# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。
随着 DeepSeek R1 的持续爆火,推理和强化学习已经成为 AI 领域的热门词汇。
短短几个月的时间,我们已经见证了太多的推理大模型,AI 更新迭代速度似乎已经快进到了以天为单位。
但在众多研究成果中找到值得关注的内容并不容易。
这有一篇价值非常高的博客,可以帮你梳理最近关于推理模型的研究,重点关注 DeepSeek R1 里用到的 GRPO 及后续的改进算法,非常值得一读。作者是来自 AI2 的 ML 科学家 Nathan Lambert,他博士毕业于 UC 伯克利,曾在 HuggingFace 领导 RLHF 团队。

博客地址:https://www.interconnects.ai/p/papers-im-reading-base-model-rl-grpo
文章列举了最近比较火的论文和大模型,包括:
此外,作者还给出了参考论文中重复看到的损失函数,我们不难发现这应该是比较重要的损失函数:

是时候给 GRPO 降降温了
现在很多人被 RL 在语言建模领域的表现所吸引,这给人一种错觉,彷佛 GRPO 和 DeepSeek R1(以及之前的模型)的工作已经开启了 RL 训练的全新时代。
但事实远非如此。
其实 GRPO 并不是一种特殊的 RL 算法。
目前许多领先的研究工作和实验室并没有使用 GRPO 进行研究。
实际上,GRPO 与其他 RL 算法关系极为密切 —— 它源自 PPO(近端策略优化),并且具有与 RLOO (REINFORCE Leave One Out)超级相似的计算优势。
GRPO 确实包含了巧妙的改进,尤其是在推理训练(reasoning training)而非传统的 RLHF 场景下。
传统 RLHF 实践沿袭了早期 RL 文献的做法,通常每个批次中每个提示词仅采样一个生成结果进行训练。而在推理任务中,我们现在会生成多个答案。
若不深入技术细节,现代实现中 GRPO 和 RLOO 的优势值计算几乎如出一辙 —— 这与 PPO 形成鲜明对比(PPO 的优势值来源于价值函数,通常采用 GAE 方法计算)。

因此,REINFORCE 与 GRPO 的唯一区别仅在于 PPO 的 clipping logic 机制 —— 它们本质上都是同宗同源的策略梯度算法。与此同时,前 LLM 时代流行的另一个 RL 算法 A2C,根据超参数设置的不同,也可以视为 PPO 的特殊变体。
这里需要把握的核心认知是:当前使用的所有 RL 算法在实现层面上是高度相似的。
因此,尽管 GRPO 是当前最流行的算法,但如今 RL 算法的变革其实只聚焦在几个核心维度:
Kimi k1.5
《Kimi k1.5》的报告内容非常丰富,论文长达 25 页。不过,其并未开放模型权重。
这篇论文报告了 Kimi k1.5 的训练实践,这是 Kimi 团队最新多模态大语言模型(LLM),采用 RL 进行训练,包括其强化学习训练技术、多模态数据配方以及基础设施优化。长上下文扩展和改进的策略优化方法是 Kimi 团队方法的核心要素,他们建立了一个简单而有效的强化学习框架,无需依赖蒙特卡洛树搜索、价值函数和过程奖励模型等更复杂的技术。

该模型在 o3-mini 发布之前就已经推出,其评估结果非常出色。
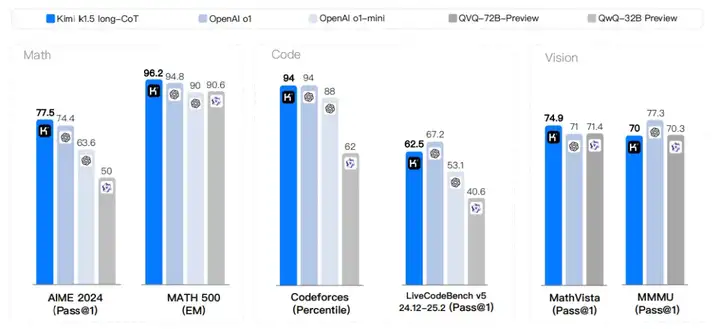
数据分布
这篇论文(以及本文后面提到的《Open Reasoner Zero》)都包含了 01 和 R1 版本所没有的对数据的讨论。Kimi 团队强调了为 RL 进行提示策划(prompt curation)的重要性。这听起来很简单,但强化学习提示集的质量和多样性在确保强化学习的有效性方面起着关键作用。由此,团队人员指出了两点与我们目前看到的大多数仅数学模型不同的地方:
在任务难度方面,Kimi 团队采用了一种与推理模型相关的较新的方法: 他们采用基于模型的方法,利用模型自身的能力来适应性地评估每个提示的难度。具体来说,对于每个提示,一个经过监督微调(SFT)的模型使用相对较高的采样温度生成答案十次。然后计算通过率,并将其作为提示难度的代理(proxy)—— 通过率越低,难度越高。
此外,他们还移除了一些可能促使模型猜测而不是进行推理的问题: 经验观察表明,一些复杂的推理问题可能有相对简单且容易猜测的答案,这会导致假阳性验证 —— 模型通过不正确的推理过程得出了正确答案。为了解决这一问题,他们排除了容易出现这种错误的问题,例如选择题、基于证明的问题。
训练方法
Kimi K1.5 的训练方案包含了许多有趣的细节,但随着训练技术的成熟,这些方法可能不会成为长期推荐的最佳实践。
例如,他们的初始阶段与 DeepSeek R1 论文非常相似:采用 SFT(监督微调)预热,结合长思维链(CoT)和拒绝采样(rejection sampling)。
又比如,他们重点关注数据中的行为模式,包括规划(planning)、评估(evaluation)、反思(reflection)和探索(exploration),这些对最终性能提升至关重要。
进入后续训练阶段后,他们的方法变得更加有趣:未采用 GRPO,而是使用了一种在线策略镜像下降(online policy mirror descent) 的变体(仍属于策略梯度算法家族)。
除此之外,他们未使用价值函数,而是采用蒙特卡洛奖励基线(Monte Carlo reward baseline),其核心思想与 GRPO 类似,但并非直接用于优势估计(advantage)。

为了提高模型训练的稳定性和效果,研究者们采用了多种策略。其中一种策略是引入长度惩罚,即鼓励生成较短的回答,并在正确回答中惩罚较长的回答,同时明确惩罚错误答案中的长回答。这种策略有助于控制模型生成回答的长度,避免模型过度生成冗长且可能不准确的内容,从而提高训练的稳定性。尽管这种方法在训练初期可能会减慢训练速度,但研究者们会逐渐在训练过程中引入这种奖励机制,以实现更好的训练效果。
此外,研究者们还采用了数据序列策略来辅助模型学习。这种方法类似于一种明确的教学大纲,即从较简单的任务开始训练,并在训练过程中对模型表现不佳的任务进行重新采样,增加这些任务的训练频率。这种策略类似于逐步引导模型学习,类似于人类学习过程中从易到难的逐步进阶。尽管这种方法可能会增加训练的复杂性,但它被视为一种有效的技巧,可以帮助模型在训练过程中逐步提升性能。
这些方法虽然在短期内可能会增加训练的复杂性,但它们有助于模型在长期训练中保持稳定性和一致性,从而提高模型的整体性能和泛化能力。
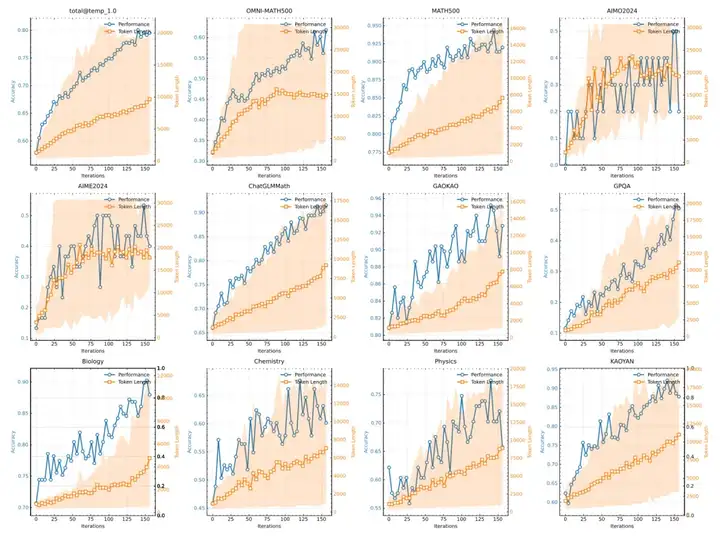
在关于模型大小的消融研究中(尽管没有明确提及模型的具体大小),他们发现,尽管较大的模型在初始阶段表现优于较小的模型,但较小的模型通过利用强化学习(RL)优化的更长的思维链(CoTs)也能达到相当的性能。然而,较大的模型通常在 token 效率方面表现得比小模型更好。
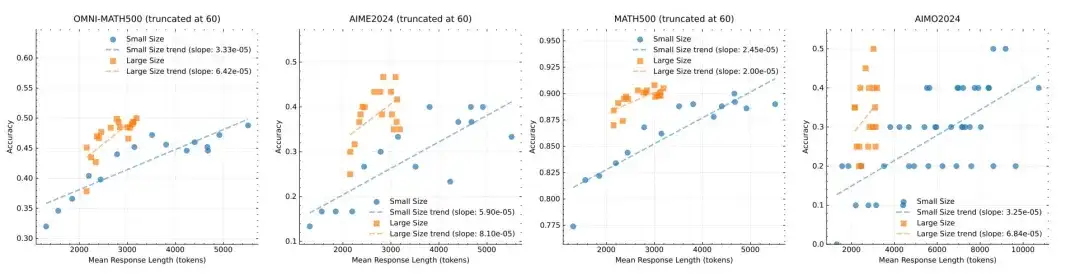
另外,这篇论文对模型最终实用性方面的总结非常有趣,也与近期许多强化学习(RL)文献中的观点一致: 如果目标是尽可能达到最佳性能,那么扩大较大模型的上下文长度具有更高的上限,并且在 token 效率方面更具优势。然而,如果测试时计算资源有限,那么训练具有较大上下文长度的小型模型可能是可行的解决方案。
论文中还详细介绍了他们的监督微调(SFT)数据集、强化学习(RL)基础设施、长思维链到短思维链的蒸馏过程。感兴趣的读者可以查看论文深入了解。
Open- reasoner - zero
这篇论文的主要贡献在于,它是第一篇展示在基础模型上通过 RL 取得非常出色结果的研究。
论文地址:https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero/blob/main/ORZ_paper.pdf
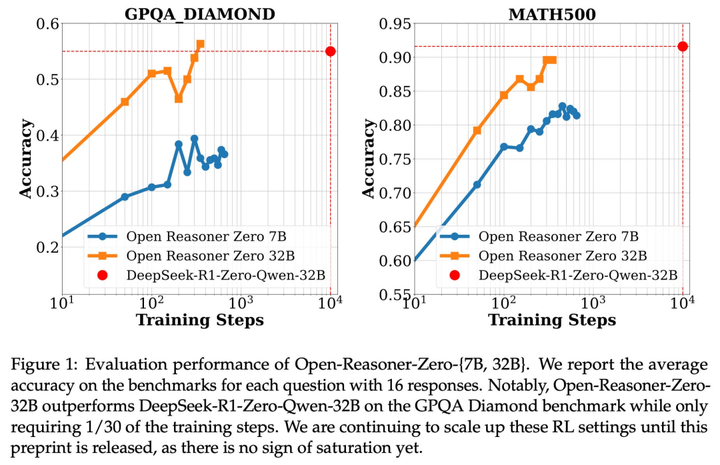
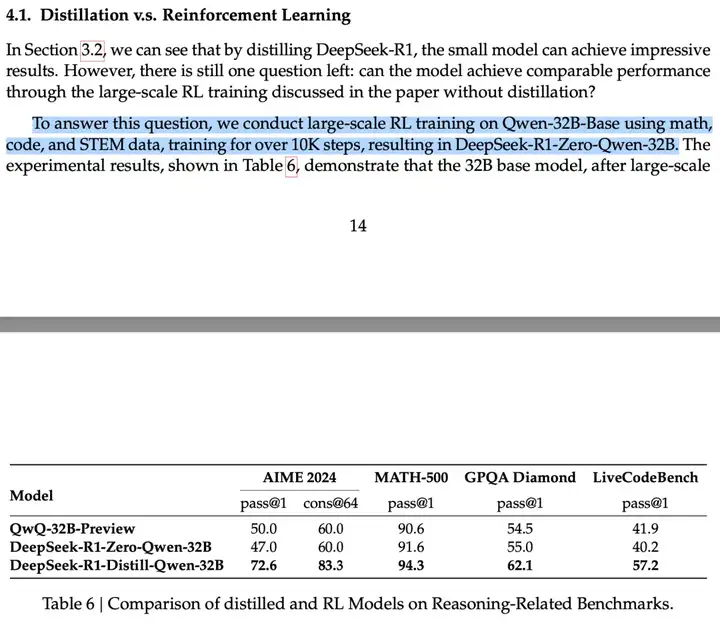
事实上,他们使用 Qwen-32B 基座模型时,能够达到 DeepSeek 论文在其蒸馏部分提到的 Qwen-32B 强化学习(RL)模型的性能。不过,DeepSeek 论文中提到的这个 RL 模型并未引起太多讨论,因为同一表格显示,DeepSeek 发现在这种规模的模型中,蒸馏推理能力(而非从强化学习开始)能带来更显著的性能提升。
R1 论文:https://arxiv.org/pdf/2501.12948
这里,问题在于并非所有的 RL 步骤都是等价的。它在很大程度上取决于:
数据分布
这项工作的核心成功之处在于,它非常清晰地展示了数据对于学习的重要性。
他们从各种来源收集公开数据,包括 AIME(截至 2023 年)、MATH、Numina-Math 数据集、Tulu3 MATH 以及其他开源数据集。根据数据来源和问题难度,他们提取了 AMC、AIME、数学、奥林匹克竞赛以及 AoPS 论坛的相关部分,作为难度较高的提示,以确保数据集的难度水平适当。
该研究还通过程序化方法合成额外的推理任务,以扩充数据集。此外,他们还对数据集进行格式筛选等一系列操作。
此外,研究者排除了那些难以用基于规则奖励函数进行评估的问题,例如选择题和证明题,以确保在训练过程中奖励计算的准确性和一致性。
训练消融
《OpenReasonerZero》是另一篇发现 GRPO 对他们不起作用的论文。作者使用了带 GAE(Generalized Advantage Estimation)的 PPO 算法来对一组响应进行估计,这也进一步证实了文章之前提到的 GRPO 并非有特别之处。
在训练过程中,他们没有使用任何复杂的长度或格式 token(例如 < answer>token)来构建奖励函数,而是发现仅正确性是必要的。此外,他们还移除了所有的 KL 惩罚,这对于允许模型在响应长度上进行显著变化以及学习新行为至关重要,这些行为有助于下游性能的提升。
实验结果表明,移除 KL 损失和 KL 惩罚能够实现最优的训练稳定性和最终性能。
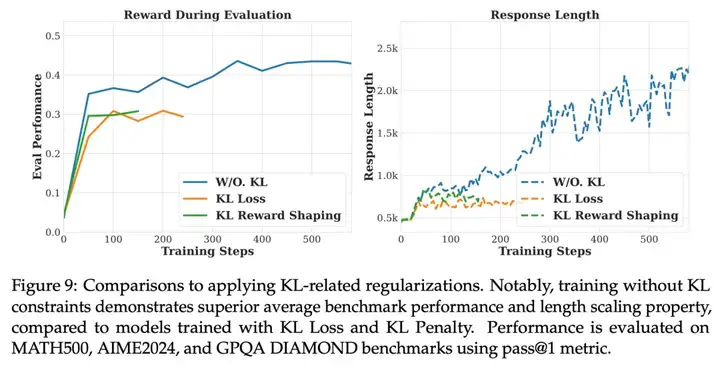
这篇论文的附录里还有更多有趣的消融实验,比如调整 RL 训练时的采样温度、修改 RL 超参数,或是调整批次大小和更新规则等,感兴趣的读者可以查看原文章。
DAPO:一个大规模开源 LLM 强化学习系统
在开始讨论接下来的两篇论文前,我们需要了解一些背景,以便理解机器学习特别是强化学习中的算法进步。有一个经验法则是,如果你看到一篇论文中提出的方法没有提高到基准方法的 2 倍左右,那么这个解决方案的成功很可能主要归功于超参数调整或其他混淆变量。这是对语言模型新型强化学习算法应持有的适当怀疑态度。
读这些论文时,你很容易想到「哇,我的项目现在就能顺利运行了」。实际情况远非如此。这些论文是学习 GRPO 损失函数复杂细节的绝佳练习。多年来,这类论文积累起来会带来巨大的直觉增益。但目前在训练真正的 SOTA 模型时,大多数改变在代码复杂性上可能会过于繁重,相比之下,专注于调整数据分布(如上述论文所讨论的)更为重要。
让我们来看看 DAPO—— 这是对之前 Twitter 上简短介绍的扩展版本。

他们展示的学习曲线不错,但有些混乱,因为「DeepSeek R1 Zero Qwen 32B」模型的训练步骤精确比较实际上并不存在(如上所述),尤其是,x 轴是有误导性的。再强调一遍,DeepSeek 所做的工作并非不可复制。
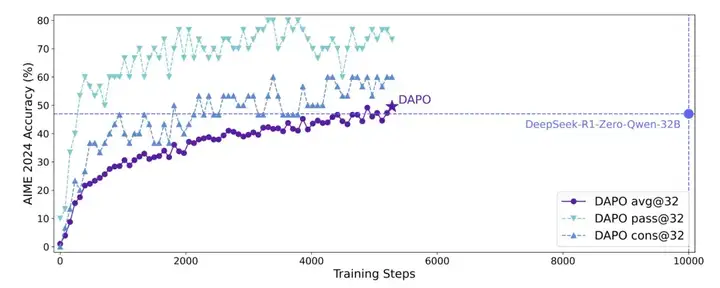
这是一篇非常整洁的关于推理的强化学习论文。我们将介绍的 GRPO 改进包括:
1. 两个不同的裁剪超参数,使正向裁剪能够更多地提升意外的 token。
2. 动态采样 —— 从批次中移除具有平坦奖励的样本以提高效率。
3. 使用每个 token 的损失(而非每个回应(per-response)的损失)来改善学习动态。
4. 在损失函数中管理过长生成以获得更好的稳定性。
我希望这篇论文,正如我将在下面讨论 Dr. GRPO 论文时提到的,能做更多关于最终性能的比较。我们关心的是评估结果,所以在算法变化带来性能提升之前,我很难说这些是关键的实现决策。
总之,DAPO 看起来如下:

像现在的许多论文一样,他们也建议从 GRPO 中移除 KL 散度惩罚以帮助学习。许多人表示,如果没有要过度优化的奖励模型,这个惩罚就不是必要的。对于基础模型的强化学习,我同意这一点,因为模型通常需要更大的变化才能成为完整的推理模型。但如果对指令模型进行可验证奖励的强化学习(RLVR),KL 惩罚可能仍然有用。
GRPO 改进点 1:更高的裁剪 / 分离裁剪超参数
PPO 和 GRPO 有一个控制更新步长的裁剪超参数。这是 PPO 和 TRPO 相比 REINFORCE 或普通策略梯度的核心思想。DAPO 将其改为两个超参数,这样上限 / 正向对数比率步长可以更大。这是为了增加 token 的概率,比如推理链中令人惊讶的新 token。

PPO/GRPO 更新是基于对数比率的,所以概率较小但正在增加可能性的不太可能的 token 会变成更大的对数比率,比可能性已经很高的 token 更容易被裁剪。这对于提升效果来说是一个相当复杂的变化,但它很好地说明了裁剪如何影响学习动态。
这篇论文对他们的改进做了很好的消融实验!如下图(右)所示,他们显示模型在训练过程中保持了更高的熵(即探索 / 随机性)。不错。
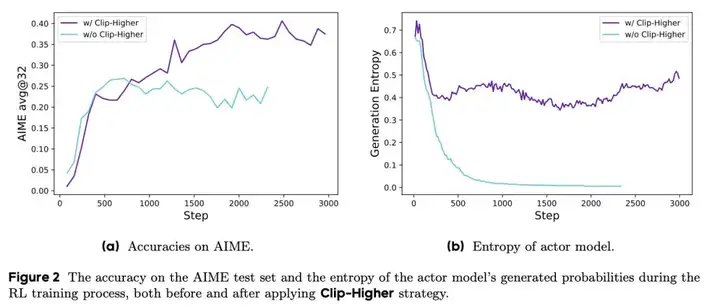
GRPO 改进点 2:从批次中移除不必要的样本
本质上,在 GRPO 中,如果批次中针对一个提示的所有样本具有相同的奖励,则没有学习信号,因为每个答案的优势是计算为该答案与批次中组平均值的差异。移除它们可以通过计算更少的梯度来提高学习速度。
这实际上是 GRPO 的一个简单事实。从理论上讲,当批次中的答案没有信号时,它们不会影响模型,但这也与为什么更大的模型可能通过强化学习学习得更好有关。更大模型的强化学习步骤不太可能无意中伤害模型中不在学习批次中的其他区域,因为它们的能力分布在更多参数上。

GRPO 改进点 3:token 级策略梯度
论文作者表示,token 级损失有助于减轻非常长的推理链中的重复行为,同时仍然鼓励模型从正向的长上下文示例中学习。这与标准 RLHF 实现不同(见下文关于 Dr. GRPO 的讨论)。他们的改变比我们稍后讨论的更为温和。
作者的直觉很好,我们将在接下来的论文中看到很多关于这种权衡的讨论:
由于所有样本在损失计算中被赋予相同的权重,较长回应中的 token(包含更多 token)对整体损失的贡献可能不成比例地低,这可能导致两种不良影响。首先,对于高质量的长样本,这种效果可能阻碍模型学习其中与推理相关的模式的能力。其次,我们观察到过长的样本通常表现出低质量的模式,如胡言乱语和重复词汇。因此,样本级损失计算由于无法有效惩罚长样本中那些不受欢迎的模式,导致熵和回应长度的不健康增加。
将长度归一化 1/|o | 移到组总和之外,使得损失计算仅通过对两个总和内部的 token 求和来完成。

在这里,答案组是按照该提示的总体 token 计数归一化的。默认 GRPO 只对 token 所对应的回应进行每 token 损失归一化。
这很酷,但需要更多的复制!见下面的讨论。在他们的设置中,他们看到了相当不同的行为。
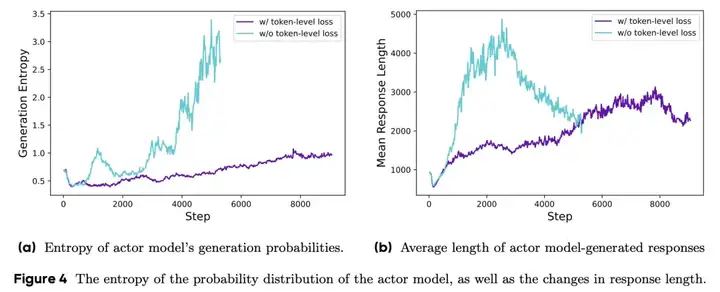
这个想法是为了能更好地从长答案中学习。好的长答案应该得到充分奖励,而重复的、糟糕的长答案需要被惩罚。
GRPO 改进点 4:避免截断的奖励塑造
这是 DAPO 中最微小的改变。本质上,他们添加了一个柔性然后是一个严格的惩罚,当模型生成长度超过限制时。对于最大上下文长度为 16k token 的模型,他们在 12k token 开始应用惩罚,并线性增加到 16k。这种长度控制机制感觉将会过时,或者在未来只是一个非常小的技巧。
参考一下,许多强化学习实现已经包含了一些更大的惩罚,如果模型截断自身(即从不生成 EOS token 或答案)。

他们称之为解耦裁剪和动态采样策略优化(DAPO)算法。称其为新算法似乎足够公平,这在强化学习中一直如此,但实际上这基本上是 GRPO++。
训练专注于 AIME,所以最终模型并不超级有趣,但它们陈述了一个永恒真理: 即使是初始条件的微小变化,如数据和超参数的变化,也可以通过迭代强化学习过程放大,产生实质性的结果偏差。
Dr. GRPO

这是我们获得的第二篇关于修改 GRPO 以使其更适合推理训练(实际上,就是让它更有效)的论文。该论文还包括一些优秀的实验,帮助理解不同基础模型如何影响学习到的推理行为。
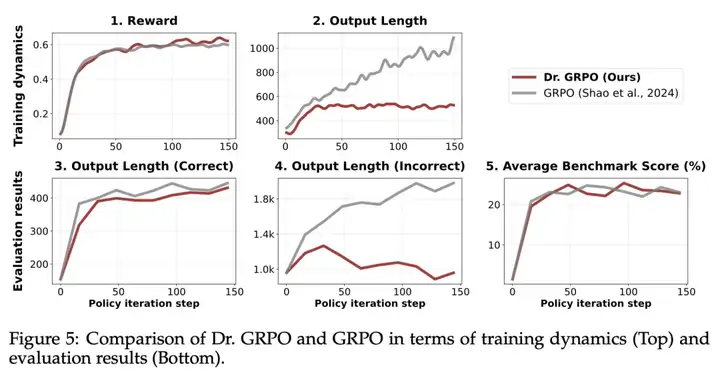
论文的核心图表如下:
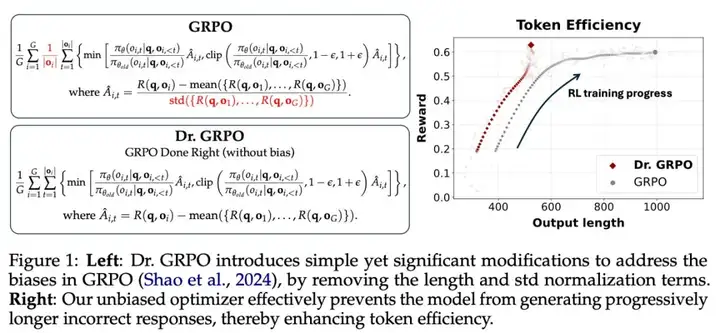
论文的核心思想是,通过修改 GRPO,他们可以改善学习动态,使得在生成长度增加较少的情况下实现更强的性能。这是每个人都应该想要的!
他们假设默认的 GRPO 实现实际上设置了一个偏置,使生成长度增加的程度超过了实际有用的范围。
关于 GRPO 的修改
他们提出的核心修改有些微妙,与 GRPO 实现的常见做法密切相关。GRPO 实现的一个核心步骤在 DeepSeekMath 论文中有详细说明:
「结果监督在每个输出𝑜_𝑖的末尾提供归一化的奖励,并将输出中所有 token 的优势𝐴ˆ_(i,t)设置为归一化奖励...」
本质上,不是只在验证结果的最终 token 上分配优势,而是批次中的每个 token 都被分配了优势。然后使用这些策略梯度算法计算每个 token 的损失。
要了解这是如何工作的,让我们重新回顾论文中的损失函数:
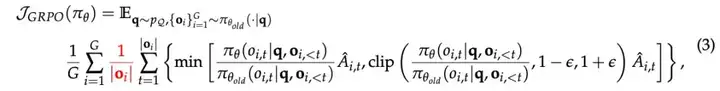
这里发生的事情是,第一个求和管理问题的回应组 G,内部求和管理每个 token 的损失。作者正在纠正学习中的两种行为:
这些合在一起,有点与我们想要的相反(与 DAPO 的想法非常相关)。我们希望在推理时有更长的正确答案以提高扩展性,并且不想浪费 token。个人而言,我更喜欢 DAPO 的解决方案,将长度归一化移到组外,而不是完全去除它。
他们提出的第二个修改非常聪明(已在 TRL 中实现)—— 移除问题级难度偏置。当执行像 GRPO 这样的更新(例如也用 PPO)时,优势的大小影响梯度更新的大小。在这里,相对于更容易解决(或失败)的问题,具有高方差的问题会受到惩罚 —— 从直觉上讲,这甚至可能与我们想要的相反!较难的问题,特别是在学习的关键阶段,将有更高的方差。作者也解释了与之前的强化学习实践的关系:
虽然优势归一化在强化学习中是一种常见技巧,但它通常是在整个批次中计算的。
实际上,这种变化的影响可以完全被高质量的数据工程所吸收,正如上面其他论文中讨论的那样,批次中问题难度的分布是均匀的。
不过,这些变化也没有免费的午餐 —— 我的同事 Costa Huang 提醒我,低方差问题可能是我们模型学习的关键。在模型 9 次回答错误、只有 1 次正确的情况下,移除标准差会降低那一个正确答案的权重。这可能是模型需要学习的关键!
他们将这两个变化称为「GRPO Done Right」,即 Dr. GRPO。当他们将这些结合在一起时,模型显示了他们预期的输出长度变化 —— 总体上更短,特别是错误答案更短。这里的缺点是,他们实际上没有展示更好的下游最终性能。最终性能是目标,很可能更多地来自数据。
关于为强化学习更换基础模型
论文作者比较了来自 Qwen 2.5、Llama 3.1 和 DeepSeek 的基础模型,看它们如何回答 MATH 问题。对于这些模型,它们使用 R1 模板、Qwen MATH 模板和无模板。当模型已经通过带有推理 / CoT 轨迹的中间训练时,这些模板起着至关重要的作用:
模板 1(R1 模板):A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer.
The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.
模板 2(Qwen-Math 模板): <|im_start|>system Please reason step by step, and put your final answer within \boxed {}. <|im_end|> <|im_start|>user {question} <|im_end|> <|im_start|>assistant
模板 3(无模板):{question}
他们发现 Llama 和 DeepSeek 使用 R1 模板能够最好地遵循指令,而 Qwen 在没有模板的情况下效果最好。记住这些基础模型在不同的「微调」机制下有多大差异是至关重要的。格式合规性的比较如下所示。
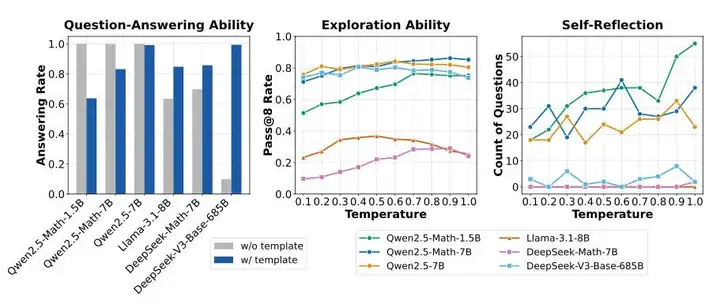
中间图显示了数学问题的 pass@8 率,可以理解为「如果我对 1 个问题采样 8 个答案,正确答案出现的频率是多少?」这是衡量模型在训练开始时学习难易程度的指标。Qwen 再次表现最佳,温度的影响比我想象的要小。
最右边他们显示,更大的 Qwen 模型在任何强化学习训练之前就已经有反思行为!如果你正在使用这些模型,这并不令人惊讶,但这是一个很好的数据点,可以淡化强化学习训练中「啊哈时刻」的作用。这些模型主要是在放大,而不是学习新东西。
论文还有其他不错的结果,例如在更多领域特定的数学数据上继续预训练可以提高强化学习性能,很多人通过在 Qwen-MATH 模型上训练的容易程度也能看到这一点。
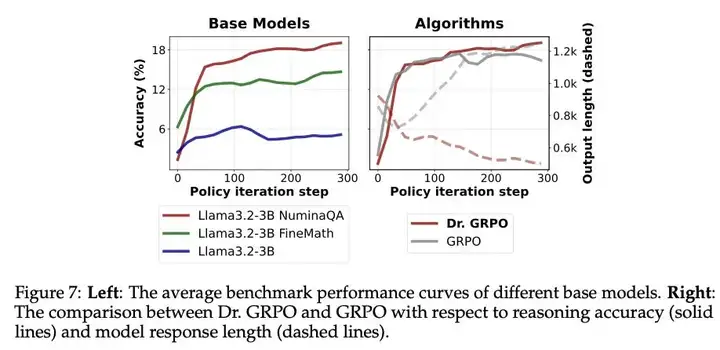
与 GRPO 训练失败的关系
在我们早期的研究中看到的一些失败,我也从其他实验室听到过,是 GRPO 可能会失败,开始生成非常重复和长的回应。答案的序列长度膨胀到训练设置中允许的最大值,下游评估的性能降至 0。这些潜在的干预措施,对于 Dr. GRPO 和 DAPO 来说,都有助于缓解这种情况。我们很快就会有独立的复制实验了!
与现有 RLHF 基础设施的关系
在过去几周里,我参与了许多关于 RLHF 基础设施中每批次使用总和损失还是平均损失的讨论。其中的核心问题是:强化学习应该平等地对待每个 token(即从批次中较长的答案学习更多)还是应该相对于问题对它们进行归一化?我的基本观点是,基于每个问题的归一化更有意义,因为模型需要针对不同问题学习不同的行为,但这种学习动态很微妙。
这篇论文对目前所有流行的开源强化学习工具提出了批评,称 per-response 的方式偏向于更糟糕的情况。实际情况比这复杂得多 ——per-response 求和肯定是标准做法。
区别在于从像 TRL 这样的库中的 masked_mean 变为作者使用的 masked_sum。
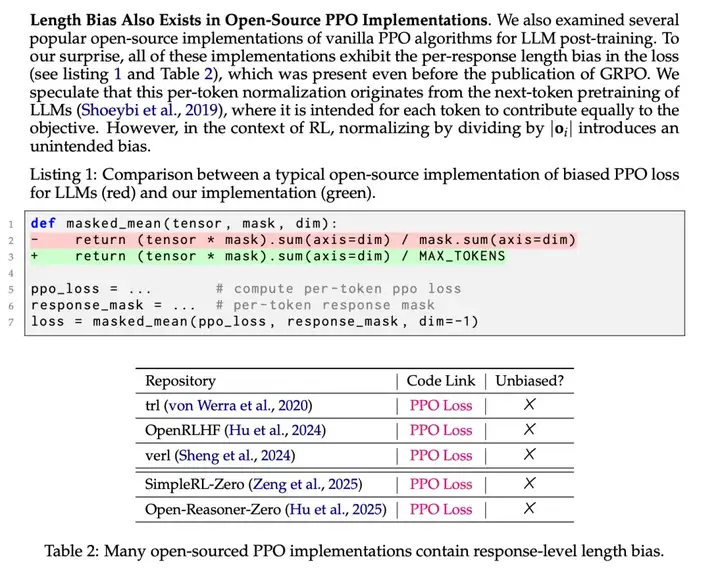
为什么 per-response 可能是好的一个直觉是,如果你有一个 KL 惩罚,你不希望一个非常奇怪的 token(KL 爆炸)影响批次中的每个 token。这些实现差异非常依赖于特定的训练设置。
不过,关于推理 vs.RLHF 的上下文也很酷。是的,在大多数方面,实现都如作者所说,但这只是因为社区之前不像我们现在对推理模型那样关心上下文长度学习动态。
以前,重点是在奖励上。现在,重点是奖励正确的长上下文行为并惩罚重复的长行为。所以,是的,回答倾向于反对较长的、高奖励的序列,但我们不在乎!

在原文的「Further reading」作者还推荐了其他论文,感兴趣的读者可以参考下图。
原文链接:https://www.interconnects.ai/p/papers-im-reading-base-model-rl-grpo
文章来自微信公众号 “ 机器之心 ”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
