# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI数学奥赛第一名「答卷」终于公布!
NVIDIA公布并开源了他们的冠军模型OpenMath-Nemotron系列!

论文地址:https://arxiv.org/abs/2504.16891
参加本次Kaggle比赛、软件工程师Chan Kha Vu,则盛赞道:这些模型太不可思议了!从基础的Qwen模型训练开始,甚至都不是推理模型。
而且没有利用强化学习!

英伟达团队参赛的模型叫做OpenMath-Nemotron系列,使用OpenMathReasoning Dataset进行训练,共发布了四种参数:
这些模型在流行的数学基准测试中都取得了最好的成绩。
甚至1.5B的OpenMath-Nemotron模型,超越14B的DeepSeek-R1蒸馏模型!
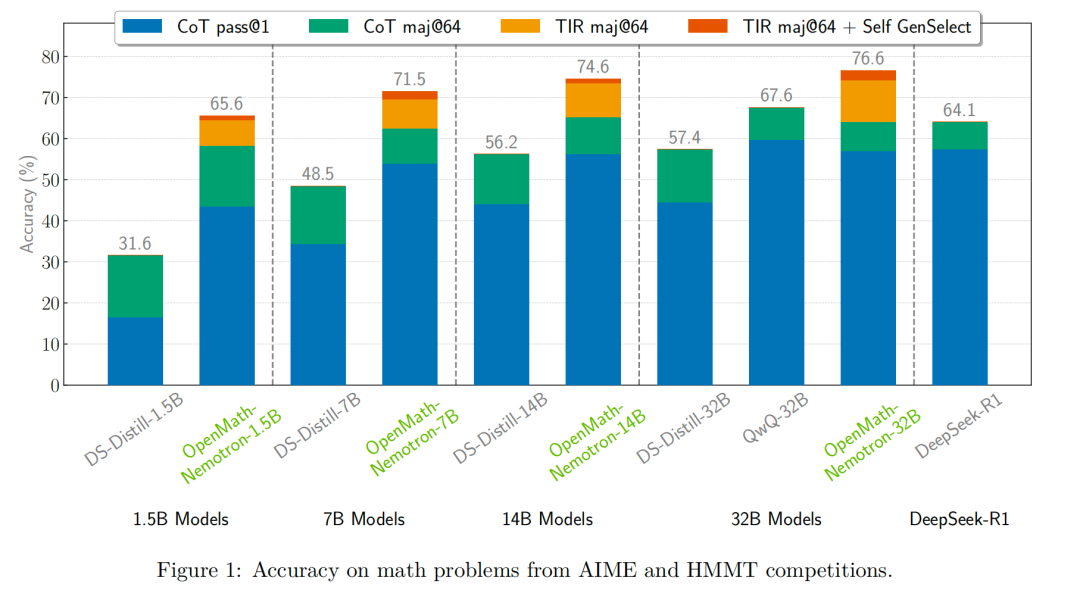
图1:AIME和HMMT竞赛中的数学问题准确率
英伟达能在AIMO-2拔得头筹,不是没有理由的。
除了他们有用不完的卡以外
团队在如何复现成果中暗示了如果没有大型GPU集群,就别试了
英伟达的OpenMath-Nemotron模型能够获胜依赖于三个关键步骤。
从而得到1.7M个高质量的工具集成推理解决方案;
这种生成式解决方案选择(GenSelect)显著优于多数投票基线。
540K来自AoPS论坛的独特数学问题
首先,英伟达团队从互联网上收集了一大批数学问题。
他们从Art of Problem Solving(AoPS)社区论坛收集了大量数学问题数据集。
除「中学数学」(Middle School Math)版块外,他们收录了所有论坛讨论内容
数据采集后,他们建立系统化流程提取问题和对应答案,使用Qwen2.5-32B-Instruct模型进行处理,具体流程如下:
1.问题提取:通过大语言模型识别初始帖文中的数学问题。
2.问题分类:采用大语言模型对每个问题进行多维度分类,并剔除所有选择题、二元判断题及无效问题。
3.问题转化:将证明题转化为需要相似解题技巧的答案导向型问题。
4.答案提取:针对非证明题,从论坛讨论中提取最终答案。
5.基准去污:使用基于LLM的相似度比对,剔除与主流数学基准测试高度相似的问题。
基于LLM的问题提取和精炼流程,最终超过构建了包含54万个问题的数据集,生成了320万个长推理CoT解决方案。
DeepSeek-R1和QwQ-32B等模型为每个问题生成多个解决方案候选。而较难的问题会获得更多的候选方案。
错误的解决方案通过Qwen2.5-32B-Instruct验证答案等效性来过滤。如果没有找到答案,则使用最频繁的候选答案。
在提交的本次解决方案中,他们使用了由DeepSeek-R1生成的220万个问题的子集。
对于求解数学问题,传统的LLM单纯地预测下一个单词的概率并不是非常适合。
解决数学问题,更好的做法还是要调用专业的计算工具。
对于工具集成推理,模型会在需要的地方提示代码进行计算,然后在沙箱中执行代码。
英伟达用特殊token <tool_call>和<\tool_call>识别代码片段。
然后将代码附加到LLM输出中,位于文本```和```output之间。
下面是一个输出示例片段。

下图是GenSelect的数据构建流程,主要包含三个步骤:
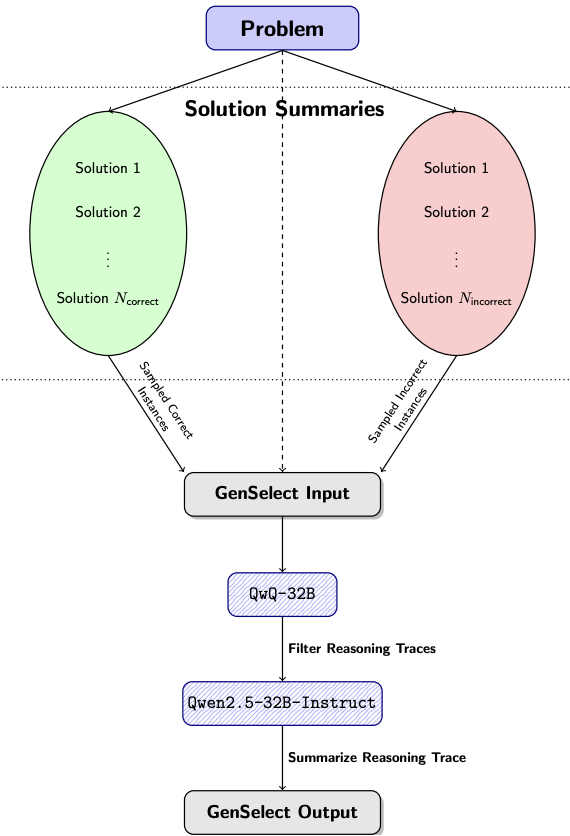
1. 生成摘要
对于OpenMathReasoning数据集中的每个问题,随机抽取2到16个候选解答摘要,确保每个样本组中至少包含一个正确解答和一个错误解答。
这个过程会重复进行,直到为每个问题获得8个不同的比较组。
2. 选择并过滤答案
然后,使用GenSelect提示词,将任务交给QwQ-32B,让它从每个组中选择最有可能的解答。

GenSelect推理提示词
这个过程生成了100万个选择项,随后删除选择了错误解答的实例,将数据量过滤到565K。
3. 总结推理过程(reasoning traces)并输出
通过Qwen2.5-32B-Instruct总结上一布筛选的正确解答的推理过程,从而形成GenSelect的输出。
模型训练
本次提交的Kaggle解决方法 ,使用的训练方法与论文中详细描述的略有不同。
参赛团队发现:这种不同的方法训练的模型,比公开发布的模型使用的token更少。
新模型表现良好,但由于时间限制,他们没有在最终模型上进一步实验减少token。
首先,他们使用SFT在2.2M的CoT解决方案子集上,训练了一个Qwen2.5-14B-Base模型,共8个epoch。
他们将基础RoPE改为500k以允许长推理。
该模型的其他训练参数如下:
使用NVIDIA/Nemo-Skills训练了8 个epoch,
学习率:1e-4,
优化器:AdamW,
权重衰减系数:0.01,
并且有10%的线性预热衰减到学习率为1e-7,
批大小:1024个样本。
他们还利用了NVIDIA/NeMo-Aligner中的序列打包和上下文并行化技术,显著加速了长推理数据的训练。

论文链接:https://arxiv.org/pdf/2405.01481
在512个H100(是的,512 个!)上,训练持续了48小时。
在使用20%算力的情况下,他们就已经实现了模型的大部分性能,但他们扩大了训练规模,观察学习何时达到饱和。
论文中的图 3(b)显示了不同训练阶段的指标。最终权重是从不同阶段进行权重平均得到的。
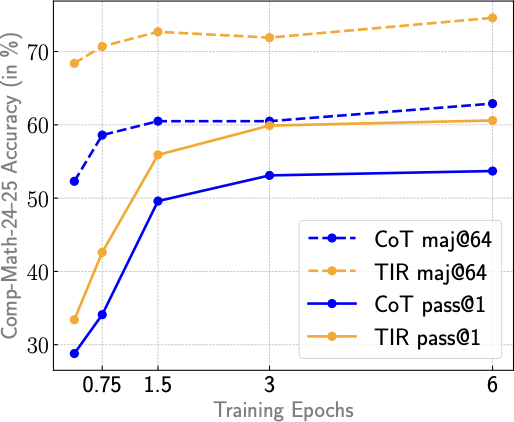
接下来是对15K TIR样本进行轻量级的TIR微调。
参赛团队用恒定的学习率1e-5 训练了TIR 模型400步,并使用最后一个checkpoint而没有进行平均。
随后合并CoT和TIR两个checkpoint,因为这样做既能提高准确性,又能减少解决方案长度和代码执行次数,从而加快生成速度。
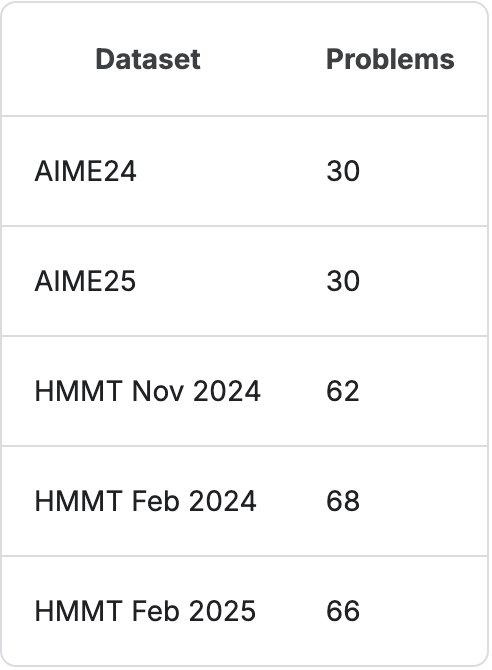
在比赛中,他们主要使用2024年的美国邀请数学考试(AIME 24)和哈佛-麻省理工数学锦标赛(HMMT)的题目。
后来增加了两项测试的2025年度题目。
最终基准Comp-Math-24-25包括256道题目,具体组成如下。
模型推理三步走
在这次竞赛中,他们探索了多种方法来合并具有CoT和TIR行为的两个LLM。
主要目标:有效地结合这两个微调阶段的独特优势,以提高模型的性能。
他们试验了mergekit包中的几种合并技术。

mergekit是专用于合并预训练语言模型的工具包,采用核外计算(out-of-core)技术
结果出乎意料,令人惊讶:最有效的方法竟然是简单的线性组合!
也就是在TIR微调之前使用的思维链checkpoint以及之后获得的最佳TIR checkpoint,两者之间的简单线性组合。
这种策略,能够控制每个阶段对最终模型行为的影响程度。
对于Comp-Math-24-25数据集,下表展示了合并模型的准确率和生成统计数据。
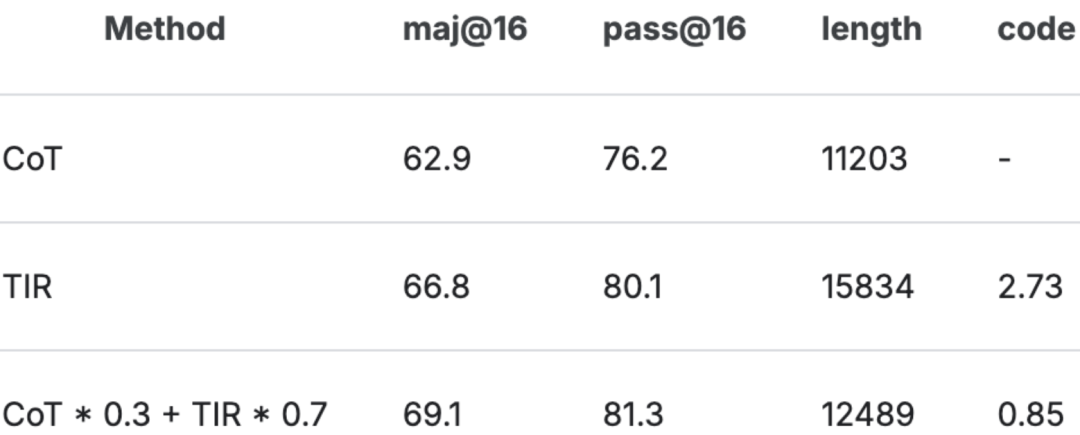
其中length表示解决方案的平均token数,而code表示解决方案的平均代码执行次数。
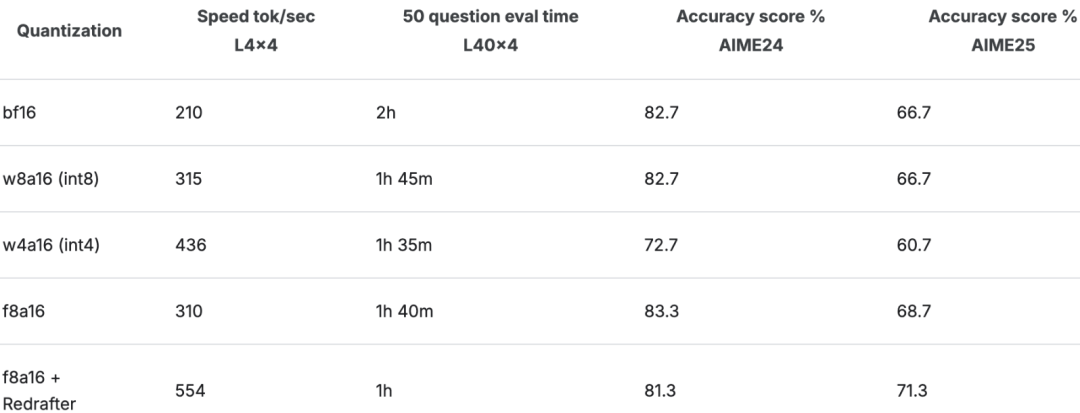
优先考虑了权重为Int8 (W8A16) 和FP8的量化,这比BF16提供了更快的推理速度,且精度损失最小。
减少的权重大小还释放了内存,以便用于更大的键值缓存。
ReDrafter是由Apple开发的一种推测解码技术,并在TensorRT-LLM 中实现。

论文地址:https://arxiv.org/abs/2403.09919
在OpenMathReasoning-1数据集的随机子集上训练了一个ReDrafter头。
使用这些问题,用目标模型生成了100k个解决方案。
生成的ReDrafter在每个 LLM 步骤中生成3个token,接受率为65%,实现了大约 1.8 倍的速度提升。
表格中的准确率得分是使用合并模型的maj@12指标,在5次运行中取平均值。
预训练模型使用TensorRT-LLM转换为TensorRT引擎。
TensorRT-LLM:专为大语言模型推理优化的TensorRT 工具包
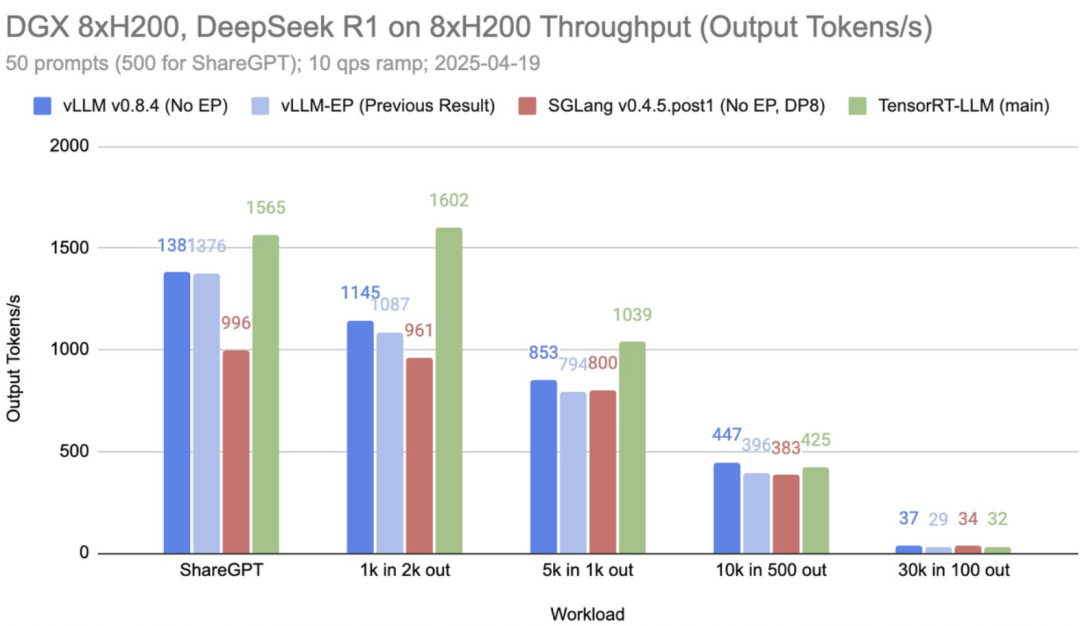
TensorRT的动态批处理通过动态组合推理请求来提高吞吐量,每个样本一旦完成就立即释放——从而减少延迟并优化 GPU 利用率。
vLLM团队提供的一些最新基准测试, 请参见下图。
由于样本处理相互独立,批次计算可无缝混合不同输入提示(prompt)或随机种子。
TensorRT-LLM还集成了多项优化技术,包括定制注意力内核(custom attention kernels)和分页KV缓存(paged KV caching)等。
对于每个新问题,他们使用不同的种子,利用TensorRT中的异步批处理,启动12次生成。
每个样本的流处理会监控代码块、停止语句、最大标记数或超时。
如果LLM生成了代码,LLM的生成过程会停止,代码块会在沙箱中执行。
沙箱的输出(或部分错误跟踪)会被附加到LLM中,生成过程继续进行。
生成过程会持续,直到遇到另一个代码块。
当没有遇到其他代码块时,根据最大标记数、超时时间或停止语句之一,LLM会停止。
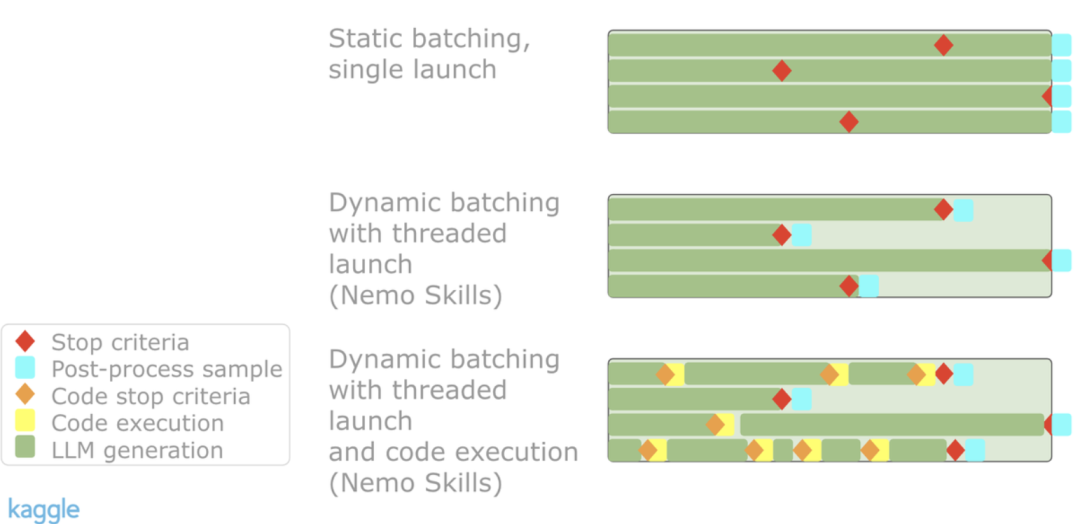
异步批处理流程
他们最终提交了基于一种「几乎」贪心的搜索策略,因为它在小批量大小下提供了更稳定的结果,并且在猜测解码的速度上略有提升。
为了提高速度,会监控生成过程是否完成:当初始答案相同时,就会提前停止。
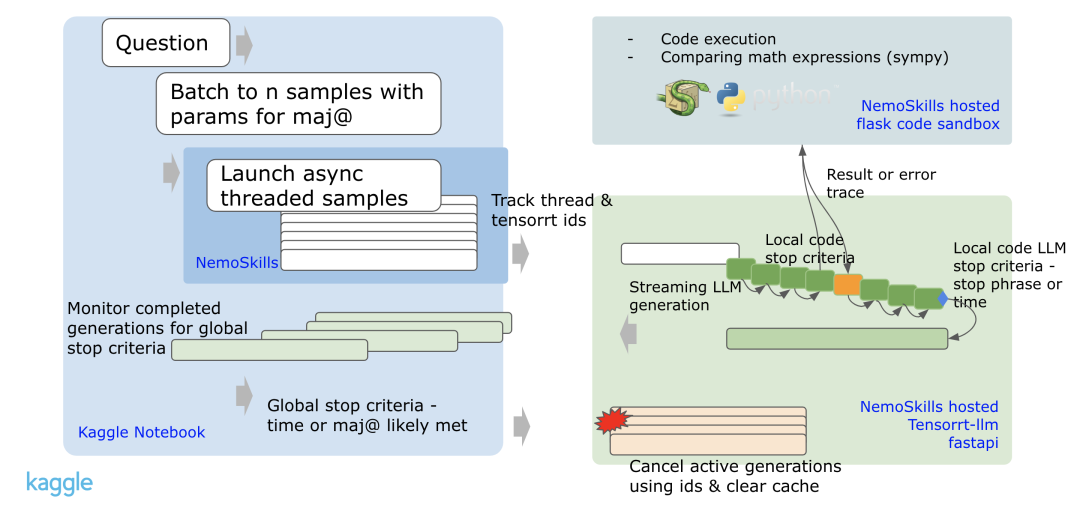
提前停止和缓存策略
在监控异步生成过程中,在12次生成中完成10次,他们会提前停止,避免过度等待任何滞后的生成。
他们还实施了一种缓冲策略。
如果一个问题提前完成,未使用的时间将被加入到共享缓冲区。
下一个问题可以从这个缓冲区中提取最多210秒的额外时间,从而使总时间达到560秒。

推理流程
对于最终选择的提交,他们选择了一个14B CoT模型和上述的MIX TIR模型。
MIX TIR模型在交叉验证数据集上得分明显更好,在公开排行榜上的得分也得到提高(公开排行榜得分:32, 33, 28)。
最终,私密排行榜的结果更接近交叉验证数据集的结果,而不是公开排行榜的结果。
由于每次提交的时间限制以及只有50个问题被评分,
他们没有足够的时间和提交机会来准确缩小交叉验证数据集和公开排行榜之间的差异,尤其是在每次只能提交一个模型的情况下。
AIMO Progress Prize已经举办了两届。
在第一届中,前五名的最高分为29分,最低分只有20分。
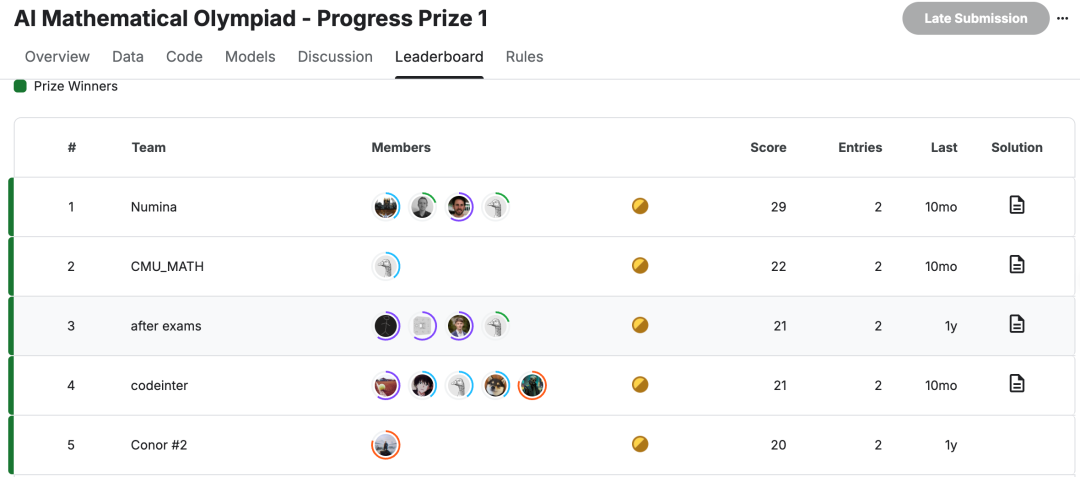
在过去一年时间后,前五名中,最高分被英伟达刷到了34分,最低分也和第一届相同。
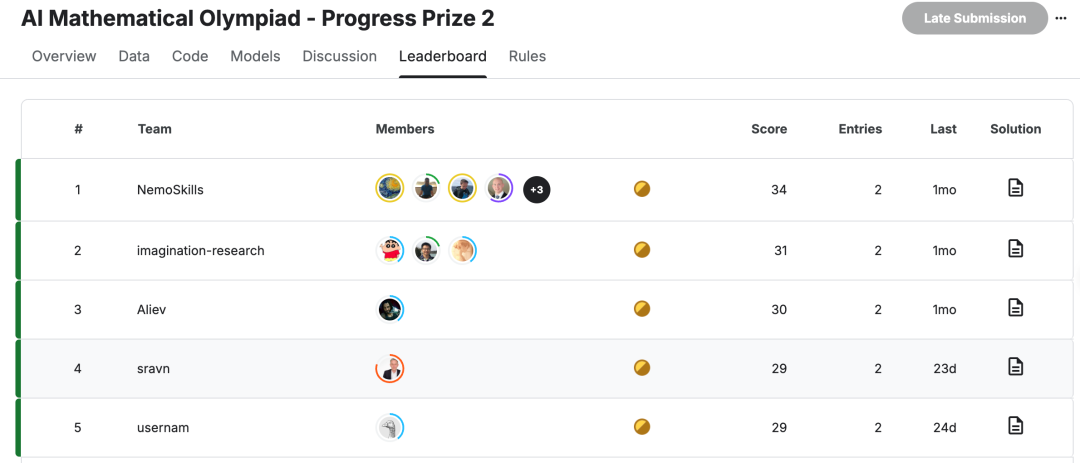
AIMO是一个难度非常高的挑战,在这一届中,AI解决了50道题目中的34道题。
如果换算成100分,AI在这场考试中已经取得了68分,超过了及格线。

也许明年,或者后面,AI就能在这场测试中获得「全胜」。
当AI能够解决所有人类数学家提出的问题,也许数学的边界也会被重新定义。
参考资料:
https://x.com/jandotai/status/1915345568483991741
https://www.kaggle.com/competitions/ai-mathematical-olympiad-progress-prize-2/discussion/574765
https://arxiv.org/pdf/2504.16891
https://huggingface.co/collections/nvidia/openmathreasoning-68072c0154a5099573d2e730
文章来自于 “新智元”,作者 :KingHZ 定慧



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
