# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。
如何将这种深度推理模型扩展到智能体和具身领域,让机器人通过思考和推理来完成复杂具身交互等任务?
近期,来自浙江大学、中科院软件所和阿里巴巴的团队提出了 Embodied-Reasoner,
让机器人或智能体拥有深度思考和交互决策能力,从而在真实物理世界完成环境探索、隐藏物体搜索、交互和搬运等长序列复杂任务。
可以想象,未来某一天,机器人能够帮你在房间里找钥匙、信用卡等容易遗忘的小物件。它可以观察房间、分析和思考,然后一步一步地搜索,最后帮你找到它们。

尽管深度思维模型在数学和编码任务上展现出卓越的推理能力,但不同于数学、代码等文字模态上的推理,具身领域的推理有几个重要的挑战需要解决:
它们必须持续与环境交互,收集视觉反馈,并基于这些反馈做出合理的行动(文本模态)。
因此,模型每次需要处理多轮次的、图文交织的冗长输入,而后产生连贯、符合上下文的推理和决策。
包括多模态的感知、基于物理世界的常识推断、空间关系理解、时序的推理以及面对环境交互失败后的自我反思等能力,这些都对大模型提出了更高要求。
因此,如何设计合理的语义动作空间让「思考」和「行动」解耦也是一个难点。
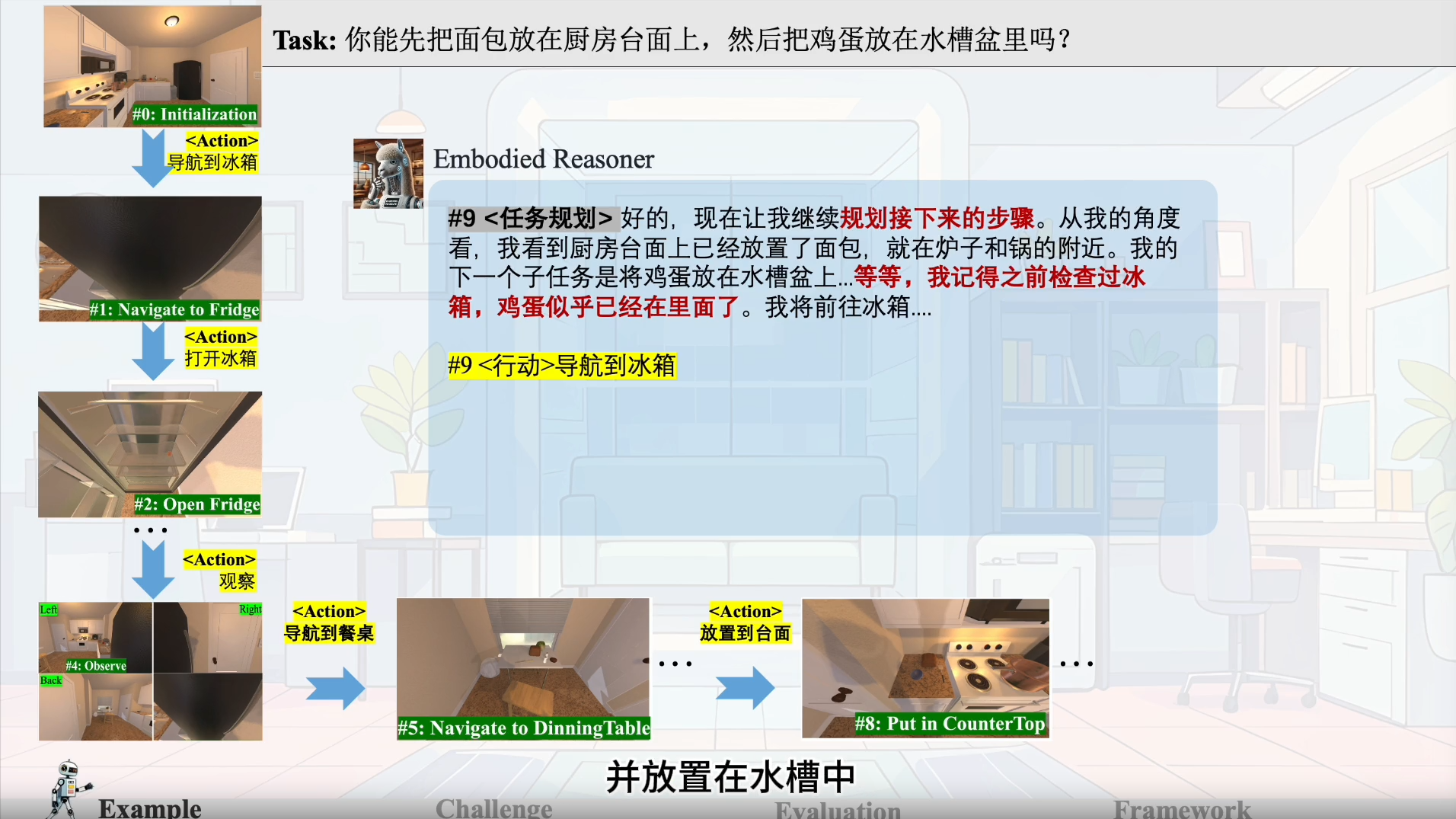
如刚才视频中展示的具体例子,当具身智能体在未知房间中搜索隐藏物体时,
它必须利用物理常识推断潜在的搜索区域(步骤 1、3),理解物体的空间关系以规划高效的探索路径(步骤 1、5),
并运用时序推理回忆先前尝试中的相关线索(步骤 9),同时反思先前的失败。这些多方面的推理要求对多模态模型提出了挑战。
实验发现,即使是像 OpenAI o3-mini 这样的先进 LLM,在这些具身交互任务中也经常难以展现可靠的推理和决策,容易出现重复的搜索或前后不一致的行为。
基于上述挑战,团队提出了 Embodied-Reasoner,将深度思考能力扩展到具身交互任务。其关键的两点包括:
因此,Embodied-Reasoner 设计了图文交织的思维链:观察-思考-行动,三者相互交织构成真正的多模态思维链。
这个设计类似于最近刚刚推出的 OpenAI 的 o3 和 o4-mini 模型,集成了图片编辑(缩放、裁剪等)等中间动作,也创造了图文交织的多模态思维链。
这些多样化的思考因子能够促进模型从不同角度进行推理和思考。
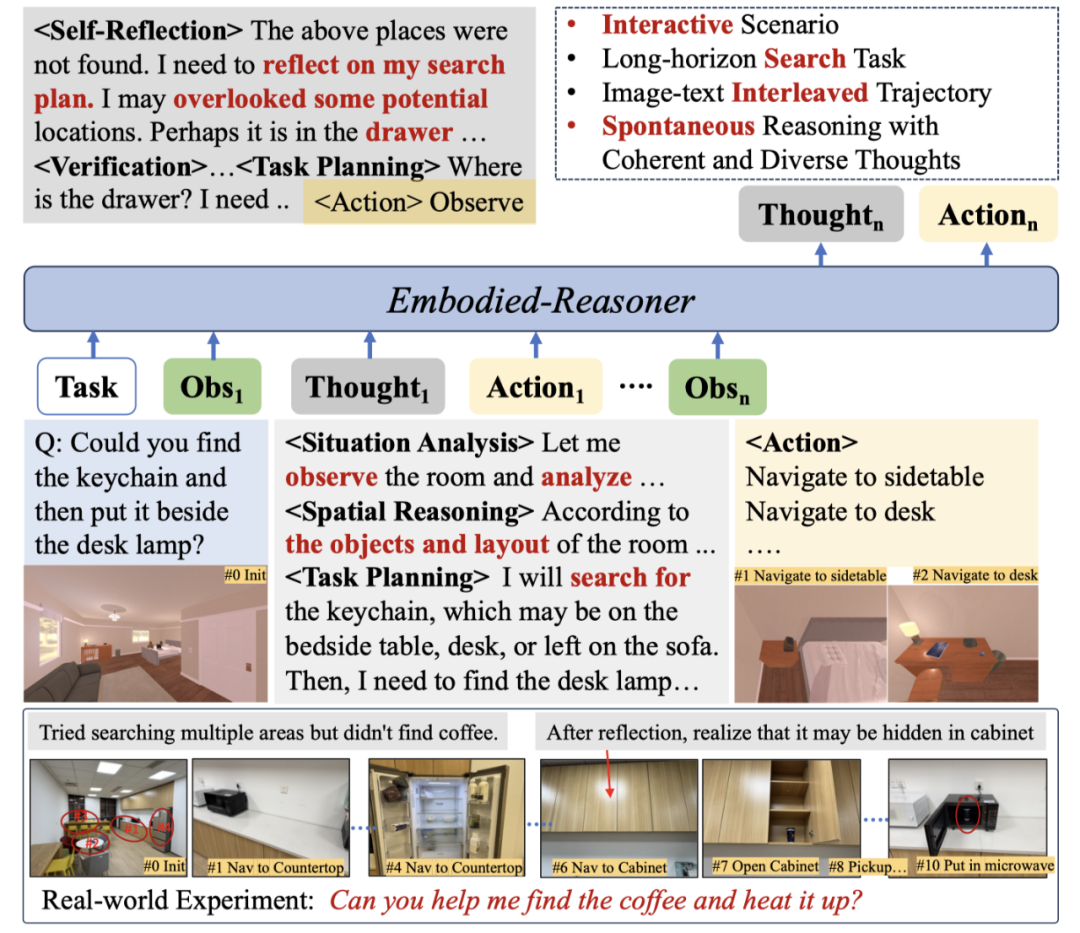
为了开发这种能力,如上图所示,我们构建了一个数据引擎,自动合成连贯的观察-思考-行动轨迹,引入了具身场景下多样化的思考过程,
例如情境分析、空间推理、自我反思、任务规划和自我验证。
这些连贯的、图像-文本交错的轨迹引导模型学习如何基于其交互历史和空间布局进行规划和推理,从而提升其空间和时间推理能力。
此后,我们引入了一个三阶段迭代训练流程,结合了模仿学习、自我探索和自我纠正微调。
该流程首先利用合成轨迹进行模仿学习以培养基本交互能力,然后通过拒绝采样微调增强探索能力,最后经反思调优培养自我纠正能力。
下面是一个具体的例子:

如上图所示,模型需要空间推理能力来理解厨房布局和物体关系,
基于常识知识推断潜在位置(冰箱、餐桌),系统地搜索未探索区域,并通过实时观察调整计划,同时避免重复搜索。
任务环境:使用广泛采用的 AI2-THOR 模拟器构建了具身任务环境,该模拟器提供物理模拟和实时视觉观测。
实验使用 120 个独特的室内场景(如厨房)以及 2,100 个可交互物体(如信用卡和微波炉)。
实验通过 AI2-THOR 的 API 控制机器人的移动(如向前移动)和交互(如拾取物体),同时在每一步返回视觉观察。
任务类别:机器人初始化在未知房间的一个角落,视野有限,即只能看到房间的一部分。本节设计了日常生活中四种常见的交互任务,复杂度依次增加:
动作定义:虽然 AI2-THOR 提供了许多低层级的动作,但本节的任务侧重于高级规划和推理,而非运动控制。
此外,低级动作可能导致过多交互,因此本节在原子动作基础上封装了 9 个高级动作:
观察、向前移动、导航至 {}、放入 {}、拾取 {}、切换 {}、关闭 {}、打开 {}、终止。
为了开发适用于具身场景的 o1 风格推理模型,本节首先设计了一个需要高级规划和推理,而非低级运动控制的具身任务,即搜索隐藏物体。
接着,基于模拟器设计了一个数据引擎,用于合成交互式推理语料库:任务指令和相应的关键动作序列。
每个动作产生一个视觉观察,形成交互轨迹。
最后,数据引擎为每个动作生成多种思考链,如情境分析、任务规划、空间推理、反思和验证,创建了一个具有观察-思考-行动上下文的交互式推理语料库。

多样化思考模式:首先,本节定义了五种思考模式,模拟人类在不同情况下的认知活动:
情境分析(Situation Analysis)、任务规划(Task Planning)、空间推理(Spatial Reasoning)、自我反思(Self-reflection)和双重验证(Double Verification)。
本章节使用简洁的提示来描述每种模式,指导 GPT-4o 合成相应的思考过程。

多轮对话格式:考虑到交互轨迹遵循交织的图像-文本格式(观察-思考-行动),Embodied-Reasoner 将其组织为多轮对话语料库。
在每个回合中,观察到的图像和模拟器的反馈作为用户输入,而思考和行动则作为助手输出。在训练过程中,我们仅对思考和行动 token 计算损失。
为了增强推理能力,Embodied-Reasoner 设计了三个训练阶段:
模仿学习、拒绝采样微调和反思调优,这些阶段将通用视觉语言模型逐步提升为具有深度思考能力的具身交互模型:
然后在此数据集上微调 Qwen2-VL-7B-Instruct,使其学会理解交织的图像-文本上下文,输出推理和动作 token。经过微调得到 Embodied-Interactor。
该阶段一共保留了 6,246 个成功轨迹进行微调,最后得到 Embodied-Explorer。
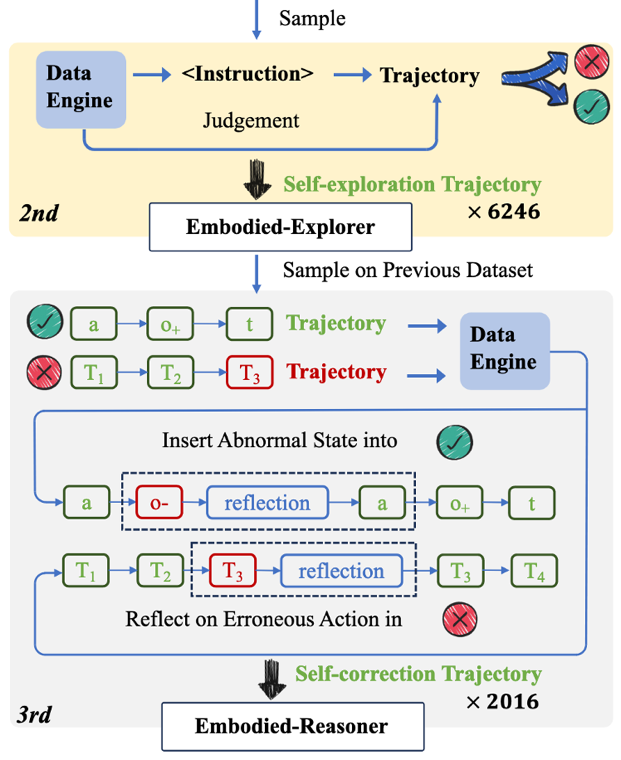
此外,机器人经常会遇到临时硬件故障,这要求模型能够对不合理行为进行自我反思,识别异常状态,并及时纠正。
如上图所示,第三阶段使用 Embodied-Explorer 在先前任务上采样大量轨迹。对于失败的轨迹,我们定位第一个错误动作并构建自我纠正轨迹。
对于成功的轨迹,我们插入异常状态来模拟硬件故障。这一步骤补充了 2,016 条反思轨迹(每条轨迹平均 8.6 步)。
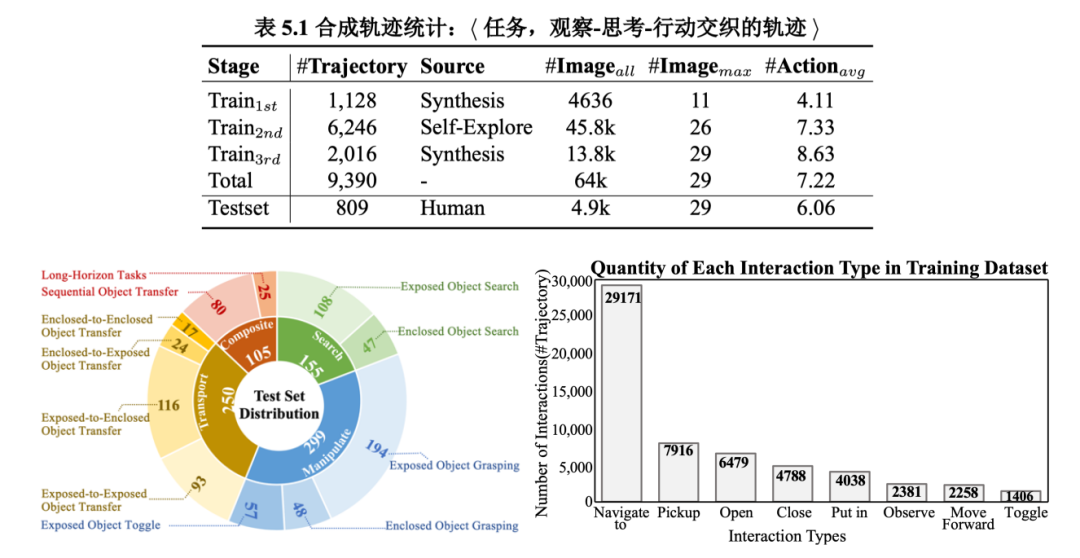
统计结果:我们为三个训练阶段合成了 9,390 个独特的任务指令及其观察-思考-行动轨迹,即〈场景, 指令, 交织的多模态思维链〉。
如下面表格所示,在第一阶段,数据引擎合成了 1,128 条轨迹数据。在第二阶段,通过拒绝采样保留了 6,246 条探索轨迹。
在第三阶段,数据引擎合成了 2,016 条自我纠正轨迹。
所有合成的数据集涵盖 107 个多样化的室内场景(如厨房和客厅),包括 2,100 个可交互物体(如鸡蛋、笔记本电脑)和 2,600 个容器(如冰箱、抽屉)。
所有轨迹包含 64K 张第一人称视角的观察图像和 8M 个思考 token。
测试任务:此外,我们在 12 个全新场景中构建了 809 个测试案例,这些场景与训练场景不同。
然后,人工设计了任务指令并标注相应的关键动作和最终状态:〈指令,关键动作,最终状态〉。
值得注意的是,测试集还包含 25 个精心设计的超长序列决策任务,每个任务涉及四个子任务的组合,并涵盖至少 14 个、最多 27 个关键动作。
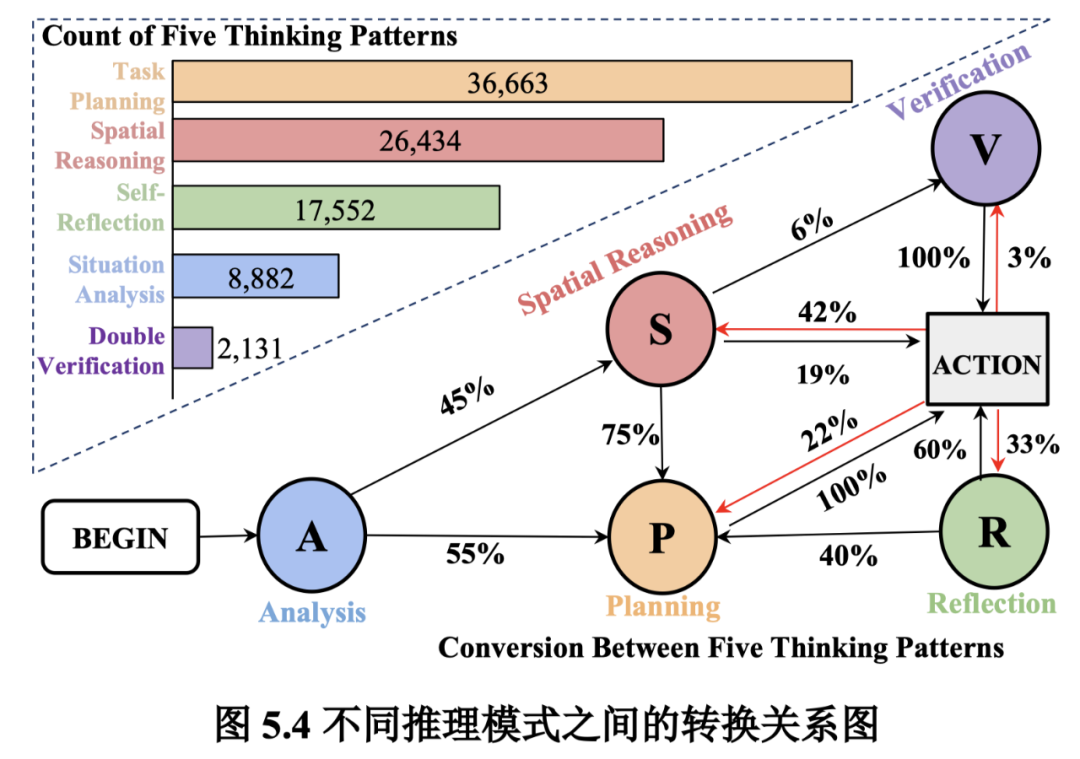
思考模式的分布:本节统计了所有轨迹中五种思考模式的频率。如下图所示,Task Planning 和 Spatial Reasoning 出现最频繁,分别为 36.6k 和 26.4k 次。
这意味着每条轨迹包含约四次 Task Planning 和三次 Spatial Reasoning。此外,Self-Reflection 通常在搜索失败后出现,每条轨迹平均出现两次。
这些多样化的思考促进了模型的推理能力。
思考模式之间的转换:五种思考模式之间的转移概率如下图所示。实验发现它们之间的关系是灵活的,取决于具体情况。
通常从 Situation Analysis 开始,随后是 Task Planning(55%)和 Spatial Reasoning(45%)。
在导航到未知区域时,它经常依赖 Spatial Reasoning(Action→S:42%)。
如果搜索尝试失败,它会转向 Self-Reflection(Action→R:33%),当(子)任务完成时,它有时会进行 Double Verification(Action→V:3%,S→V:6%)。
这种多样化的结构使模型能够学习自发思考和灵活适应性。
实验对比了通用的 VLMs 和近期出现的视觉推理模型,例如 o1、Claude-3.7-sonnet-thinking 等。
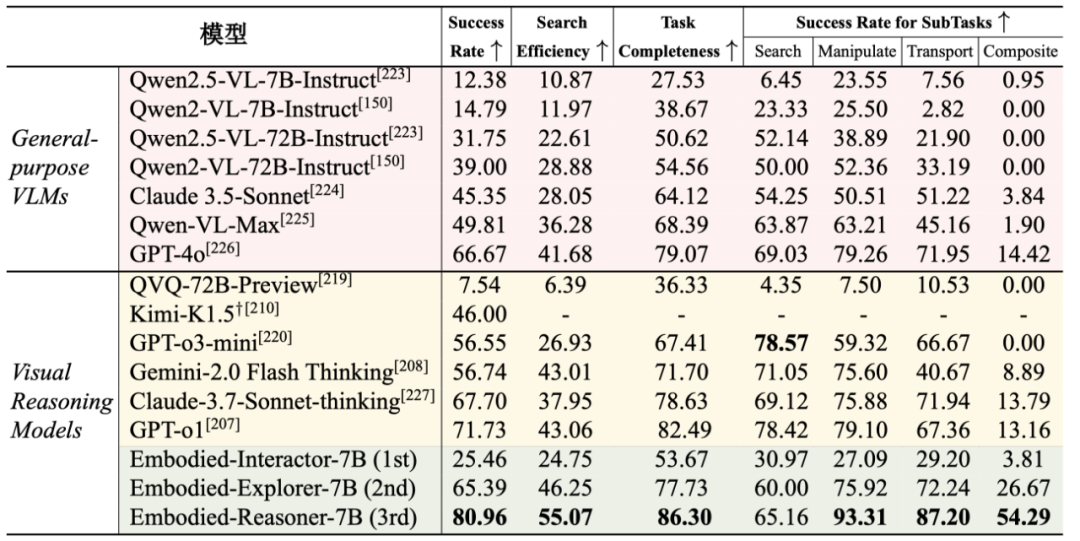
从上表的实验结果来看,Embodied-Reasoner 显著优于所有推理模型和 VLMs,
成功率比 GPT-o1 高出 9.6%,比 GPT-o3-mini 高出 24%,比 Claude-3.7-Sonnet-thinking 高出 13%。
它在搜索效率和任务完成度方面也明显领先,尤其在复杂任务(如复合和运输任务)上表现更为突出,在复合任务上比第二好的模型 GPT-4o 高出 39.9%。
通过三阶段训练(模仿学习、拒绝采样调优和自我纠正轨迹微调),模型性能从基础的 14.7% 逐步提升至 80.9%,
减少了其他模型常见的重复搜索和不合理规划问题,展现出更强的深度思考和自我反思能力,尽管规模小于先进推理模型。
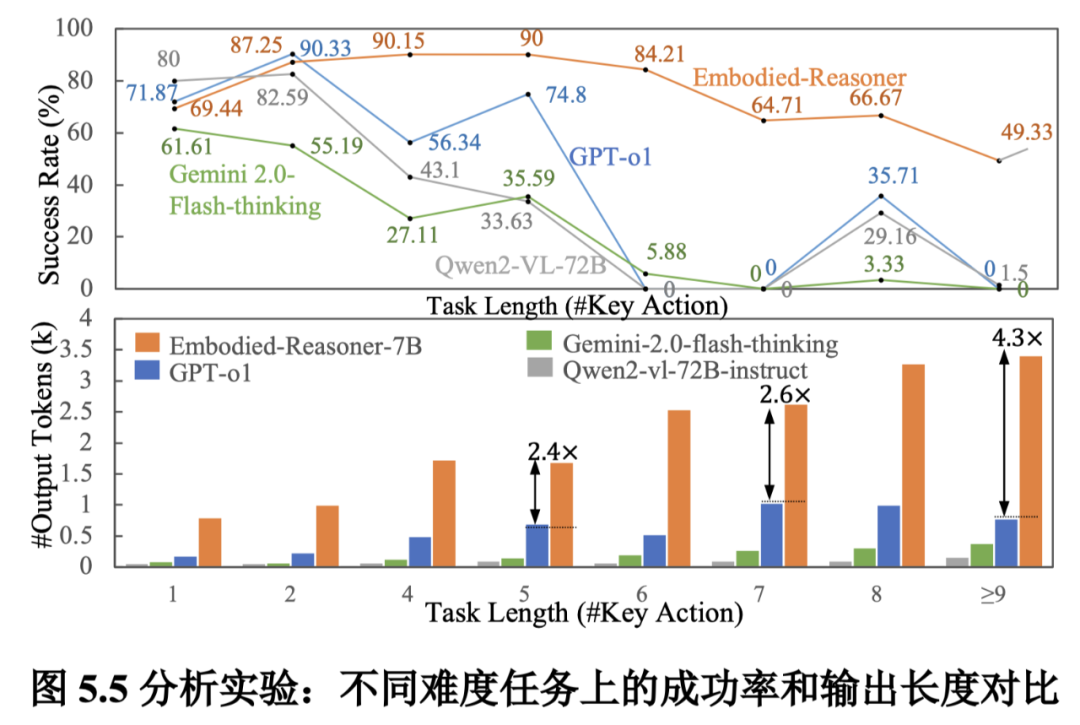
对长序列任务更具鲁棒性:Embodied-Reasoner 在处理复杂的长序列决策任务时表现出显著优势。
实验结果显示,当任务所需的关键动作数量增加时,基线模型的成功率急剧下降,特别是在任务超过五个动作时。
而 Embodied-Reasoner 在大多数复杂情况下仍能保持超过 60% 的成功率,展现出对长序列任务的强大鲁棒性。
自发地为复杂任务生成更长的推理链:面对复杂任务时,Embodied-Reasoner 会自动生成更深入的思考过程。
数据显示,随着任务复杂度增加,其输出 token 从 1,000 增长到 3,500 左右,几乎是 Gemini-2.0-flash-thinking 的五倍。
这种深度思考能力使其能够规划更高效的搜索路径并避免冗余动作,而其他模型如 Gemini-2.0-flash-thinking 则无法通过扩展推理时间来应对更复杂的具身任务。
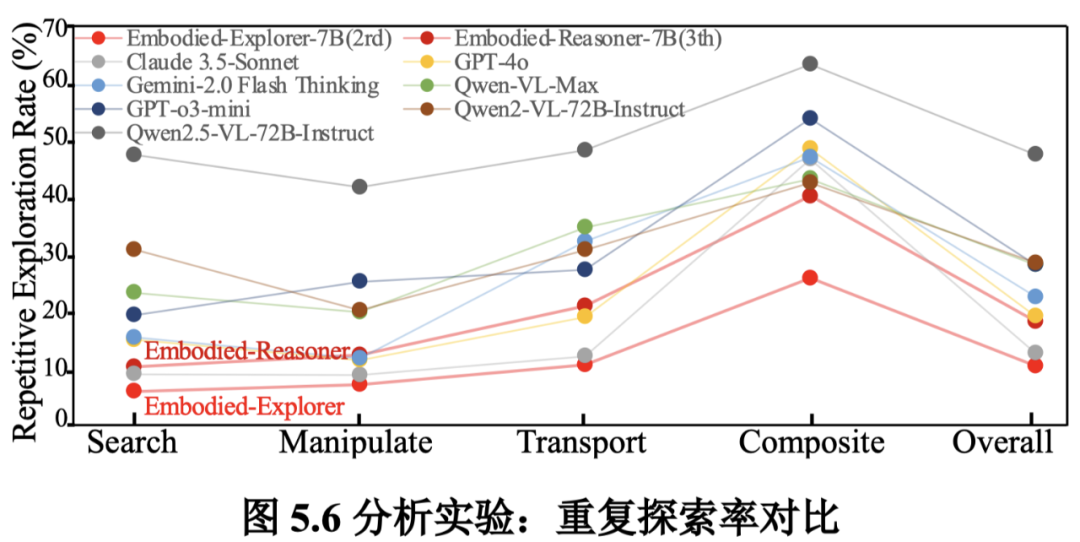
深度思考减轻了重复搜索行为:实验引入重复探索率(RER)来衡量模型在轨迹中重复导航到同一区域的频率。
Embodied-Reasoner 和 Explorer 在所有任务类型中都表现出显著较低的 RER。
在复合任务中,Embodied-Explorer 的 RER 仅为 26%,而 GPT-o3-mini 和 Qwen2-VL-72B 分别达到 54% 和 43%。
Embodied-Reasoner 通过回忆过去观察、反思先前探索动作并制定新计划,增强了时序推理能力,有效减少了重复搜索行为。
为了评估 Embodied-Reasoner 的泛化能力,本节设计了一个关于物体搜索的真实世界实验,涵盖三个场景中的 30 个任务:
6 个厨房任务、12 个浴室任务和 12 个卧室任务。在测试过程中,人类操作员手持摄像机捕捉实时视觉输入。
模型分析每张图像并生成动作命令,然后由操作员执行这些动作。

上图展示了一个例子:「你能帮我找到咖啡并加热它吗?」
Embodied-Reasoner 在两次探索(步骤 1、2)后排除了台面和餐桌,最终在橱柜中找到咖啡(#7)并将其放入微波炉加热(#11)。
然而,实验观察到 OpenAI o3-mini 未能制定合理的计划,先前往微波炉而不是搜索咖啡。
此外,它经常忘记搜索并表现出重复搜索行为,这与本章节之前的分析一致。


Embodied-Reasoner 的贡献包括:
Embodied-Reasoner 已发布于 AGIROS 智能机器人操作系统开源社区。
AGIROS 智能机器人操作系统开源社区由中国科学院软件研究所发起,旨在通过凝聚智能机器人操作系统产学研用各方力量,
共同推动智能机器人操作系统技术及生态的发展,全面推进智能机器人领域的开源开放协同创新,为智能机器人产业夯实基础。
研究团队来自浙江大学、中科院软件所、阿里巴巴和中科南京软件技术研究院,在多模态模型、具身智能体、机器人共用算法框架技术等方面拥有丰富的研究经验。
共同一作为张文祺(浙江大学博士生)与王梦娜(中科院软件所硕士生),通讯作者为中科院软件所副研究员李鹏与浙大庄越挺教授。
该团队曾开发了数据分析智能体 Data-Copilot,在 github 上获得超过 1500 stars, 开发multimodal textbook,首月在huggingface上超过15000次下载。
文章来自于微信公众号 “机器之心”,作者 :张文祺、王梦娜




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
