# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
孙子兵法有云:“故其疾如风,其徐如林”,意指在行进迅速时,如狂风飞旋;而在行进从容时,如森林徐徐展开。
同样,对于大模型,我们也希望其面对简单问题时能减少思考内容,快速输出答案。而当面对困难问题,其可以进行详尽的思考分析,保证输出的准确性。
传统大模型面临二者不可兼得的困境 —— 快思考面对复杂任务显得力不从心,而深度思考面对简单问题经常输出冗余 token。
为此,华为盘古团队创新性地提出盘古 Embedded 模型,在多个领域实现了高效精准推理。
基于昇腾 NPU,盘古 Embedded 采用双系统认知架构,在一个模型中集成 “快思考” 与 “慢思考” 双推理模式,
并通过两阶段训练及多源动态奖励系统,实现了推理效率与精度的协同提升。

大模型推理长期受制于两大矛盾:长链条深度思考与低时延反馈。
为了解决这个问题,基于昇腾 NPU(Ascend Neural Processing Unit)算力,华为盘古团队提出具备灵活切换快慢思考能力的盘古 Embedded 模型。
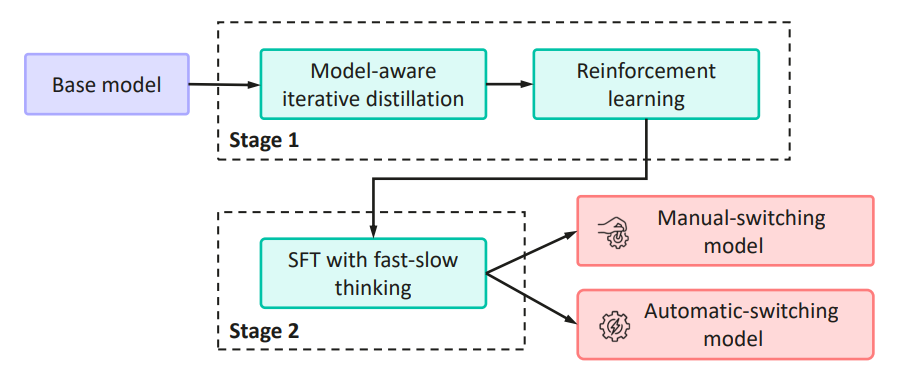
该模型由两阶段训练框架得到:
在阶段 1 中,模型通过迭代式蒸馏,结合训练过程中的模型合并,以高效地聚合互补知识。
RL 过程由多源指导自适应奖励系统(MARS)指导,该系统使用确定性指标和轻量级 LLM 评估器为数学任务、
编码任务和通用任务生成动态的、特定于任务的奖励信号。
在阶段 2 中,通过双系统框架赋予模型用于简单任务的 “快” 模式和用于困难任务的的 “慢” 模式。
该框架提供了用户控制的手动切换以及问题难度感知的自动切换,以取得推理效率和推理深度的动态平衡。
盘古 Embedded 实现了在统一的模型架构中融合快慢思考能力,为开发强大而实用的语言模型指明了方向。
昇腾亲和的快慢思考融合架构:从单推理进化到双推理
问题背景
当前主流的语言模型基于强化学习等策略实现了复杂推理,在数学和代码基准上取得了惊人的成绩。
但是通常存在过度思考的问题,庞大的计算开销限制了其更广泛的部署应用,尤其是在资源受限的端侧设备上。
基模型构建
为了系统性地解决上述问题,华为团队在这项工作中提出了 7B 参数量的盘古 Embedded,该模型同时具备快慢思考能力。
对于预训练数据与分词器,与该团队之前发布的盘古 Ultra 保持一致。
对于后训练数据,引入了推理和非推理多种任务,并通过先验过滤和多样性检验,确保了训练数据的质量和多样性。
在训练策略上,团队提出了基于模型感知型迭代蒸馏(Model-aware Iterative Distillation)的 SFT 方案。
这种方法不仅能够动态选择与模型当前能力相匹配的数据样本进行训练,还能通过训练过程中的模型合并策略保留训练早期的知识,从而实现性能的持续提升。
具体细节如下:
包括规则验证和模型验证,以确保数据质量。
计算出数据复杂度分数,以此衡量数据样本的难易程度。
避免知识遗忘,提升模型的稳定性和泛化能力。
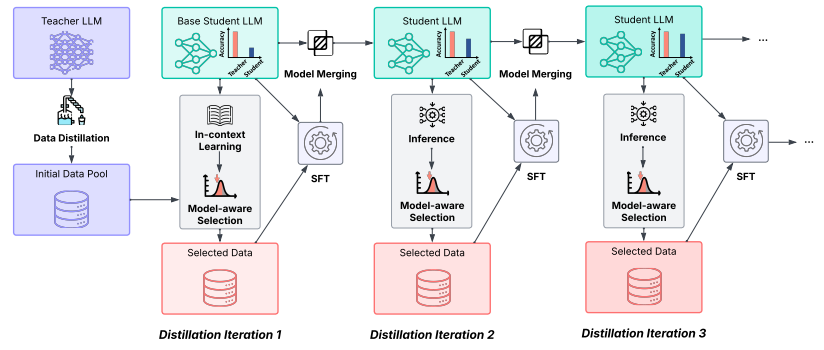
模型感知型迭代蒸馏整体架构
重复输出自修正
为了实现重复输出自修正,团队引入了局部 n-gram 重复检测和显式 prompt 注入。
其中,前者是在限定窗口内进行 n-gram 比较,以低计算量有效检测重复 token。后者则是通过显式注入特定的 prompt,引导模型自主脱离重复输出。
该方案可有效避免生成长篇连贯文本时的内容重复问题,确保输出结果的高质量。
多源自适应奖励系统与课程数据混合策略
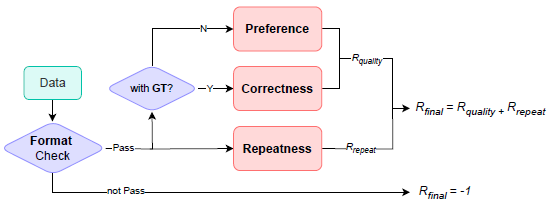
多源自适应奖励系统流程
在强化学习阶段,盘古 Embedded 采用了多源自适应奖励系统(MARS),
该系统融合了正确奖励、偏好奖励和其他奖励三部分,保证了模型输出的稳定性和结构完整性。
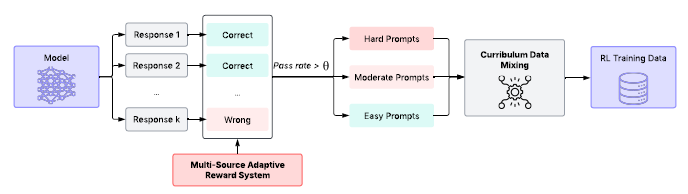
课程数据混合策略
同时,在强化学习阶段,团队还采用了课程学习策略,通过评估每个数据样本对于当前策略的复杂性,
将不同难度的样本组合逐步反馈给模型训练,有助于实现高效且稳定的策略更新。
基于昇腾集群的 RL 基础架构
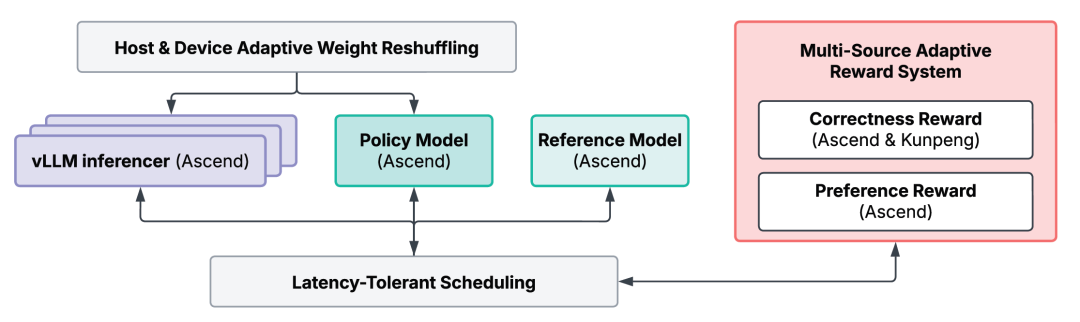
基于昇腾集群的 RL 基础架构
为了实现基于昇腾的大规模 RL 训练,团队还设计了针对昇腾优化的高效可扩展框架。
首先,通过结合延时同步并行(Stale Synchronous Parallel)调度器和分布式优先级数据队列,
该团队解决了大规模 RL 中的协调瓶颈问题,实现了系统吞吐量的显著提升。
在 128 个节点的昇腾集群上,相较于完全同步的基线,该框架可减少 30% 的设备空闲时间,同时保持训练的稳定性。
其次,通过主机和设备之间的自适应权重调整,实现了在训练和推理管道之间的模型参数无缝共享。相比于孤立的训练和推理部署,该方法可将吞吐量提升近 2 倍。
最后,通过面向昇腾的 vLLM 推理优化,降低批处理序列之间的延迟方差,从而保证在大规模批处理解码期间的高吞吐量。
快慢思考双系统认知结构
受认知心理学中双过程理论的启发,盘古 Embedded 提出双系统认知架构,使得模型同时具备快思考(System 1)与慢思考(System 2)两种思维能力。
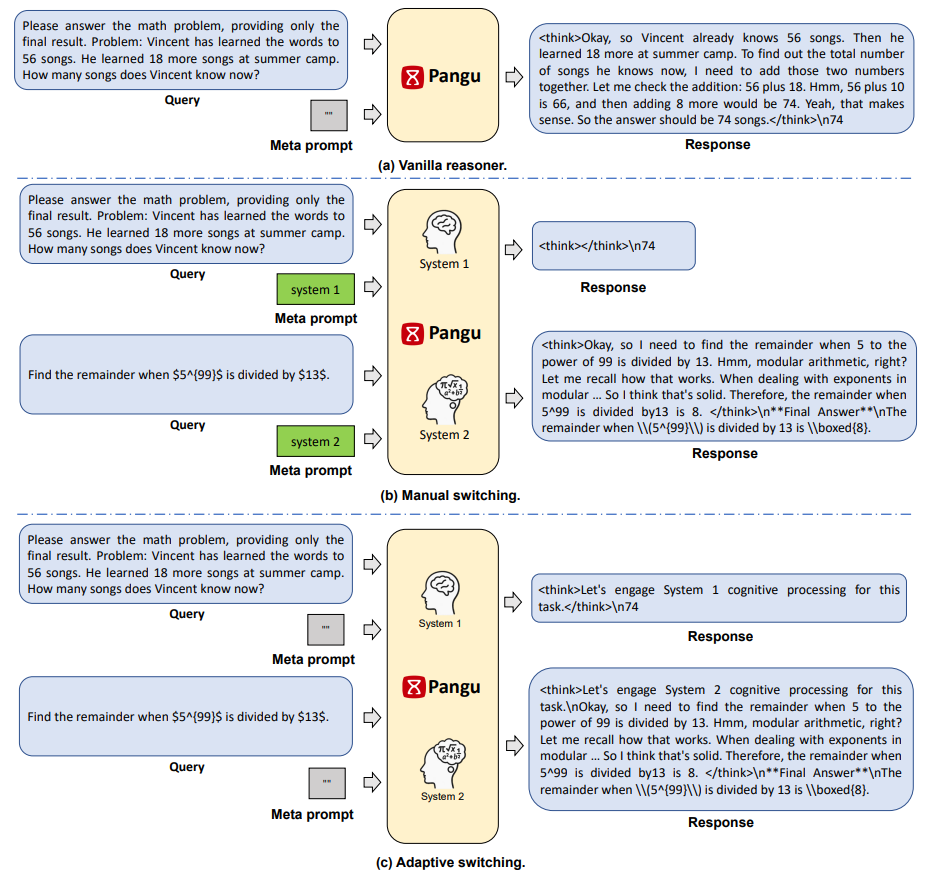
三种不同的思考模式:(a) 传统的推理模型,默认慢思考。(b) 手动切换,允许用户手动调整快思考(System 1)与慢思考(System 2)模式。
(c) 自适应切换,模型将基于任务复杂度自动切换快慢思考。
首先,团队实现了手动切换功能,允许用户通过给定的 meta prompt 来指定模型的认知模式,例如 META_PROMPT: system 1 和 META_PROMPT: system 2,
分别指代模型采用快思考模式与慢思考模式。这种特殊的 meta prompt 独立于 system prompt,可在避免干扰预期功能的情况下显式指定模型的快慢思考模式。
为了将快慢思考两种不同的能力灌输给模型,团队采用了融合训练的方式:基于已经训练好的一阶段慢思考模型,辅以快慢思考混合数据进行训练。
1.慢思考数据:继续训练部分已经掌握的慢思考数据,避免可能出现的遗忘;
2.快思考数据:引入新的快思考数据(直接输出答案,或者非常短的 CoT)。
在此基础上,分别添加 “System 2” 和 “System 1” 指令,这种训练方式使得模型保留了深度推理能力的同时,能够学习到快速思考的能力,
并可以基于用户的指令熟练地切换两种模式。
此外,团队还提出新颖的自适应切换功能,能让模型根据任务的难度自动选择快慢思考。

模型能力
通用评测榜单
盘古 Embedded-7B 与 Qwen3-8B、GLM-4-9B 和 Nemotron-Nano-8B 的主要对比详见下表。
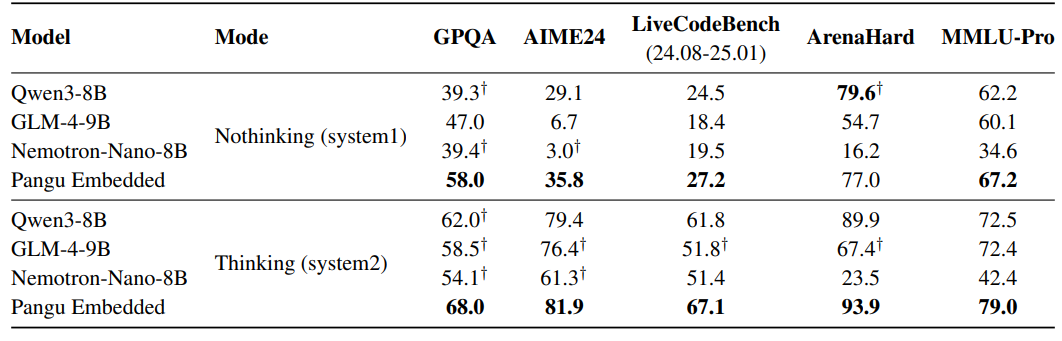
不同模型在通用领域基准测试的能力对比。盘古 Embedded 的模型参数量级为 7B。
“Nothinking (system1)” 和 “Thinking (system2)” 分别对应其快思考和慢思考模式。† 表示结果来自模型官方的报告。每个数据集的最佳结果以粗体显示。
可以看到,在慢思考和快思考模型式下,盘古 Embedded 在多项基准测试中均表现出一流的水准。
在使用 “慢思考” 模式时,盘古 Embedded 在多个推理密集型基准测试中表现出领先能力。
在使用可提高推理效率的 “快思考” 模式时,盘古 Embedded 仍具有很强的竞争力。
行业垂域能力拓展性
在通用的推理能力增强之外,团队也探索了在垂域任务的表现。
以法律行业为例,团队基于行业语料,通过合成思维过程数据、多种类型数据配比、拒绝采样、蒸馏等技术提升模型的法律专业能力。
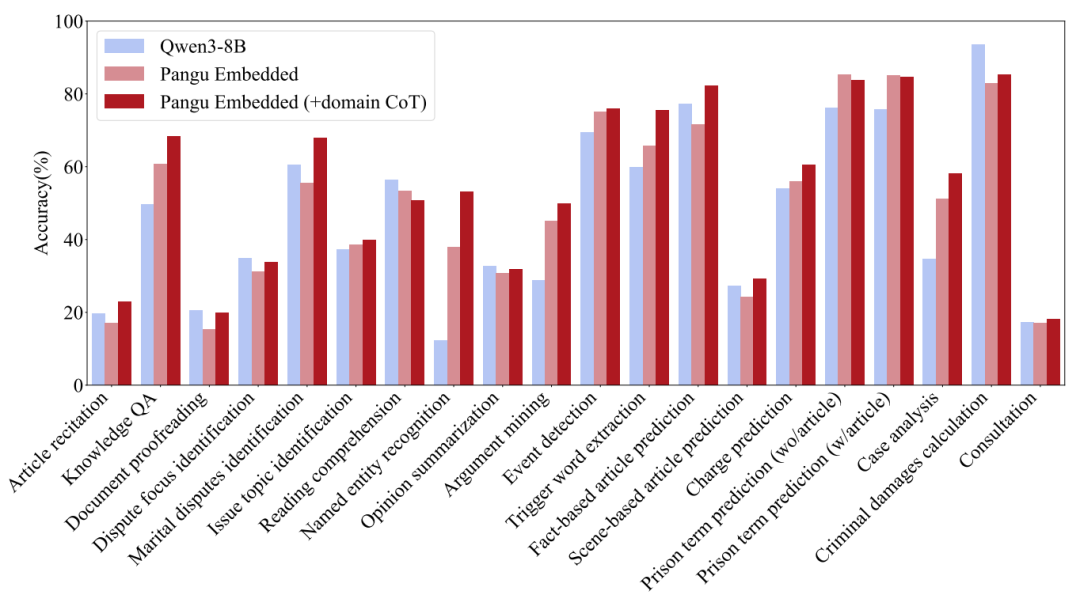
不同推理模型在 LawBench 基准上的能力比较
在 LawBench 为代表的法律任务中,在使用了法律领域的长思考数据继续训练之后,
盘古 Embedded 在 17 项子任务上的表现有了进一步提高,平均准确率达到 54.59%。
这些结果表明,在强大的通用推理模型基础上,通过有针对性的继续后训练,还有很大的空间可以提升在专业任务上的能力水平。
自适应快慢思考模式切换
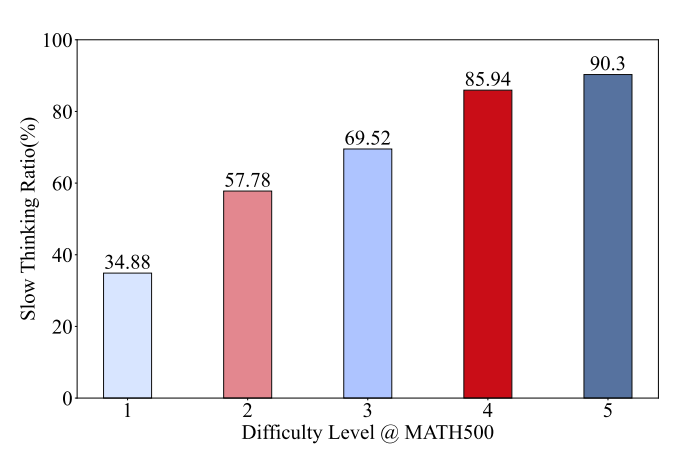
盘古 Embedded(自适应)在 MATH-500 基准测试中自主激活慢思考模式的比例分析(问题按难度分类)。说明该模型能够根据任务复杂程度自动调整推理深度。
团队在数学测试基准上分析了模型自动采用慢思考的问题比例。结果表明,这一比例随任务复杂程度的不同而变化:
对于相对简单的 GSM8K 数据集,慢思考模式的使用率低至 14.56%。
而在 MATH500 基准测试中,如上图所示,使用慢思考模式的趋势随着问题难度的增加而单调增加。
这表明,盘古 Embedded 能够有效地自动分配推理资源,以取得计算效率和推理准确性的平衡。
总结
华为盘古团队推出基于昇腾 NPU 开发的高效语言模型盘古 Embedded,其在同规格模型中实现了精度和速度的平衡。
该研究的核心创新在于提出的两阶段训练框架:
第一阶段通过迭代蒸馏构建鲁棒的基础推理器,关键技术包括模型型感知数据复杂度筛选、训练迭代间检查点融合实现知识巩固,
以及采用延迟容忍调度器与多源自适应奖励系统优化的大规模强化学习。
第二阶段创新性地赋予盘古 Embedded 双系统快慢思考能力,兼具用户手动切换与自适应模式选择功能,
动态平衡推理深度与计算效率,并配合重复自修正机制提升生成质量。
本研究为开发效率更高、性能更强的语言模型提供了新的路径探索。
文章来自于微信公众号 “机器之心”,作者 :机器之心编辑部




【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
