# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
苹果追上来了,用它最擅长的方式。
大模型领域最新的一个热门趋势是把模型塞到手机里。而最应该做这个研究的公司终于带着它的论文现身,那就是苹果。
这家公司的研究团队最近发布了一篇论文《LLM in a flash: Efficient Large Language Model Inference with Limited Memory》,简单说,它尝试利用闪存来解决大模型在塞进手机时遇到的内存不足的问题。
这是一个对于端侧部署模型十分关键的问题。
计算机的记忆体(Memory)简单分为内存(Ram)和闪存(Flash)两种。内存用于临时存储那些需要随时访问的数据和指令,它提供高速的读写,有较高的存储密度。而闪存正相反,它读写较慢,适用于长期数据的存储。
因此从特性上看,内存更适合需要频繁读写的大模型。然而这带来一个问题,它成了一个限制死了的搭配,比如一个70亿参数的模型就必须需要超过14GB的内存才能以半精度浮点格式加载参数,但这超出了大多数边缘设备的能力。
如这篇论文的标题所示,苹果想要通过闪存来解决这个问题。
论文为了将大模型搬到闪存上,一共做了三步。
第一步:先让闪存能参与进模型运行中来。论文提到一个概念,大语言模型在前馈网络(FFN)层展现出高度的稀疏性(超过90%)。FFN是一种基本的神经网络架构,其中信息单向流动,从输入层流向输出层,中间可能经过多个隐藏层。在这种网络中,每一层的输出仅作为下一层的输入,而没有任何反馈或循环连接。于是论文把FFN当成是一个筛子,仅迭代传输闪存中必要的、非稀疏数据到DRAM进行处理。
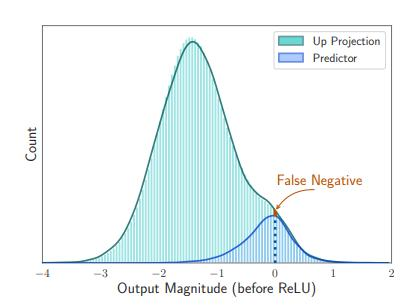
使用修正线性单元(ReLU)前后输出幅度对比,ReLU用来实现稀疏性
接下来是第二步:论文提出了一种名为“滑动窗口技术”的神经元数据管理方法。把那些在预测模型中产生正输出的神经元定义为活跃神经元,在内存中保留最近一部分输入标记的神经元数据,仅加载当前输入标记与其直接前驱不同的神经元数据。这样做能有效利用内存,释放掉之前分配给已不在滑动窗口内的旧标记神经元数据的内存。

滑动窗口技术
第三步:论文还提出了一种增加数据块大小的策略。论文用OPT和Falcon模型做实验,把向上投影的第i列和向下投影的第i行捆绑存储。当激活第i个中间神经元时,这两部分数据会同时被使用。通过在闪存中将这些对应的列和行一起存储,可以将数据整合成更大的块进行读取。

内存管理策略,首先将最后的元素复制到要删除的神经元中,以保持连续的内存块,然后将需要的元素堆叠到最后
这些术语看起来依然晦涩?没关系我们可以做个类比,事实上它的思路与曹冲称象非常像。
首先论文要解决的问题就是,大模型是大象,没办法直接上秤测量(设备内存有限,放不了大模型)。
于是用了三个步骤来在特定环节减少对大模型的访问延迟。
首先找到一个等价方法,让大象上船,测量水位线,再用石头垒在船上,船达到同样的水位线,最后称这些石头的重量(也就是上面说的第一步,可以理解为减少数据加载)。
然后,其中体积一样大的石头不需要称第二次(也就是第二步,优化数据块大小以提高闪存吞吐量)。
此外,搬运石头的时候使用更大的框,一次可以装很多块石头(就是最后一步的,高效管理加载到内存中的数据)。
而这个过程的重点,是优化闪存交互和内存管理,以实现内存受限设备上的高效推理。使用这个方法来预测FFN的稀疏性并避免加载零化的参数,优化成本模型和按需选择性加载参数,实现了可以运行比设备DRAM容量大两倍的模型,并在CPU和GPU上分别比传统方法提速4-5倍和20-25倍。
当然,论文提供的方法只针对60到70亿左右参数的模型,如果是几百亿参数的模型,这样的办法会造成死锁或者内存溢出。不过他仍然给了便携使用大模型这事一种可能性,这是非常难得的。
为了证明论文提出方法的实际价值,论文引用了Facebook的OPT 6.7B模型和TII的Falcon 7B模型。下图在模型的一半内存可用时,1个token的推理延迟。在M1 Max上,每个token从闪存加载需要125毫秒的延迟,内存管理需要65毫秒。因此,每个token的总的与内存相关的延迟小于190毫秒(两者总和)。相比之下,传统方法需要以6.1GB/s的速度加载13.4GB的数据,导致每个token的延迟大约为2330毫秒。因此,这个方法相对于基准方法表示了重大改进。Falcon 7B也是类似,使用论文的方法延迟仅为250毫秒,而传统方法的延迟为2330毫秒。延迟肯定是越低越好,越低代表从闪存中加载大模型的速度越快。

各模型1个token的推理延迟
在今年AI的疯狂里,苹果曾被诟病动作很慢,但这篇论文、此前苹果提出的MLX框架、自动语音识别(ASR)以及它自己的模型Ferret等研究其实说明,苹果已经目标明确的在做很具体的研究了。看看这几个重要的但并没有引起很多重视的研究,也可以感受到苹果AI上的方向。
MLX框架是苹果在2023年推出的一个专门运行在苹果芯片上的机器学习数组框架。MLX支持可组合的函数变换,用于自动微分、自动向量化和计算图优化,但重点是MLX中的计算只有在需要时,数组才会被实际计算出来。同时MLX中的计算图是动态构建的,改变函数参数的形状不会触发缓慢的编译过程。而且MLX中的数组存在于共享内存中,可以在任何支持的设备类型上执行MLX数组的操作,而不需要数据传输。
也就是说,MLX突出一个节省资源且“海陆空”三栖作战(可以同时调用内存、显存,可以在手机和电脑运行)。这说明苹果非常注重模型的可实现性,即便是手机这样内存有限的设备也能跑大模型。当有了这样的框架后,苹果就可以将Ferret模型塞进便携设备里了。
Ferret模型是苹果在2023年10月推出的新型多模态大型语言模型(MLLM),它能够理解图像内任意形状或粒度的空间指代,并准确地对开放词汇的描述进行定位。Ferret采用了一种新颖而强大的混合区域表示方法,将离散坐标和连续特征结合起来表示图像中的一个区域。为了提取多样化区域的连续特征,论文提出了一种空间感知的视觉采样器,能够处理不同形状之间的稀疏性差异。模型这种理解能力,意味着Ferret可以接受各种输入,比如点、边界框和自由形状,像是DALL·E也好,Midjourney也好,都不能完全理解这种提示词的输入。
苹果将要推出的AR设备Vision Pro,对外宣称是首款采用空间计算的产品。空间计算本质是传感器的一门学问,通过传感器来获取关于物理空间的数据,并通过计算和分析这些数据来理解和处理环境信息。传统电子设备屏幕都只是平面二维,但是空间计算作用的是现实中三维空间的物理概念,在Ferret的加持下,空间的边界感、长宽高三种向量的立体感就会更加明显。
Ferret模型不一定能按要求画出最美的画面,但它一定能符合拥有艺术设计能力创作者的需求。尤其是在视觉识别、配色方案、排版、网格等设计专业领域,Ferret模型的效果将会最为明显。设计从业者是苹果最为广泛的受众之一,苹果就像是个狙击手,专门瞄准用户最需要它的地方。
此外苹果也一直在对与Siri相关的AI技术做研究,比如大语言模型在SLU任务上的准确性受限于ASR系统对给定语音输入的准确性。那为了解决这一问题,苹果找到了一种方法:使用ASR的n-best假设列表来提示大语言模型,而非仅依赖错误率较高的1-best假设。意味着Siri在接入大语言模型后,性能会得到提高。
至此,从硬件的芯片层,到调用系统侧,到与空间计算概念相联系的自研多模态模型,再到目前看起来最被期待的苹果的AI能力的入口Siri,苹果已经有体系有目的有节奏的完成了诸多技术积累。2024年,在讨论AI时没人能忽视苹果了。
文章来自于微信公众号 “GenAI新世界”(gh_e06235300f0d),作者 “苗正”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
