# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。
为推进大语言模型的逻辑推理能力研究,来自北大、清华、阿姆斯特丹大学(UvA)、卡内基梅隆大学(CMU)、MBZUAI 等 5 所高校的研究人员全面调研了该领域最前沿的研究方法和评测基准,联合发布了调研综述《Empowering LLMs with Logical Reasoning: A Comprehensive Survey》,针对两个关键科学问题 —— 逻辑问答和逻辑一致性,对现有方法进行归纳整理并探讨了未来研究方向。
该综述论文已被 IJCAI 2025 Survey Track 接收,并且作者团队将于 IJCAI 2025 现场围绕同一主题进行 Tutorial 演讲,全面探讨该研究领域的挑战、方法与机遇。

大语言模型(LLMs)虽然在很多自然语言任务中取得了显著成就,但最新研究表明其逻辑推理能力仍存在显著缺陷。本文将大模型逻辑推理困境主要归纳为两个方面:
为推进该领域研究,我们系统梳理了最前沿的技术方法并建立了对应的分类体系。具体而言,对于逻辑问答,现有方法可根据其技术路线分为基于外部求解器、提示工程、预训练和微调等类别。对于逻辑一致性,我们探讨了常见的逻辑一致性的概念,包括否定一致性、蕴涵一致性、传递一致性、事实一致性及其组合形式,并针对每种逻辑一致性归纳整理了其对应的技术手段。
此外,我们总结了常用基准数据集和评估指标,并探讨了若干具有前景的研究方向,例如扩展至模态逻辑以处理不确定性,以及开发能同时满足多种逻辑一致性的高效算法等。
具体的文章结构如下图。
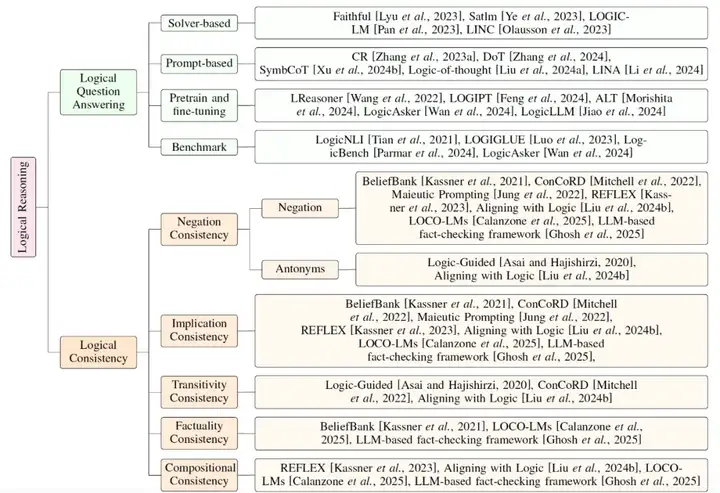
图 1:大模型逻辑推理综述分类体系,包含逻辑问答和逻辑一致性两个关键科学问题
尽管大语言模型在文本生成、分类和翻译等广泛的自然语言任务中展现出了卓越的性能,大语言模型在复杂逻辑推理上仍然面临着重大挑战。这是由于大语言模型的预训练语料库主要由人类撰写的文本组成,这些文本缺乏高质量的逻辑推理样本(如演绎证明),且通过下一词元预测(next token prediction)或掩码语言建模(masked language modeling)等任务来学习语法、语义和世界知识,并不能确保大语言模型具备逻辑推理能力。以上局限性会导致大语言模型在需要逻辑推理能力在以下两个任务表现不佳。
逻辑问答
大语言模型在逻辑问答中往往无法生成正确答案,其要求大语言模型在给定一系列前提和推理规则的情况下,进行复杂的演绎、归纳或溯因推理。具体而言,这些逻辑问题大致可分为两类:
令人惊讶的是,在逻辑问题数据集 FOLIO 上,LLaMA 13B 参数模型在 8-shot 下的准确率仅为 33.63%,这只比从真、假和无法判断中随机猜测对应的准确率 33.33% 略高一点。这极大地限制了大语言模型在智能问答、自主决策等场景的实际应用。
逻辑一致性
大语言模型在推理复杂问题的过程中回答不同问题时,容易产生自相矛盾的回答,或与知识库 / 逻辑规则相矛盾,我们称其违反了逻辑一致性。
需要注意的是,逻辑一致性的形式可以是多样的。例如,LLaMa-2 70B 参数模型对 “信天翁是一种生物吗?” 和 “信天翁不是一种生物吗?” 这两个问题都回答 “真”,这违反了逻辑的矛盾律。又如,Macaw 问答大模型对 “喜鹊是鸟吗?” 和 “鸟有翅膀吗?” 这两个问题都回答 “是”,但对 “喜鹊有翅膀吗?” 却回答 “否”,这不符合三段论推理规则。
许多研究表明,仅在大型问答数据集上进行训练并不能确保大语言模型的逻辑一致性。这些相互矛盾的回答引发了对大语言模型可靠性和可信度的担忧,尤其限制了其在高风险场景中的实际部署,如医疗诊断、法律咨询、工业流程控制等场景。
我们可以将逻辑问答和逻辑一致性视为大语言模型逻辑推理能力的一体两面。接下来我们将对这两个方面的最新研究进展进行归纳总结。
为了更好地理解大语言模型逻辑推理能力的边界,探索更有效的技术方法,研究者们开发了许多相关的测评任务与基准数据集,用于评估大模型在逻辑问答任务的性能。在此基础上,许多研究探索了增强大语言模型逻辑推理能力的方法,这些方法可以大致分为三类:基于外部求解器的方法、基于提示的方法,和预训练与微调方法。下面进行具体介绍。
1. 基于外部求解器的方法
总体思路是将自然语言(NL)表达的逻辑问题翻译为符号语言(SL)表达式,然后通过外部求解器进行逻辑推理求解,最后基于多数投票等集成算法生成最终答案,如图 2 所示。
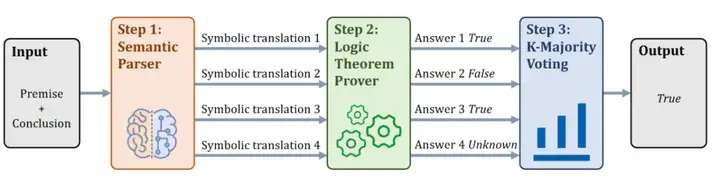
图 2:基于外部求解器方法提升大模型逻辑问答能力
2. 基于提示的方法
一类思路是通过设计合理的提示词,让 LLMs 在回答问题时显式地构造逻辑推理链;另一类思路是通过设计提示实现 NL 与 SL 的表达转换,从而增加大模型的逻辑推理能力。
3. 预训练与微调方法
考虑到预训练语料库中缺乏高质量的逻辑多步推理或证明样本,预训练和微调方法通过纳入演绎证明或包含逻辑推理过程的自然语言例子来增强数据集,并基于该数据集对大模型进行预训练或微调。
开发可靠的大语言模型并确保其安全部署变得越来越重要,尤其是在它们被用作知识来源时。在可信性中,逻辑一致性至关重要:具有逻辑一致性的大模型可以有效避免不同问题的回答之间产生矛盾,从而减少大模型幻觉,增强终端用户在实践中对大模型可靠性的信心。
逻辑一致性要求大模型在推理复杂问题的过程中回答不同问题时,不与自身回答、知识库或逻辑规则相矛盾。确保大模型能够在不自相矛盾的情况下进行推理,也被称为自洽性(self-consistency)。现有大量研究表明,仅通过在大型数据集上进行训练无法保证其回答满足逻辑一致性。
我们根据一个、两个和多个命题之间应具备的逻辑关系,对各种逻辑一致性进行分类,并探讨了增强大模型逻辑一致性的不同方法及其测评指标。
1. 否定一致性(Negation Consistency)

2. 蕴涵一致性(Implication Consistency)

3. 传递一致性(Transitivity Consistency)

例如,Macaw 问答模型对 “喜鹊是鸟吗?” 和 “鸟有翅膀吗?” 这两个问题都回答 “是”,但对 “喜鹊有翅膀吗?” 却回答 “否”。根据传递性规则,前两个肯定答案可以推出 “喜鹊有翅膀”,这与对最后一个问题回答 “否” 是相互矛盾的。
4. 事实一致性(Fact consistency)
事实一致性指的是大模型生成的回答或推理结果与给定知识库(KB)的对齐程度。在事实核查(fact-checking)任务中,通过将模型的回答与可靠的知识库进行比较,来评估模型的回答是否符合知识库中给定的事实。
5. 复合一致性(Compositional consistency)
复合一致性要求大模型不仅满足以上单个逻辑一致性,还应该在组合以上简单逻辑一致性时对复合逻辑规则仍具有一致性。具体而言,当模型需要通过逻辑运算符(如蕴涵、合取等)将多种逻辑关系组合成复杂的推理链时,应确保对每个推导步骤都符合逻辑规则,并使最终结论自洽且逻辑正确。
针对以上每种逻辑一致性,我们都分别探讨了其提升方法和评测基准。下图展示了一类通用的提升大模型回答的逻辑一致性的方法框架,首先对每个问题生成多个候选回答,然后对不同问题的回答计算逻辑一致性的违背程度,最后优化求解为每个问题选择一个最优答案使逻辑一致性的违背程度降到最低。更多细节请参见我们的原文。
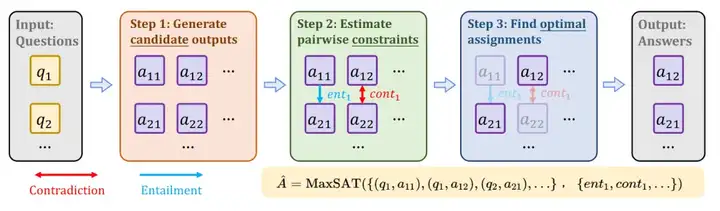
图 3:一类通用的提升大模型回答的逻辑一致性的方法框架
模态逻辑推理能力:现有方法多局限于命题逻辑与一阶逻辑,未来可考虑将大语言模型的逻辑推理能力扩展至模态逻辑以处理不确定性命题。
高阶逻辑推理:由一阶逻辑扩展得到的高阶逻辑强调对属性(即谓词)进行量化,未来可考虑训练大模型的高阶逻辑推理能力以处理更复杂的推理问题。
满足多种逻辑一致性的高效算法:目前增强逻辑一致性的方法仍存在解决的逻辑一致性单一和计算复杂度过高等问题。因此,开发能同时让大模型满足多种逻辑一致性的高效方法至关重要。
本综述系统梳理了大语言模型逻辑推理能力的研究现状。尽管在很多自然语言任务中取得了显著进展,但大语言模型的逻辑推理能力仍面临重大挑战,尤其在逻辑问答和逻辑一致性两个方面。通过建立完整的分类体系,我们对前沿研究方法进行了系统归纳和概述,并整理了用于该领域常用的公开基准数据集与评估指标,探讨了未来的重要研究方向。
文章来自于“机器之心”,作者“机器之心”。




【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
