# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

近半年来,OpenAI 形象开始变得灰暗: 团队骨干相继离职引发猜疑、组织转型遭受口诛笔伐、GPT-4.5/Sora 等模型表现不及预期,还有被 DeepSeek R1 打破的叙事神话……
踉跄前行的身影,让大众逐渐意识到:在最前沿的研究领域,强如 OpenAI,也无法躲避被「失败」肘击的命运。
我们观察到,OpenAI 在 4 月份经历了至少 3 次颠簸:1)o3 和 o4-mini 强大的视觉推理能力带来了同样强大的幻觉,2)GPT-4o 新版本因为谄媚而被撤回,3)DeepSeek R1 余威仍在。
逐一剖析下。
4 月 17 日,OpenAI 发布 o3 和 o4-mini 视觉推理模型,作为 o 系列的最强版本,其推理能力和工具调用能力都获得了显著增强。
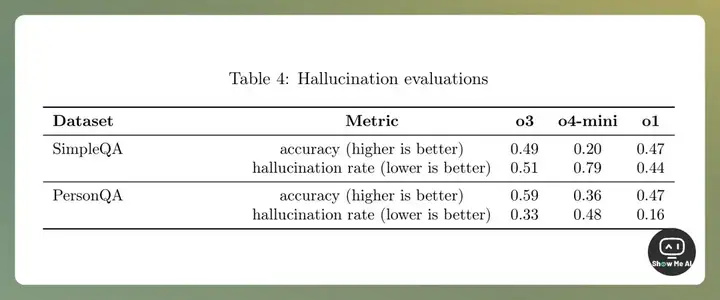
OpenAI 在 System Card 里坦陈,与前代 o1 相比,o3 和 o4-mini 幻觉率明显上升(如上图所示)。
o4-mini 尚可以解释,毕竟小模型的世界知识相对有限,更容易产生幻觉。但旗舰级 o3 为什么也有这么高的幻觉率呢?OpenAI 初步分析是 o3 倾向于做出更多的断言,这在提升回答准确率的同时,也导致了不准确/幻觉内容的增加。但其深层机制仍然有待研究。
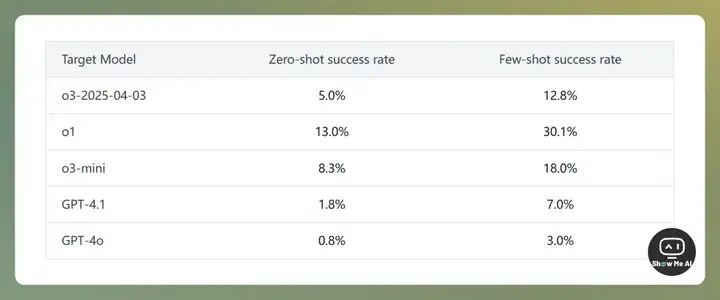
在将近一周的话题讨论中,有两项分析非常值得关注:非营利研究机构 Transluce 的分析报告与机器学习专家 Nathan Lambert 的一篇长文。
Transluce 在报告指出,o 系列推理模型普遍存在「幻觉」,不仅限于 o3(如上图所示)。可能的原因有两类:1)强化学习机制诱导模型陷入了「正确率陷阱」,导致模型为了获取正确奖励而生成看似合理但实则虚构的内容;2)彻底丢失思维链,使模型在后续对话中失去了推理记忆,被迫为过往行为编造解释,从而出现了「坚持错误 - 突然改口」的矛盾行为。
Nathan Lambert 则认为幻觉产生的根源在强化学习的「过度优化(Over-optimization)」。他推测,OpenAI 训练模型时大量采用其他 LLM 作为评估器,并且在优化过程中过于重视数学推理和代码生成等任务的准确性,从而牺牲了其他维度的鲁棒性,衍生出了严重的幻觉问题。
4 月 25 日,OpenAI 更新了 ChatGPT GPT-4o 模型,目标是提升问答自然度。但是,4 月 30 日,因新版本模型过于迎合用户,官方撤回了本次更新,恢复到了之前更平衡的版本。
对于本次新版本过于「谄媚」的原因,官方技术文档给出的解释是:OpenAI 一直在使用用户反馈(如点赞/点踩行为)来优化模型,但是本次更新的版本过于重视短期反馈数据,没有充分考虑到用户与 ChatGPT 长期互动的特点,导致模型有时会给出看似支持实则不够真诚的回答。
3 月 26 日,ChatGPT 上线新版 GPT-4o 图像生成模型,其受欢迎程度远超想象,为 ChatGPT 带来了新一波用户增长。
4 月 1 日,Sam Altman 宣布 ChatGPT 图像生成功能开放给所有免费用户,并在同一天宣布未来几个月将开源一款语言推理模型。
发现了吗?OpenAI 很矛盾。它把本可以继续吸引付费的图像生成功能,直接开放给免费用户。它不遗余力堆砌资源构建的封闭生态,却又要开源一款模型。
为什么会这样呢?我们可以从 Sam Altman 一次访谈中找到线索:他分析 DeepSeek 成功的原因,一是最前沿的模型完全免费开放,二是毫无保留地展示了「思维链」过程(OpenAI 隐藏了),因而迅速占领了用户心智。
作为对 DeepSeek 挑战的回应,OpenAI 调整了模型和产品策略,希望借助扩大用户范围(即免费)、展示技术实力(即开源)等措施,提升大众对 OpenAI 的了解和认可。

✦ OpenAI | Introducing OpenAI o3 and o4-mini → https://openai.com/index/introducing-o3-and-o4-mini
✦ OpenAI | OpenAI o3 and o4-mini System Card → https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
✦ Transluce | Investigating truthfulness in a pre-release o3 model → https://transluce.org/investigating-o3-truthfulness
✦ Nathan Lambert | OpenAI's o3: Over-optimization is back and weirder than ever → https://www.interconnects.ai/p/openais-o3-over-optimization-is-back
✦ OpenAI | Sycophancy in GPT-4o: what happened and what we’re doing about it → https://openai.com/index/sycophancy-in-gpt-4o
✦ Stratechery | An Interview with OpenAI CEO Sam Altman About Building a Consumer Tech Company → https://stratechery.com/2025/an-interview-with-openai-ceo-sam-altman-about-building-a-consumer-tech-company | 中文版本
从多个社区的反馈来看,Gemini 2.5 Pro 终于拿到了它应得的认可,成为开发者与先锋用户心中的首选模型。这是 Google 一次极为有力的自我证明,一扫早期的阴霾,重新回到人工智能竞赛的舞台中央。
不过,耀眼的 Gemini 也只是 Google 整体战略的冰山一角。Google Cloud Next '25 大会,为外界清晰地勾勒出了 Google 在 AI 领域广泛而深远的布局。
4 月 9 日至 11 日,Google Cloud Next '25 大会在拉斯维加斯举行,35,000 多名从业人员与 350 多家赞助合作伙伴参与了会议。
Google Cloud Next 自 2016 年首办以来,已经成功举办了十届。Next '25 会议主题是 AI-Driven Transformation(AI 驱动的转型),系统阐述了 Google 将 AI 全面渗透至云平台各个层级的决心与能力,推动 AI 从概念验证走向企业规模化部署,切实创造商业价值。

特别值得一提的是,官方发布了一份包含 229 项更新的大会总结,内容横跨 AI 基础设施、数据处理、安全防护及开发者工具等多个领域,让外界得以窥见 Google AI 商业帝国的宏伟版图。随便挑几个我们比较熟悉的:Gemini 2.5 Flash、Imagen 3、Veo 2、Vertex、Agent Development Kit(ADK)、Agent2Agent(A2A) protocol、Deep Research agent、AlphaFold 3、Ironwood、 Gemini Code Assist、Firebase Studio……
2022 年底,ChatGPT 横空出世,OpenAI 真的完成了初创时的雄心壮志,把 Google 拽下了王座。
从疲于应对到重回巅峰,Google 经历了非常艰辛的两年:内部进入 Code Red(红色警报)状态、Bard 聊天机器人回答踩中敏感话题、Google Brain 与 DeepMind 整合为 Google DeepMind、Gemini 系列模型正式入局、强势将 AI 功能整合到几乎所有产品线中(包括 Google 搜索),以及发布会一次次被 OpenAI 截胡…、
在最艰难混乱的时候,Google 员工聚集在走廊里聊天,担心 Google 可能成为下一个雅虎。

Google 是如何在两年内完成蜕变的呢?前段时间,WIRED(连线杂志)采访了 50 多名 Google 员工,包括工程师、市场人员、法律专家、安全顾问以及十几名高管,回顾了这段艰辛但也传奇的历程,内容非常详细(因此略微有点「流水账」)。
回过头看,此轮竞赛中,Google 是大型科技企业里面应对最有效、策略最彻底、体系最完善的组织,没有之一。
在 AI Native 产品创意层面,Google 也是大型科技公司里面最出色的。我们熟知的 AI Overview、AI Mode,NotebookLM,Whisk、Learn About、Firebase Studio 等等,全都来自于 Google,而且是内部一个「神秘」组织 —— Google Labs。
前段时间,Google Labs 副总裁 Josh Woodward 在访谈中揭秘了 Google Labs 的运营精髓。我摘录几个印象深刻的点,推荐你阅读原文,找找他们层出不穷的创意到底从何而来!
其一,Google Labs 独立于其他产品部门,专注于开发创新型 AI 产品,核心使命是通过实验和快速迭代,在 50 到 100 天内完成创意的市场验证。
其二,Google Labs 人才团队非常多元,不仅有经验丰富的 Google 资深员工,还吸纳了外部优秀的全能型创业人才,也会邀请作家、音乐家等专业创作者深度参与产品设计。
其三,Google Labs 推崇实验精神与对失败的高度容忍,鼓励团队大胆尝试。产品能获取少量(如一万名)高粘性周活跃用户,即被视为重要的阶段性胜利。

✦ Google | 229 things we announced at Google Cloud Next '25 – a recap → https://cloud.google.com/blog/topics/google-cloud-next/google-cloud-next-2025-wrap-up
✦ WIRED | Inside Google’s Two-Year Frenzy to Catch Up With OpenAI → https://www.wired.com/story/google-openai-gemini-chatgpt-artificial-intelligence | 中文版本
✦ Josh Woodward | Google Labs is Rapidly Building AI Products from 0-to-1 you → https://www.youtube.com/watch?v=3-wVLpHGstQ | 中文版本
Amazon 过去两年间在大模型领域一直比较低调,研发重心更多服务于内部业务和云客户。然而,从 4 月开始,Amazon 突然在模型、产品、Agent 等多个维度同时发力,以惊人的速度和效率,仅用一个月就搭建起了基本框架。管中窥豹,Amazon 内部战略规划之成熟、执行力之强大,可见一斑。
4 月 1 日,Amazon Nova Act,浏览器 AI Agent 及开发 SDK 发布。
4 月 8 日,Amazon Nova Sonic 通用音频基础模型发布,单一框架整合理解和生成能力。
4 月 30 日,Amazon Nova Premier 多模态基础模型的旗舰版本发布。
整体梳理下 Amazon Nova 目前的模型体系:
理解模型:
创意模型:
语音转语音模型:
为了让普通用户也能便捷体验 Nova 模型的能力,Amazon 专门上线了免费体验网站 Amazon Nova(如下方图片所示)。用户通过邮箱或亚马逊账户轻松注册,就可以试用包括文本对话、绘画生成、语音处理在内的多种模型功能了。
网站更新非常快!3 月 31 日上线,目前已经把基本功能追了个七七八八,而且最新的 Agent 领域也没落下,已经先后公布了 Nova Act 和 SDK(类似 OpenAI Oprater),看演示效果还行。
2024 年 11 月 19 日,Perplexity 推出 AI 购物功能,一键完成从搜索到购买的全链路。
4 月 29 日,ChatGPT 搜索功能升级购物体验,向全球用户(含免费及未登录)提供商品查找、比较与购买服务。
近期,AI 头部公司开始试水电子商务业务,纷纷上线 Shopping 功能,并引起了不小的反响。其中,比较出圈的是 Perplexity AI 和 ChatGPT。
BUT!美国电商领域的王者 Amazon 才是这个赛道拥有绝对优势的玩家:领先的电商平台、海量的真实购物数据以及成熟高效的物流配送网络。Amazon 这些核心资产,一旦与顶尖大模型实现深度整合,能构建起从智能搜索、精准个性化推荐到无缝线下履约的商业闭环。这种生态级的壁垒,是其他 AI 创业公司在短期内难以复制和逾越的。
✦ Amazon Nova 官方页面 → https://aws.amazon.com/ai/generative-ai/nova
✦ Amazon Nova 体验网站 → https://nova.amazon.com
最近,关于「大模型刷榜」的讨论又开始变多了。与以往对「碾压 GPT-4」「远超 Claude 3.5」陈词滥调的批评不同,这轮讨论直指技术操作层面,切实抓住了模型厂商和排行榜弄虚作假的证据。
至此,「刷榜」话题超越了宣传策略的道德范畴,演变为可能实质性扭曲榜单表现、甚至误导模型研发方向的严重问题。曾经「投机取巧」的捷径,终于被验证是一条彻头彻尾的歧途。
4 月 6 日,Meta 推出 Llama 4 系列模型,包含 Scout、Maverick 和仍在训练中的 Behemoth 三个版本。
Meta 上个月把脸丢到了全世界面前。Llama 4 发布时宣称在 Chatbot Arena 获得了极高排名,但随后被开源社区打假并实锤,一并击碎了行业的殷殷期待。一周时间,从「开源之光」跌进「信任危机」,把开源之王的宝座彻底拱手让了出去。
我们快速捋一下事件脉络:
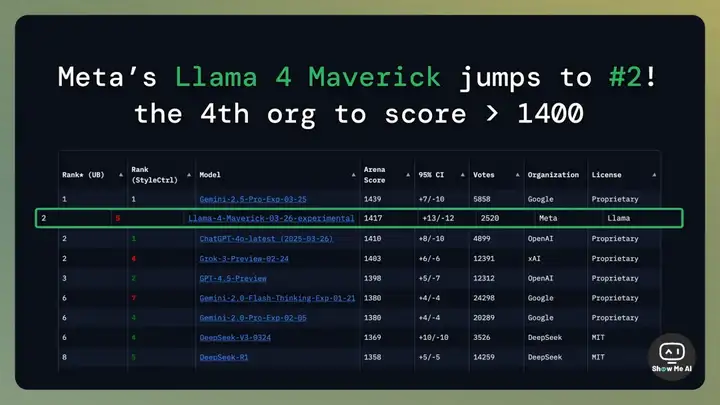
4 月 6 日,Meta 推出 Llama 4 系列模型,包含 Scout、Maverick 和仍在训练中的 Behemoth 三个版本,并高调宣称 Maverick 版本在 Chatbot Arena 拿到了第二名的好成绩,仅次于 Gemini-2.5-Pro。
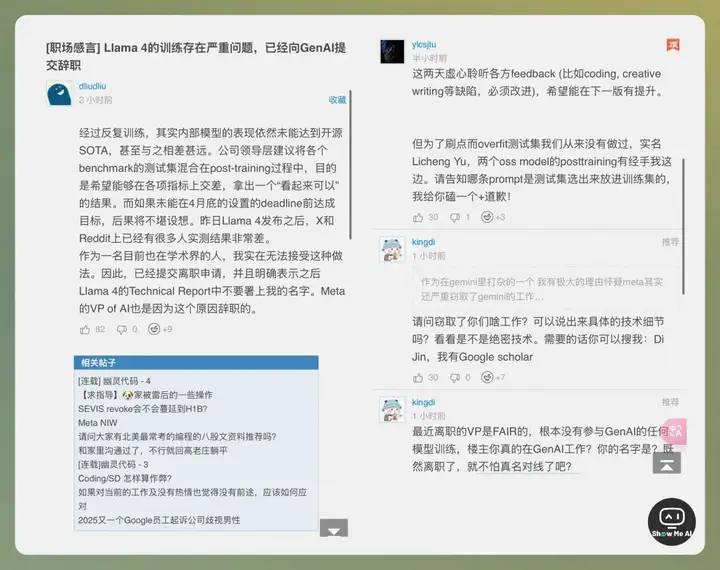
4 月 7 日,「一亩三分地」网络论坛上,有自称参与 Llama 4 训练的员工爆料称,模型在训练后期针对性地混入了 Benchmark 测试数据,以此来提升榜单表现。
很快,Meta 研究科学家主管 Licheng Yu 实名辟谣(如上图所示),Meta GenAI 团队负责人 Ahmad Al-Dahle 也发帖澄清,确认 Llama 4「没有在测试集上进行训练」。
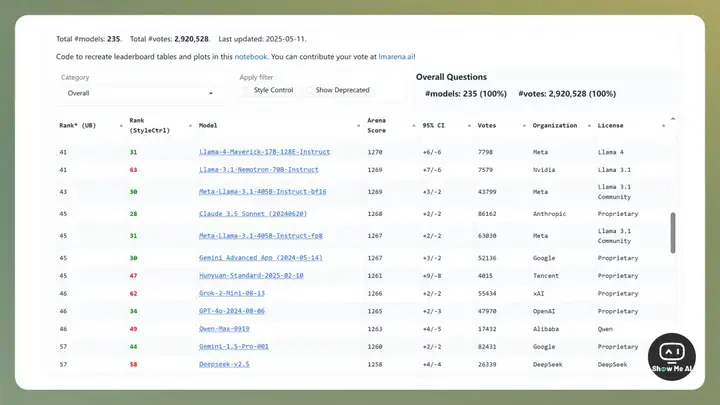
4 月 8 日,开源社区开发者发现,Meta 提交给 Chatbot Arena 的模型版本与公开发布的开源版本存在显著差异。
Chatbot Arena 随后说明,先前榜单上的高分模型 Llama-4-Maverick-03-26-Experimental 是一个经过人类偏好深度优化的定制版本。算是承认了。
最终,Llama-4-Maverick 公开发布的开源版本在 Chatbot Arena 的对战成绩,从第二名滑落至二十名开外,坐实了公众的疑虑。(在 5 月 11 日更新的排行榜里已经滑落到了 41 名)
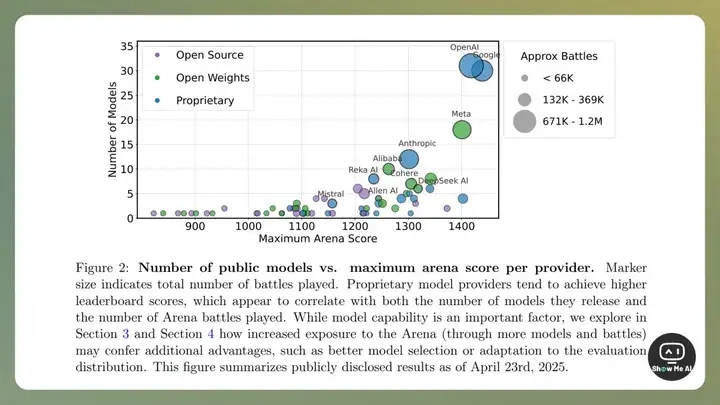
两周后,一篇名为《The Leaderboard Illusion》的论文,进一步揭发了头部模型厂商与 Chatbot Arena 之间的种种「潜规则」,直指当前评估机制的深层缺陷。
作者团队有成员就职于 Cohere 实验室,曾参与模型训练并向 Chatbot Arena 提交模型。他们在操作过程和对榜单的长时间观察中,发现了排名被操纵的痕迹:OpenAI 和 xAI 的模型曾在同一天轮流占据榜首,Google和 OpenAI 也曾在几天内交错拿到第一名。这么频繁的排名更新,显然违背了常理和平台自身规则。
所以!有猫腻!作者团队开始收集数据,把少数模型厂商与 Chatbot Arena 之间的作弊方式,扒了个干干净净:
作弊方式1:Chatbot Arena 允许少数特权厂商(主要是 Meta、Google、OpenAI、Amazon 等)同时提交多个模型变体进行匿名测试,最终只选择性地公开表现最好的版本。仅仅 3 月份,Meta 公司就私测了 27 个版本,Google 私测了 10 个版本。(然后,Llama 4 和 Gemma 3 就发布了)
作弊方式2:部分商业闭源模型在 Chatbot Arena 社区对战中获得了远超开源模型的曝光与用户反馈数据(67.7%)。这种事实上的数据倾斜,为其模型迭代优化提供了不公平的优势。
作弊方式3:实验发现,针对特定榜单进行少量微调(如加入 Chatbot Arena 对战数据),能显著提升模型在该榜单的排名,但对其在其他任务上的真实泛化能力助益甚微,甚至可能造成损害。也就是说,Chatbot Arena 榜单上的高分模型不一定能力更强,也有可能是过拟合了。
4 月 4 日,Midjourney V7(alpha)图像生成模型,提升理解能力与图像质量。
面对 Benchmark 和排行榜的残酷内卷,部分模型及产品团队选择了一条看似更「取巧」的路径:避开硬核的量化指标竞争,转而全力优化用户感官体验,对齐当前主流的人类审美偏好。比如,近期更新的 Midjourney v7 侧重于细节清晰度和画面质感,可灵 2.0 侧重于画面美学和流畅度,Suno 4.5 侧重于音质和人声表现力。
短期内,这种策略当然是奏效的,「好看」和「好听」就是硬道理,用户喜欢就可以,何必在榜单上卷生卷死。但是,从更长远的视角来看,过度依赖人类主观品味就注定会被人类当前水平所束缚,永远做不出超越人类的模型和产品。
Midjourney v7 发布后,资深用户反馈其进步幅度不及预期。团队应该已经开始品尝 The Bitter Lesson(苦涩的教训)了。

"历史的经验一次又一次地告诫我们:
1)AI 研究者常常试图将人类的知识灌输到 AI 算法中;2)这种做法在短期内通常有效,并且能给研究人员带来个人的成就感和虚荣心;3)但从长远来看,它会造成瓶颈,甚至阻碍进一步发展;4)最终的突破性进展往往源于一种截然不同的思路,即通过搜索和学习来扩展算力规模。而那些最终的成功往往伴随着是苦涩,常常难以被下咽,因为算力的成功意味着对我们所虚荣的以人类为中心的固有思维一记响亮的打脸。
优秀的 Benchmark 有助于模型智能增长,平庸的 Benchmark 会把模型带到反面。现有主流 Benchmark 的全面性与有效性已然捉襟见肘,有些还为模型厂商「应试优化」提供了可乘之机。
行业迫切需要建立一套全新的、能够更真实、更全面反映大模型核心能力的测评基准体系。这方面走在前沿的,依然是 OpenAI(国内字节跟进)。以下是 OpenAI 和 字节跳动近期发布的新测试基准,你也可以从中窥见接下来一段时间内的模型发展趋势。
✦ Chatbot Arena → https://lmarena.ai/?leaderboard
✦ Chatbot Arena 承认的帖子 → https://x.com/lmarena_ai/status/1909397817434816562
✦ The Leaderboard Illusion → https://arxiv.org/abs/2504.20879 | 中文版本
✦ The Bitter Lesson(苦涩的教训)→ http://www.incompleteideas.net/IncIdeas/BitterLesson.html | 中文版本
✦ The Second Half → https://ysymyth.github.io/The-Second-Half | 中文版本
2024 年 10 月31 日,Recraft Recraft V3 图像生成模型发布。
3 月25 日,Reve Reve Image(Halfmoon)图像生成模型发布发布。
4 月 15 日,字节跳动 Seedream 3.0(Mogao)图像生成模型,原生高清输出与商业级文本效果。
Artificial Analysis 是一家提供 AI 模型性能数据的分析机构,其发布的各类 Leaderboard(排行榜),特别是「文生图(Text To Image)」细分榜单,已成为行业观察模型能力的重要参考之一。
该榜单首次大规模进入公众视野,是去年名不见经传的 red_panda 模型超越 FLUX1.1 意外登顶,引发了大众的好奇心。几天后,该模型被一家英国初创团队 Recraft AI 认领并正式发布。之后,同样丝滑的宣传小连招偶有触发但无伤大雅,直到我看见字节也用上了这个套路😏
要知道,在竞争激烈且套路满满的模型营销环节,被各大厂商盯上的宣传渠道,其真实性和公正性就要被打上一个大大的问号了 (•_•)??
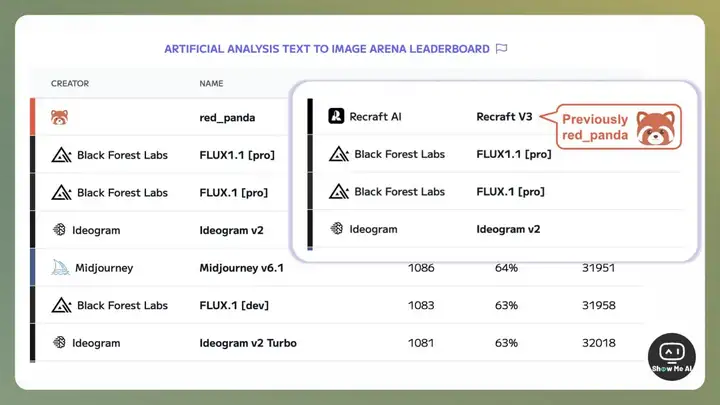
第一步:新模型突然登顶。
2024 年 10 月 28 日,red_panda 模型登上 Artificial Analysis 网站 Text To lmage 细分榜单第一名。Artificial Analysis 截图发 X 表示疑惑。
第二步:几天之后再揭秘。
2024 年 10 月 31 日,Artificial Analysis 再发 X 宣布,red_panda 模型正式名称为 Recraft V3,所属公司 Recraft AI 是一家位于英国伦敦的平面设计公司。
第三步:团队认领并发布。
同一天,Recraft AI 团队发帖认领,模型正式发布。
第一步:新模型突然登顶。
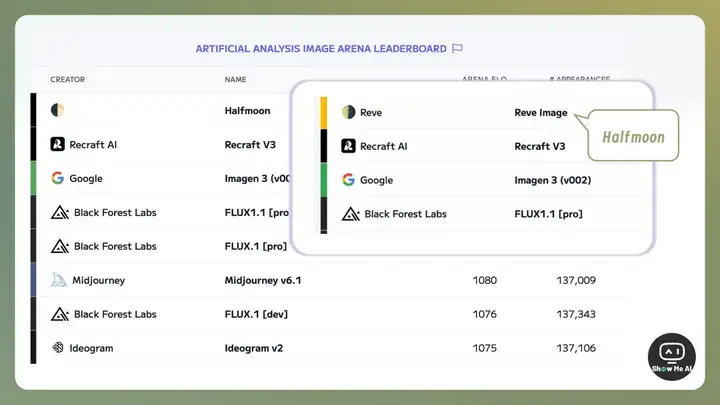
3 月 19 日,Halfmoon 模型登上 Artificial Analysis 网站 Text To lmage 细分榜单第一名。Artificial Analysis 截图发 X 表示疑惑。
第二步:几天之后再揭秘。
3 月 25 日,Artificial Analysis 再发 X 宣布, Halfmoon 模型正式名称为 Reve Image。
第三步:团队认领并发布。
同一天, Reve 团队发帖认领,模型正式发布。
第一步:新模型突然登顶。
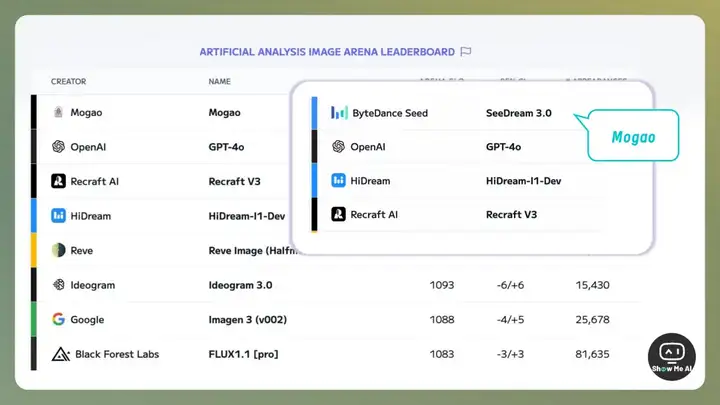
4 月 13 日,Mogao 模型登上 Artificial Analysis 网站 Text To lmage 细分榜单第一名。Artificial Analysis 截图发 X 表示疑惑。
第二步:几天之后再揭秘。
4 月 15 日,Artificial Analysis 再发 X 宣布,Mogao 模型正式名称为 SeeDream 3.0,所属团队 Dreamina AI(即梦)是 ByteDance(字节跳动)的图像&视频团队 。
第三步:团队认领并发布。
同一天, Dreamina AI(即梦)团队发帖认领,模型正式发布。
✦ Recraft V3→ https://x.com/recraftai/status/1851706399631224939
✦ Reve Image → https://x.com/reveimage/status/1904211082870456824
✦ SeeDream 3.0→ https://x.com/dreamina_ai/status/1912145370978881763
✦ Artificial Analysis 文生图榜单 → https://artificialanalysis.ai/text-to-image/arena
最近两个月,Agent 最火爆但也最让人困惑。Manus 的爆火,首次将 Agent 从抽象概念推进到产品时代,但也在公众认知中形成了一些初步的、可能不完全准确的「刻板印象」。就在这半明半昧的热闹里,MCP 和 Agent 风风火火地发展起来了。
从 4 月份的行业动态来看,Agent 领域的讨论主要围绕三大方向展开:协议、生态、应用。
4 月 11 日,Google Gemini 模型将支持 MCP 协议。
Anthropic 在此领域布局较早,早在 2024 年 10 月就已经发布了 MCP(Model Context Protocol)。目前,OpenAI 和 Google 已经陆续宣布接入 MCP。
Google 在 2025 年 4 月的 Cloud Next '25 大会上正式推出了 A2A(Agent-to-Agent)开放协议。OpenAI 则围绕 Agent 开发构建基础生态,目前已经公开的工作就有 Operater、Response API、Codex CLI、Agents SDK、Deep Research、o 系列推理模型等等。
4 月 9 日,阿里云百炼上线业界首个全生命周期 MCP 服务。
4 月 9 日,腾讯云上线 AI 开发套件(SDK),可以快速搭建 AI Agent 小程序,并提供 MCP 插件托管服务。
阿里巴巴和腾讯同一天宣布了 Agent 方向的进展,都是希望降低 Agent 的开发门槛,并且构建属于自己的垂直 Agent 开发平台。阿里的动作幅度更大。
4 月 2 日,Genspark AI Super Agent 通用 AI Agent。
4 月 22 日,Fellou.ai 是全球首款 Agentic Browser(内测)。
4 月 19 日,字节跳动 Coze Space(扣子空间)AI Agent 应用内测。
自 Manus 一鸣惊人之后,Agent 应用的巨大潜力被市场充分认知,相似或同类型的 Agent 产品如雨后春笋般涌现。赛博月刊收录了 4 月份在国内市场获得较高关注度的 Agent 应用。

✦ Anthropic | Building effective agents → https://www.anthropic.com/engineering/building-effective-agents
✦ Google | Agents → https://www.kaggle.com/whitepaper-agents
✦ OpenAI | A practical guide to building agents → https://cdn.openai.com/business-guides-and-resources/a-practical-guide-to-building-agents.pdf
✦ Genspark Super Agent → https://www.genspark.ai
✦ Fellou.ai → http://fellou.ai
✦ 扣子空间(Coze Space)→ https://www.coze.cn/space-preview
Jomy 写了一个系列,目前更新了两篇,厘清了 MCP 和 Agent 的原理和基础知识。读完应该会刷新你的认知。
聊一聊 Tool、MCP 和 Agent 来龙去脉 | 大白话技术科普系列@Jomy
AI下半场,聊一聊 Agent 本质与变革 | 大白话技术科普系列@Jomy
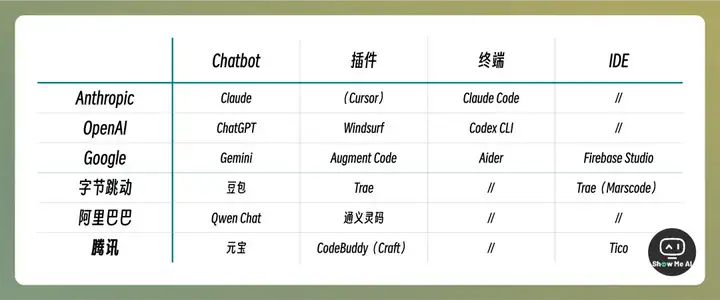
随着 Cursor、Winsurf、V0、Bolt.new 等辅助编程产品的陆续崛起,AI Coding 赛道最近变得异常拥挤。科技巨头也不甘示弱,近期密集发布或更新了自家 AI Coding 应用,其产品形态和功能定位也呈现出了高度的趋同性。
这种高度一致的布局背后,是各大厂商之间心照不宣的战略默契,也是抢占高质量代码数据、锁定核心开发者群体等深层原因。当然,或许还有其他尚未显露的、更为长远的战略意图。
以下是对主要厂商在 AI Coding 领域产品形态的梳理与归纳:
整理月刊资料时,一个集中且有趣的现象浮现在我眼前:多个在各自领域具备一定知名度的产品团队,果断选择战略转型并取得了成效,新方向带来了更大的市场关注和认可。
在大模型能力迭代升级、创新产品层出不穷的当下,及时转型是产品团队要做出的艰难但必要的选择。成功的转型,能带领产品迎来「柳暗花明又一村」的全新局面。
以下重点介绍赛博月刊 4 月份收录的成功转型案例,希望能为从业者带来一点信心和启发:
4 月 1 日,Higgsfield AI 上线 DoP I2V-01-preview 视频生成模型,具有专业运镜效果。
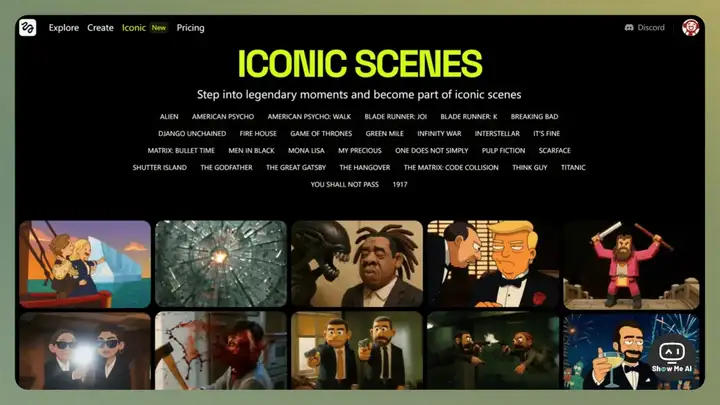
4 月 29 日,Higgsfield AI 上线 Iconic Scenes 功能,将照片一键融入经典电影场景。
Higgsfield AI 此前聚焦在 AI 视频工具领域,从 4 月份开始,战略重心转向了专业影视级视频生成与特效制作。凭借 4 月 1 日发布的 DoP I2V-01-preview 视频生成模型,以及 4 月 29 日上线的 Iconic Scenes 功能,Higgsfield AI 以令人耳目一新的技术实力和应用场景,拿到了非常棒的成绩。
4 月 2 日,Genspark AI Super Agent 通用 AI Agent。
Genspark 创始团队拥有前百度高管背景,早期定位是 AI 搜索引擎。搭乘近期 Manus 的东风,Genspark 果断调整航向,于 4 月 2 日正式推出了其通用 AI Agent 产品——Super Agent。
据 Genspark CEO Eric Jing 透露,Super Agent 发布后短期内即实现了千万美金级别的 ARR,为此团队不惜关停了已拥有数百万用户的原 AI 搜索产品,将公司资源全面聚焦于 AI Agent 的研发与推广。

✦ Higgsfield AI → https://higgsfield.ai
✦ Genspark → https://genspark.ai
文章来自于“ShowMeAI研究中心”,作者“南乔River”。



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
