# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,语言模型技术迅速发展,然而代表性成果如Gemini 2.5Pro和GPT-4.1,逐渐被谷歌、OpenAI等科技巨头所垄断。
与此同时,开源社区的小规模模型正面临日益严峻的挑战——
他们参数规模通常仅在7B左右,难以在多任务、多领域场景中与大型闭源模型相抗衡,尚未形成真正意义上的通用人工智能能力。
在此背景下,上海人工智能实验室联合东北大学、西北工业大学等机构,提出了Avengers框架,旨在探索开源小模型群体智能的新路径。

实验表明,Avengers框架在15个涵盖数学、代码、逻辑、知识和情感任务的数据集上,平均得分超越了GPT-4.1
(OpenAI 4月发布的旗舰模型),并在其中9个数据集上显著更优。
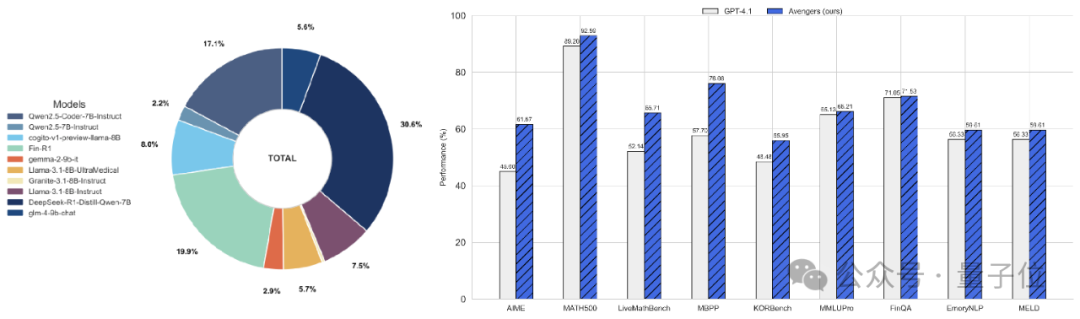
△模型路由分布图与部分任务性能对比
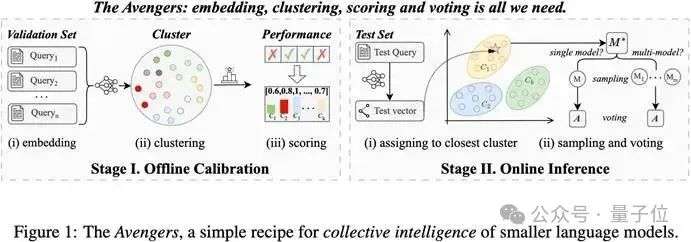
Avengers框架的设计核心是简洁、高效且无需额外训练,通过四个轻量的步骤,集结多个小模型的优势:
1.Embedding:通过嵌入理解问题
无论是系统准备阶段用作学习的验证问题,还是用户实时提出的新问题,框架都会首先利用文本嵌入模型将这些问题“翻译”成语义信息向量。
Clustering:通过聚类构建“任务地图”
在系统准备阶段,Avengers通过计算这些向量间的相似性,将问题划分为不同的簇(cluster),
其中每个簇都代表着一种具备相似性的问题,例如“数学计算区”、“代码生成区”或“逻辑推理区”。
Scoring:为每个模型建立“能力档案”
Avengers利用各个簇的代表性验证问题(验证集)去“考核”模型池中的每一个小模型,并记录下它们在每个问题类别上的表现得分。
Routing & Voting:通过动态路由与投票决策,实现人尽其才,择优输出
当一个新问题进入Avengers后,框架会实时进行处理:
首先,通过语义嵌入理解新问题。
然后,在“任务地图”上迅速定位该问题所属的簇。
接着,系统查阅各模型的“能力档案”,动态选择(路由)在该问题类别中表现最好的一个或多个“专家模型”来生成答案。
最后,通过投票机制(如Self-Consistency),从所有候选答案中选出一致性最高的作为最终输出。
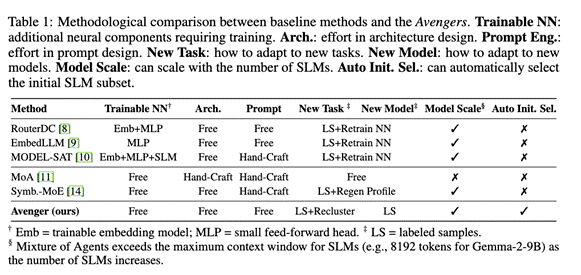
为了全面评估Avengers框架的性能,研究团队选取了覆盖数学推理
(如AIME, Math500,LiveMathBench)、代码生成(MBPP, HumanEval)、逻辑推理(如KORBench, BBH,Knights and Knaves)、知识问答(ARC Challenge,
MMLUPro,GPQA,FinQA,MedQA)和情感分析(如EmoryNLP, MELD)等五个领域的15个公开数据集。
实验中,Avengers框架集成了10个参数量在7B左右的开源小型语言模型。
此外,为了进行更加充分的对比,研究团队还对基线方法进行了增强。
具体而言,对于路由方法(RouterDC, EmbedLLM, MODEL-SAT),统一使用gte-qwen2-7B-instruct作为文本嵌入模型,
推理时统一使用Self-Consistency策略(采样10次)。训练路由时,研究人员人为选取了路由模型的测试集最高性能点作为训练终止点。
对于混合方法(MoA, Symbolic-MoE),研究团队统一使用32K上下文的Qwen2.5-7B-Instruct作为聚合模型(aggregator)。
为了避免模型过多带来的上下文窗口过长问题,研究团队还设计了MoA(Oracle)——推理时使用在当前任务最强的3个模型,而不是全部模型。
核心实验结果表明:
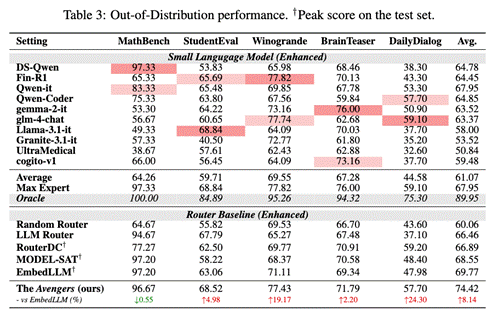
Avengers在无需额外训练的情况下,平均性能最高,并且在分布外泛化(Out-of-Distribution Generalization)任务上表现出更强的鲁棒性,
在OOD测试中平均得分比EmbedLLM高出8.14%。
相比于MoA(Oracle)方法平均得分高出17.16%。
这些结果清晰地证明,通过Avengers框架的有效组织和调度,多个小型模型的“集体智慧”能够达到甚至在某些方面超越顶尖大型模型的水平,
相比于混合式方法,性能优势明显,相比于路由方法,无需训练且OOD性能优秀。
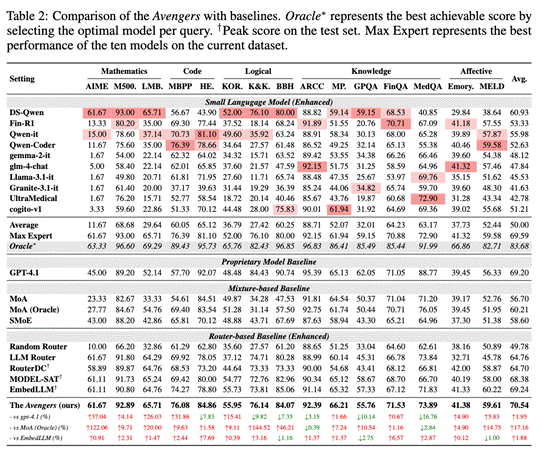
通过细致的消融实验,研究团队探究各组成部分对整体性能的贡献:
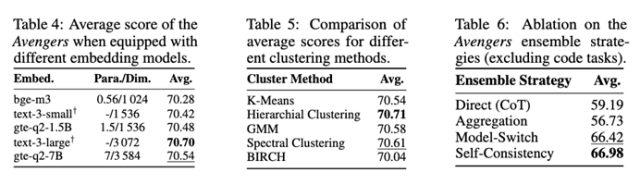
1.对嵌入模型和聚类算法的鲁棒性:实验表明,Avengers框架的性能对于所选用的具体嵌入模型
(测试了从0.56B到7B参数不等的多种模型)和聚类算法(测试了K-Means、层次聚类、GMM等多种经典算法)并不敏感。
这意味着Avengers具有良好的普适性和易用性,不强依赖于特定的组件。
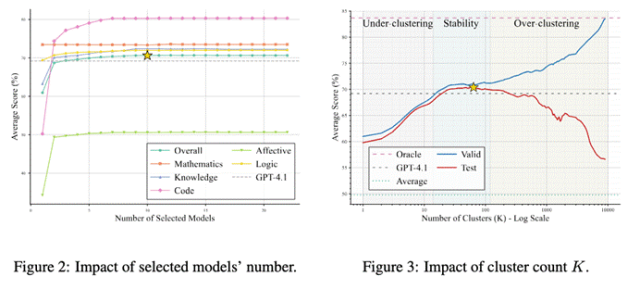
2.模型数量与性能的权衡:研究发现,随着集成的小模型数量增加,Avengers的整体性能也随之提升。
值得注意的是,仅需3个小模型,其性能便可与GPT-4.1持平(根据簇排名自动选择)。
当模型数量达到约10个时,性能趋于饱和,尤其在知识、代码和情感等任务上展现出良好的互补效应。
这说明Avengers能够有效地利用模型的异质性,实现“1+1>2”的效果,而无需盲目堆砌模型数量。
3.集成策略的有效性:在多种输出集成策略中,基于投票的策略被证明是一种简单且高效的选择,
它通过对单个或多个模型进行重复采样及投票,显著提升了最终答案的质量和稳定性。
4.对超参数的低敏感度:以聚类数量K为例,实验显示在一个相当宽泛的K值范围内(约14至140),Avengers均能保持稳定且优于GPT-4.1的性能。
这降低了超参数调优的难度,增强了框架的实用性。
这些特性共同构成了Avengers框架的核心优势:它是一个轻量级、适应性强、且对具体组件选择和超参数调整不敏感的协同解决方案。
Avengers框架的提出和验证,对于当前的AI研究和开源社区具有多重意义:
它证明了通过有效的协同策略,参数量相对较小、资源要求较低的开源模型也能够在复杂任务上取得良好表现,为提升开源模型实用性提供了参考路径。
作为一个无需训练、易于实现的框架,Avengers简化了高性能AI系统的构建流程,有助于更多开发者和研究人员开展相关实验与应用探索。
通过发掘和利用不同模型的独特优势,Avengers展示了模型在特定任务中互补使用的潜力,有助于构建一个更加丰富和多元的AI模型生态。
未来工作将聚焦于以下几个方面:
1.降低初始校准成本
探索更高效的聚类和模型能力评估方法,以减少框架在引入新模型或新任务时的前置计算。
2.扩展应用范围
将Avengers框架应用于更广泛的任务类型(如对话系统、多模态任务)和更多样化的模型(包括更小规模的模型)。
3.动态适应与进化
研究在线学习和动态调整机制,使Avengers框架能够根据实时反馈和环境变化,持续优化其模型选择和集成策略。
本文第一作者张逸群(东北大学博士三年级)和李昊(西北工业大学博士二年级)均为上海人工智能实验室实习生。
通讯作者为上海人工智能实验室研究员胡舒悦和东北大学副教授冯时。
团队其他成员还有实验室实习生王晨旭、陈林尧,以及实验室研究员张乔生、叶鹏、徐甲、白磊、欧阳万里等。
论文链接:https://arxiv.org/abs/2505.19797
代码链接:https://github.com/ZhangYiqun018/Avengers
文章来自于微信公众号 “量子位”,作者 :Avengers团队




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
