,实验在新加坡的双核CPU、2GB RAM服务器上执行,所有MCP服务器(除DuckDuckGo外)都以SSE模式在服务器上启动,超时设置为30秒,这确保了评估结果的一致性和可比性。
研究结果显示,不同MCP服务器在效果和效率方面存在显著差异,如下表所示:
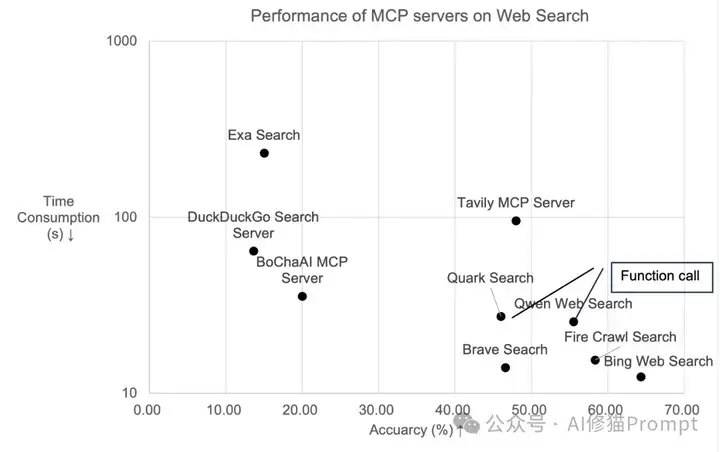
研究者将MCP服务器与函数调用的性能进行了比较,结果令人意外,如下图和下表所示:
这表明MCP并不一定在各方面都优于传统的函数调用方式。
研究者探索了如何提高MCP服务器性能,关注点放在数据库搜索任务上。他们发现:
为深入了解不同Web搜索服务的性能差异,研究者使用Frames数据集评估了Brave Search、BochaAI和Qwen Web Search的搜索性能:
如下图所示,提供了前十个相关的wiki百科页面,包括标题、描述和URL,但缺乏详细描述使LLM难以有效地将问题与相关搜索结果联系起来。
如图4所示,总结了搜索结果并明确告知LLM正确答案是"Crimson Tide",这种直接方法使LLM能够准确无误地提供正确答案。

尝试分析和总结搜索结果,但产生了不正确的结果,且没有向LLM展示原始搜索结果,大大阻碍了LLM推导正确答案的能力。

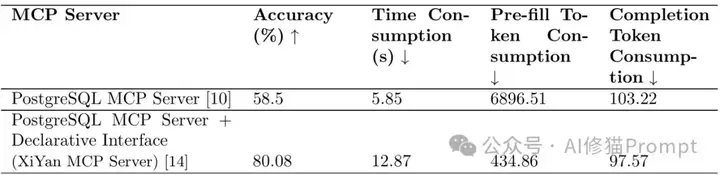
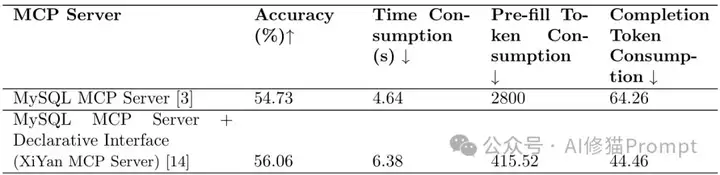
研究者使用SQL_EVAL数据集评估了PostgreSQL MCP Server和XiYan MCP Server在数据库搜索任务上的性能差异:
如下图所示,通过接收LLM生成的SQL查询语句,执行查询并返回结果,实际上只处理数据库连接和执行SQL查询。

如下图所示,设计为直接接受原始问题作为输入,在服务器内部完成SQL生成和执行过程,输出为数据库查询结果,然后由LLM推导最终答案。这种声明式接口方法显著提高了性能,特别是在复杂查询场景中。

研究结果清晰地表明以下关键发现:
对你作为开发Agent产品的工程师而言,这一研究提供了宝贵的指导原则:
通过这些优化,你可以显著提升Agent产品的性能和可靠性。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
