# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
上一篇文章聊了聊 Tool、MCP 和 Agent 三者之间的关系。简单来说就是 Agent = LLM + Tools,而 MCP 统一了 Tools 开发和使用的过程。
文章很受欢迎,很多朋友也跟我进行了交流讨论。但在沟通中,我发现还是有部分朋友对 Agent 存在质疑和误解:
这种认知混乱的现状,一方面源于 Anthropic、Google、OpenAI 等头部公司尚未就 Agent 精确定义达成共识,仍在「各说各话」;
另一方面,媒体的过度炒作与选择性解读,也使得 Agent 这个词被严重稀释和泛化,几乎失去了技术内涵。
那么,到底什么是 Agent?它与我们熟知的 LLM、Tools、Workflow 又是什么关系?它的出现将为 AI 的发展带来哪些深刻变革?
今天,我将结合 302.AI 的一线实践经验,帮大家厘清 Agent 本质,并分享我对未来发展格局的判断。
目录
1. Agent = LLM + Tools,在喧嚣中寻找共识
2. LLM:模型是没有记忆的
3. Tools:从问答到循环的进化
4. Agent 框架:三种循环类型
5. 判断一:单 Agent 框架存在极限,多 Agent 系统仍是目前的主流
6. 判断二:从对话问答到任务委托,AI 使用方式发生巨变
7. 判断三:闭源 VS 开源,共同撑起一个巨大 Agent 生态
8. 总结
2025 年,公认的 Agent 之年。随之而来的,是这个词的泛滥成灾。文章、播客、访谈、演讲、闭门会、白皮书…… 人人都在谈论 Agent,大家却越听越迷糊。
知名科技媒体 TechCrunch 甚至撰文吐槽 No one knows what the hell an AI agent is(没人知道 TMD 到底什么是 Agent)。
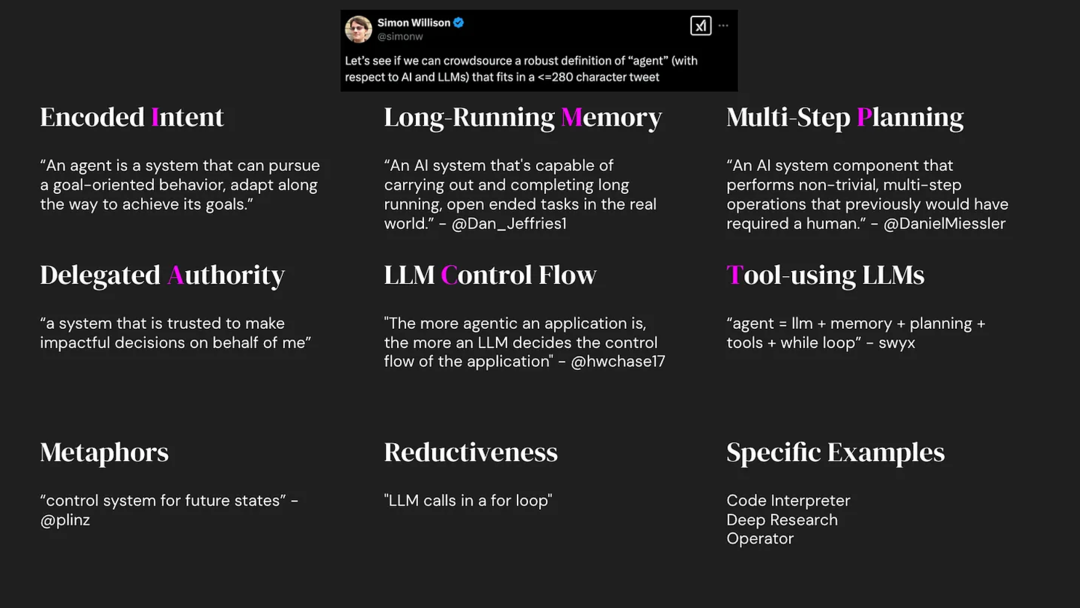
尝试给 Agent 一个定义
知名科技博主 Simon Willison 曾在 X 发起了一个挑战:用 280 字给 Agent 下一个通用的定义。
这个月,Latent Space 主理人 Swyx 在 2025 AI Engineer Summit 上重提此事,展示了评论区里五花八门的答案(如上图所示)
——满屏的定义,恰恰就是当前认知混乱的缩影。
几个月过去了,即便行业巨头纷纷下场,也没能完全统一口径。混乱仍在继续。让我们看几家代表性的观点:
Anthropic《Building effective agents》
At Anthropic, we categorize all these variations as agentic systems, but draw an important architectural distinction between workflows and agents:
Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
(2024.10)
OpenAI 《A practical guide to building agents》
Agents are systems that independently accomplish tasks on your behalf. (2025.4)
Google《Agents》
A Generative AI agent can be defined as an application that attempts to achieve a goal by observing the world and acting upon it using the tools that it has at its
disposal. (2024.12)
Lilian Weng《LLM Powered Autonomous Agents》
In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components: Planning, Memory, Tool use.
(2023.6)
每家都用一个长长的文档来说明 Agent 是什么。但没几个人真的会认真看完。
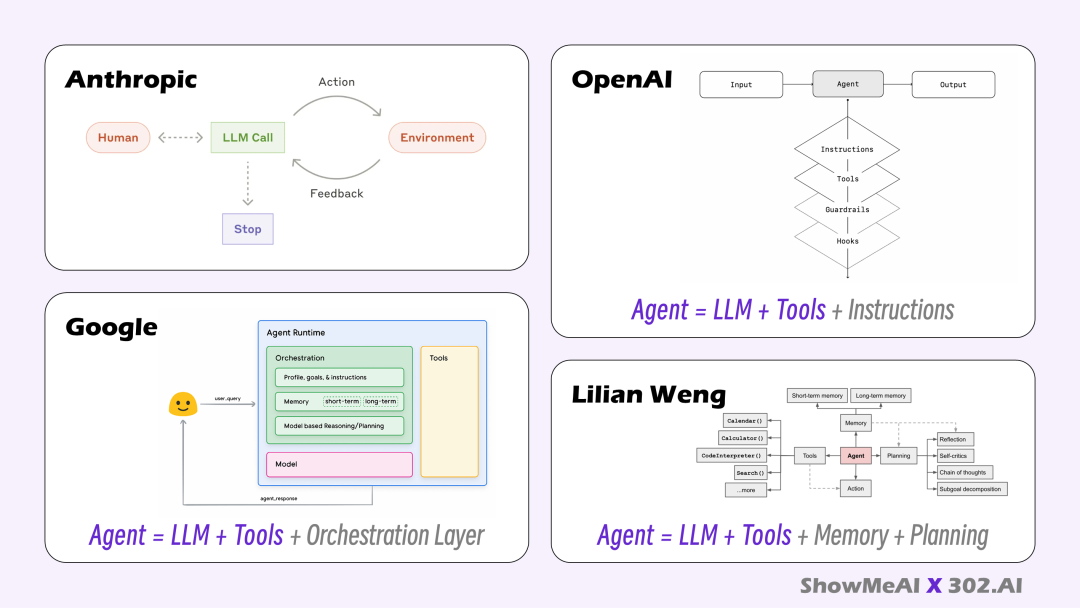
巨头的 Agent 定义示意图与公式总结(我看完了)
其实没那么复杂,我们可以抓取一个最精简、也是最核心的公式:Agent = LLM + Tools
这足以揭示了 AI Agent 核心机制:LLM 负责思考和调用,Tools 负责执行和与返回结果。理解了这一点,你就已经掌握了走进 Agent 世界的钥匙。
为了更好的理解下面的段落,我们还需要提一提大语言模型(LLM)的一个基础特性。
模型为什么无法替代 Agent 呢?因为模型(LLM)本身是没有记忆的,专业术语叫 stateless(无状态的)。
这是一个极其重要但容易被忽略的事实。通俗来讲,无论你之前与一个 LLM 对话了多少轮,它本身并不会「记住」任何历史信息。
每次交互,它处理的都只是你当前输入的内容。模型本身的状态,不会因为过去的输入输出而改变。
那么,为什么我们常常感觉 AI「记住」了自己之前说过的话,能够进行连贯的多轮对话呢?
这其实是一种模拟的记忆。应用程序(比如 ChatGPT 等)每次向模型发送新请求时,会主动将之前的对话历史作为上下文(Context)一并打包发送给模型。
模型依据这个临时的、外部提供的「记忆」来进行回应,从而让人产生了连贯对话的「错觉」。
这种外部存储的「记忆」,可以存在你设备本地,也可以存在云端服务器,总之它不在模型内部。
这种设计将模型计算与会话状态管理解耦(decouple),使得同一个模型可以同时服务于大量不同的用户和会话,不会互相干扰。
我们可以把模型(LLM)想象成网吧里的电脑:每次用完电脑后重启(一次对话请求处理完成后,LLM 内部恢复初始状态),如此循环。
预训练数据就像是它预装的操作系统。
说明:将记忆数据通过微调(Fine-tuning)融入模型权重,形成私有模型是另一回事,暂且不讨论。

把 LLM 完成对话,类比成电脑重启
正是因为 LLM 无状态、擅长处理单次输入输出的特性,非常适合做一问一答,所以其最初、最自然的应用形态便是对话机器人(Chatbot)。
Chatbot 交互模式基本就是「人 - AI - 人 - AI - ....」的交替循环。在这个过程中,人类不断通过提问、追问、澄清来引导 AI,使其输出逐渐符合预期。
这个阶段被称为 Human in the Loop(人在循环中)。
无论是单轮问答,还是通过程序传入历史上下文多轮对话,本质上都没有脱离这种模式。

Human in the Loop(人在循环中)
随着 LLM 能力的提升,人们逐渐发现,AI 的回答越来越靠谱了,很多环节已经不再需要人类的干预。
于是,一个革命性的想法诞生了:能否让 AI 自己与自己「对话」呢?换言之,能否让 AI 在执行任务的过程中自我驱动呢?
我们把这种「人 - AI - AI - AI - ....」的新逻辑,称之为 Human on the loop(人在循环外)。人类只需设定一个初始目标,后续所有步骤都由 AI 自主循环完成。
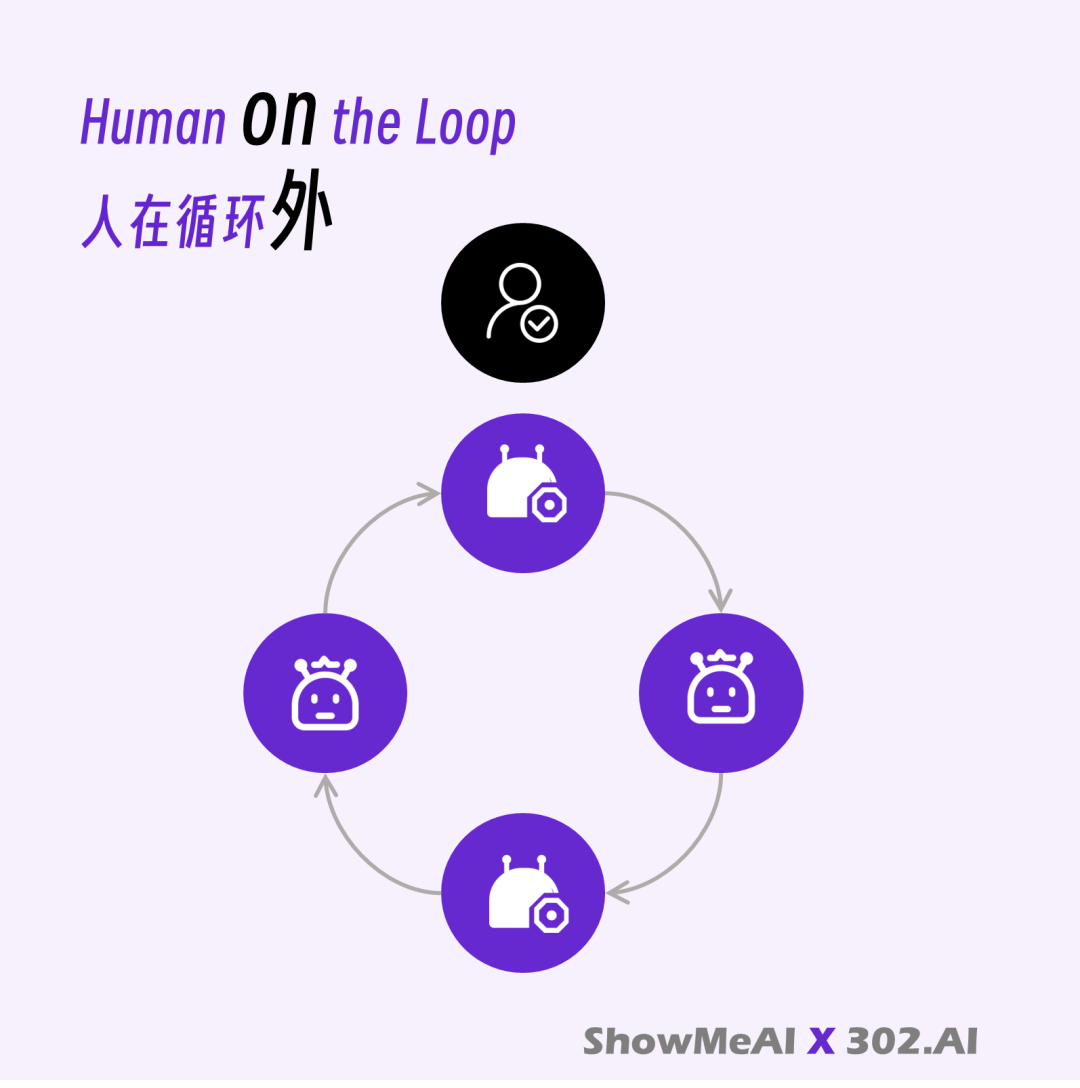
Human on the loop(人在循环外)
这正是 Agent 重要本质之一:自我循环。
实现这种了「自我循环」,LLM 才有了调用工具的能力。比如,我们最熟悉的 Function Call(函数调用),就是一个典型的 LLM 自我循环过程:
人提出问题 → AI 提出调用工具来辅助回答 → 工具自动执行返回结果 → AI 接收到结果来判断是否继续循环。
这里需要特别指出一个常见的误区:大部分应用客户端把上述过程呈现在了同一个对话界面里,让用户误以为只有一次 AI 问答。
但实际上,每调用一次工具,AI 都需要回答两次。
这也是 LLM 无法取代 Agent 的根本原因:LLM 无法在一次回答中既调用工具,又获得工具调用的结果。
模型学会了自我循环,这时 AI 突然「意识」到:我这次可以不直接回答!我可以先请求调用某个工具,从模型外部获得信息后,交给下一个循环的自己;
然后在下一个循环里,再基于这些新信息来回答!
那么谁来控制循环过程呢?LLM 本身无法完成,这是就需要借助人类构建的外部代码,用来接收请求和传递信息。
这类代码就叫 Agent 框架,本质是控制 AI 自我循环和维护记忆。
我把当前的 Agent 框架分为三大类:
开发者预先设定好任务执行的每一步计划,明确规定哪个步骤使用哪个工具,LLM 主要负责在预设节点上填充内容或做简单决策。
我称之为工作流(Workflow),它是一个白盒系统。
Dify 和 Coze 就是典型的代表,能够提供可视化流程编排工具。此时 Tools 的执行步骤,在很多时候是被人强制执行的,以此换取更多的确定性。
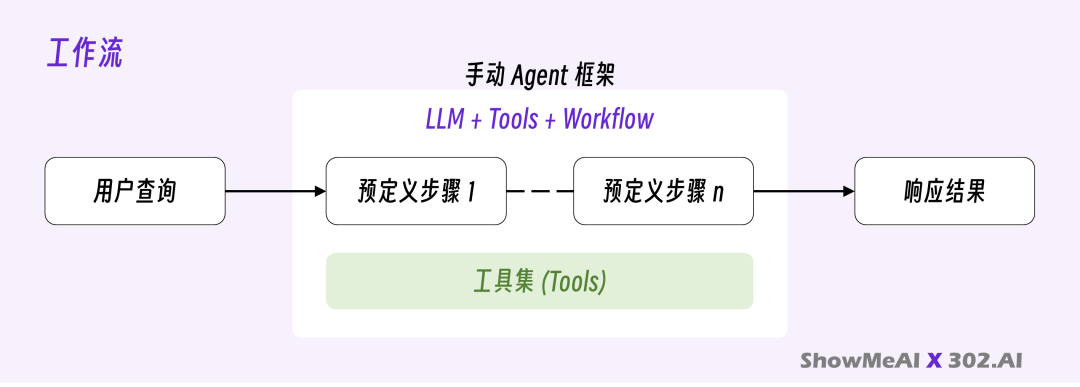
手动 Agent 框架 = LLM + Tools + Workflow
将 AI 预设为不同身份的垂直 Agent(系统提示词+特定工具),每个垂直 Agent 完成不同的子任务,
最后通过框架将每个子任务的执行过程和结果组合起来,完成最终目标。
我称之为 Multi-Agent System(多 Agent 系统),它是一个灰盒系统。
Manus 和扣子空间的规划模式就是典型的多 Agent 框架。规划和记忆管理都属于编排的一部分。
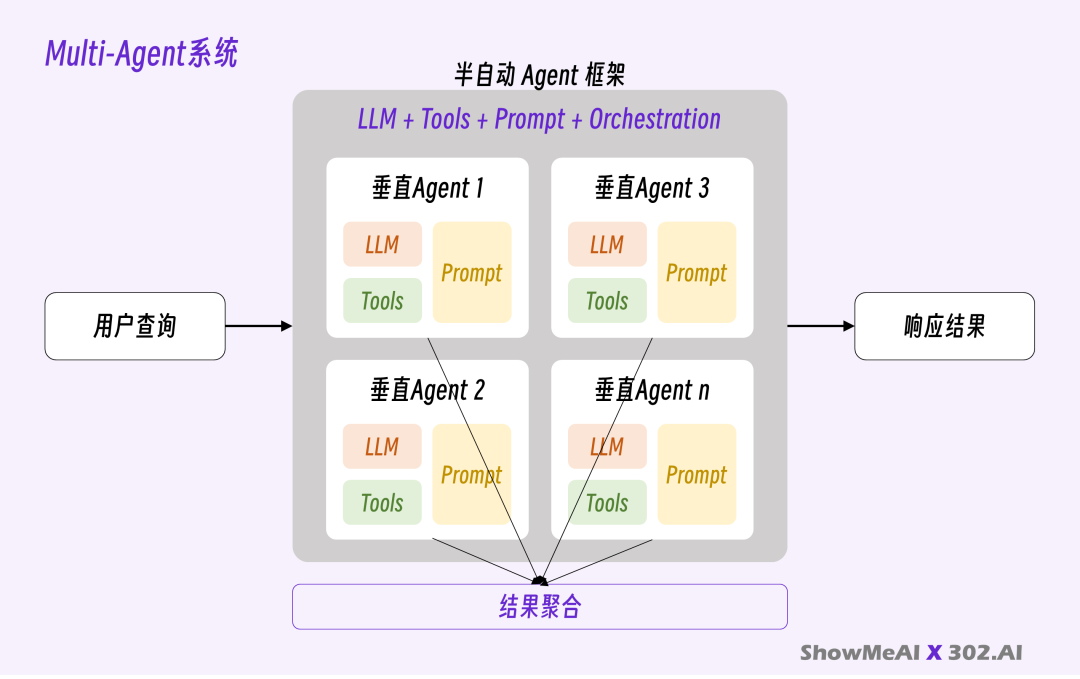
半自动 Agent 框架 = LLM + Tools + Prompt + Orchestration(编排)
只给模型设定一个最终目标,模型接收到目标就开始自我循环,直到完成目标或遇到无法解决的障碍。
全自动 Agent 框架是最简洁的,调用工具的那几行代码,就是其全部的核心了,复杂过程全部交由模型去解决。
我称之为 Single-Agent System(单 Agent 系统),也就是所谓的通用 Agent,它是一个黑盒系统。
模型自主完成工具调用这个操作,就是全自动 Agent 框架了,如果模型没有 Tool Use 功能,也可以通过代码来实现。
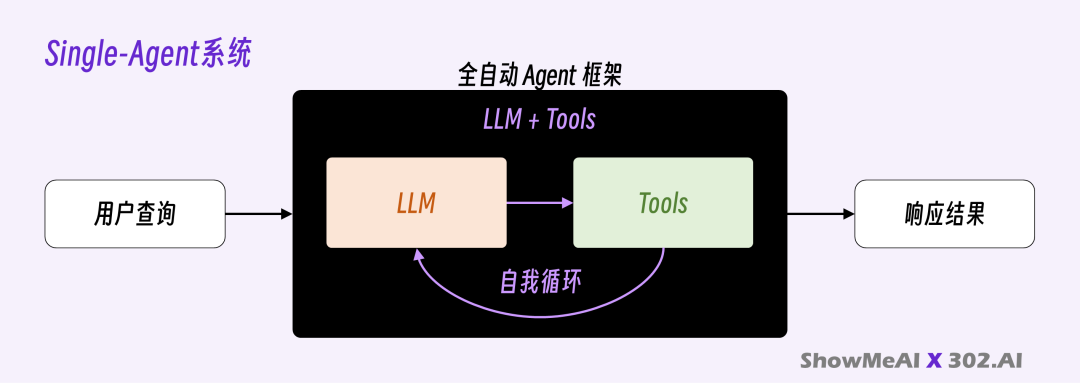
全自动 Agent 框架 = LLM + Tools
需要强调的是,这 3 种框架并不是对立关系,而是常常组合使用。
比如,Multi-Agent 系统可以与 Workflow 相结合,Single-Agent 系统也是 Workflow 和 Multi-Agent 系统的重要组成部分。
读到这里,你就可以丝滑接入 Anthropic 、Google、OpenAI 三巨头先后发布的 Agent 白皮书了(链接见文末,下同)!
并且,你开始在这个领域游刃有余。甚至在看到 Langchain 团队发长文吐槽 OpenAI 概念不清时,还会投去赞许的目光。
随着 OpenAI o3 和 o4-mini 等新模型的发布,我们观察到了模型 Agent 能力的明显提升——能够更熟练地使用更多工具、执行更长的步骤链来完成复杂任务。
这些进步的本质,是模型自我循环的次数增加了。
就像一个陀螺,过去可能转两下就歪倒,需要人不断去「抽打」;现在内置了更强劲的小马达,能够自主稳定旋转更长时间。

抽打陀螺保持旋转
这时,有一种声音出现了:模型要替代 Agent 了,或者 Model is Agent。
其实,这句话更严谨准确的技术表达是:Single-Agent 系统要替代 Workflow 和 Multi-Agent 系统了;或者说,通用 Agent 将一统天下。
但我认为,这只能是一个美好的愿景,短期内不可能实现。
LLM 的输出天然带有一定的随机性。对于一个需要多个步骤才能完成的复杂任务,
如果完全依赖模型本身的能力,那么每一步决策的微小偏差都可能被累积和放大,最终导致结果谬以千里。
还是用陀螺举例。一个陀螺的初始动力再强,在无人监管、不受控制的情况下,谁也不能保证它最终会停在期望的位置。
目前,主流 LLM 的训练和评估都围绕单轮次(或有限轮次)的问答任务展开,缺乏针对「长链条现实任务」的训练和评估。
这导致 LLM 在完成复杂任务方面存在先天不足。
我们极度缺乏 LLM Agent 训练所需要的高质量行动序列数据。
例如,训练「搜索」任务时,不能只看最终结果,还要评估模型获取信息、生成中间步骤、根据反馈调整计划、甚至回溯重试的能力。
我甚至怀疑,连 OpenAI 或者 Anthropic 这种大厂,也未必能拿到足够数量的这类数据。
因此,通往 AGI 的必经之路,是将 LLM 变为 Agent,在真实世界中去做持续的强化学习,最终才有可能超越人类。
LLM 训练也从此迈向 Agent 与环境直接、持续互动获取第一手经验为主导的新纪元(也就是Sutton 所说的 the Era of Experience)。
LangChain 团队曾进行过一项关于 Agent 的调查,发现影响其落地的最大瓶颈是「性能质量(Performance Quality)」,而性能质量瓶颈的来源就是大模型。
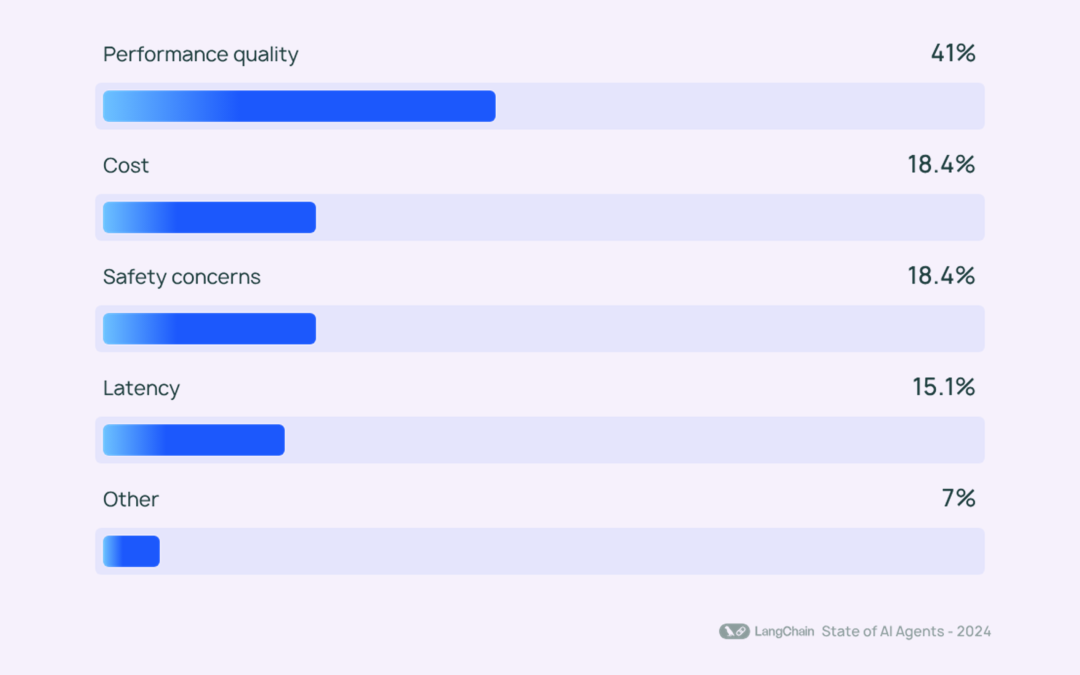
LangChain 关于 Agent 落地阻碍因素的调研结果
这里给一个明确的结论: 受限于当前 LLM 的可控性以及能力,指望一个全能的模型 + 简洁的单 Agent 系统包打天下,在短期内是不现实的。
Multi-Agent 系统将是未来相当长一段时间内构建复杂、可靠 Agent 应用的主流范式。
读到这里,你就可以丝滑接入几乎所有爆火的必读文章了!
比如,Shunyu Yao《The Second Half》,Richard Sutton 最新的论文《Welcome to the Era of Experience》以及大名鼎鼎的《The Bitter Lesson(苦涩的教训)》。
随着 Agent 时代的到来,一个显而易见的变化是:我们与 AI 的交互模式正在从「即时的回答问题」 转向「异步的完成任务」。
过去,我们问 AI 一个问题,期待它立刻给出答案。
现在及未来,我们交给 Agent 一个复杂任务,它可能需要几分钟甚至几小时来独立工作,并最终交付一个完整的结果。
这个转变,看似简单自然,却将带来一系列深远的影响。
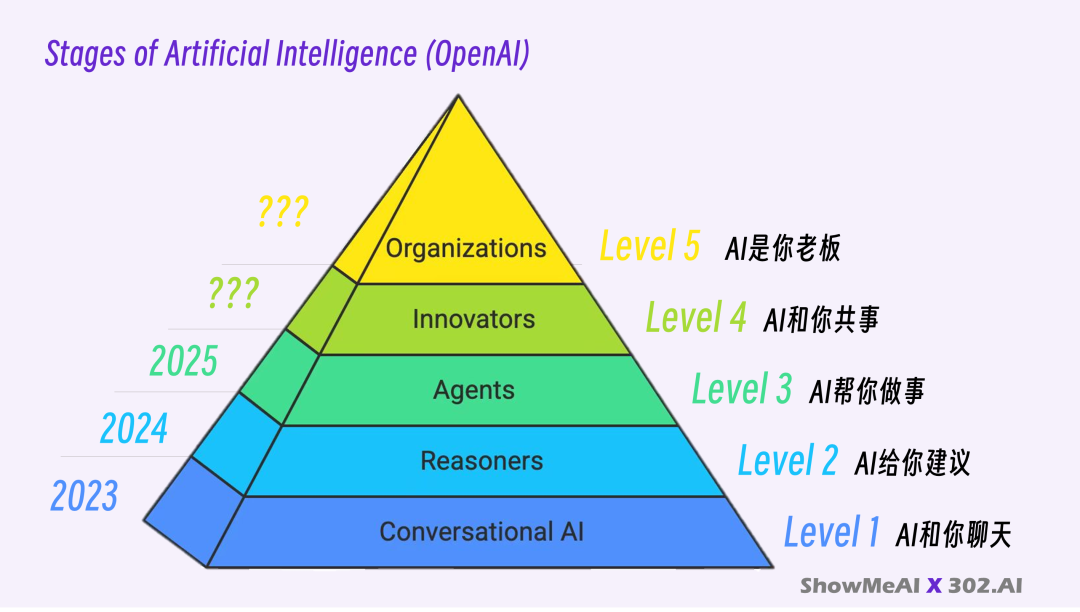
根据 OpenAI 之前公布的 AGI 路线图,我们现在已经发展到了 Agent 时代
过去人机对话模式下,Token 消耗速率受限于人类的输入和阅读速度(大约每秒 4 个 Token)。
现在 AI 实现自我循环后,Token 消耗速率取决于模型的推理和生成速度(可达每秒上百 Token 甚至更多),而且机器还可以 7x24 小时不间断工作,
因此 Token 消耗将指数级增加。这还会对模型服务的并发能力和推理速度,提出前所未有的巨大挑战。
当交互的核心从「过程」转向「结果」,当用户不再需要实时等待 AI 的每一步响应,当用户从「AI 创作者」变为「AI消费者」,产品形态又会如何发展呢?
如上文所说,复杂任务需要多 Agent 协作完成。这就意味着,市场需要大量专注于解决特定领域、特定类型问题的「垂直 Agent」。
而垂直 Agent 的开发以及它们之间的互联互通(比如我们上篇文章讨论过的 ANP 和 A2A),将开启下一个巨大的创业和创新浪潮。
读到这里,你就可以明白,近期百度云、阿里云、腾讯云、火山云动作频频,接入 MCP 再押注 Agent 生态的意义所在了:
他们都想做属于自己的垂直 Agent 开发平台。
Agent 生态的爆发,把用户的关注点从「用了哪个模型」拉向了「哪个 Agent 能最好地完成我的任务」。这不仅会重塑产品形态,更将深刻改变 AI 的商业模式。
我认为,未来 Agent 生态可能会闭源与开源并行的商业发展路径。
部分模型厂商将不再提供模型接口,而是直接提供 Agent 接口。
Alexander Doria 和 Naveen Rao(Databricks 副总裁)前段时间发表了相同的观点,并且给出了明确的时间周期:只需要 2-3 年,甚至更快。
传言已久的 GPT-5,或许就会以这种形态出现,把 LLM 和工具直接封装在一起。
在基础模型通用能力提升有限的情况下,通过对特定工具使用的训练,来提高最终完成任务的效果。
这样做还可以通过用户现实任务的反馈,不断地强化模型能力,形成数据飞轮。
如果你仔细观察,就不难注意到,OpenAI Deep Research 和 Anthropic Claude Code 这类 Agent 工具都没有提供 API 接口。顶尖模型厂商的意识是一致且一流的。
另一部分模型厂商(尤其是开源模型厂商,比如 DeepSeek 等)则将联合广大的开发者社区,共同构建一个开放、多元的 Agent 生态。
Agent 开发门槛一定会远低于传统软件,这使得更多普通人也能参与其中,融合自己的独特经验来开发出各种各样的 Agent,满足海量的长尾需求。

Agens 开源与闭源生态之争,开始了
一边是闭源巨头用数据飞轮形成规模化效应,一边是人民群众为开源社区贡献出自己的独特经验。这一定会是一个史无前例的巨大市场。
读到这里,你就可以丝滑接入 Alexander Doria 上个月爆火的长文《The Model is the Product》!我不完全同意文章的标题,但认可他背后的思考和判断路径。
让我们再次回到本文的核心:Agent = LLM + Tools
Agent 是一种新的 Scaling Law。
数千年人类发展史,我们个体智力的增长早已趋于平缓,但人类文明整体科技水平却在加速进步。
这背后关键的驱动力,正是人类学会了使用工具,学会了大规模协作。
很有可能,我们创造的硅基智慧,正在经历着一模一样的进化历程。
希望这篇文章,可以帮助你更好地理解 Agent 领域正在发生的深刻变革,并在即将到来的新时代里,更快地占据自己的一席之地。
文章来自于微信公众号 “ShowMeAI研究中心”,作者 :Jomy



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
