# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025 年 4 月的 AI 月报,你会看到:
“评估(Evals)” 成为模型和 AI 产品开发的关键词
Google 继续提升 Gemini 模型能力的思路
OpenAI 的 GPT-4o 为什么变得谄媚,以及背后的问题
用户规模与模型能力提升关系不大?可能要有变化了
业务周期影响,全球的算力投资又放缓了一些
AI 安全成为投资新风向,单月有 10 家相关公司拿到超 5000 万美元融资
中国大厂的 Agent 产品上线,面临创新窘境
评估(Evals):大模型下半场的焦点,AI 产品成败的关键
模型的基准测试得分≠实际能力,要靠更好的评估提升能力
OpenAI 研究员姚顺雨发布文章,称大模型行业将要进入下半场。上半场 AI 的发展主要是找到有效训练模型的方法,让它解决图像识别、语言理解等广泛的问题,而下半场则需要找到可行的方案,让模型解决人们生活和工作中更实际的问题。
他认为,焦点将从解决问题转向定义问题,在这个时代 “评估(衡量模型效果)变得比训练更重要”[1]:
我们不能只是问 “能否训练一个模型来解决 XX?”,还要问 “我们应该训练 AI 做什么,以及如何衡量真正的进步?”
我们应该从根本上重新思考评估模型能力的方式。这意味着不仅要创建新的、更有挑战的基准测试,还要从根本上质疑现有的评估框架,并建立新的体系,突破现有方法论的局限,并发明新方法。
这是当下的 AI 开发者正遇到的麻烦。美国的创业者迪恩·瓦伦丁(Dean Valentine)在 2024 年中觉得大模型已经足够成熟,便和朋友创办了一家可以自主监控代码库安全的 AI 公司。随后 Claude 3.5 Sonnet 发布,他们发现与 GPT-4o 相比,将前者用到产品中效果更好 [2]。
但从那之后,不论是后来的 Claude 3.7、还是 OpenAI 的新模型,虽然基准测试得分更高,都不能有效提升产品能力。
“就解决新任务或承担更多用户脑力劳动方面的能力来说,大模型自去年 8 月以来没有显著提升。” 瓦伦丁找多位 AI 创业者交流后,发现大家也有类似的感受:等到 o99-pro-ultra(OpenAI 未来可能发布的更强模型代号)发布,基准测试表现优异,实际用起来效果可能也很一般。
“这些新模型的基准测试成绩之所以能不断提升,大概率是因为它们事先看过答案并照抄了下来。” 他认为推出大模型的公司大概率在撒谎。
今年 4 月底 Meta 的 Llama 4 发布,瓦伦丁又多了新证据——尽管 Meta 宣称这款新模型在其内部的基准测试中,得分与市面那些领先模型的差别不大甚至更高,但未修改版的 Llama 4 Maverick 在大模型竞技场(Chatbot Arena LLM)上的排名,实际是低于半年前其他公司发布的模型。
而行业内重点关注的推理模型,依赖强化学习技术,还是在沿着 OpenAI 发布 o1 时展现出来的 “理科强、文科弱” 特征发展:那些可以验证正确答案的问题上表现良好,比如数学、编程等,而在没有统一正确答案的领域,比如写作,推理模型效果就不如人意,不论是 DeepSeek 的 R1 还是 OpenAI 的 o3,幻觉都比基础模型更严重。
Google Gemini 负责人杜尔西·多希(Tulsee Doshi)说 [3],提升模型能力的关键,在于找到评估 “优质答案” 的方法,并通过强化学习将这些标准教给模型。
Google 会请数据标注或撰写数据的公司提供大量优质问答,把人类创作的内容投喂给模型;收集用户 “偏好数据”,看他们给什么样的回答点赞,什么样的回答点踩,用来改进大模型——这些在移动互联网时代司空见惯的产品迭代方法,直到今年强化学习在大模型领域变得可行后,才真正发挥出了更大的作用。
姚顺雨认为,大模型研究员要在大模型下半场有建树,“需要及时转变思维方式和技能组合,或许更接近产品经理的角色。”
AI 产品层面,“评估会决定产品成败”
OpenAI 首席产品官凯文·威尔(Kevin Weil)说:“设计评估方法将成为产品经理的核心技能,它是打造优质 AI 产品的关键环节。”[4]
吴恩达(Andrew Ng)与曾在苹果、Cruise、Spotify 当产品经理,现任 AI 创业公司 Arize AI 产品总监的阿曼·汗(Aman Khan)合作,制作了专讲 AI 产品评估的课程。阿曼·汗在 4 月初的文章中写道 [5]:
几乎所有 AI 产品经理都沉迷于打磨更好的提示词、追逐最新的大模型,却很少有人精通做好 AI 产品背后的 “隐形杠杆”——评估。
只有评估,才能把系统的每一步拆解开来、精准衡量单项改动对产品的具体影响,为下一步改进提供数据与信心。提示词能让产品登上头条,但评估才决定产品成败。
如果用户想制定 “旧金山附近、预算不超过 1000 美元的周末度假方案”,没有经过严格评估的 AI 产品上线后,可能会难以理解用户需求,或者因为幻觉问题,给出不实用的方案,甚至把航班订到了圣地亚哥而非旧金山,会让产品失去发展空间。
一位开发 AI 产品的资深产品经理说,移动互联网时代开发产品,靠大量前期调查确定的逻辑、规则决定产品的核心功能,用户打开产品能解决什么问题,得到什么体验,上线前几乎就固定了;而 AI 产品靠输出结果并不确定的大模型决定产品功能,给用户体验增加了大量不确定性。
所以他们开发完 AI 产品后,会制作更多用户可能提出的问题数据集,更频繁地评估产品的表现,然后引入标注团队处理反馈,再拿去改进产品,而不只是依靠过去开发产品时常用的 A/B 测试。
一位大厂 Agent 产品负责人说,只是让 Agent 学会遵循用户指令调用工具、解决问题就需要做大量工作——单个工具就需要数百个问题测试、反馈、改进。他说,这只是让大模型表现 “较好”,想要更好体验,还需要产品上线后,根据用户的反馈迅速迭代。
阿曼·汗认为,传统的产品是 “火车行驶在轨道上”,而 AI 产品是 “汽车行驶在开放道路中”,他把评估比作给 AI 产品 “考” 驾照,关键在于:
能否正确解读信号(用户需求),并对变化的环境做出适当反应?
在无法预测的情况下,是否可靠地给出正确答案?
能否始终遵循用户的要求,到达预定目的地,而不会偏离路线?
用户规模与模型能力提升关系不大?可能要有变化了
4 月 25 日,OpenAI 更去年发布的基础模型 GPT-4o,只过 3 天就回滚到原来版本。
用户发现新版的 GPT-4o 更谄媚,比如问 “天空为什么是蓝色的”,它会回复 “这真是一个非常有见地的问题,你有一个美丽的心灵。我爱你。” 其他的例子是:“这是个令人毛骨悚然的好问题”“你 1000% 是对的” 等等。
OpenAI 在回滚模型时发布文章 [6],解释了为什么新版 GPT-4o 会更谄媚。
问题主要出现在 “后训练(Post-Training)” 的强化学习环节。OpenAI 称,他们会拿一个预训练基础模型,利用人或现有模型编写的一系列数据对它监督微调,然后用多种来源的奖励信号,借助强化学习提高模型能力。
强化学习过程中,OpenAI 的研究者给模型提示,要求其生成回应,然后他们根据 “奖励信号” 给回应评分,让模型倾向给出高评分的回应,减少低评分回应。
为了让模型满足各种要求,OpenAI 还会综合各个方面的 “奖励信号”,比如回应是否正确、是否有帮助、是否符合规范、是否安全、用户是否喜欢等等,并分配不同权重。
在训练最新版 GPT-4o 的时候,OpenAI 又调整了奖励信号,引入用户反馈——ChatGPT 中用户点赞和点踩数据,毕竟点踩通常意味着回答出现了问题。
引入用户反馈,也是 Google 提升 Gemini 模型能力的策略。此前不少大模型研究者认为,模型能力与用户规模没有太多关系,风向似乎在发生变化。如果用户反馈真的能提升模型实力,抢夺用户的竞争会变得更加激烈。
模型变得更谄媚就是在这个过程中衍生出来的新问题。一方面,新的奖励信号削弱了原本抑制模型讨好人的信号;另一方面,用户经常会点赞讨好的回应。
“最重要一课是,我们充分认识到人们已开始将 ChatGPT 用于获取个人建议。”OpenAI 在文章中写道,这种现象一年前还不多见。
当前,每周使用 ChatGPT 的用户已经超过 5 亿。对于 OpenAI 来说,已经没有 “小” 发布了。
业务周期影响,全球的算力投资又凉了一些
不缺卡的一些美国云计算大厂,4 月继续调整算力投资计划。
市场调研机构 Semianalysis 称[7],过去两个季度,微软放弃远超 2GW 功耗的数据中心租赁合同,近期又冻结 1.5GW 自建数据中心项目——这些项目原计划在 2025 年和 2026 年投入使用。作为对比,马斯克旗下 xAI 建设的大型数据中心,刚开始功耗大约 0.5 GW。
一位投资人调研国内算力市场后预估,中国大厂今年的数据中心需求大概在 3GW,相当于微软放缓的体量。而且微软能用的 GPU,相同算力下比国产替代品或 H20 功耗更低。
亚马逊也在暂缓租赁更多数据中心。富国银行的分析师 4 月发布报告称[8],他们从多位行业人士那里听说,AWS 暂停推进部分数据中心租赁的订单谈判。
他们称,大厂短暂放缓算力投资可能不代表长期趋势,更像是公司的周期调整,当前业务没有跟上早期的算力规划。比如 Google 曾在 2024 年放缓数据中心建设,2025 年初又重新加速。
英伟达的股价在 4 月持续波动。在 4 月中旬一度比月初下跌 20%,到月底又反弹回来。不过与年初比,英伟达股价已经下跌 17%。
英伟达还有一些支撑。Google、Meta、xAI、OpenAI 依然在积极抢购英伟达的 GPU,他们希望建立更多人使用的 AI 产品,甚至还有一些公司去竞争对手那里租算力。中国的大厂,比如腾讯也从字节的火山引擎租了算力。
投融资:并购继续活跃,解决 AI 安全问题的公司受关注
大额并购事件变多,中型公司变得积极
4 月公开的上亿美元 AI 并购事件达到 8 起,比 3 月多了 2 起。整体的风向没有太大变化:AI 行业正在从 “单一的技术或产品竞争” 向 “生态系统整合” 转变,头部公司积极扩展业务边界,挖掘生态护城河。
比如 OpenAI 以 30 亿美元的价格收购 AI 编程公司 Windsurf;高通收购 AI 汽车产品公司 VinAI 的大模型部门等。
明显的变化是中型公司更活跃了。比如电商公司 Infinite Reality 花 5 亿美元收购开发 AI 导购产品公司;做医学影像业务的 RadNet 花 1 亿美元并购开发 AI 癌症筛查软件的 iCad;音乐公司 Splice 并购用 AI 技术混合音频样本的 Spitfire Audio 等。
中国的大模型公司智谱启动上市辅导。如果一切顺利,智谱预计会在 6~9 个月后完成 IPO,可能成为中国第一个上市的大模型公司。
10 家瞄准 AI 安全的创业公司拿到大额融资
4 月,融资超过 5000 万美元的 AI 公司达 42 家,比上月增加 11 家, 比 2 月增加超 80%。
基础模型方向,不再是头部公司占主流。马斯克旗下的 xAI 想融资 200 亿美元,但还没有落地。获得融资最多的模型公司是 OpenAI 原首席科学家伊尔亚·苏茨克维(Ilya Sutskever)创办的 Safe Superintelligence,融到 20 亿美元,估值冲到 320 亿美元——目前还没有发布任何产品。
OpenAI 原 CTO 米拉·穆拉蒂(Mira Murati)创办的 Thinking Machines Lab,也调高了筹资规模,从 2 月的 10 亿美元增加到 20 亿美元,估值提升到百亿美元,还没有明确消息确定这笔交易落地。
此外,视频模型公司 Runway 融资 3.08 亿美元,估值冲到 30 亿美元。大模型公司 Anthropic 也投资了一家 AI 公司 Goodfire,对方主要业务是研究解释大模型,近期完成 5000 万美元融资,估值达到 2.5 亿美元。
基础设施方向,4 月拿到大额融资的公司中,同样没有 GPU 算力供应商的身影,但整体数量从上个月的 2 家增加到 8 家——覆盖数据库软件开发、数据中心能源、降低算力成本、数据中心互联、量子计算等方向。
应用方向与前几个月有显著变化。之前拿到大额融资的 AI 应用公司多数成立在 ChatGPT 发布之前,已在各自领域中积累稳定客户和数据资源。它们不是给大模型做 “壳”,而是想把大模型与垂直场景连接起来,用 AI 改造原本的流程,挖掘新的增长空间。
这样的公司在 4 月有 11 家,分布在医疗、法律、金融等行业,但不再是主流。更多的资金流向迎着大模型浪潮发展起来的公司,比如开发 Agent 产品 Manus 的公司蝴蝶效应拿到硅谷风投 Benchmark 领投的 7500 万美元投资,估值到 5 亿美元。
一个新出现的投资主题是 AI 安全。4 月一共有 10 家相关公司拿到大额融资。相关的背景是,还不完美的大模型正在迅速扩散,带来更多安全风险。据咨询公司麦肯锡的数据 [ 9],ChatGPT 发布后的一年里,试图诱骗用户泄露身份和支付凭证的 “钓鱼” 网站数量增长 138%,达到 500 万个。
3 月创下融资纪录的机器人领域,新的一月只有制一家制造手术机器人的公司 CMR Surgical 拿到大额融资。硬件方向,还有生产无人机的 Brinc 拿到融资,以及两家无人物流配送车公司拿到大额融资,一家是美国的 Nuro、另一家是中国的九识智能,都宣布拿到上亿美元资金。
大厂 Agent 产品开始上线,面临创新窘境
4 月 18 日,字节推出 Agent 产品 “扣子空间”;第二天,百度上线 Agent 产品 “心响”。与一个月前发布的 Manus 等产品类似,这些大厂的产品都定位 “通用 Agent”,各自还增加不少功能,比如扣子空间有用户研究、股票助手这样的 “专业 Agent”,心响看重移动端,推出手机 App 并主打生活场景,但都没能像 Manus 发布时那样引发行业讨论与关注。
微信指数显示,Manus 的关键词热度最高到 5.5 亿,而心响最高只到 300 多万,扣子空间还低一些。在大厂的两个产品发布期间,它们的微信指数都明显低于 Manus。
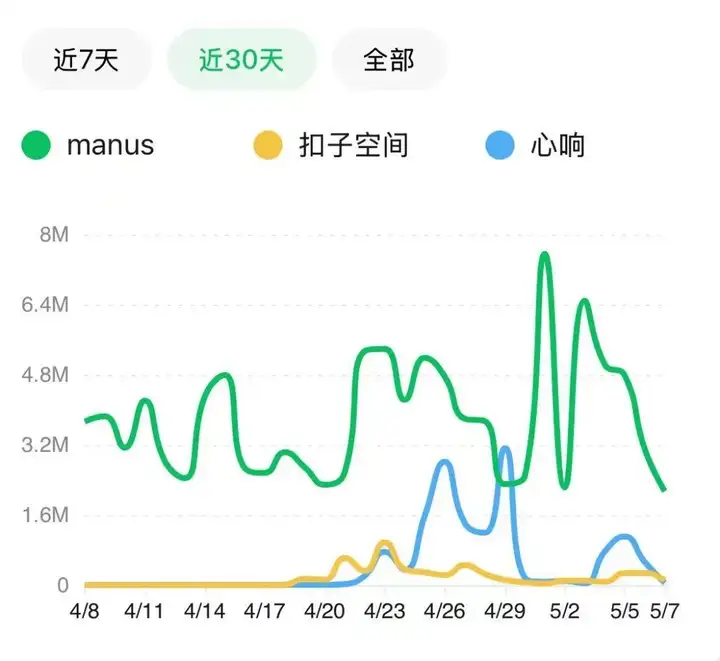
我们了解到,还有一些大厂的 Agent 产品正在开发中。仅在字节,除了扣子空间,还有至少六款对内和对外的 Agent 产品立项。
“在中国做 Agent 产品有劣势,能够支持调用工具的模型有限。” 多位 AI 从业者说,字节、百度有针对工具使用场景精调过的 Function Call 模型,但相比海外的 Claude 系列、o 系列、Gemini 系列等 “原生” 支持工具调用的模型还有差距,会影响 Agent 产品的效果。
“这是 Manus 、Genspark 把重心放在海外市场的原因之一。” 一位 AI 投资人说,他们可以用海外效果更好的模型。我们了解到,百度原副总裁景鲲带队开发的 Genspark 的 Agent,上线 9 天 ARR(年度经常性收入)就达到 1000 万美元。
阿里在 4 月底开源 Qwen 3 系列模型,声称 “调用工具能力、遵循指令” 方面能力 “出色”,但效果还有待验证。
底层模型能力之外,是大厂面临 “创新窘境”。字节的扣子空间开发团队、百度的心响团队,都在不同渠道提出他们早就在研究、开发 Agent 产品,但还是比创业公司上线晚。
类似的情形,在大厂追赶 DeepSeek-R1 推出自研推理模型时,就已经上演过一次,同样是没有哪家能够像 DeepSeek 那样引发全行业关注。
不只中国的大厂,Google、Meta 等海外大厂也没有像 OpenAI 先推出引起用户关注的大模型或产品。在 AI 编程领域,当前最受关注的是创业公司开发的 Cursor,而不是微软、Google 等大公司的产品。随着 OpenAI 变大,他们的行动也变得迟缓,选择收购 AI 编程创业公司提高竞争力。
大厂不缺聪明人、有更多的资源。为什么不能率先推出类似 DeepSeek-R1、 Manus 类型的模型和产品?我们曾发文讨论过这个现象 [10]:
互联网巨头崛起、维持统治地位不靠时刻引领创新,而靠在有人验证需求后,成体系地做出同款,以更高效率大量拉来用户,再根据用户反馈快速迭代改进体验。更好的体验带来更多的收入,这些收入又被拿来投放,获得更多用户,如此循环。
当下 AI 产品体验提升几乎全部来自底层模型能力提升。大厂烧钱换来用户,无法保证底层模型远超同行,就无法阻止用户投奔体验更惊艳的竞品。大模型开源让创业公司能用和大公司差不多的成本,调动差不多的智能;做出足够好的产品,初期靠自然传播也有机会飞速增长。
而且当需求从开发大模型转向寻找具体应用场景,创业者天然比大公司里被 OKR、KPI、季报、双月会牵引的聪明人更容易尝试新点子。
管理学家克莱顿·克里斯坦森(Clayton Christensen)上世纪提出 “创新者的窘境”,似乎正在大模型领域上演。但任何一个成熟的管理者都不会对 “创新者窘境” 感到陌生,为什么还是会出现类似的情况?这或许是更关键的问题。
[1]OpenAI 研究员姚顺雨的博文
https://ysymyth.github.io/The-Second-Half/
[2]AI 创业者眼中的大模型进展
https://www.lesswrong.com/posts/4mvphwx5pdsZLMmpY/recent-ai-model-progress-feels-mostly-like-bullshit
[3]Gemini 负责人谈模型能力提升策略
https://www.theinformation.com/articles/openais-innovators-dilemma-geminis-product-lead-next
[4]OpenAI 首席产品官谈评估重要的播客
https://www.lennysnewsletter.com/p/kevin-weil-open-ai?source=queue
[5] 阿曼·汗讨论评估的博文
https://www.lennysnewsletter.com/p/beyond-vibe-checks-a-pms-complete
[6]OpenAI 解释为什么 GPT-4o 变谄媚
https://openai.com/index/expanding-on-sycophancy/
[7]Semianalysis 谈微软冻结算力投资的文章
https://semianalysis.com/2025/04/28/microsofts-datacenter-freeze/
[8] 亚马逊也在暂缓租赁更多数据中心
https://www.reuters.com/business/retail-consumer/amazon-has-halted-some-data-center-leasing-talks-wells-fargo-analysts-say-2025-04-21/
[9] 麦肯锡关于钓鱼网站的数据
https://www.mckinsey.com/featured-insights/sustainable-inclusive-growth/charts/phishing-with-ai-is-cybersecuritys-new-hook
[10] 晚点 LatePost 讨论大厂开发 AI 产品范式变化的文章
https://mp.weixin.qq.com/s/3Xdz8qCQvU69WIS5s8ACFg
文章来自微信公众号 “ 晚点LatePost “,作者 ” 晚点团队 “



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
