# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

蛋白质是分子尺度上生命体的功能单元,负责从催化生化反应到识别外来病原体等各种活动。
蛋白质的三维结构与功能活性,均可以通过 20 种氨基酸结构单元排列组合所形成的序列来描述。
蛋白质设计的挑战在于如何设计新的氨基酸序列,使其能够执行进化过程中未曾出现的功能,例如疾病的治疗方法或超稳定的工业酶。
这个设计空间大得惊人——假设将研究范围限制在 100 个氨基酸组成的短小蛋白质,研究者所需要筛选的序列条数将超过宇宙中原子的数量。
很明显,科学家需要考虑另一种策略——生成式蛋白质语言模型 (PLM)。
近期,声称要用「AI 书写生物学」的生物计算公司 ProFluent 推出了 ProGen3 系列稀疏生成式 PLM,
并提出了计算优化的缩放定律,用于扩展到 46B 的参数模型(基于 1.5T 氨基酸标记进行预训练)。
ProGen3 的预训练数据取自 Profluent Protein Atlas v1 的优化数据分布,该数据集包含 34 亿个全长蛋白质。
并且,研究人员首次在湿实验室中评估模型规模对 PLM 生成的序列的影响,他们发现更大的模型可以为更广泛的蛋白质家族生成可行的蛋白质。
「这并非纯粹的学术探索。我们最终会根据为社会创造实际价值的能力来评估 Profluent 的成果。
扩展蛋白质语言模型实现了从生成溶菌酶等模型酶到设计像 OpenCRISPR 这样复杂、功能强大的基因组编辑器的能力飞跃。」ProFluent 团队表示。
该研究以「Scaling unlocks broader generation and deeper functional understanding of proteins」为题,于 2025 年 4 月 16 日发布在 BioRxiv 预印平台。

论文链接:https://www.biorxiv.org/content/10.1101/2025.04.15.649055v1
准确地说,ProGen3 是一套用于蛋白质设计的前沿生成语言模型。它不仅允许用户生成新的全长蛋白质,还能重新设计现有蛋白质的特定结构域以增强其功能。
它利用稀疏架构实现了 4 倍加速,且不牺牲建模性能。
为了训练 ProGen3,研究人员构建了 Profluent Protein Atlas v1 (PPA-1),这是一个精心挑选的资源,
包含 34 亿个全长蛋白质和 1.1 万亿个氨基酸标记,是目前为止最全面的高质量蛋白质数据集。
他们优化了 PPA-1 以用于训练语言模型,并利用它将 ProGen3 最佳扩展至基于 1.5 万亿个标记训练的 460 亿个参数模型。
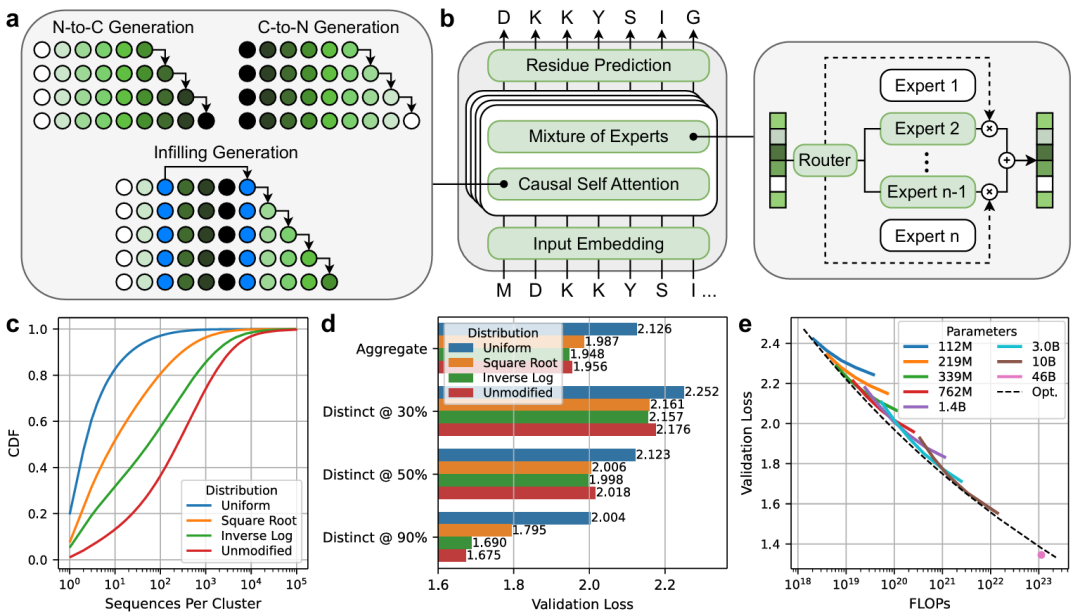
图示:确定最佳数据分布和缩放定律来训练稀疏生成 PLM ProGen3。(来源:论文)
接下来,研究团队探究了 ProGen3 模型的规模如何影响其生成真实蛋白质的能力。
ProGen3-46B 产生的多样性比 ProGen3-3B 高 59%,比 ProGen3-339M 高 198%(以 30% ID 下独特的世代数衡量)。
这表明,随着模型规模的扩大,它们能够更真实地呈现更广泛的生命多样性背后的生物学原理。
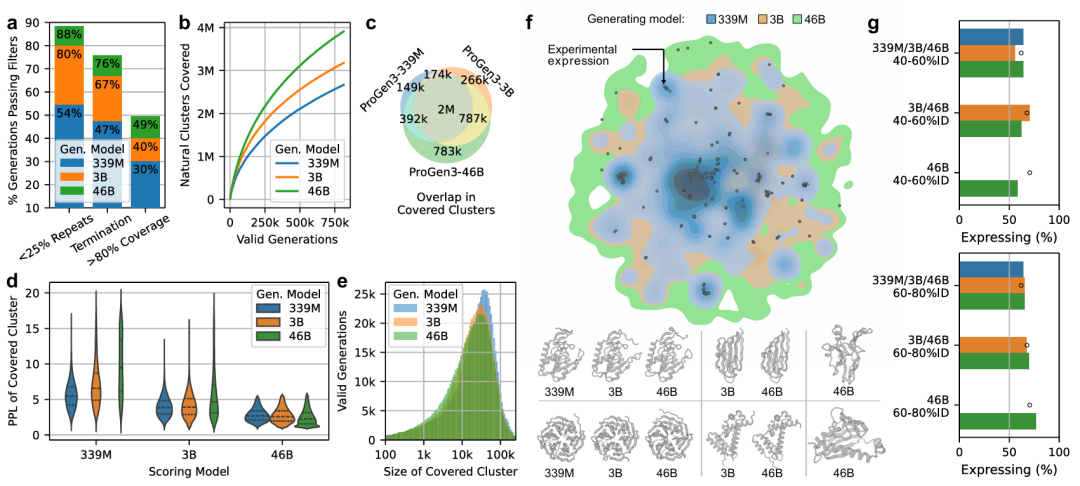
图示:与较小的模型相比,较大的模型可以为更加多样化的家族产生真实可用的蛋白质。(来源:论文)
研究人员使用有限的实验室数据来比对 ProGen3 的活性、表达、稳定性和结合亲和力等特性,证明比对可以优化任何规模的模型。
当然,规模更大的模型获益最大,比对后 ProGen3-46B 与实验测量的蛋白质适应度的相关性从 33.1% 提高到 67.3%。
为了进一步验证 ProGen3 在现实应用中的强大实力,研究人员设计了一系列挑战任务测试 ProGen3。
在过去的二十年里,抗体已成为治疗多种疾病的关键药物。
然而,治疗性抗体的发现、工程化和优化是一个耗时且昂贵的过程,通常需要动物免疫和/或多轮实验筛选。
研究人员想测试他们的蛋白质设计平台,看看它能否一次性生成在多个属性上与已获批准疗法相媲美的抗体。
于是,该团队选择了20个不同的靶点,这些靶点的已获批准药物已累计治疗了 700 万患者,并产生了 6600 亿美元的销售额。
对于每个目标,该模型生成的抗体通过计算预测可以与已批准的治疗方法精确结合相同的表位,但构成不同的物质成分。
这些设计与任何已知的针对相同靶点的结合剂的同源性中位数最多为 80%,并且所有设计的每个互补决定区 (CDR) 环都存在氨基酸差异。
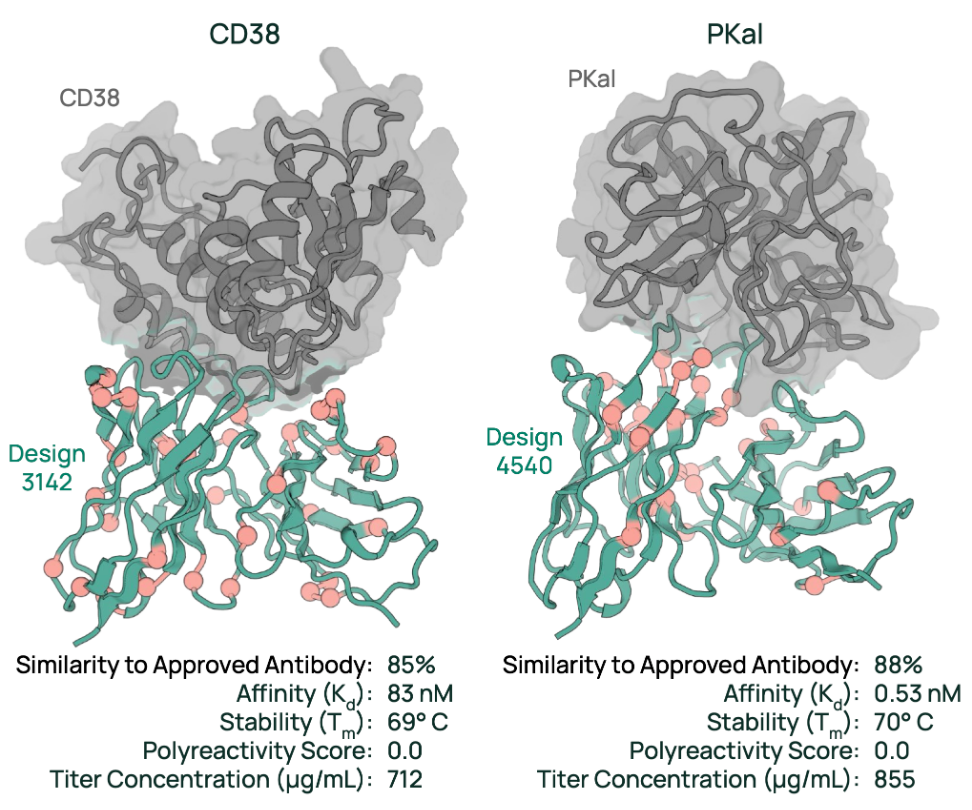
图示:针对 CD38 和 PKal 靶点的抗体设计。(来源:论文)
除了计算评估之外,研究人员还通过湿实验测试了针对 CD38 和 PKal 靶点的抗体设计,涵盖了从结合到可开发性等多种属性。
该团队的许多设计不仅达到了针对相同表位的高度优化疗法的亲和力水平,而且还显示出显著提升的可开发性。
相比之下,传统方法往往会因为优化一个属性而牺牲掉另一个属性。
设计的抗体与其治疗性对应物在整个可变区 [包括互补决定区 (CDR)] 上均存在差异。具体来说,即使 CDR 环中的一个突变也可能完全破坏结合。
由于这种敏感性,目前的主要方法仅限于非 CDR 突变,并力求与母体序列仅存在几个突变(同一性 >98%)。
这些结果表明 ProGen3 能够针对各种潜在药物靶点设计高质量的抗体候选物,并且拥有探索序列和适应度景观的强大能力,
甚至触及了抗体结合界面等高度敏感的相互作用。
挑战二:紧凑型基因编辑器
基因组编辑技术有望改变医学和农业,其主要途径是重新利用 CRISPR 等天然防御系统。
这些系统的简单性和稳健性使其得到了广泛的应用,但在具体的应用领域仍存在许多挑战,
例如,来自化脓性链球菌的 Cas9 核酸酶由 1,368 个残基组成,需要 100 个核苷酸的引导 RNA,这已经接近单个 AAV 递送系统的包装极限。
鉴于这些问题,研究人员设计了大量可编程基因编辑器,它们高度紧凑,仅含有 592 个残基,并在湿实验室中展示了功能性能。
传统 CRISPR-Cas 系统无法做到这一点,但是该团队将这些紧凑蛋白与其他效应子和组织特异性启动子结合起来,用单个 AAV 靶向之前无法靶向的靶点。
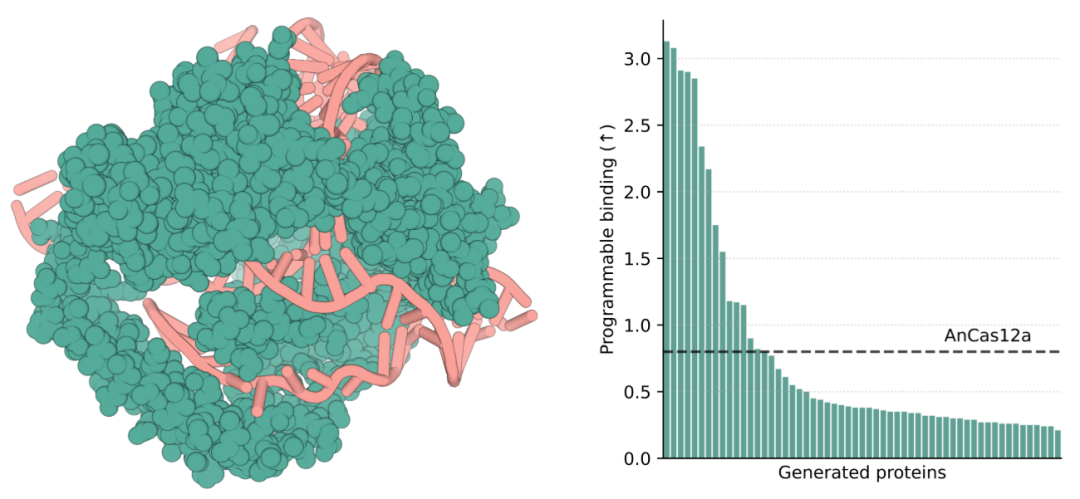
图示:生成可用于基因编辑应用的超紧凑蛋白质。(来源:论文)
总体而言,研究人员证明了,规模更大的生成式PLM是处理各种实际蛋白质设计任务的更实用的工具。
持续的模型扩展可以利用呈指数级增长的蛋白质序列数据量,同时采用更复杂的稀疏性实现来保持高效。
「我们的结果表明,ProGen3-46B 已具备推进定制蛋白质设计愿景的条件,可用于药物发现、酶工程和工业生产流程优化等领域。」研究人员表示。
相关内容:
https://www.profluent.bio/showcase/progen3
https://x.com/_judewells/status/1912743353608741260
文章来自于 微信公众号“ScienceAl”,作者 :萝卜皮



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
