# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来随着大语言模型的爆火,旨在取代 Transformer 的高效模型架构及其预训练成为大模型领域的研究热点,主要包括线性序列建模(如 Linear Attention、SSM、Linear RNN 等)和混合专家(Mixture-of-Experts, MoE)两部分。这两部分分别都有了长足的进步,但两者的结合却鲜少有人研究,两者结合后的 Linear-MoE 架构开源实现更是完全缺失。
值得一提的是,近期广受好评的 MiniMax-01 模型(使用 Lightning Attention-MoE)和腾讯混元 TurboS 模型(使用 Mamba2-MoE)均属于 Linear-MoE 架构。
来自上海人工智能实验室团队的最新成果 Linear-MoE,首次系统性地实现了线性序列建模与 MoE 的高效结合,并开源了完整的技术框架,包括 Modeling 和 Training 两大部分,并支持层间混合架构。为下一代基础模型架构的研发提供了有价值的工具和经验。

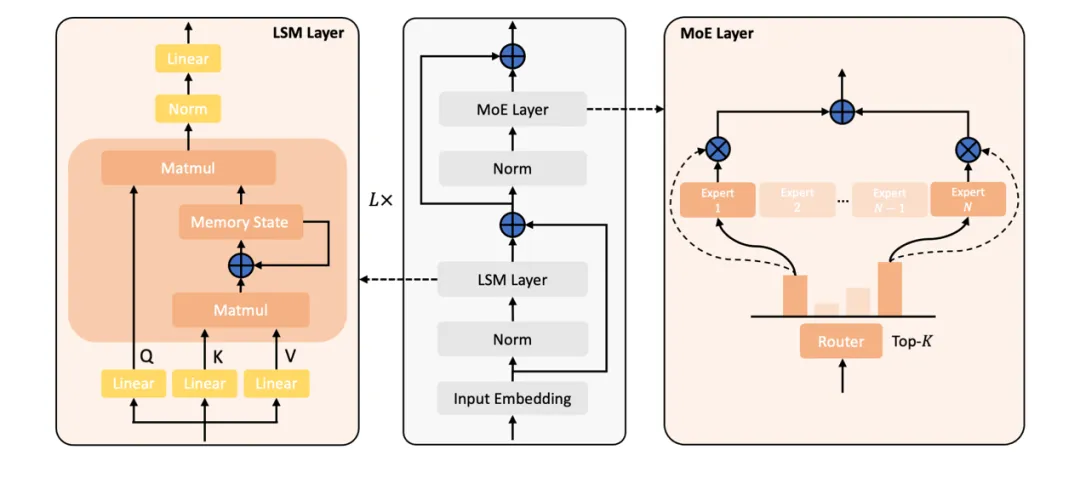
过去两年,线性序列建模技术取得了显著进展,其核心优势在于线性时间复杂度的训练和恒定内存占用的推理。
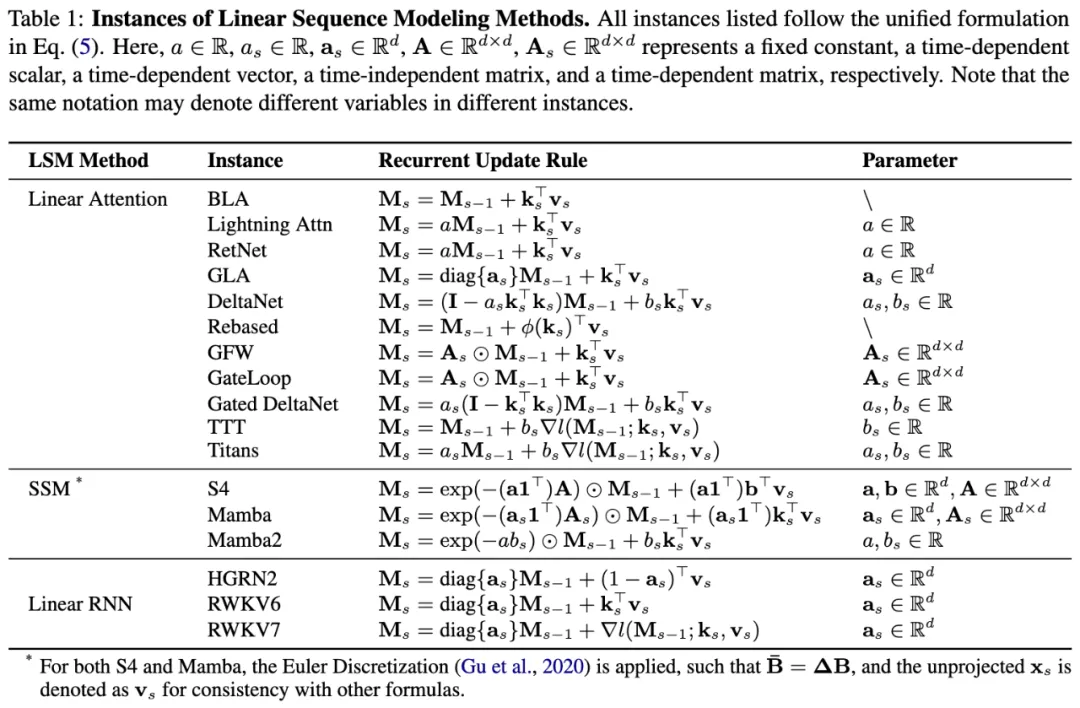
这类模型主要分为三大类:线性注意力(Linear Attention)、状态空间模型(SSM)和线性 RNN(Linear RNN),代表性工作包括 Lightning Attention、GLA、Mamba2、RWKV 等。
已有研究工作表明,这些模型实际上可以通过统一的递归形式进行表达,如下表所示。这也反映出,尽管三类方法分别出自不同的技术流派,但已逐渐收敛至统一的表达形式。
另外一方面,从国际上的 GPT-4 系列、Gemini 系列、Claude 系列到国内的 DeepSeek 系列、Qwen 系列、腾讯混元 LLM、字节豆包、MiniMax-01、Moonshot-Kimi 等,都在步伐一致地 All in MoE。其重要性不言而喻,本文不做过多展开。
Linear-MoE 的核心贡献在于构建了一个从 Modeling 到 Training 的完整系统,支持线性序列建模层与 MoE 层的灵活组合,同时兼容传统的 Softmax Attention Transformer 层,支持形成混合架构。其设计亮点包括:
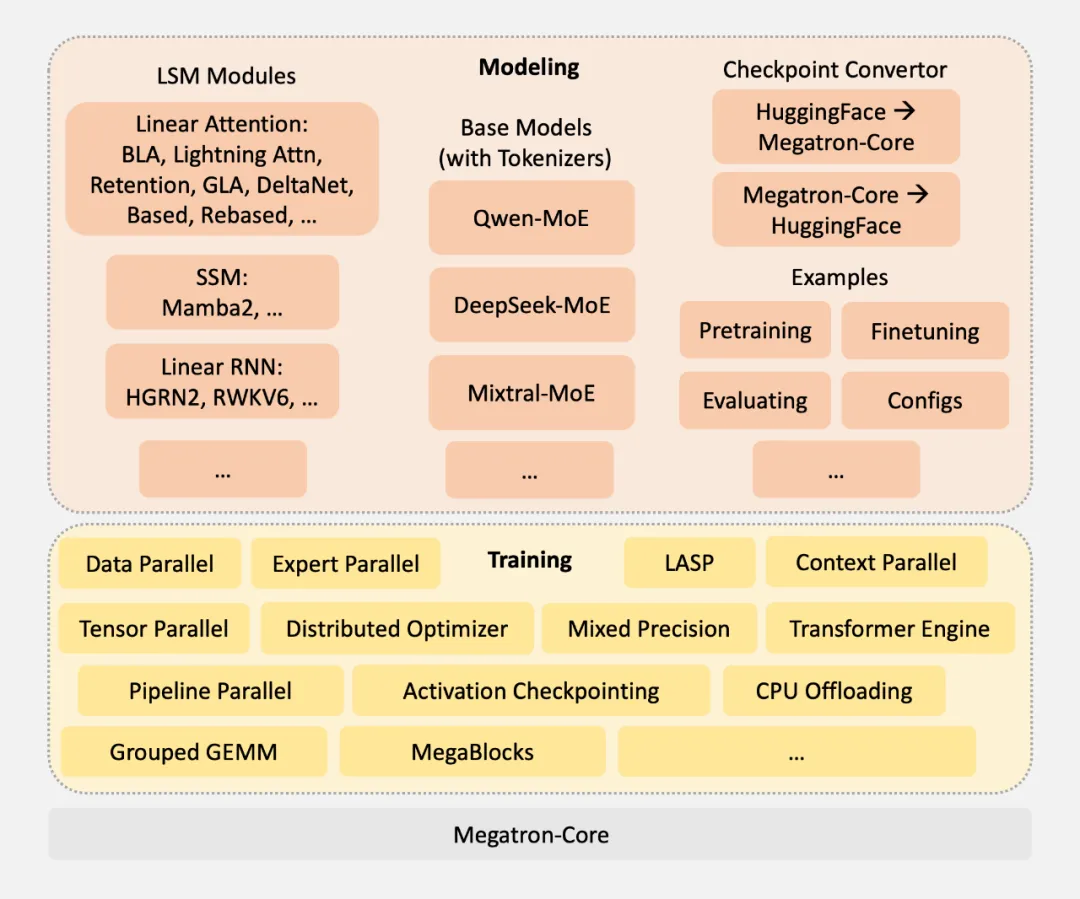
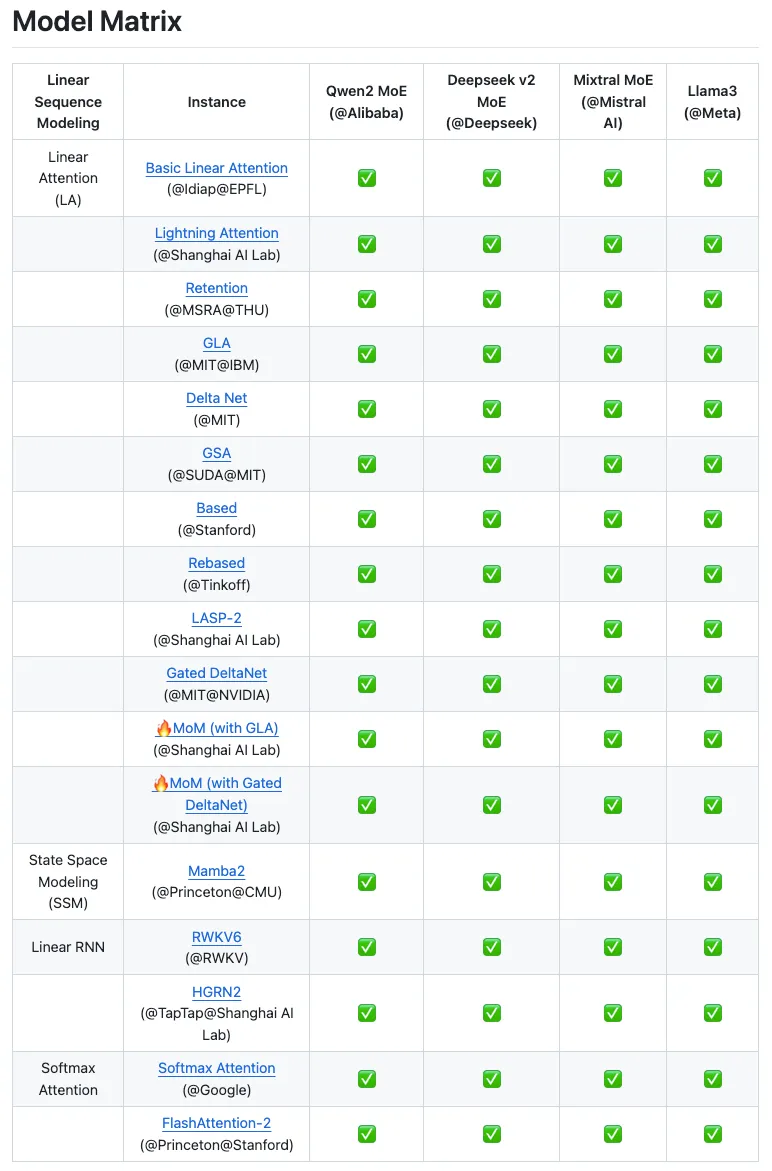
大规模实验验证了 Linear-MoE 的优越性:
目前 Linear-MoE 已全面开源,支持多种主流的线性序列建模方法和 MoE 实现。这一工作不仅填补了线性建模与 MoE 结合的技术空白,还为社区提供了可复现的高效训练方案。未来将进一步探索 Linear-MoE 在长上下文理解、Vision-Language 模型架构中的应用潜力。
文章来自微信公众号 “ 机器之心 ”




