# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当前顶尖AI模型是否真能“看懂”物理图像?
全谱系多模态物理推理新基准来了,结果SOTA级模型准确率都不足55%。
新基准名为SeePhys,强调了图形感知对于模型认识和理解物理世界的重要性。
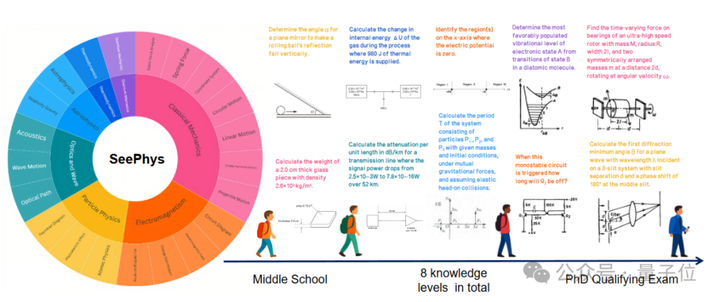
内容涵盖经典与现代物理的各个知识等级和领域,包括从初中到博士资格考试的全谱系多模态物理问题。

它由中山大学、苏黎世联邦理工学院、华为诺亚方舟实验室和香港大学的研究团队联合推出,于近日正式开源。
团队在实验中系统性评估了LLM/MLLM在复杂科学图表与理论推导耦合任务中的表现。
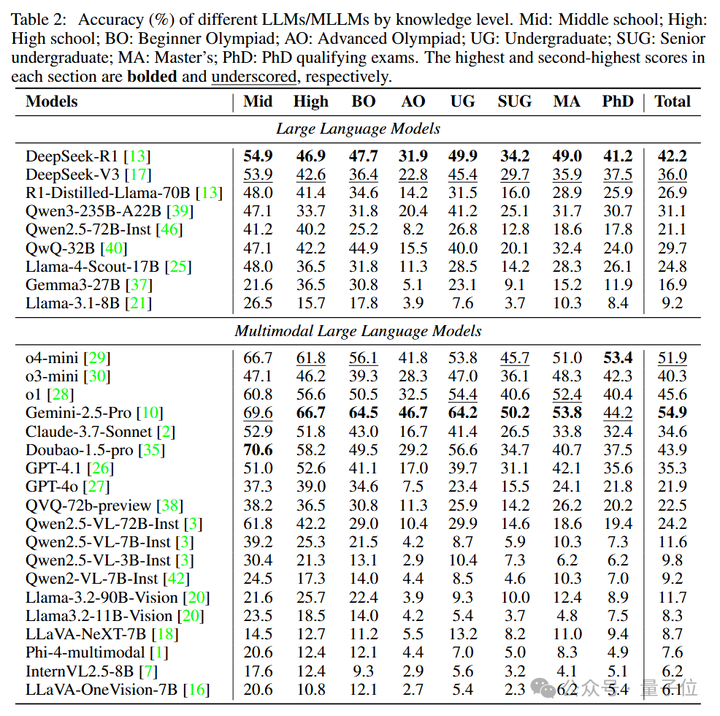
结果表明即使是Gemini-2.5-Pro和o4-mini等SOTA模型准确率都不足55%,暴露出多模态推理的巨大挑战。
团队表示,目前该基准正在ICML 2025 AI for MATH Workshop中开放评估,欢迎学界与工业界的团队来挑战。

近年来,数学在大语言模型(LLMs)的推理能力评估中大放异彩,而物理学由于其具有与真实场景的强相关性和更复杂的图像信息,正在多模态测评中得到越来越多的重视。
物理学不仅知识体系庞大、逻辑链条复杂,而且天然地将抽象世界规律与千变万化的视觉图像紧密结合。无论是电路图、受力分析图,还是费曼图等,都挑战了多模态大模型根据图表理解世界本质规律的能力。
现有物理学基准或缺乏视觉组件,或仅覆盖单一的知识层级,难以全面评估模型的物理思维能力。
SeePhys的诞生填补了这一空白,它旨在回答当前的顶尖AI模型是否真的“看懂”了物理图像,并能像人类科学家一样结合图像进行思考。
SeePhys的独特之处在于:
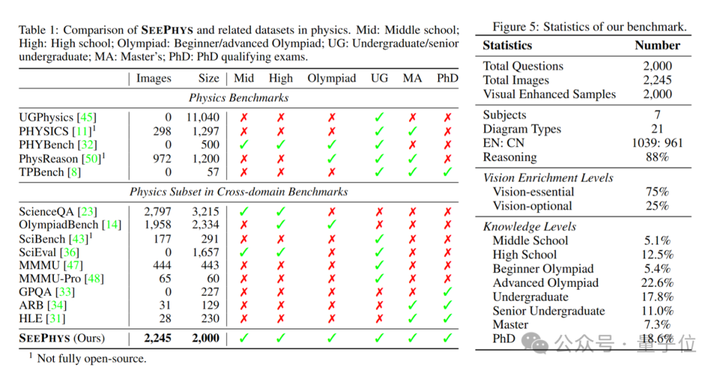
具体来看,SeePhys具有以下几个关键属性。
首先是全谱系覆盖:
其次是不同的视觉富集程度:
还有多模态增强设计:
通过对28个主流模型(包括o4-mini、Gemini-2.5-Pro、Claude-3.7-Sonnet等)的大规模测试,研究团队总结以下结论:
视觉-文本对齐能力的缺陷:
“看见”对于“思考”的重要性:
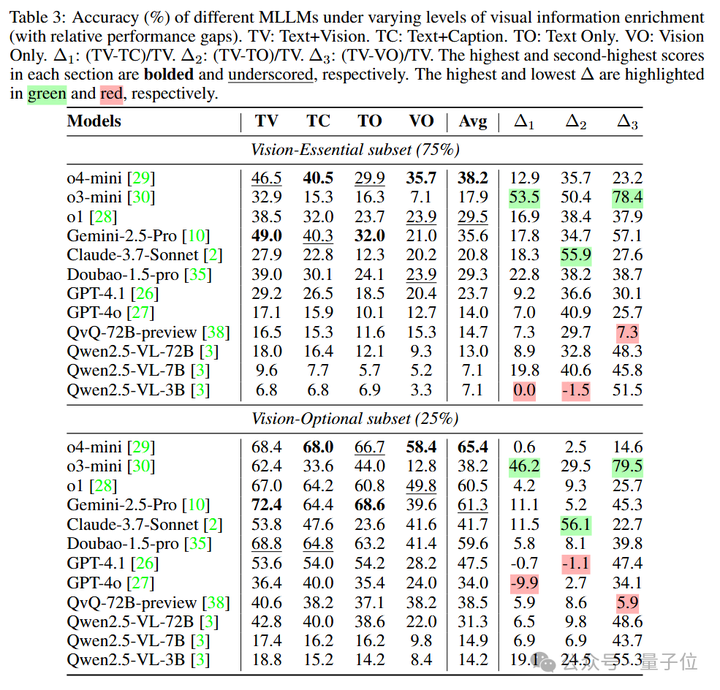
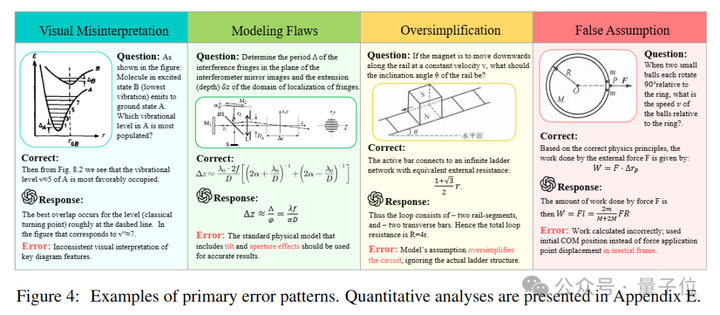
错误推理模式归纳
研究团队对强模型o4-mini, Gemini-2.5-Pro与弱模型Qwen2.5-VL-3B共同错误的100个样本进行人工分析。
然后,归纳得出了9种错误的推理模式,包括视觉误读、文本误读、建模错误、错误假设、数值计算错误、过度简化、总结错误、过度思考和重复输出。
所有三个模型都表现出明显的建模缺陷(例如定理和公式误用),同时表现出相对较少的文本误读和数值计算错误。
而过度思考和过度简化的错误频率在模型之间存在显著差异,且较小的Qwen2.5-VL-3B出现了高重复输出率(21%)。
参赛链接:https://www.codabench.org/competitions/7925/
挑战赛详细信息:https://sites.google.com/view/ai4mathworkshopicml2025/challenge
ICML workshop 主页:https://sites.google.com/view/ai4mathworkshopicml2025/home
论文:https://arxiv.org/pdf/2505.19099
项目主页:https://github.com/SeePhys/seephys-project
本文来自于“量子位”



