# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
然而,当战场转移至多模态推理场景时,这些「思维巨匠」却表现平平:GPT-o在MathVista、MathVerse等多模态推理基准上的表现与快思考模型持平,甚至被 Qwen2.5-VL-72B 超越。
为何文本推理中得心应手的慢思考能力,在多模态场景中却难以施展?
来自港科大、滑铁卢大学、INF.AI、Vector Institute的研究团队深入探究了这一问题,揭示了视觉语言模型(VLM)在慢思考能力构建中的两大核心障碍 :「优势消失」与「反思惰性」,并提出了创新的解决方案——VL-Rethinker。
该模型通过「优势样本回放」(Selective Sample Replay)和「强制反思」(Forced Rethinking)两项关键技术,成功激发了VLM的深层推理和自我校准能力。

研究团队在训练如Qwen2.5-VL-72B等大规模视觉语言模型时发现,经典GRPO用于多模态模型的强化训练时面临两大核心挑战:
1.1 GRPO中的「优势消失」问题 (Vanishing Advantages)
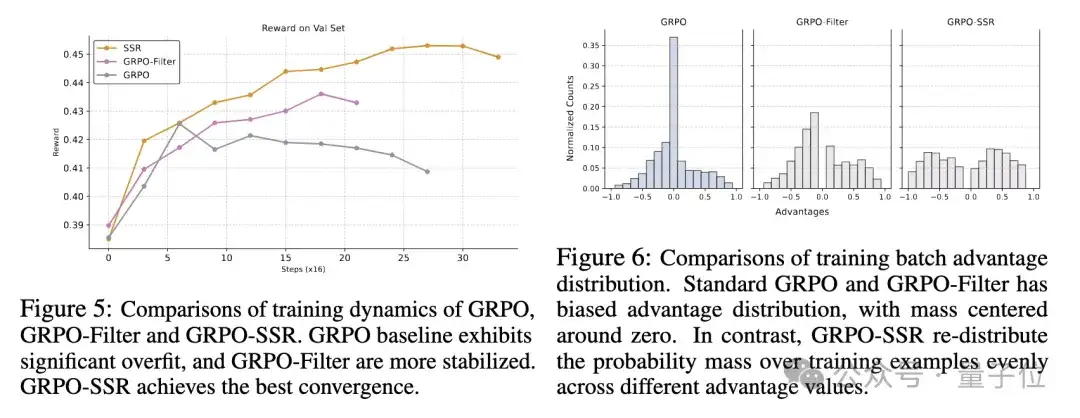
在GRPO算法中,优势信号(advantage)是通过比较同一查询组内不同候选回复的奖励来计算的 。当同一个问题组内所有回答获得相同奖励(例如,全部正确或全部错误)时,计算得到的优势信号便为零 。研究团队发现,在GRPO训练多模态模型的过程中,随着训练的推进,出现零优势信号的样本比例显著增加,这种现象被定义为「优势消失」 (Vanishing Advantages)。
相比于用于更多高质量推理数据的纯文本推理,Vanishing Advantages在能力较强的多模态模型强化学习时尤其突出。
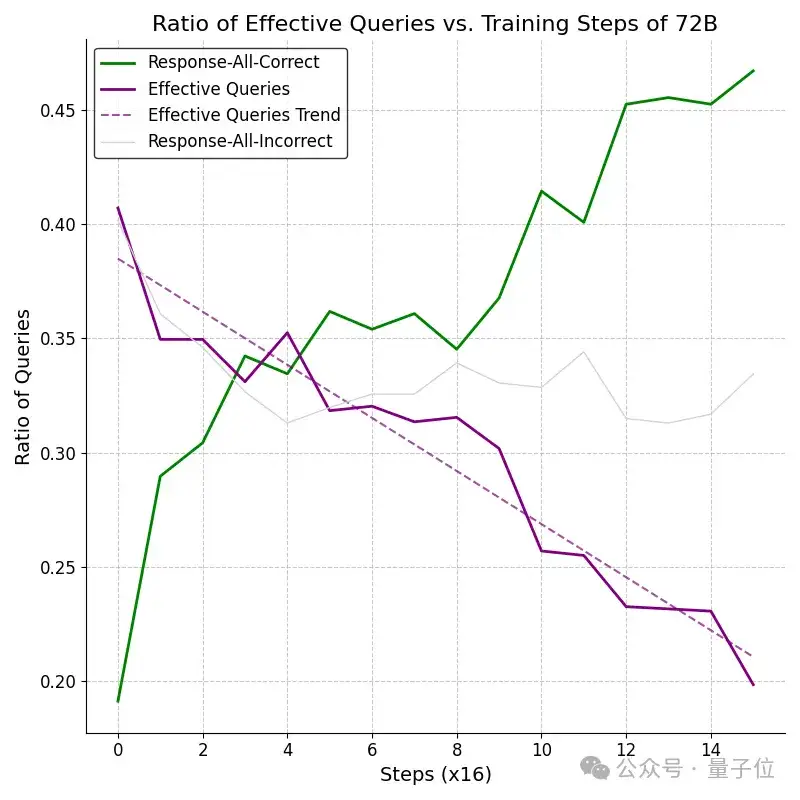
例如,在训练Qwen2.5-VL-72B模型时(如图所示),初始阶段具备非零优势信号的有效查询比例约为40%,但在仅仅约256个梯度更新步骤(16x16 steps)后,此比例便迅速下降至20%以下。
这种显著的Vanishing Advantages源于两方面原因:
Vanishing Advantages也带来双重负面影响:
1.2 多模态模型的「反思惰性」
与纯文本模型经强化训练后自发产生长思考链不同,现有 VLM 基座受限于视觉模态的感知驱动特性与预训练语料中反思模式稀缺性,更倾向于执行「快思考」(直接映射感知输入与语言输出),缺乏对推理过程的主动审视与修正能力。
这种「反思惰性」使得标准强化训练难以激活 VLM 的慢思考潜能,成为多模态推理能力进阶的第二大瓶颈。
针对高质量开源数据稀缺的挑战,研究团队精编了ViRL39K强化训练数据集。
数据集精选现有多模态推理数据和新增推理数据,经过清洗、验证、改写获得38870条高质量多模态推理问题。
这39K数据,不仅囊括八大主题,包括逻辑推理、图表推理、空间推理、科学问答等。
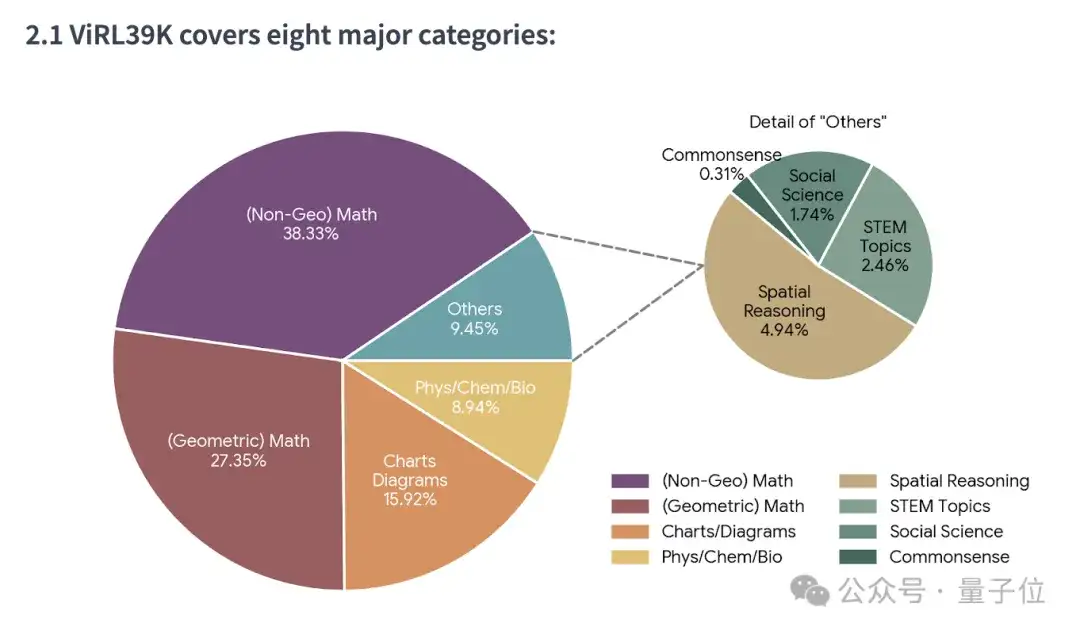
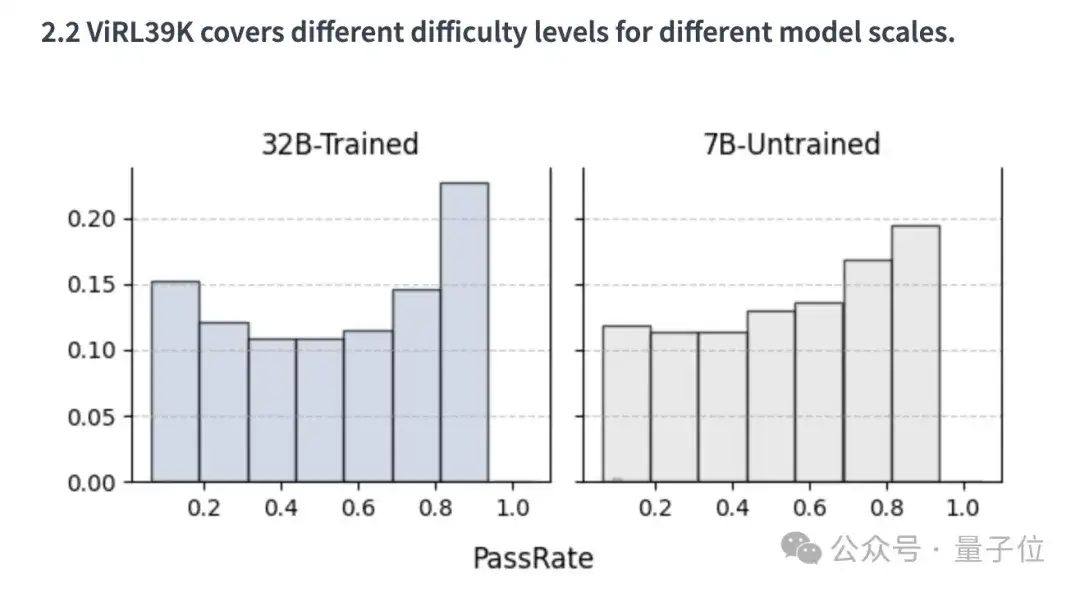
还包含细粒度模型能力标签,并针对不同能力水平的模型提供均匀的难度分布。
基于ViRL39K训练数据,研究团队开发了VL-Rethinker—— 首个专为多模态场景设计的慢思考强化框架,其核心由两大创新技术构成:
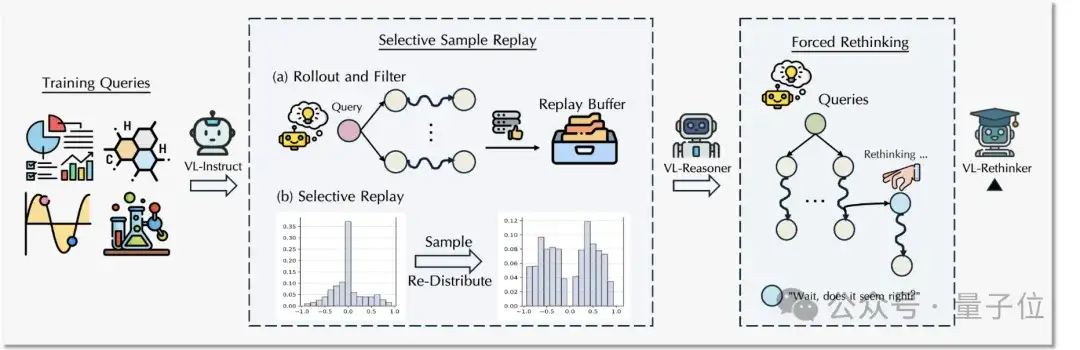
2.1 优势样本回放 (Selective Sample Replay, SSR)
针对Vanishing Advantages,研究团队提出了优势样本回放(SSR)来动态聚焦高价值训练样本。
SSR引入经验回放机制,动态存储非零优势训练样本,并设计价值敏感回放策略:优先复用绝对优势值较大的「关键样本」(如难例正确解、易例错误解)。
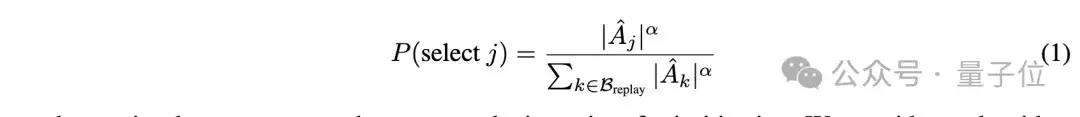
这种设计提供了双重优势:
目前SSR技术已经在Pixel Reasoner、SkyR1V2中得到应用。
2.2 强制反思 (Forced Rethinking)
为了克服VLM的「反思惰性」,研究团队提出了「强制反思」机制:当模型生成初步回答后,人为地追加一个特定的“反思触发”文本,强制模型启动二次推理流程。研究团队设计了包括自我验证、自我纠错和自我提问等多种类型的反思触发器,以引导模型学习并生成多样化的反思行为(如词云中所示)。训练样本中,进行强制反思的回答只对正确的部分进行保留。

研究团队发现,这种拒绝采样结合简单的正确性奖励,就能够让模型学会选择性地触发反思过程,而非盲目地对每个问题都进行冗余的二次思考,从而实现了更高效、更智能的「慢思考」。
有趣的是,VL-Rethinker习得的反思能力不仅限于审慎模型自身的回答,甚至帮助模型意识到题目中的错误。在下面的例子中,模型在反思自己的推理过程时,意识到了自身推理和题目的矛盾之处,从而意识到问题设定中的错误。

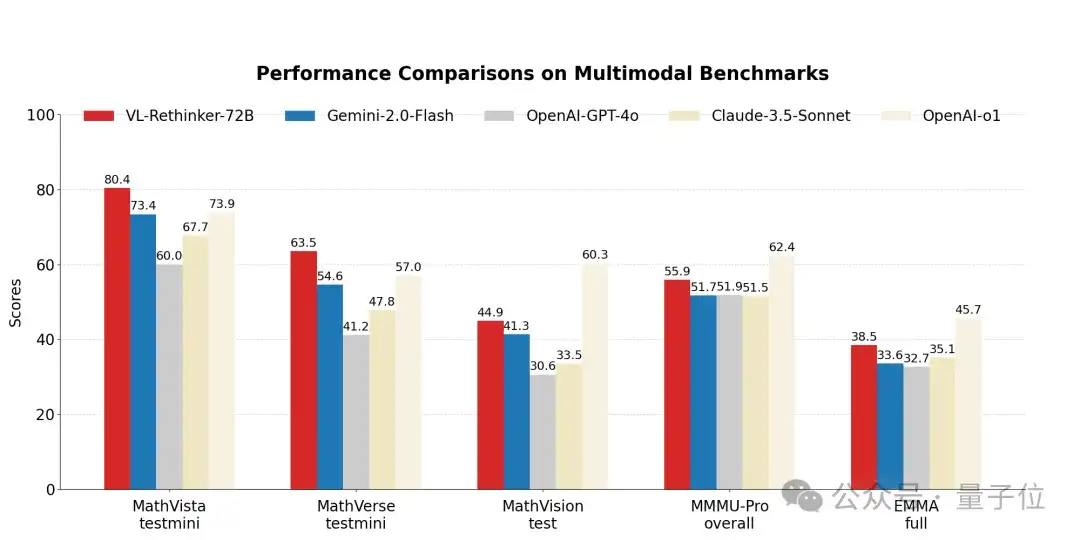
在数学推理任务中,在MathVista数据集上取得80.4%的成绩,在MathVerse数据集上达到63.5%,均超越GPT-o1模型(分别为73.4%和57.0%);在MathVision 任务中以 44.9%的成绩保持领先地位。
多学科理解能力测试中:
MMMU-Pro 整体测试成绩达55.9%,EMMA全量测试成绩为38.5%,不仅刷新了开源模型的当前最优性能(SOTA),更接近OpenAI-o1模型的水平。
模型迭代效果显著:
实验结果验证了SSR的有效性,以及 “慢思考” 模式在多模态领域的应用潜力。
论文地址:https://arxiv.org/pdf/2504.08837
项目主页:https://tiger-ai-lab.github.io/VL-Rethinker/
高质量数据集:https://huggingface.co/datasets/TIGER-Lab/ViRL39K
模型试玩:https://huggingface.co/spaces/TIGER-Lab/VL-Rethinker
文章来自于微信公众号“量子位”。




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
