# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当您的Agent需要规划多步骤操作以达成目标时,比如游戏策略制定或旅行安排优化等等,传统规划方法往往需要复杂的搜索算法和多轮提示,计算成本高昂且效率不佳。来自Google DeepMind和CMU的研究者提出了一个简单却非常烧脑的问题:我们是否一直在用错误的方式选择示例来引导LLM学习规划?

传统规划方法仅关注任务描述的表面相似性,而GRASE-DC通过分析行动序列的本质相似性,让AI获得前所未有的规划能力,在多种任务上实现了高达40%的准确率提升。谷歌在规划方面的研究还是很有深度的,比如《谷歌Deepmind最新 | 规划究竟属于哪种推理?用变分规划Prompt提升策略分布》。但遗憾的是,这项研究,作者并未开源代码。
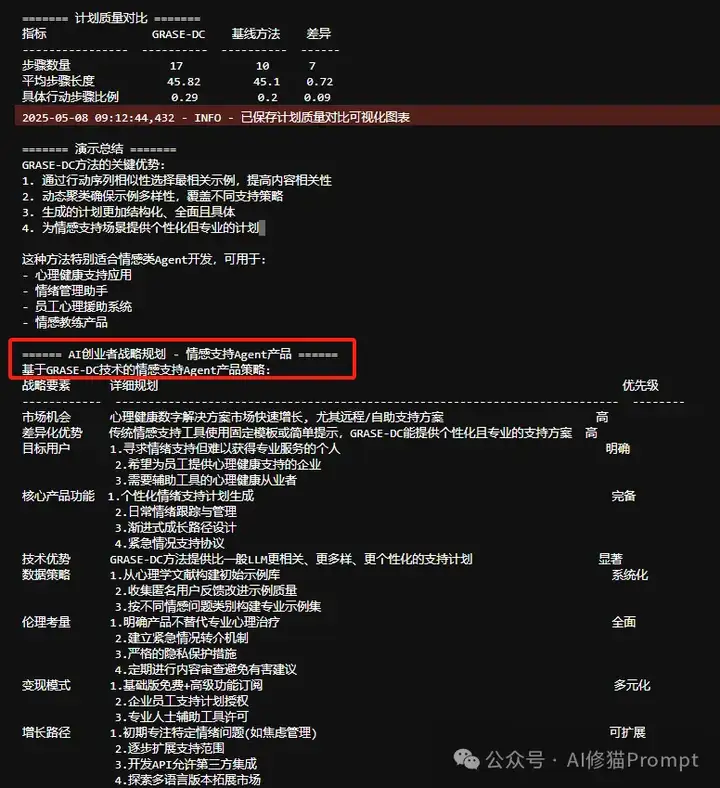
大家知道,规划是Agent非常重要的必要能力之一。我试着基于GRASE-DC写了一个情感支持的Agent。用DeepSeek-V3运行,实验结果还不错:相比传统方法,GRASE-DC生成的支持计划更全面、更具体、更有针对性,在应对"社交媒体引发的自我比较和焦虑"等现代心理挑战时表现卓越。作为一个Agent产品,Agent最终还给出了产品的简要战略规划。
传统的示例选择方法主要基于任务描述的语义相似性,这在规划任务中可能导致严重的"假阳性"问题。例如,两个描述只相差一个词的堆积木任务:"将b1放在桌子上"与"将b100放在桌子上",看似几乎相同,但实际需要的操作策略和复杂度天差地别。这种基于任务描述相似性的示例选择方法,往往会误导模型,导致规划失败或效率低下,成为限制LLM规划能力提升的隐形天花板。
研究者提出了一个全新视角:不应关注任务描述的相似性,而应关注行动序列的相似性(Action Sequence Similarity, AS)。他们设计了一种基于最长公共行动序列(LCAS)的相似度度量方法,计算两个计划中有序且连续的共同行动序列,并通过序列长度归一化。实验证明,与任务描述相似性或随机选择相比,AS能更准确地捕捉规划任务的本质,为模型提供更有价值的示例,显著提升规划性能。
基于行动序列相似性,研究者提出了GRASE-DC这一两阶段示例选择流程。
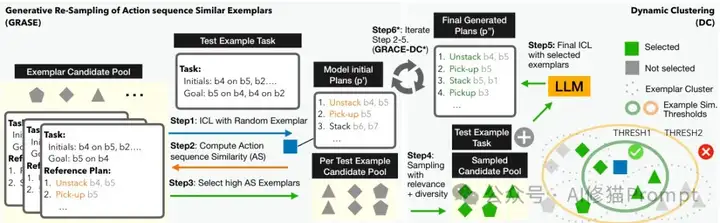
首先,GRASE(生成式行动序列相似示例重采样)阶段使用随机选择的示例让模型生成初步计划,然后,根据这个计划与候选示例之间的行动序列相似度进行重新排序和选择。其次,DC(动态聚类)阶段对高相似度示例进行聚类,确保最终选择的示例既相关又多样,通过设置相似度阈值和控制每个集群的示例数量,实现了相关性和多样性的最佳平衡。
GRASE阶段的核心在于利用模型自身生成的计划来指导更好的示例选择。对于一个测试样例,先用随机示例让模型生成初步计划p',然后将p'转换为对应的行动序列A',计算A'与每个候选示例行动序列的相似度SimAS。这种方法巧妙地利用了模型的初步理解来引导更精确的学习方向,即使初步计划不完全正确,也能捕捉到有价值的行动模式。在DC阶段,使用SimAS的倒数作为距离度量进行层次聚类,并通过设置聚类数量Nc来控制相关性(大Nc)和多样性(小Nc)的平衡,自动为每个测试样例选择不同数量的最优示例。
Prompt Templates:研究者使用了最简单的提示模板,以清晰展示示例在上下文学习中的效果。我认为很有参考价值。大家可以试试。原始提示模板为:"Please solve the problem:{task}; Your plan as plain text without formatting:{plan}; done."。对于示例,填充任务和计划部分并将它们放入上下文中。对于测试样例,填充任务并移除"...without formatting:"之后的部分。在将示例写入上下文时,研究者从相似度最高的示例开始排序。在初步研究中,研究者发现从最高相似度或最低相似度开始排序对性能影响不大。这是一个需要注意并且非常重要的点,对于以后收集或制作案例具有指导意义。
GRASE-DC的一个重要特性是其可迭代性,研究者将其表示为GRASE和GRASE-DC。通过对模型生成的计划反复应用GRASE或GRASE-DC,可以不断精炼示例集合,形成一个自我提升的学习循环。实验表明,一次迭代就能显著提升性能,比如在Blocksworld任务上,GRASE-DC*与验证器(VAL)结合后,规划准确率进一步提高了18.9%,同时减少了39%的示例数量。这种迭代方法与其他领域的自我改进技术如STaR和Self-Refine有相似之处,但独特地应用于示例选择而非直接修改模型输出。
研究者在多个经典规划任务(Blocksworld、Minigrid、Logistics、Tetris)和自然语言规划任务(行程规划)上进行了大量实验。结果表明,与随机基线相比,GRASE-DC在各任务上都实现了显著的性能提升,最高达到11-40个百分点的绝对准确率提升,同时平均减少了27.3%的示例数量。例如,在Blocksworld任务上,随机选择40个示例的准确率为37%,而GRASE-DC使用约12个示例就达到了59.3%的准确率,VAL辅助下更是达到了72.3%,这一结果充分证明了行动序列相似性在示例选择中的强大价值。
虽然GRASE-DC效果显著,但其中的AS计算和额外提示可能带来一定的计算开销。为了兼顾效率与性能,研究者提出了MLP和BPE-Proxy两种近似方法。
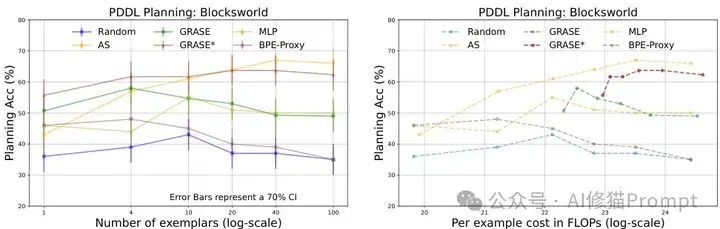
多层感知机(MLP)方法使用轻量级语言模型(如Gecko)的嵌入向量来预测AS,无需额外提示,在保持GRASE 95%性能的同时,将浮点运算量(FLOPs)减少到约66%。而BPE-Proxy更进一步,将行动视为"字符",计划视为"句子",通过字节对编码(BPE)获取常见行动子序列作为代理,虽然性能降至83%,但FLOPs仅为原来的27%,为资源受限的应用场景提供了实用选择。
研究者不仅在Gemini 1.5 Pro上验证了GRASE的有效性,还在包括GPT-4-Turbo、Claude-3.0-Opus和Llama 3.1等多种商业和开源大语言模型上进行了测试。实验表明,GRASE在所有模型上都带来了稳定的性能提升,甚至使开源的Llama-3.1-70B达到了与使用随机示例的GPT-4-Turbo相当的性能。这一结果意味着,基于行动序列相似性的示例选择方法具有强大的通用性,可以广泛应用于各种大语言模型,为开发人员提供了一种与模型无关的性能提升手段。
GRASE-DC最牛的能力之一是其在分布外(OOD)任务上的出色表现。
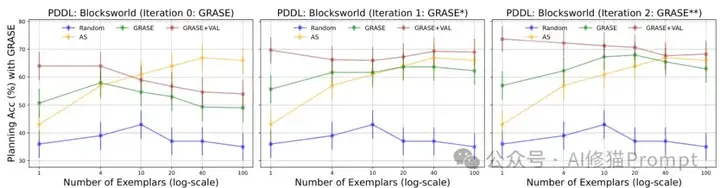
研究者设计了一个挑战性实验:使用包含3-7个积木的示例来解决包含8-20个积木的测试任务。结果表明,随机选择的示例完全无法帮助模型解决某些硬任务(如16和19个积木的问题),而GRASE-DC不仅能够解决这些任务,还在OOD测试样例上平均提升了23.3个百分点的绝对准确率。这一发现具有重要价值,表明基于行动序列相似性的示例选择方法能够帮助模型泛化到更复杂、未见过的任务场景,大大扩展了LLM规划能力的应用边界。
研究者还探索了多种计划表示方法,不仅限于简单的行动序列。他们提出了面向对象的行动序列(OAS)、基于执行的行动序列(ES)以及面向对象的基于执行的行动序列(OES)等表示方法。例如,OAS考虑每个对象的行动序列及其与特定行动的关联,而ES则分解行动为其对状态的原子变化。实验表明,除了OAS外,这些更详细的表示方法都能进一步提升性能,例如在Blocksworld上带来15-20个百分点的绝对准确率提升,为未来研究提供了广阔的探索空间。
研究中广泛采用了规划领域定义语言(Planning Domain Definition Language, PDDL)作为规划问题的标准表示方式。PDDL提供了一种结构化、形式化的语言来定义规划域和问题,包括初始状态、目标状态和可执行动作。在GRASE-DC实验中,研究者使用PDDL表示各种经典规划任务,如Blocksworld、Logistics和Tetris,确保了评估的标准化和可比性。
PDDL的优势在于其表达能力和通用性,允许用谓词逻辑精确定义动作前置条件和效果。例如,在Blocksworld任务中,"拿起"一个积木的动作可以通过PDDL定义其前置条件(积木在桌上或另一积木上且顶部无其他积木)和效果(积木被机械臂持有)。这种标准化表示使得研究者能够使用VAL(PDDL计划验证器)来客观评估生成计划的正确性,提供了可靠的性能度量。
值得注意的是,虽然PDDL是规划研究的标准语言,但大语言模型通常直接处理自然语言描述的任务和计划。如果您有兴趣也可以看下之前的一个研究《LLM做规划产生幻觉怎么破?墨尔本大学暗黑规划,无需专家的PDDL自动化管道 | 最新》GRASE-DC方法的一个创新点在于能够有效地桥接形式化的PDDL规划问题和语言模型生成的自然语言计划,通过提取和比较行动序列,实现了形式验证与自然语言生成的结合。
将GRASE-DC应用到您的Agent开发中相对简单。首先,您需要收集一个包含问题描述和对应计划的候选示例池。对于测试样例,先使用随机选择的示例让模型生成初步计划,然后计算此计划与候选示例计划的行动序列相似度(可使用最长公共子序列算法)。根据相似度重新排序候选示例,并通过层次聚类进行过滤,确保选择的示例既相关又多样。最后,使用筛选后的示例集合构建提示,引导模型生成最终计划。整个流程可以使用Python实现,关键步骤包括行动序列提取、LCAS计算、相似度排序和层次聚类,完全可以集成到现有的Agent开发框架中。
GRASE-DC的应用前景广阔,从游戏AI到实际生活规划无所不包。在游戏领域,它可以帮助您的Agent设计更高效的策略,例如在复杂战略游戏中规划多步骤操作,或在模拟环境中高效完成任务。在旅行规划领域,您的Agent可以根据用户对多个城市的访问需求,生成满足时间和交通约束的最优行程。在日历管理应用中,它可以帮助处理复杂的会议调度,在多人日程冲突中找到最佳时间段。甚至在代码生成和工作流自动化等领域,基于行动序列相似性的示例选择也有望带来性能提升,因为这些任务同样需要长序列、有依赖性的行动规划。
为了验证GRASE-DC在实际应用中的效果,如上文,我写了一个基于该方法的情感支持Agent。代码一共1182行,这个案例探索了如何将行动序列相似性方法应用于心理健康和情感支持领域,这是一个需要精确、个性化规划的复杂任务场景。您也可以看一下上一篇《南加州大学和苹果论文:用「心理支架」PB&J提升AI角色扮演能力,让Agent更懂用户》也是一项非常有价值的研究。
这个情感支持Agent是为了给用户生成个性化的情绪管理和心理健康支持计划。系统使用DeepSeek-V3模型作为基础,构建了一个包含10个不同情感支持任务的候选示例库(硬编码)将来这个部分可以用RAG,会有更好的表现,每个示例都包含特定情境下的详细支持计划。示例涵盖了从工作压力、社交焦虑到失恋痛苦等多种常见情感挑战。
Agent使用jieba分词库优化中文处理能力,同时实现了多种相似度计算方法(包括最长公共子序列和内容重叠度),以更准确地捕捉行动序列之间的相似性。
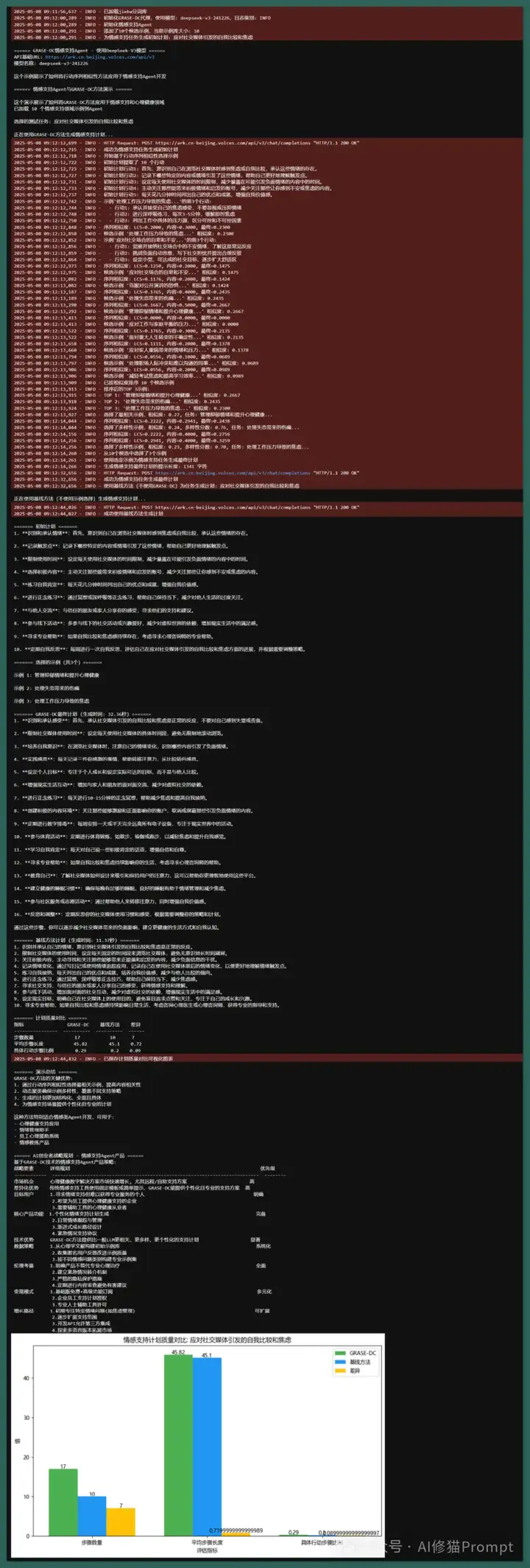
在这个演示中,我选择了"应对社交媒体引发的自我比较和焦虑"作为测试任务。系统运行的关键过程如下:
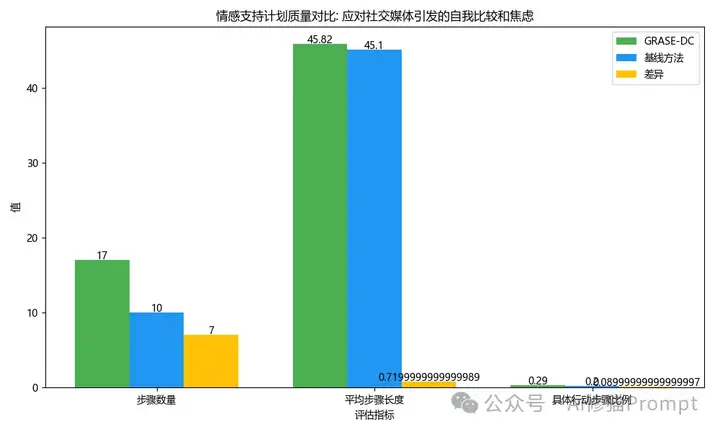
GRASE-DC方法在情感支持场景中展现出多项优势:
这种方法特别适合情感支持和心理健康领域的Agent开发,可应用于心理健康支持应用、情绪管理助手、员工心理援助系统和情感教练产品等多种场景。
基于GRASE-DC的情感支持Agent具有明确的市场机会和差异化优势。心理健康数字解决方案市场正在快速增长,尤其是远程和自助支持方案。与传统情感支持工具相比,GRASE-DC能提供更加个性化且专业的支持方案,具有显著的技术优势。
核心产品功能包括个性化情绪支持计划生成、日常情绪跟踪与管理、渐进式成长路径设计和紧急情况支持协议。数据策略方面,可从心理学文献构建初始示例库,收集匿名用户反馈改进示例质量,并按不同情感问题类别构建专业示例集。
在商业模式上,可采用基础版免费+高级功能订阅、企业员工支持计划授权和专业人士辅助工具许可等多元化策略。增长路径方面,可从特定情绪问题(如焦虑管理)起步,逐步扩展支持范围,开发API允许第三方集成,并探索多语言版本拓展市场。
相比现有方法,GRASE-DC具有多方面优势。与基于搜索的方法(如ToT和MCTS)相比,GRASE-DC无需树状结构的多轮提示,大大降低了推理成本。与传统的示例选择方法相比,它从行动序列而非任务描述角度思考相似性,避免了误导性"假阳性"。与使用外部工具的方法相比,它保持了原始ICL流程的简洁性,无需复杂的格式转换或定制工具。当然,GRASE-DC也可以与这些方法结合,例如用基于搜索的方法生成初步计划,然后用GRASE-DC选择示例进行精炼,或者将GRASE-DC与外部工具结合,进一步提升规划的正确性和效率。
行动序列相似性(AS)和GRASE-DC方法为我们提供了重新思考Agent规划能力的视角。通过关注行动的本质序列而非表面任务描述,我们可以更准确地捕捉规划任务的核心结构和相似模式。这种方法不仅提升了现有LLM的规划能力,还为构建更高效、更可靠的AI代理系统提供了坚实基础。当您下次开发需要规划能力的Agent时,不妨尝试应用行动序列相似性的视角,您可能会发现,看似复杂的规划难题,在正确示例的引导下变得异常简单。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。




【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
