# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今夜,谷歌彻底杀疯!2小时发布会,Gemini提及95次点亮全场。Gemini 2.5家族全系升级,Pro深度思考模型正刷榜。全新Imagen 4生成细节超逼真,Veo 3首次实现音视频融合。
谷歌一出手,就是王炸。
刚刚,谷歌I/O 2025大会上,劈柴登场一张图亮出了自家所有旗舰模型。一年时间跨度,可以用马不停蹄来形容。
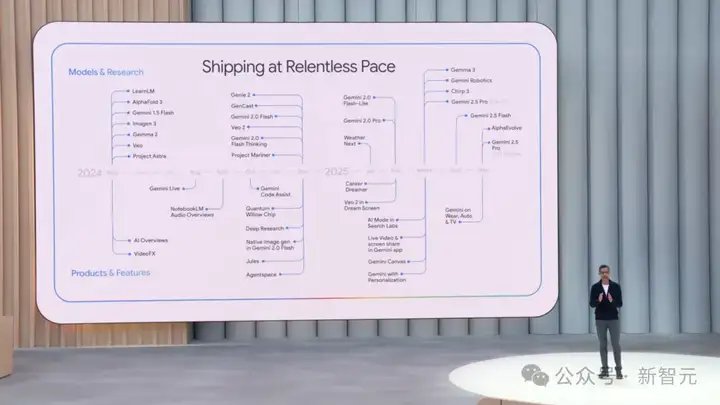
这一次,Gemini 2.5深夜迎来三连更:
· Gemini 2.5 Pro(新):再次刷榜LMArena,ELO拿下1448分,所有类别第一,碾压o3,原生文本到音频生成
· Gemini 2.5 Pro(Deep Think):刷榜数学、编码、多模态榜单,
· Gemini 2.5 Flash(新):排名仅次Gemini 2.5 Pro,ELO得分1424,原生文本到音频生成

备受期待的Imagen 4、Veo 3也在今天登场。Imagen 4生图细节逆天,10倍提速;Veo 3首次支持原生音频输出,开启音视频融合新时代。

Veo 3逼真地生成了老人声音,以及背景中的海洋声音
此外,大会上还亮相了全新文本扩散模型Gemini Diffusion、AI搜索AI Mode、全新Flow创意平台......
谷歌推出了史上最贵的订阅服务——Google AI Ultra,高达250美元(比ChatGPT Pro贵50美元)。
堪称VIP中的VIP,可无限访问最新模型。

Pro每个月20美元,开通后可同时使用Gemini 2.5 Pro、Veo 2和NotebookLM等
更让人没想到的,谷歌掏出了两款全新硬件:Project Moohan头显和XR眼镜,由Gemini加持,将革新空间计算。

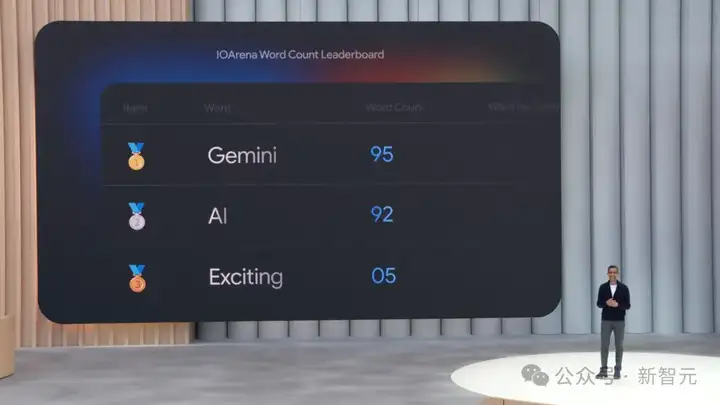
2小时发布会,全程共提到Gemini 95次,AI 92次。
Gemini 2.5更新,必然是整场大会的重点。
Demis Hassabis一出场激动地表示,「AI正在开启一个令人惊叹的全新未来」。
Gemini 2.5 Pro登顶,编码能力暴涨
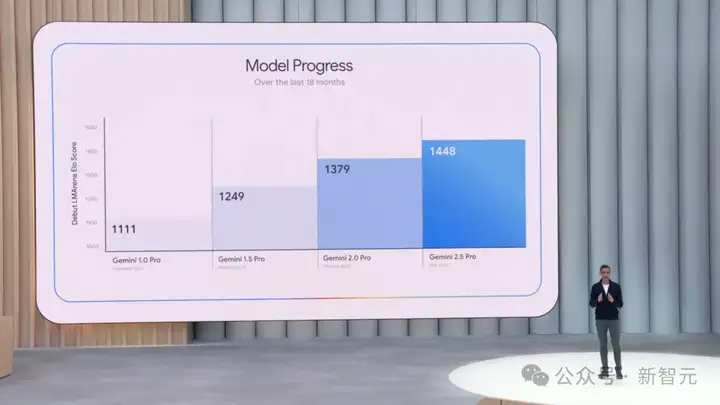
Gemini 2.5 Pro在3月首次亮相后,成为谷歌目前有史以来最智能的一款旗舰模型。
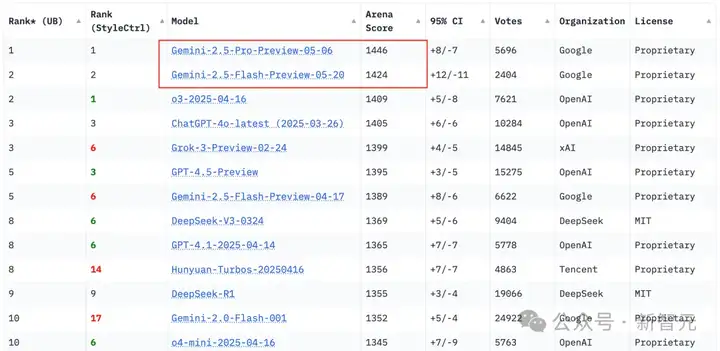
两周前,Gemini 2.5 Pro Preview版本首次更新后,便在LMArena排行榜中登顶。
其中,在WebDev Arena排行榜中拿下1415分,相较于3月版提升了142分。

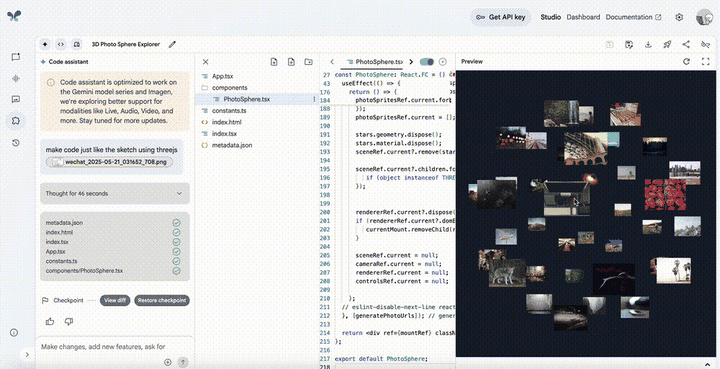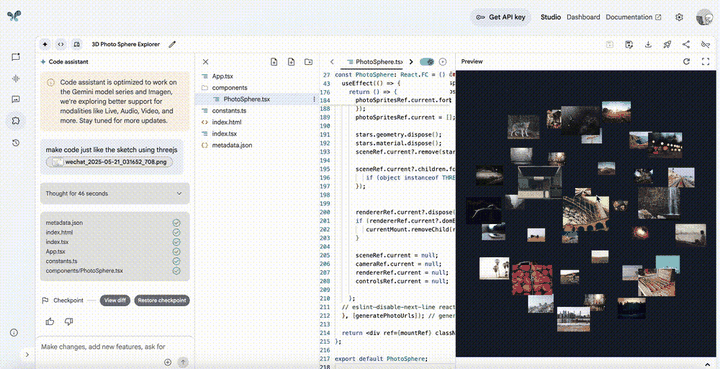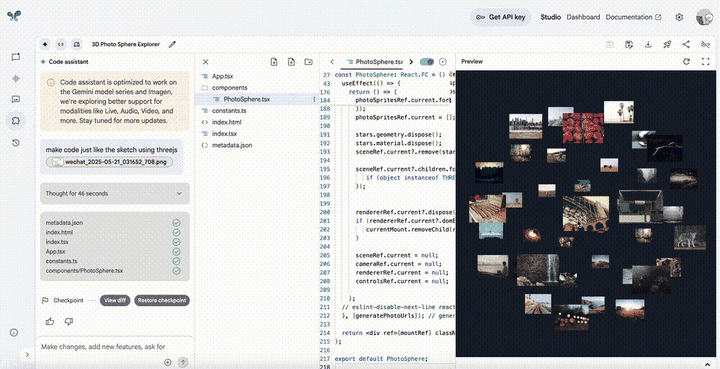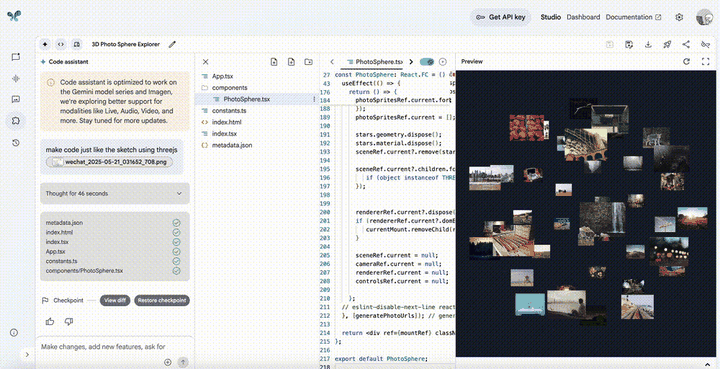
在大会中,女主持人现场演示了在AI Stuido中只需要上传一张手画草稿,即可在几十秒内生成和需求描述完全一致的页面效果。
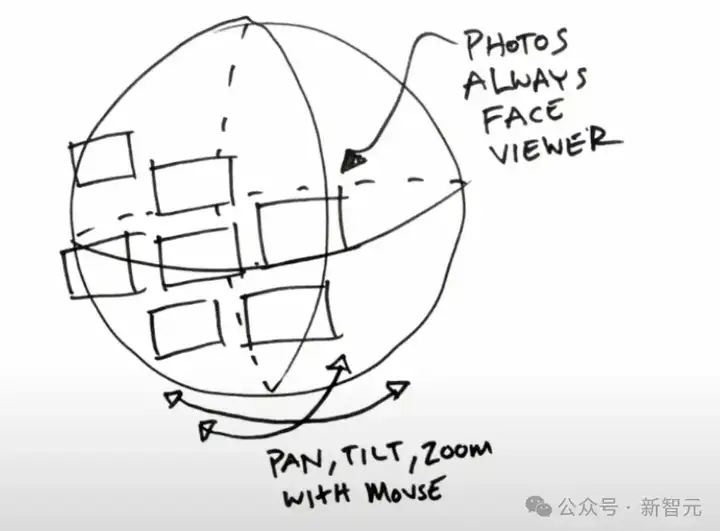
比如,生成可旋转的3D照片墙,上述图片描述了这个页面的基本结构,包括照片始终朝向观察者、可以放大和缩小。
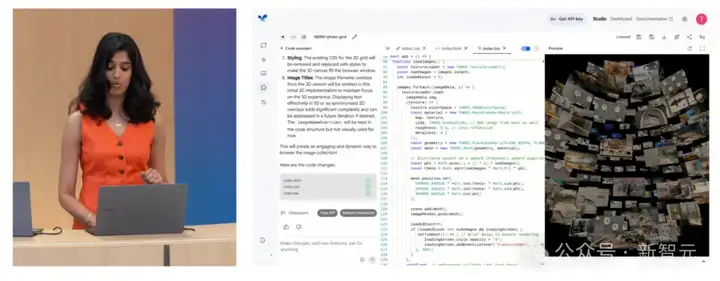
而我们使用了I/O大会中的相同命令,只花了几十秒就实现了和演示几乎一模一样的3D页面旋转效果。
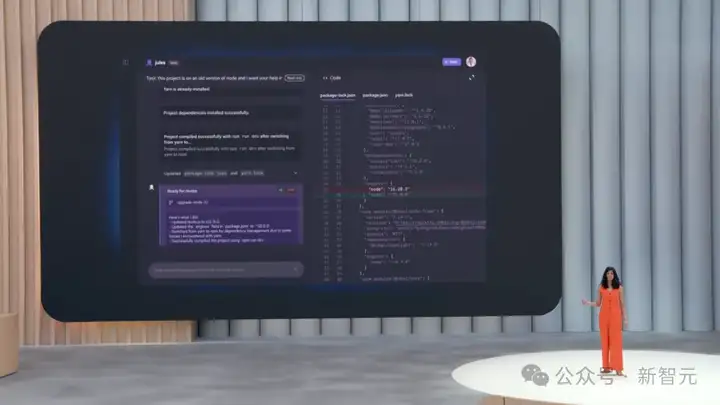
现在,所有人皆可在AI编码智能体平台Jules,体验全新Gemini 2.5 Pro,一个提示即可帮你处理任何任务。
此外,凭借100万token上下文,2.5 Pro具备领先的长上下文和视频理解能力。
Gemini 2.5 Flash全面升级,立省30%
Gemini 2.5 Flash这次也得到了全面升级,生成速度更快、成本更低。
在LMArena拿下1424高分,仅次于2.5 Pro。

在推理、多模态、代码、长上下文的关键基准上,2.5 Flash性能进一步提升。评估中,使用的token减少了20%-30%。
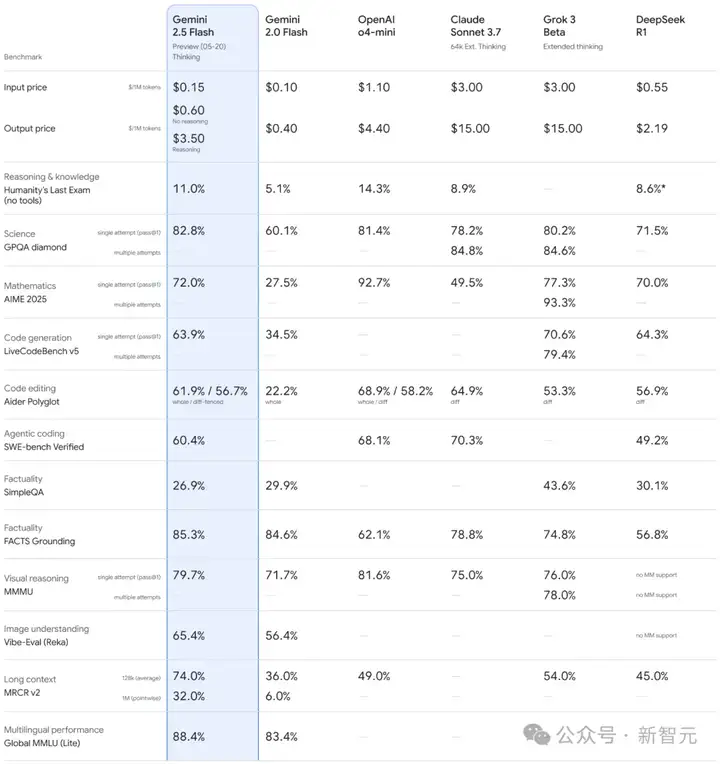
这两款迭代后的模型,支持更多新功能:

· 原生音频输出
就像原生音频对话一样,2.5 Flash和2.5 Pro最新文本转语音极具丰富的表现力,可以捕捉到非常微妙的细节,比如窃窃私语。
它支持超过 24 种语言,并且可以无缝切换,已在Gemini API上线。

· 思考预算
2.5 Pro将支持思考预算功能,让回答更加安全、高效。任何人可以开启/关闭思考模型,设置固定的思考预算。

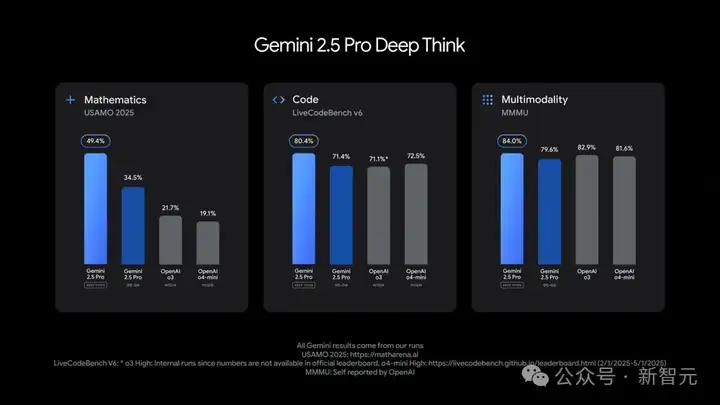
Deep Think制霸数学编码多模态
这次,Gemini 2.5系列迎来了全新成员——2.5 Pro(Deep Think)。
它采用了全新的技术,能够在响应之前考虑多个假设。

2.5 Pro深度思考版在数学、编码、多模态榜单上,刷新了SOTA。
具体来说,在2025 USAMO数学奥赛中(最难数学基准之一),取得了40.4%高分,比2.5 Pro高出了10%多。
在LiveCodeBench上,一举攻克竞赛级编程难题,拿下80.4%分。而且,在多模态推理MMMU上取得了84.0%。
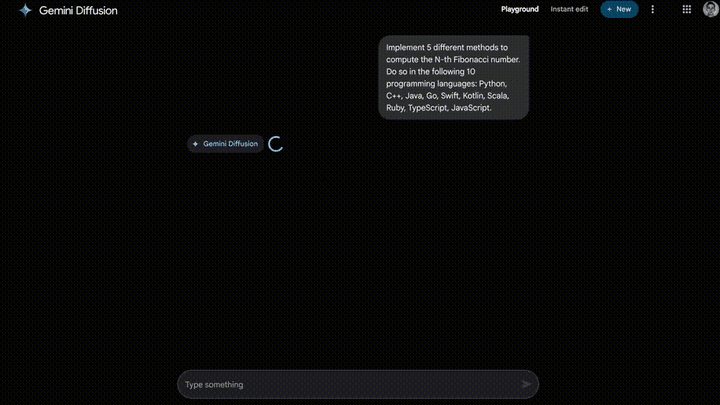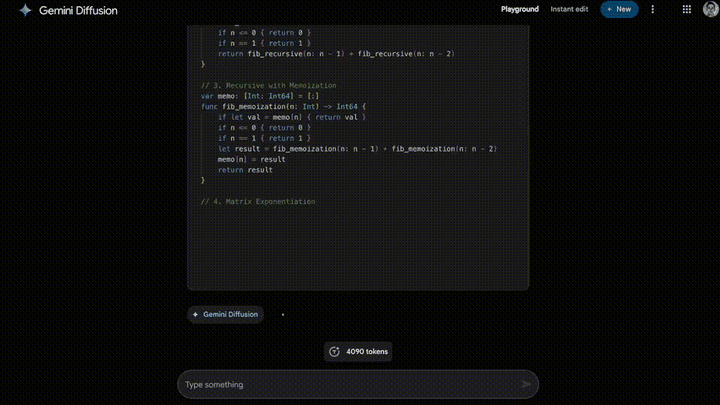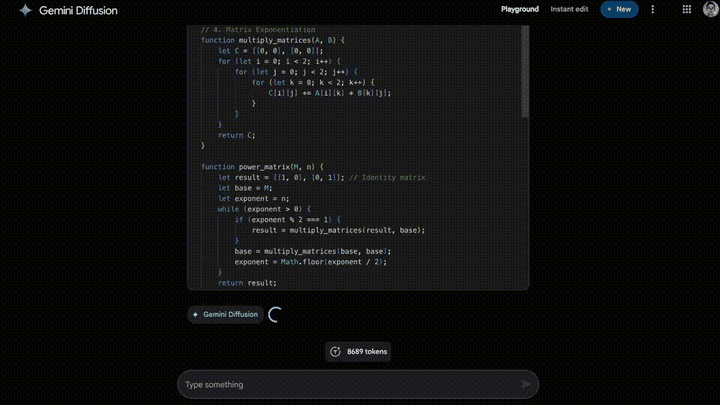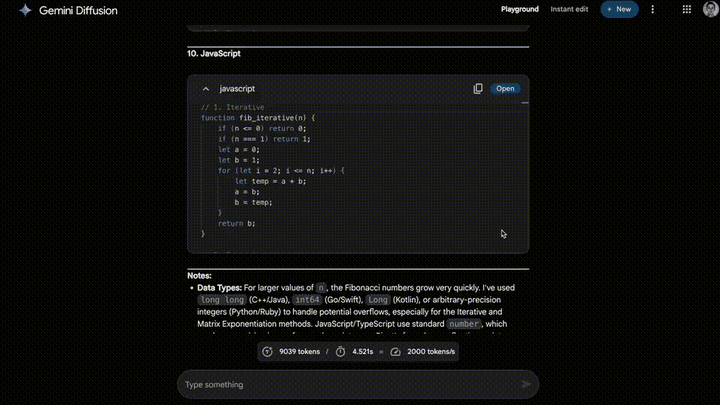
Gemini Diffusion:全新文本扩散模型
此外,谷歌还带了全新文本扩散模型Gemini Diffusion,让模型更加擅长处理编辑任务。
与直接预测文本不同,它通过逐步优化噪声来生成输出。
这种方法,让Gemini Diffusion能快速迭代优化解决方案,在编程和数学领域表现尤为出色。

Gemini Diffusion每秒输出1000多个token,性能要比Gemini 2.0 Flash-Lite快5倍。
就拿如下例子来说,眨眼之间,就错过了解题过程。
Gemini系列模型更新之后,Hassabis再次回顾了过去十年,谷歌为当前AI时代奠定基础的技术几点。
从Transfromer、到AlphaGo、Alpha Zero等,谷歌不断创造通往AGI所需的下一个重大的突破。
Gemini已经成为当今最好的多模态基础模型,未来还将不断扩展其能力,最终成为一个「世界模型」。
Hassabis称,这是我一直热衷的事情,AI系统需要世界模型才能有效运行。

而Gemini robotics是世界模型,进入现实世界的一个载体。
此外,让Gemini成为世界模型的另一个关键是,真正对人类日常生活有所帮助。
这也是谷歌Project Astra的最终愿景,在现场演示中,AI助手全程保姆级指导如何组装自行车,甚至被打断也不会有所影响。

AI在加速科学发现上,谷歌也取得了引以为傲的成就,AlphaEvolve、AlphaFold、AIME、Isomorphic Labs。
在最新案例中,谷歌Astra联手Ira公司,帮助盲人在生活中更加独立。
这次年度开发者大会,更少不了AI图像模型和AI视频模型的更新。
Imagen 4:超逼真生图,完美拼写2k画质
历时半年多,谷歌AI图像生成模型终于迭代到了Imagen 4。

在细节表现方面,Imagen 4能够生成复杂的织物、水滴,甚至是动物毛发,逼真度足以让人惊掉下巴。
而且,分辨率最高可达2k。





此外,Imagen 4在拼写、版式方面得到了改进,制作贺卡、海报、漫画,全部拿捏。




在生成速度方面,Imagen 4同样堪称极致——最多比上一代Imagen 3快10倍。

Veo 3:原生音视频融合,对话BGM一次搞定
谷歌AI视频模型Veo 3,也在万众期待中震撼登场。
用发布会大佬的话来说,「我们正在进入一个音频和视频相结合的创作新时代」。
Veo 3不仅在生成质量上超越了Veo 2,而且首次能够生成带有音频的视频。

不论是城市街道中嘈杂音,还是公园里的鸟鸣声,甚至是角色之间的对话,它都能一键还原。
森林中,一只猫头鹰和一只小獾的对话,动画感爆棚。

全面来看,Veo 3 在文本/图像生成提示、真实物理模拟和精准口型同步等各方面都表现出色。
它的理解能力超强,只需在提示词里描述一个小故事,模型就能生成一段生动还原剧情的视频。
Flow:好莱坞电影,随手即来
此外,谷歌还推出了一款专为创意人士打造的新平台Flow,一款AI电影制作工具。
它集成了Veo、Imagen、Gemini最新模型,无缝创建电影片段、场景、故事。
自然对话描述镜头,Flow就能编织出令人惊叹的场景。

谷歌重磅推出了AI Mode搜索功能,开启谷歌搜索全新纪元!
AI Mode将搜索与AI深度集成,谷歌开发了专用于Search的Gemini 2.5模型。

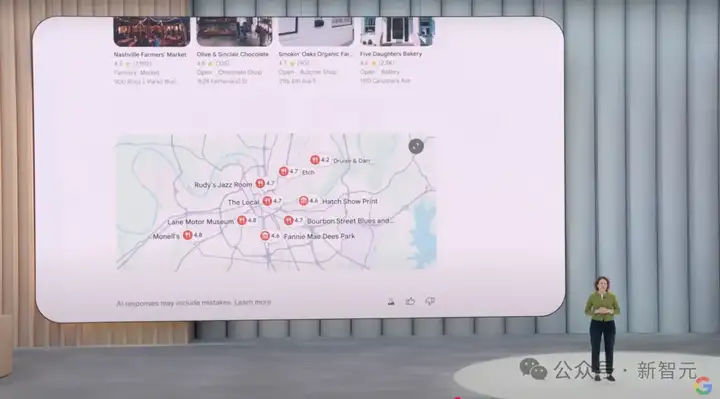
AI Mode是全能的,相比过去的「传统搜索」,AI Mode会根据回复自动规划搜索结果的展现形式,包括文本、视频,甚至地图等等,AI Mode都可以完美展现。
AI Mode目前位于谷歌搜索一级菜单的第一位,可见谷歌对于AI Mode的重视程度。
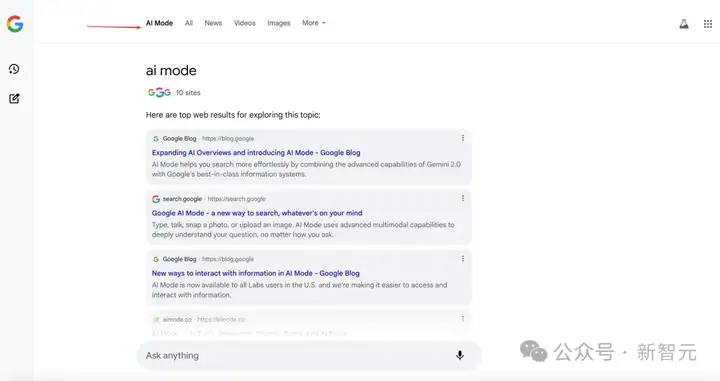
目前该功能暂时只支持英语地区,聊天语言也要使用英语。
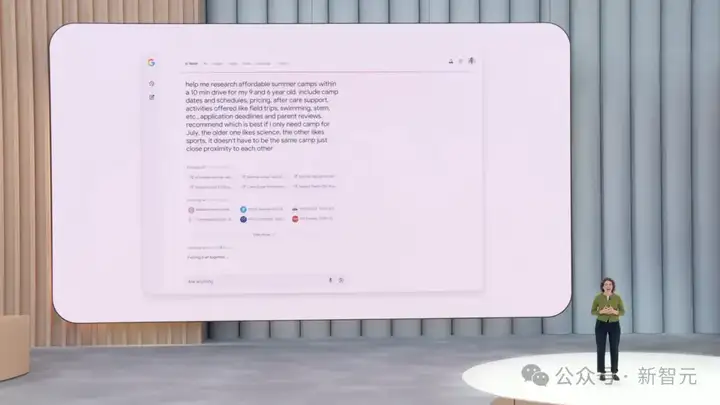
AI Mode的强大之处在于,你可以提问一个非常复杂,包含诸多信息的问题,比如:
展示本赛季和上个赛季使用鱼雷棒(最新款的比赛用棒球棒)的著名球员的击球率和上垒率。
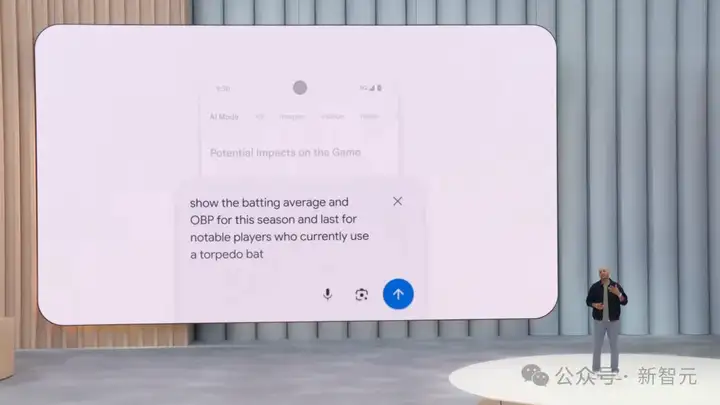
这个问题涉及到信息的定位以及计算概率,AI Mode智能的使用了表格和图表来回答。

Google Lens
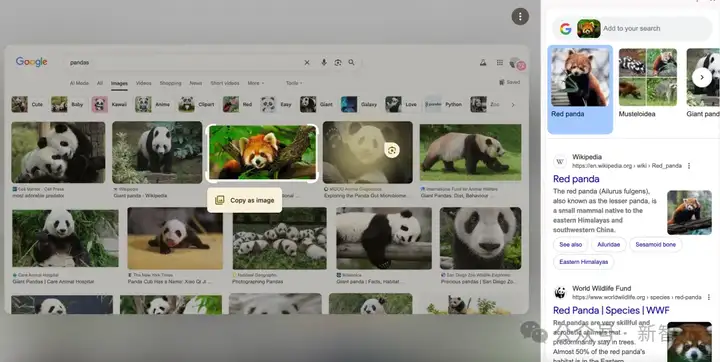
大会中,还提到了Google Lens,用AI的能力帮助搜索各种图片和信息。

Google Lens可以框选页面中的任何信息,框选后答案会自动弹出。
智能购物
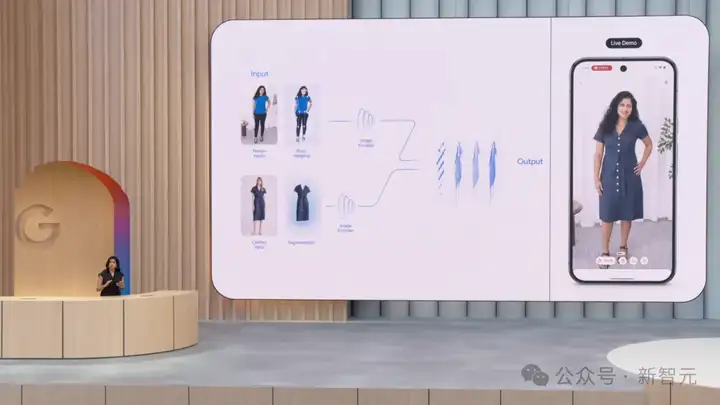
劈柴这次是和奥特曼「杠上了」,前不久OpenAI刚刚推出自己的购物功能,这一次谷歌也不甘示弱。
通过上传你自己的个人照片,谷歌可以把商店里的衣服自动穿戴到你身上,让你直观的看到衣服上身的效果。
同时智能体还能够自动下单,自动付款,完全无需人操作。
接下的几个月,这种可视化购物以及智能体自动结账将全面上线。
Gemini应用
谷歌DeepMind的副总裁Josh Woodward上台介绍了Gemini应用未来的三大特点。
Personal:谷歌提出了Personal context的概念,即你在谷歌中的一切,聊天、邮件、日历以及行程安排都将成为你个人的「上下文」,有了这些个人上下文,AI能够更好的了解你,并安排一切。

Proactive:Gemini应用将变得更具启发式,帮助用户完成日常任务,比如通过类比的方法帮助你理解物理学知识。
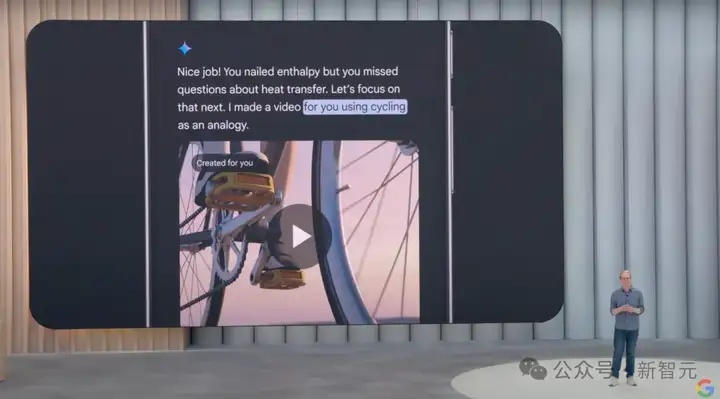
Powerful:Gemini应用中目前最强大的两个工具,一个是深度研究,另一个是Canvas。
可以上传自己的文件来让Gemini应用帮助进行深度分析。

使用Canvas,你可以与Gemini进行完美的互动,可以解答谜题、制作博客,甚至还可以在Canvas中进行氛围编程。

最后,谷歌惊喜推出了两款Android XR新硬件。
首先是和三星合作,对标苹果推出的Project Moohan头戴显示设备,预计今年内发布。

然后,是对标Meta Rayban的XR眼镜。

话不多说,直接上演示。

参考资料:
https://io.google/2025/
文章来自于“新智元”,作者“编辑部 YXH”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
