# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
iPhone迎来AI时刻?
岁末年初,苹果加快了在大模型领域的步伐。
上个月,苹果先是推出了名为Ferret的多模态大语言模型,图像处理技术堪称惊艳;而后又发布了一篇题为《闪存中的大型语言模型:在有限内存下高效的大型语言模型推理》的论文,直指大模型落地iPhone等“内存有限”设备的方法。

进入新年,Siri助手将搭载生成式模型Ajax的消息,再次不胫而走。
去年六月和九月的两次重要发布会,苹果分别掏出了早有传闻的XR项目和iPhone系列的惯例年更,前者市场反响平平,后者挤牙膏被批像是被“卡脖子”了,硅谷All in大模型之时,苹果官方对人工智能这一年度热词始终闭口不谈。
公司CEO库克曾解释道,苹果有计划在更多产品中加入AI,但要“深思熟虑”。
现如今,也许是想好了,也许是技术突破了,留了一手的苹果,终于不藏了。
Siri助手AI化其实早有预兆:去年七月份,彭博社发文称苹果内部正在暗中测试一款对标OpenAI和谷歌的生成式AI工具,暂定名“Apple GPT”。
因使用Google JAX框架进行构建,Apple GPT的开发框架被命名为Ajax。
当时的消息称,苹果LLM技术的最大用武之地,便是整合在Siri内部,让语音助手以更为智能的方式协助用户。
现在,更多细节被透露——苹果发布的论文称,这项将大语言模型放在闪存中优化运行的技术,较传统运行方法提高了4-5倍(CPU)和20-25倍(GPU)的推理速度。
把大象(大模型)装进冰箱(手机)里的方法,来了:先减少闪存传输的数据量,再提高每次传输的吞吐量。
先看框架:以手机为例,平时购机时的【12+256G】、【16+512G】,12/16为运行内存,256/512为储存空间。
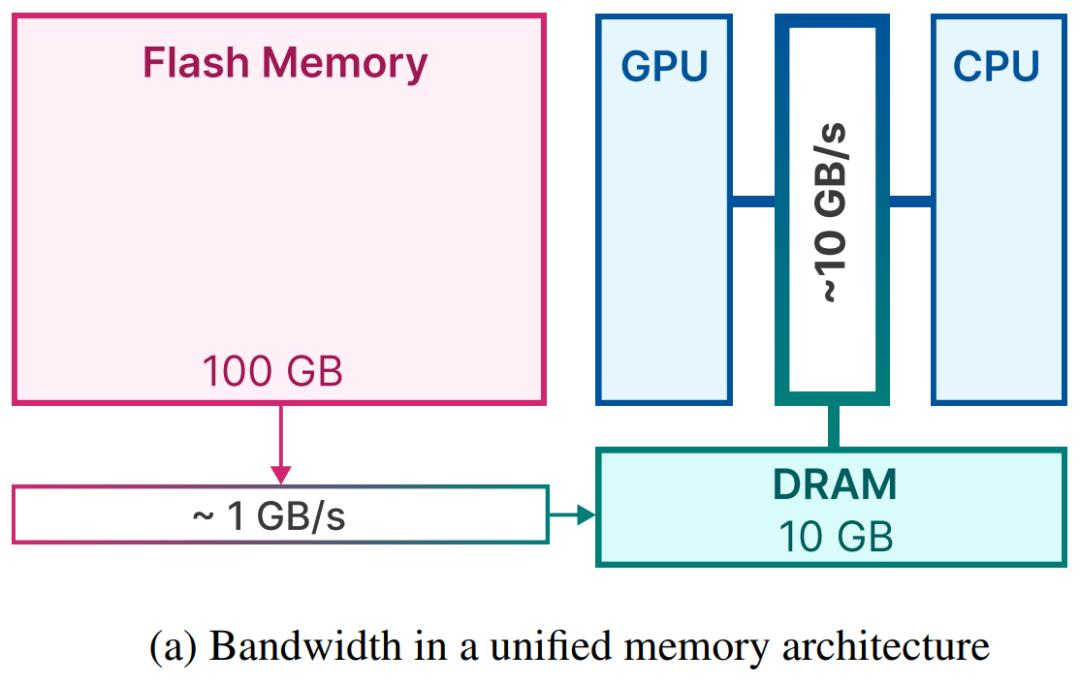
以此类推绝大部分移动设备存储结构,运存空间小,但读取速率高(DRAM 10GB/s);储存空间大,但读取速率相对较低(Flash Memory 1GB/s)
一般来说,大模型的推理阶段,模型加载、分析数据需要直接占用运存,而目前主流手机市场最大的16GB运存,也并不能完全满足大模型所需的空间:模型大小>手机内存。
苹果给出的解决方案是“先减少闪存传输的数据量”——把大模型完全体放在空间更大的储存中,运行时只调用必要数据进入运存。
这并非一个简单的搬箱子过程,如何正确筛选出所有必要数据,以及如何把数据快速由闪存传输到运存,是两个需要解决的问题。
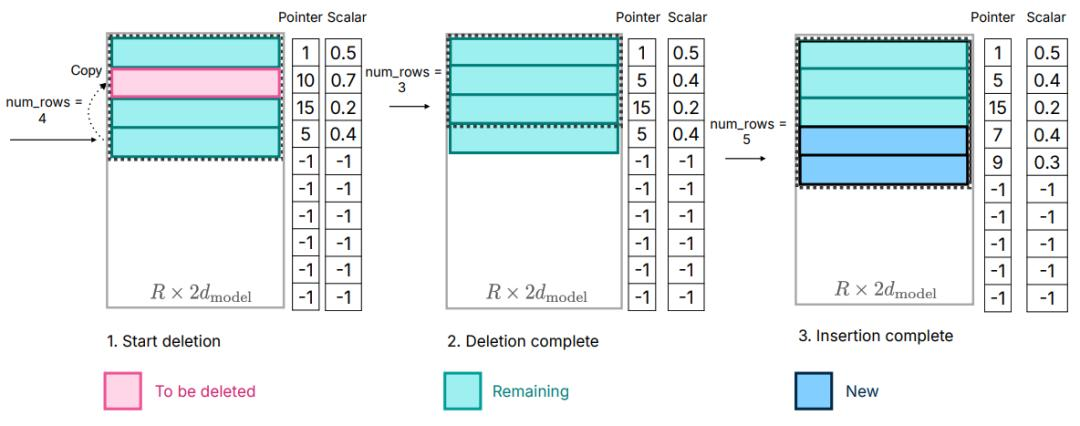
方法之一被命名为sliding window(滑窗):
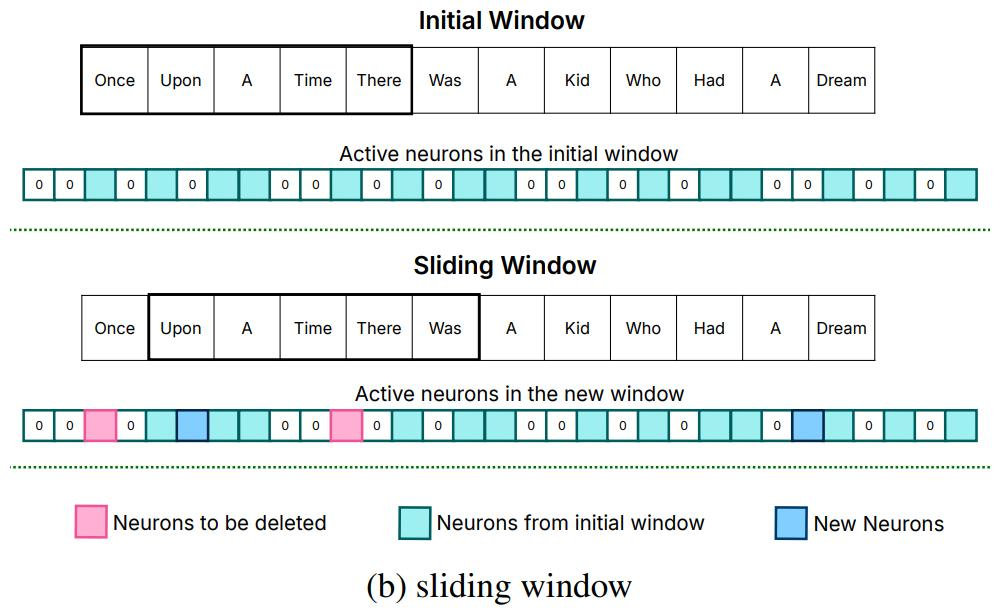
假设大模型正在处理Once upon a time there was a kid who had a dream这句话,在处理“Once upon a time there”这段字符的时候,图中上半部分的青色格子(神经元)处于激活状态;而当处理字段变到“upon a time there was”(往后推进了一个字符),图中下半部新启用了蓝色格子,并删除了了此前青色部分的几个格子(以粉色标注),其余青色保持不变。
这就是sliding Window的核心思想:查缺补漏,多退少补。在大模型运行过程中,只保留一开始就激活的神经元,后续的每次运算,都基于前一次参数进行删除和添加,省去了一部分重复工作。
当然,这种预设也并非没有问题,知乎博主@Civ发文称,sliding window可用的核心假设是大模型在处理相邻数据时前后具有相似性,但这个相似性苹果没有展开论证。
再者是传输:将多次传输的数据拼接后一次性读取,保持连续完整的“数据”,避免多次复制拖慢时间;另外,提前预留出一个较大的空间(较大,但仍远远小于模型整体占用),避免在数据传输过程中,因多次增加空间而加大设备的计算量。
此前,蓝媒汇在《AI PC发布,联想真的想通AI了吗?》中提及,限制大模型进入移动端的瓶颈就是模型占地太大,影响设备本身正常运转,或者塞不进去导致无法运行。
苹果这项新研究的诸多技术细节,都在指向空间的压缩,包括数据体量,也包括运算所占用的算力。
之前有个段子(也可能是真事儿),说是大模型搞不定人机验证,是因为AI被设定不能说谎,所以无法选择“我不是机器人”。
去年十月份,苹果还是以论文的形式公布了一项研究成果:Ferret大模型,自己搞定谷歌人机验证了。
遥遥领先于GPT4。
不久之前,苹果公布了更多Ferret模型的细节、功能。

图/苹果 Github Ferret模型介绍
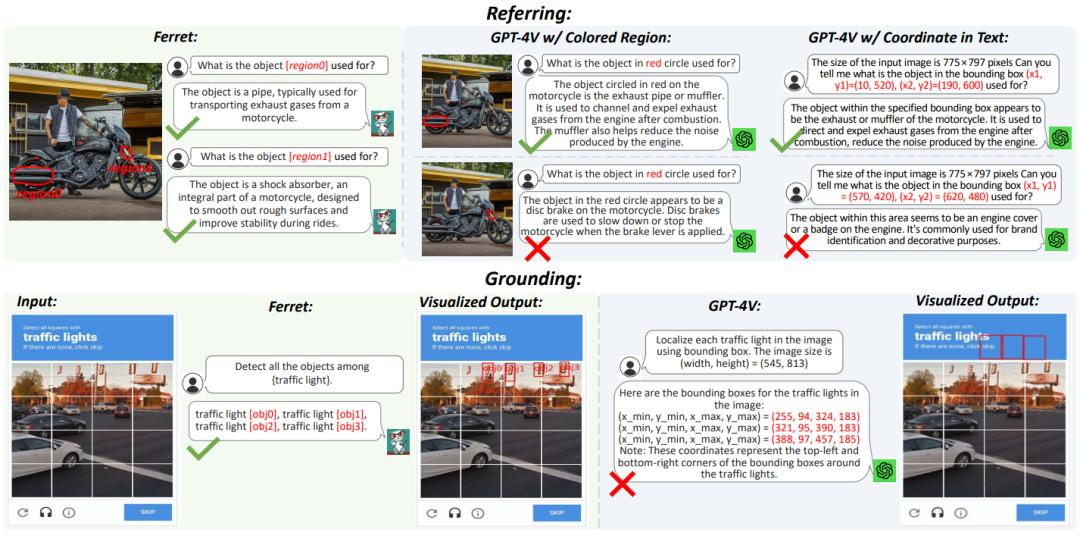
和GPT4相比,Ferret的领先之处在于,它不仅能准确识别并处理图像内容,还能用算法区分图片中各种元素(人、物体等等),并根据用户指令找出对应元素。
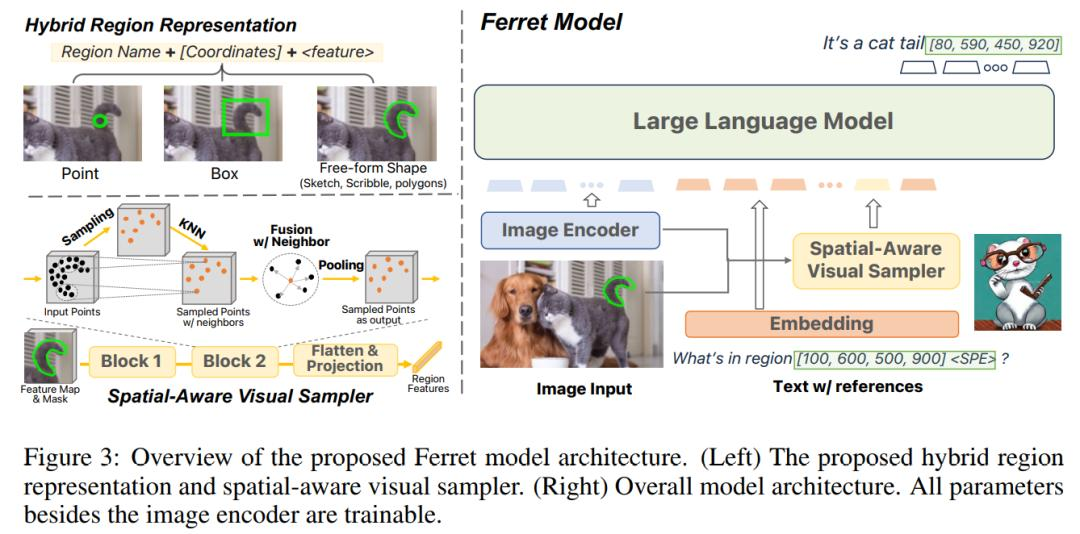
这种多模态理解能力,使得Ferret能够同时处理用户输入的图像和自然语言,并且由于其算法能够将图像中的元素准确拆分、定位,Ferret可以准确理解如“图片右上角”、“靠近沙发”这类指令。
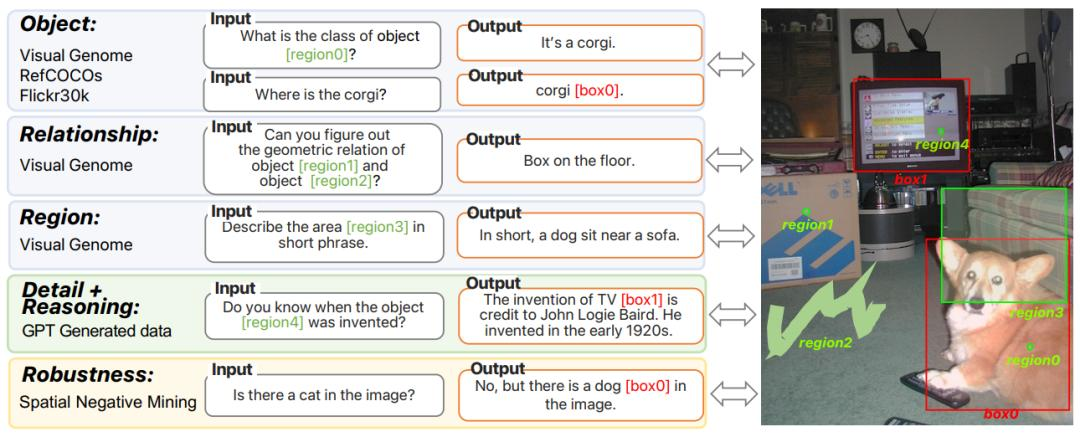
相比于卷疯了的自然语言处理,这种基于图像的交互使得信息更加直观。

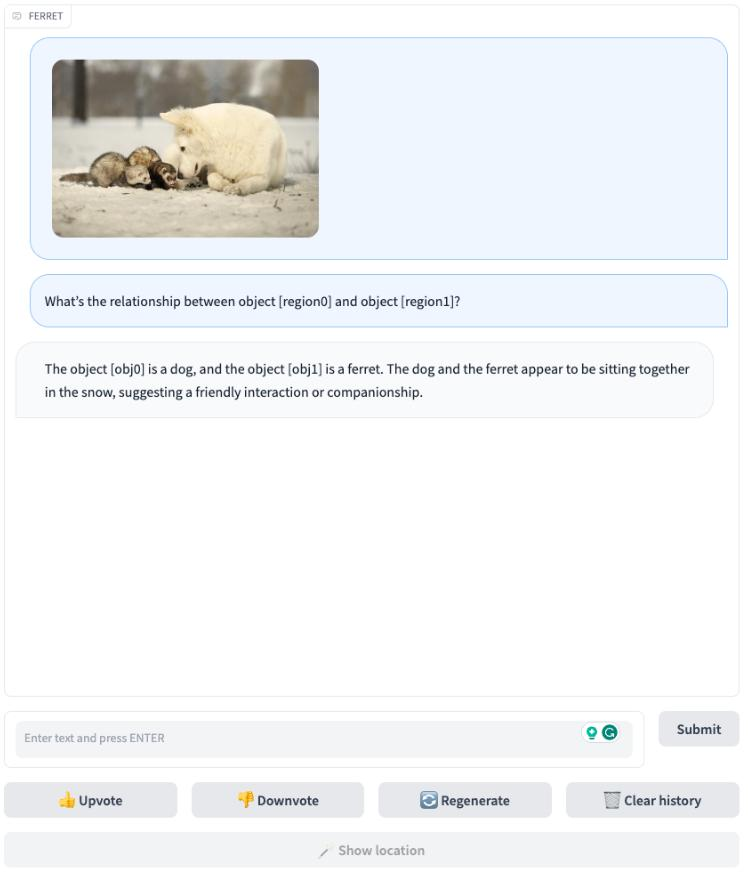
最近一次更新,苹果提供了Ferret的7B和13B两个版本,并创建了包含了1.1M个样本的GRIT的数据集以丰富空间知识,进一步增强功能。
考虑到苹果相当成熟的产品生态以及巨量用户规模,AI落地带来的换机潮等收益,或将极为可观。
2023年被称为是AI的iPhone时刻,现在,苹果的AI时刻大约也快到了。
文章来自于微信公众号 “AI蓝媒汇”(ID:lanmeih001),作者 “陶然”



