# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。
然而,它们迅速增长的规模给高效部署和推理带来了巨大障碍,特别是在计算或内存资源有限的环境中。
例如,Llama-3.1-405B 在 BFloat16(16-bit Brain Float)格式下拥有 4050 亿个参数,需要大约 810GB 的内存进行完整推理,
超过了典型高端 GPU 服务器(例如,DGX A100/H100,配备 8 个 80GB GPU)的能力。因此,部署该模型需要多个节点,这使得它昂贵且难以获取。
本文,来自莱斯大学等机构的研究者提出了一种解决方案,可以将任何 BFloat16 模型压缩到原始大小的 70%,同时还能在任务上保持 100% 的准确性。

为了应对 LLM 不断增长的模型尺寸,通常会采用量化技术,将高精度权重转换为低位表示。
这显著减少了内存占用和计算需求,有助于在资源受限的环境中实现更快的推理和部署。
然而,量化本质上是一种有损压缩技术,引入了一个基本缺点:它不可避免地改变了 LLMs 的输出分布,从而影响模型的准确性和可靠性。
相比之下,无损压缩技术在有效减少 LLM 规模的同时,保留了精确的原始权重,确保模型的输出分布与未压缩表示(例如 BFloat16)完全相同。
然而,现有的无损方法主要集中在提高 LLMs 的存储效率上,例如缩小模型检查点或优化针对专用硬件如 FPGA 的性能上。
本文提出了 DFloat11(Dynamic-Length Float),这是一种无损压缩框架,可以在保持与原始模型完全相同的输出的情况下,将 LLM 的规模减少 30%。
DFloat11 的提出源于当前 LLM 模型中 BFloat16 权重表示的低熵问题,这暴露出现有存储格式存在显著的低效性。
通过应用熵编码技术,DFloat11 根据权重出现频率为其分配动态长度编码,在不损失任何精度的情况下实现了接近信息理论极限的压缩效果。
为了支持动态长度编码的高效推理,该研究还开发了定制化的 GPU 内核来实现快速在线解压缩。其设计包含以下内容:
该研究在 Llama-3.1、Qwen-2.5 和 Gemma-3 等最新模型上进行了实验:DFloat11 能在保持比特级(bit-for-bit)精确输出的同时,将模型体积缩减约 30%。
与将未压缩模型部分卸载到 CPU 以应对内存限制的潜在方案相比,DFloat11 在 token 生成吞吐量上实现了 1.9–38.8 倍的提升。
在固定 GPU 内存预算下,DFloat11 支持的上下文长度是未压缩模型的 5.3–13.17 倍。
值得一提的是,基于该方法 Llama-3.1-405B(810GB)在配备 8×80GB GPU 的单节点上实现了无损推理。
LLM 的权重通常使用浮点数表示,包括 BFloat16 或 BF16,其在数值精度和内存效率之间取得了平衡。然而,BFloat16 表示信息并不高效。
针对 BFloat16 表示法中存在的信息效率低下问题,本文提出了一种无损压缩框架,通过熵编码技术对浮点参数进行压缩。
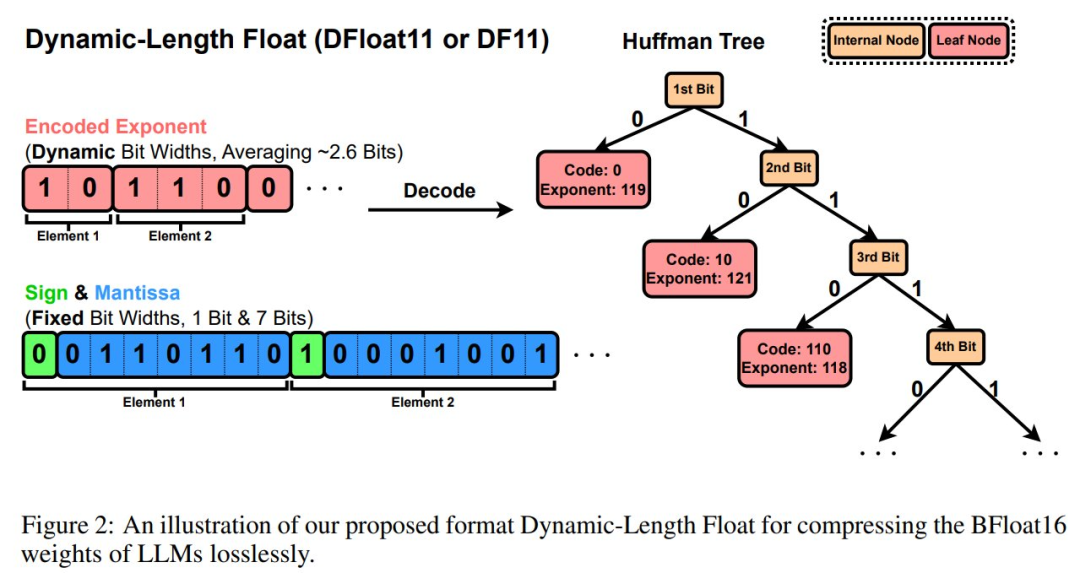
具体实现包括:基于语言模型线性投影矩阵中所有 BFloat16 权重的指数分布构建霍夫曼树,对指数部分采用霍夫曼编码压缩,同时保留原始符号位和尾数位。
压缩后的指数经过紧密比特打包存入字节数组 EncodedExponent,而未压缩的符号位和尾数则存储在独立字节数组 PackedSignMantissa 中。
图 2 展示了 DFloat11(Dynamic-Length Float)或 DF11,该格式可实现模型参数的高效紧凑表示。
虽然动态长度浮点数能有效实现 LLM 的无损压缩,但关键挑战依然存在:如何利用这些压缩权重进行高效的 GPU 推理。
接下来,文章详细介绍了解决方案,其中包括三个关键组成部分:
1.将一个庞大的无前缀查找表(LUT)分解为多个适合 GPU SRAM 的紧凑 LUTs;
2.引入一个两阶段的内核设计,利用轻量级辅助变量来高效协调线程的读写操作;
3.在 transformer 块级别执行解压缩,以提高吞吐量并最小化延迟。
算法 1 是将 DFloat11 解压缩为 BFloat16 的 GPU 内核过程。

实验
研究人员评估了 DF11 压缩方法在 GPU 上的有效性及推理效率,
将多个主流大语言模型(包括 LLaMA、Qwen、Gemma 等)从 BFloat16 压缩为 DF11 格式,并报告其压缩比和性能表现。
在软硬件环境方面,研究人员使用 CUDA 和 C++ 实现了 DF11 解压缩内核,并集成至 Transformers 推理框架。
实验基于 HuggingFace Accelerate 框架评估未压缩模型在 CPU 分流(CPU offloading)和多 GPU 场景下的性能。
为全面分析 DF11 内核在不同硬件配置下的表现,团队在多种 GPU 和 CPU 组合的机器上进行实验。
实验结果
DF11 压缩比:DF11 将大语言模型压缩至原始大小的约 70%(等效位宽为 11 位)。
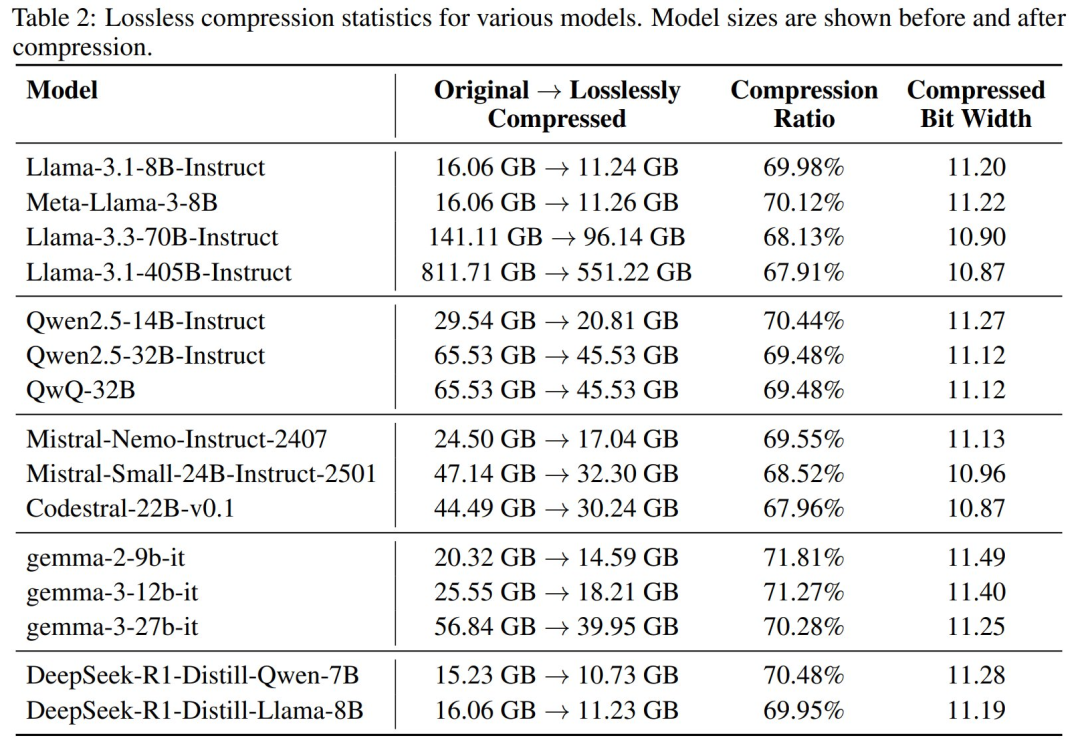
表 2 展示了 DF11 在 LLaMA、Qwen、Gemma 等模型上的压缩效果。所有模型的线性投影层参数均被压缩为 DF11 格式,压缩比稳定在 70%。
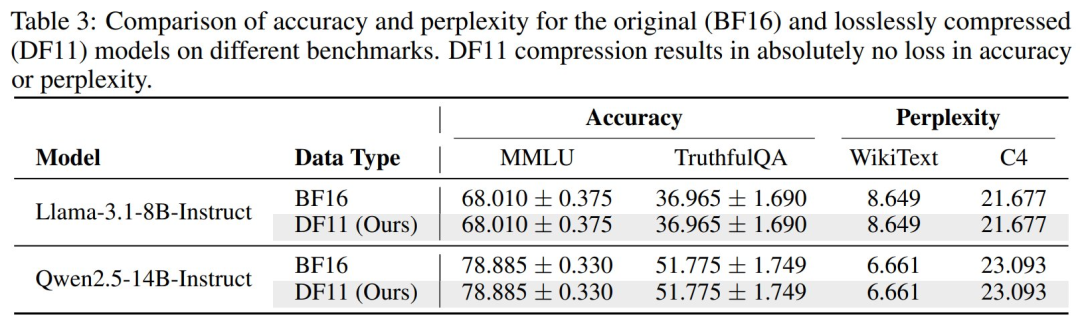
无损特性验证:为验证 DF11 的无损特性,研究人员使用 lm-evaluation-harness 工具在 MMLU、TruthfulQA、WikiText 和 C4 数据集上评估模型性能。
结果表明,压缩后的模型在准确率和困惑度(Perplexity)上与原始 BFloat16 模型一致(见表 3)。
此外,研究人员逐位对比 DF11 解压后的权重矩阵与原始矩阵,确认其完全相同。
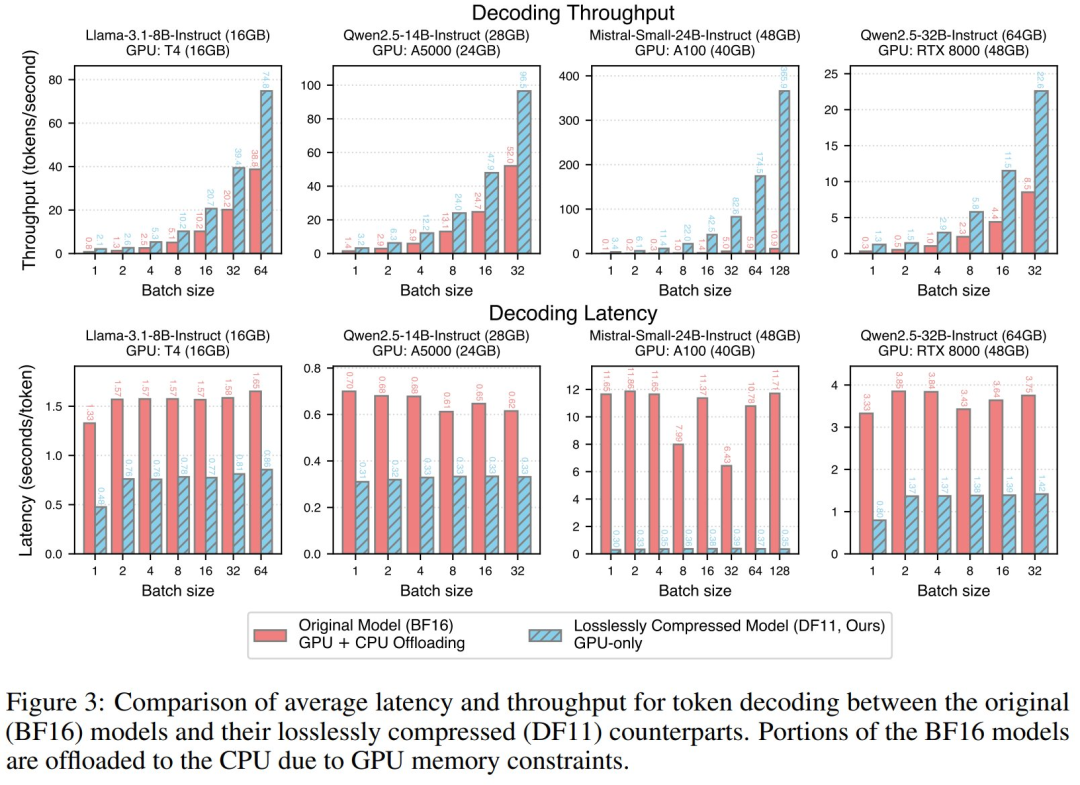
推理性能:研究人员在多个硬件平台上比较了 DF11 与 BFloat16 模型的推理效率。
对于 BFloat16 模型,当模型超出单 GPU 显存时,需将部分计算分流至 CPU,而 DF11 模型可完全加载至单 GPU。
评估指标包括延迟(Latency)和吞吐量(Throughput),结果显示 DF11 模型的性能显著优于 BFloat16 模型,延迟减少 1.85 至 38.83 倍(见图 3)。
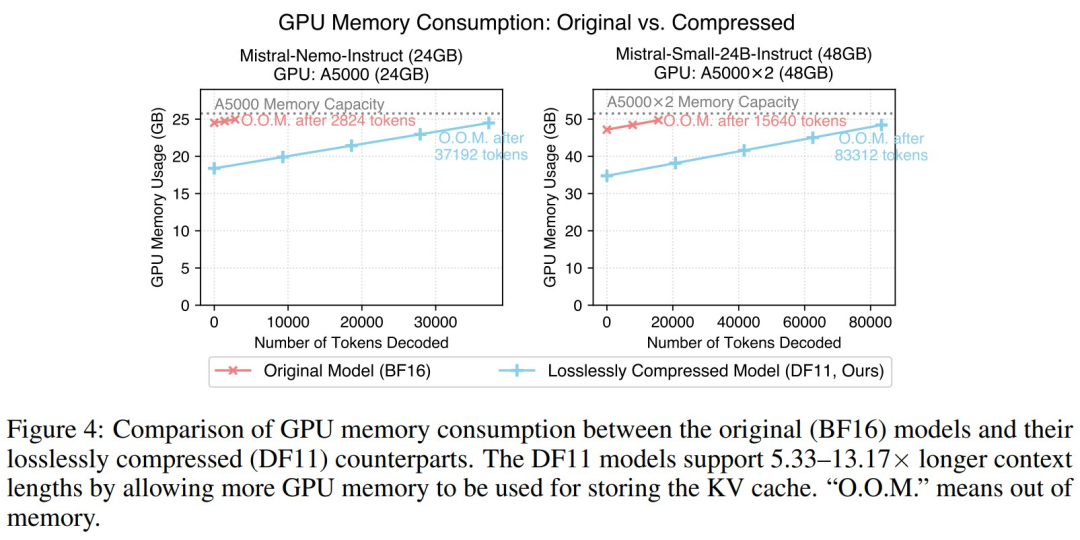
节省的显存可支持更长生成序列:DF11 的显存节省使模型能够支持更长的生成序列。
如图 4 所示,在 batch size 为 1 时,DF11 模型的显存消耗显著降低,相比 BFloat16 模型最多可生成 5.33 至 13.17 倍的 tokens。
消融研究
延迟分析:研究团队以 Llama-3.1-8B-Instruct 为例,对比了其在 BFloat16 与 DF11 格式下不同 batch 大小时的延迟组成,结果如图 5 所示。
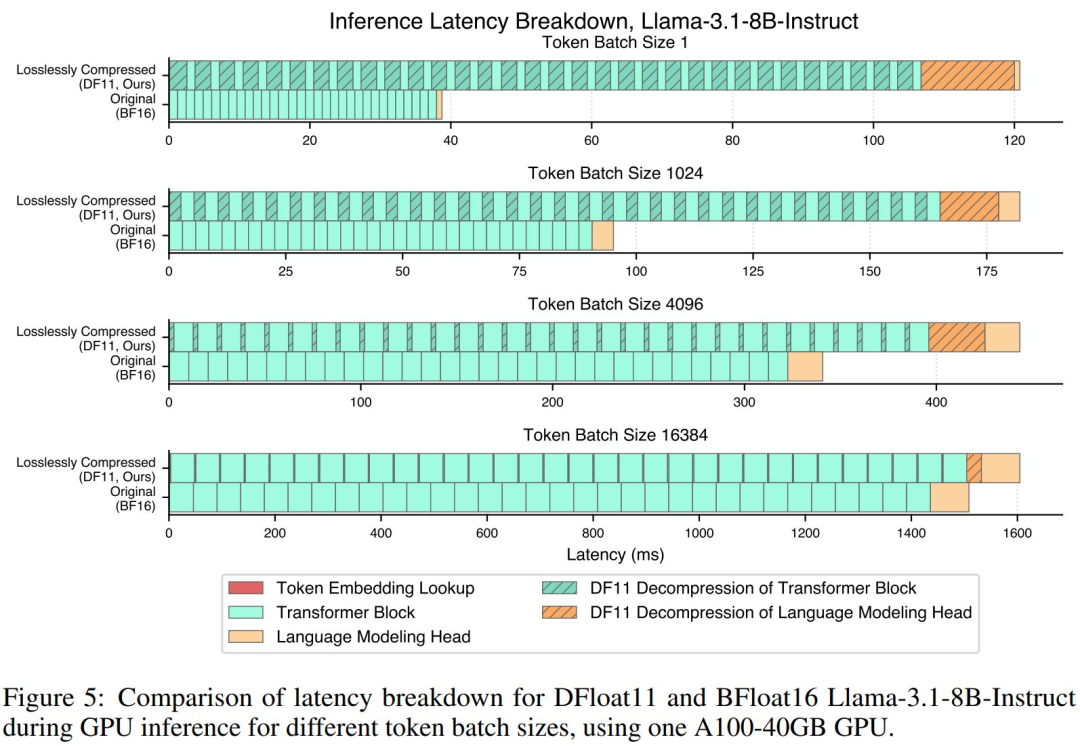
相比原始模型,DF11 压缩模型因解压 Transformer 模块与语言建模头引入了额外延迟但该开销与 batch size 无关,
因此通过提升 batch size 可有效摊销解压延迟,使总推理时间之间的差距显著缩小。
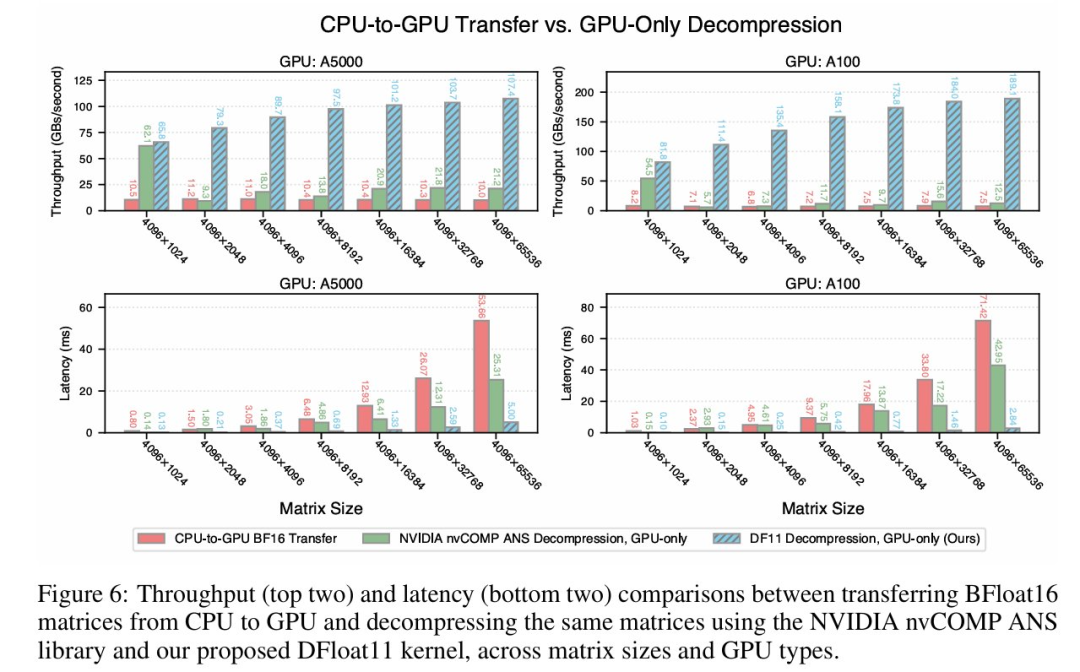
解压性能对比:研究人员将 DF11 解压内核的延迟与吞吐表现分别与两种基线方案进行对比:
实验以 Llama-3.1-8B-Instruct 语言建模头权重矩阵为例,结果如图 6 所示,DF11 的解压吞吐量最高分别为 CPU-GPU 传输和 ANS 解码的 24.87 倍和 15.12 倍。
此外,DF11 的压缩比为 70%,优于 nvCOMP 的 78%。
值得注意的是,随着权重矩阵规模的增大,DF11 的解压吞吐呈上升趋势,原因是更好的 GPU 线程利用率。
文章来自于微信公众号 “机器之心”,作者 :陈萍、+0




【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
