# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI医生的时代正在到来!
哈佛、斯坦福等学术医疗中心的医生发布重磅论文,测试了OpenAI o1-preview在医疗推理和诊断任务中的表现。
结果表明,在所有的实验中,无论是临床案例还是急诊室的第二意见,o1-preview的表现都全面超出人类医生!

论文地址:https://arxiv.org/pdf/2412.10849
文章中,研究团队全面评估了o1-preview与数百名医生表现的对比。
此外,他们还在波士顿一所大型学术三级急诊中心随机抽取患者,采用盲评方式,把大模型给出的「第二诊疗意见」与专家医生的诊断进行对比。
团队首先使用《新英格兰医学杂志》(NEJM)发表的临床病例讨论(CPCs)来评估o1-preview。
两位医生对o1-preview给出的诊断质量评价高度一致——在143个病例中有120例观点相同(84%)。
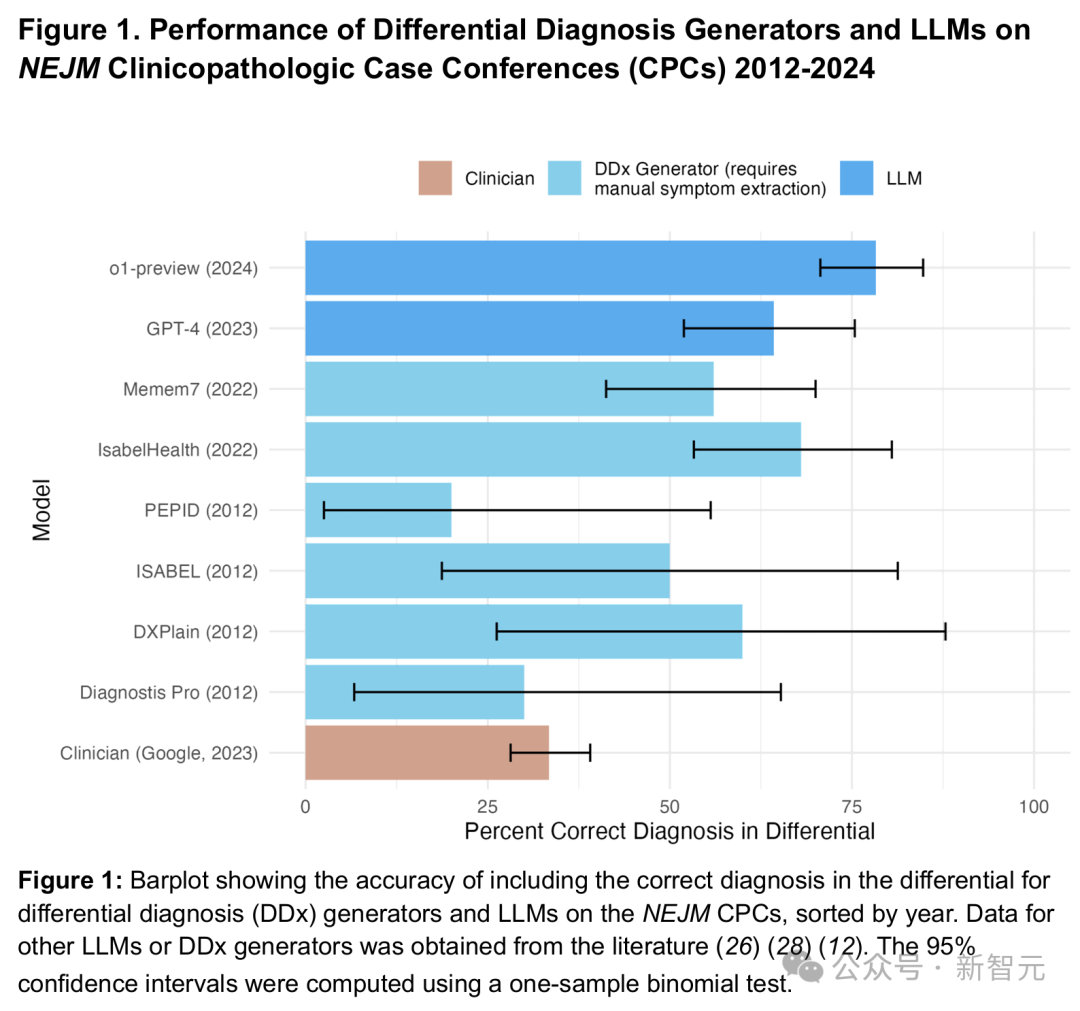
o1-preview在近八成病例(78.3%)中都把正确诊断列进了它的「待选清单」(图 1)。
如果只看它给出的第一个诊断,有52%一击即中。
另外,无论是在预训练数据截止点之前还是之后,模型的表现没有明显差异:截止点前准确率为79.8%,截止点后为73.5%。
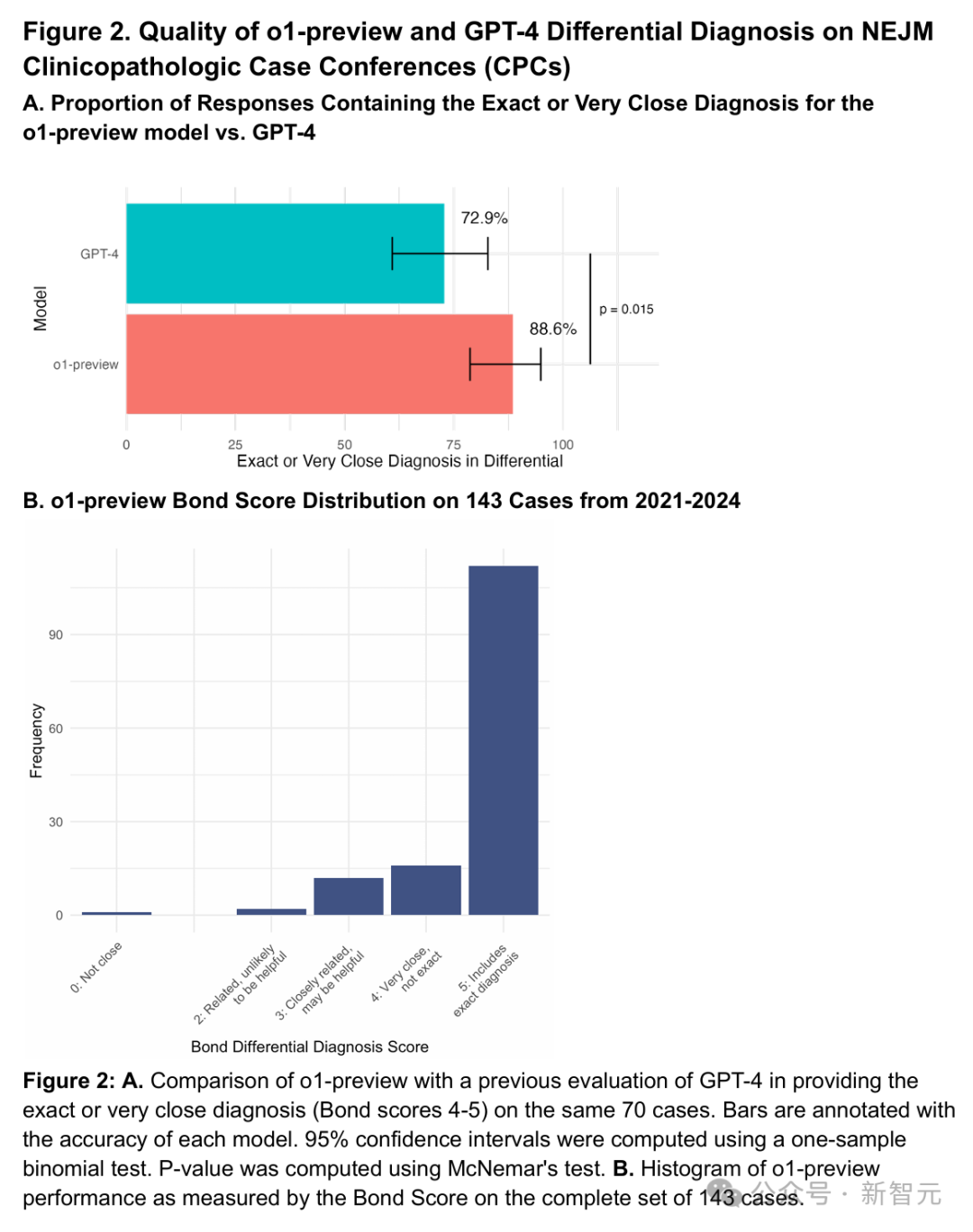
在之前的用GPT-4评估的70个病例中,o1-preview在88.6%的病例中给出了完全正确或非常接近的诊断,相比之下GPT-4为72.9%(图2)。
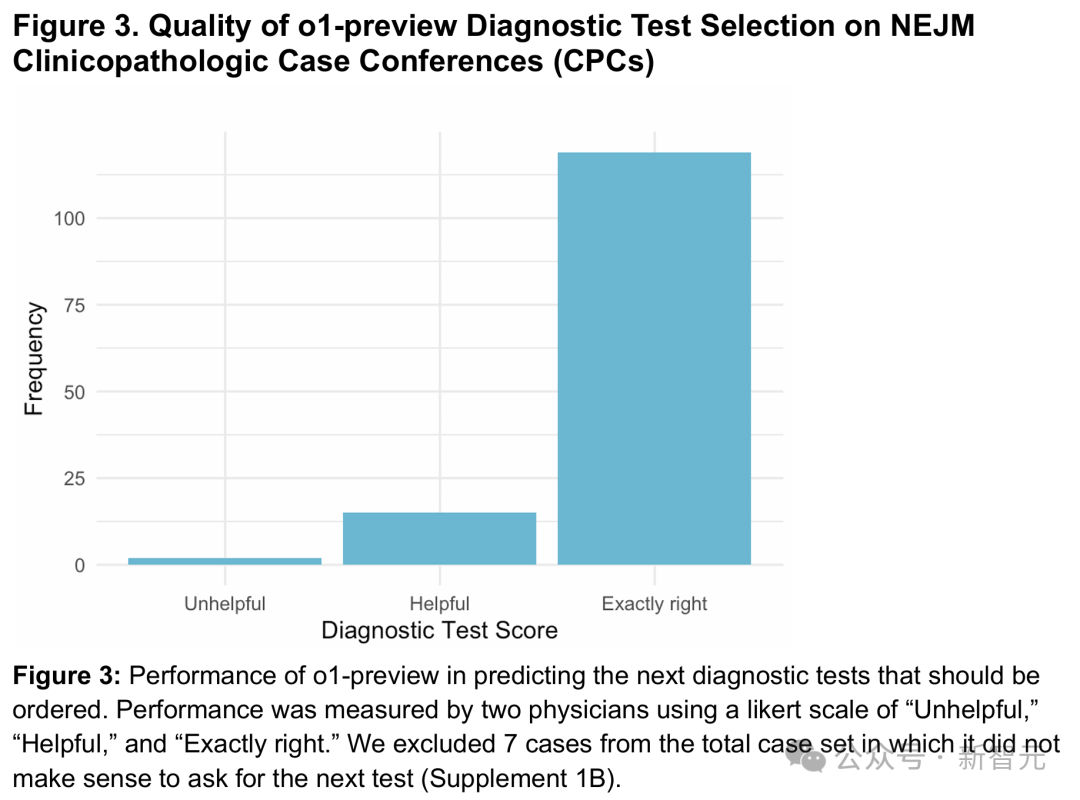
接下来,研究团队评估了o1-preview在NEJM CPC病例中选择下一步诊断检查的能力。
两位医生对o1-preview提出的检查方案评分。
在87.5%的病例中,o1-preview选择了正确的检查;另外11%的病例中,方案被两位医生视为「有帮助」;仅1.5%的病例中被认为「无帮助」(图3)。
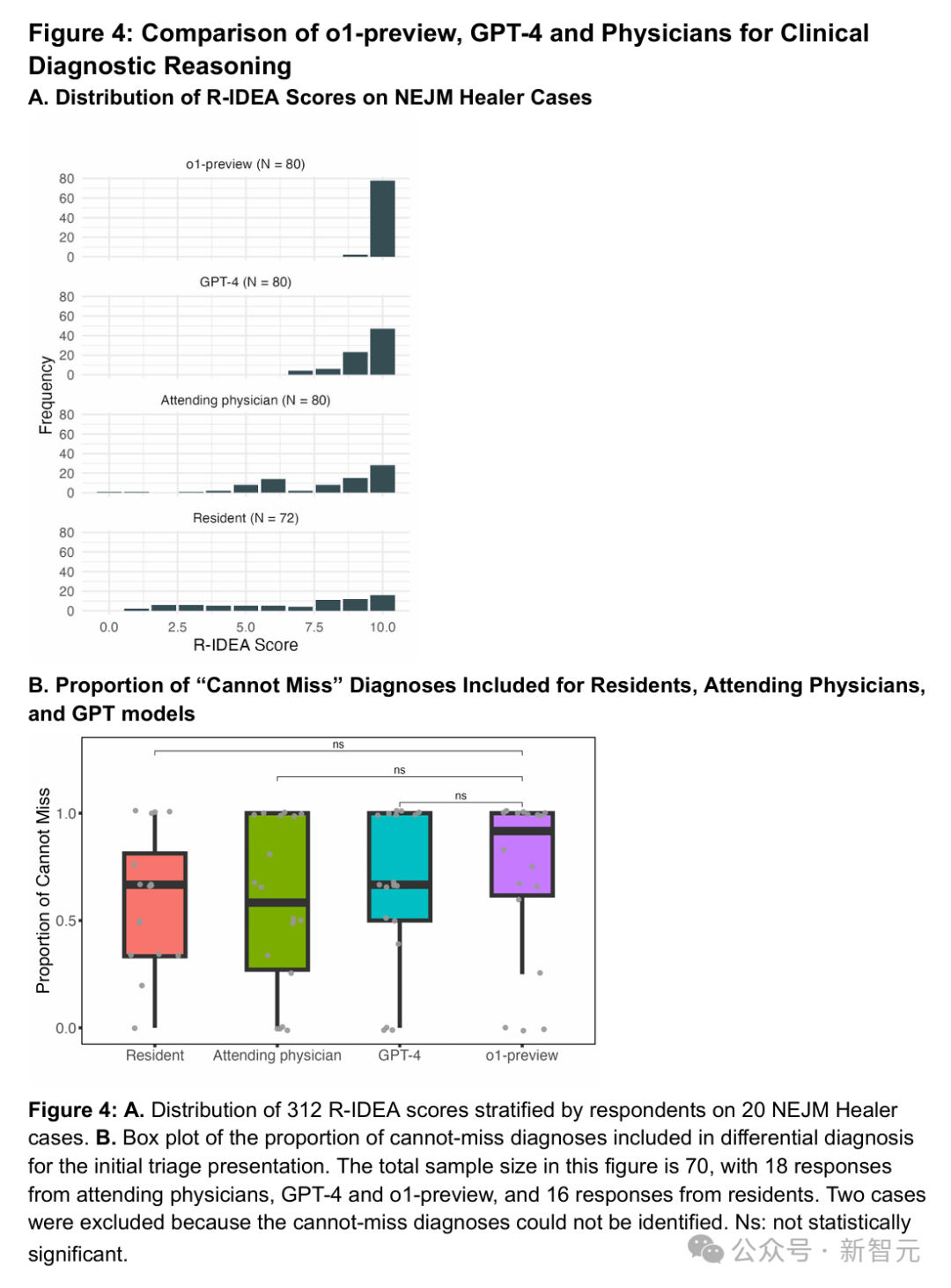
研究团队选取了NEJM Healer课程中的20个临床病例,NEJM Healer病例是一种面向临床推理评估的虚拟患者就诊场景。
在经过修订的IDEA(R-IDEA,一套验证过的10分量表,用来评估临床推理记录的四个核心维度)评分上,两位评审医生的意见高度一致
——在80份记录里有79份达成一致。
在80份记录中,o1-preview有78份拿到了R-IDEA满分。
它的成绩显著领先于GPT-4 (47/80,p < 0.0001)、主治医生(28/80,p < 0.0001)和住院医师(16/80,p < 0.0001)。(见图4A)
团队还统计了o1-preview在初始分诊阶段覆盖「绝不能漏诊」病因的比例(图4B)。
该模型的中位覆盖率为0.92,但与GPT-4、主治医生或住院医生相比无显著差异。
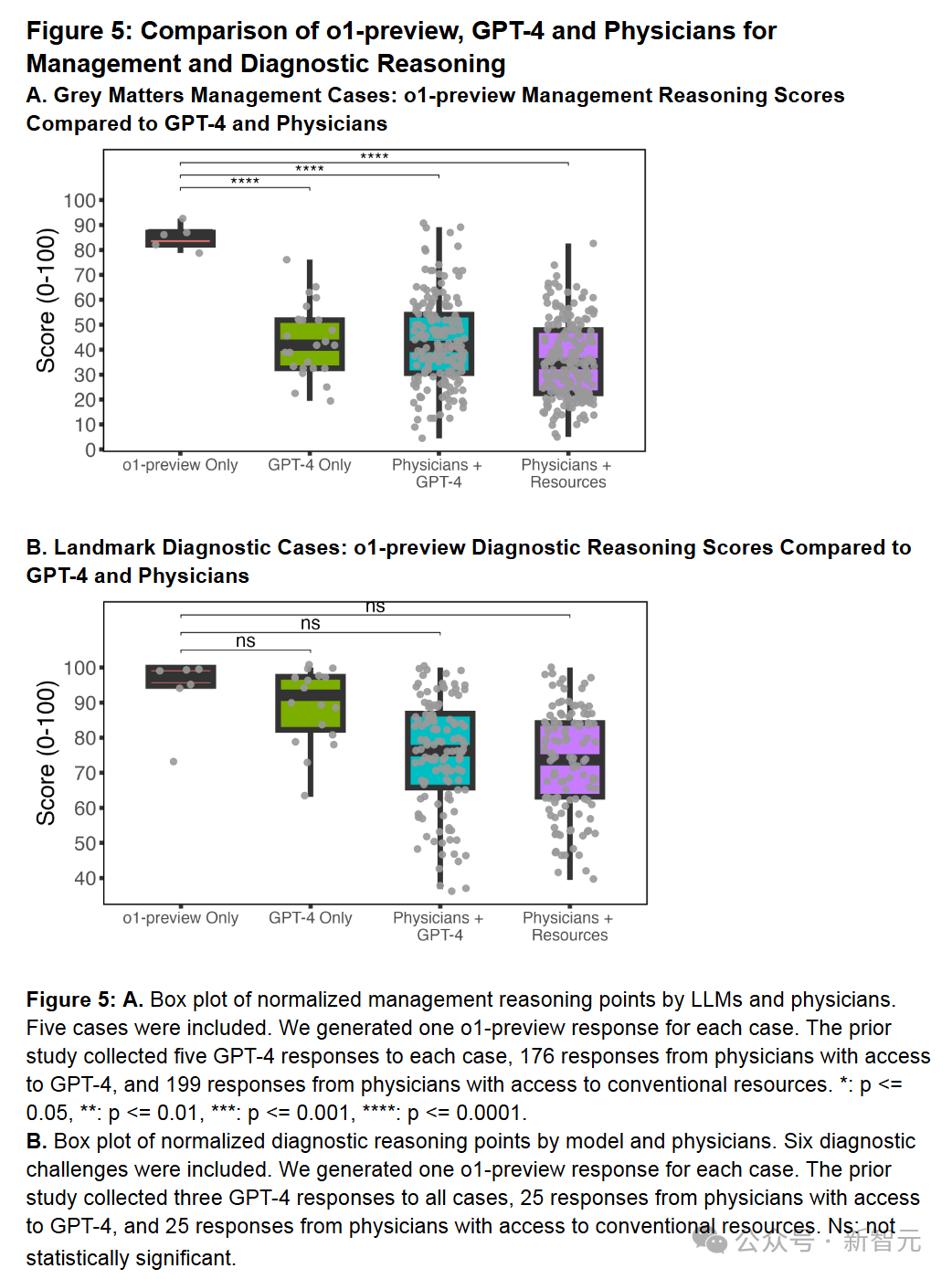
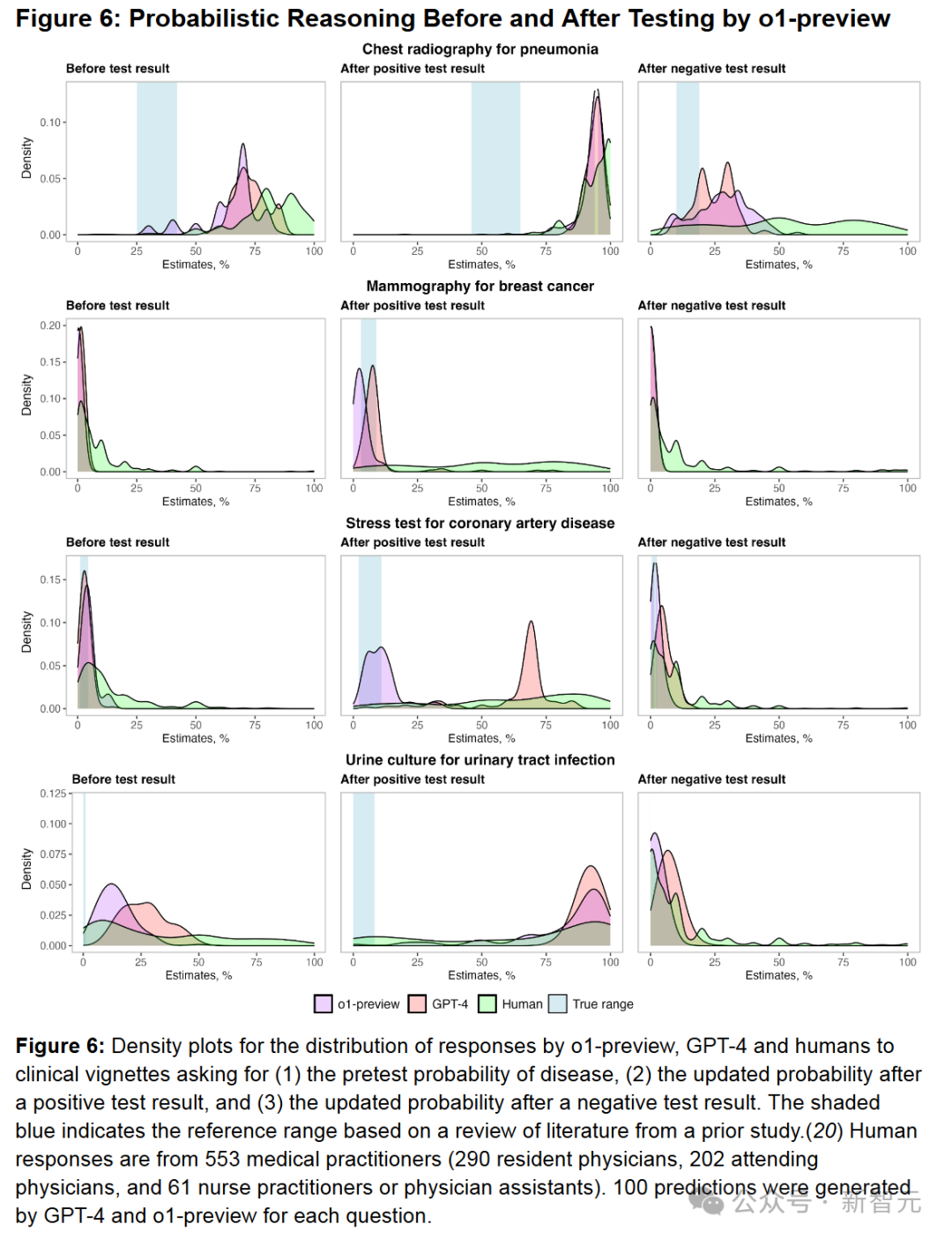
此外,在灰色事项管理案例、标志性诊断案例、诊断概率推理案例中,o1-preview都比GPT-4、使用GPT-4的医生及使用常规资源的医生表现要好。(图5A/B、图6)
急诊案例
研究团队比较了o1、GPT-4o和两位主治医师在诊断疾病方面的能力。
他们选取了贝斯以色列女执事医疗中心的79个病例,并将诊断过程分为三个关键节点:
急诊室初步分诊、急诊室医生诊断,以及转入普通病房或重症监护室时的诊断。
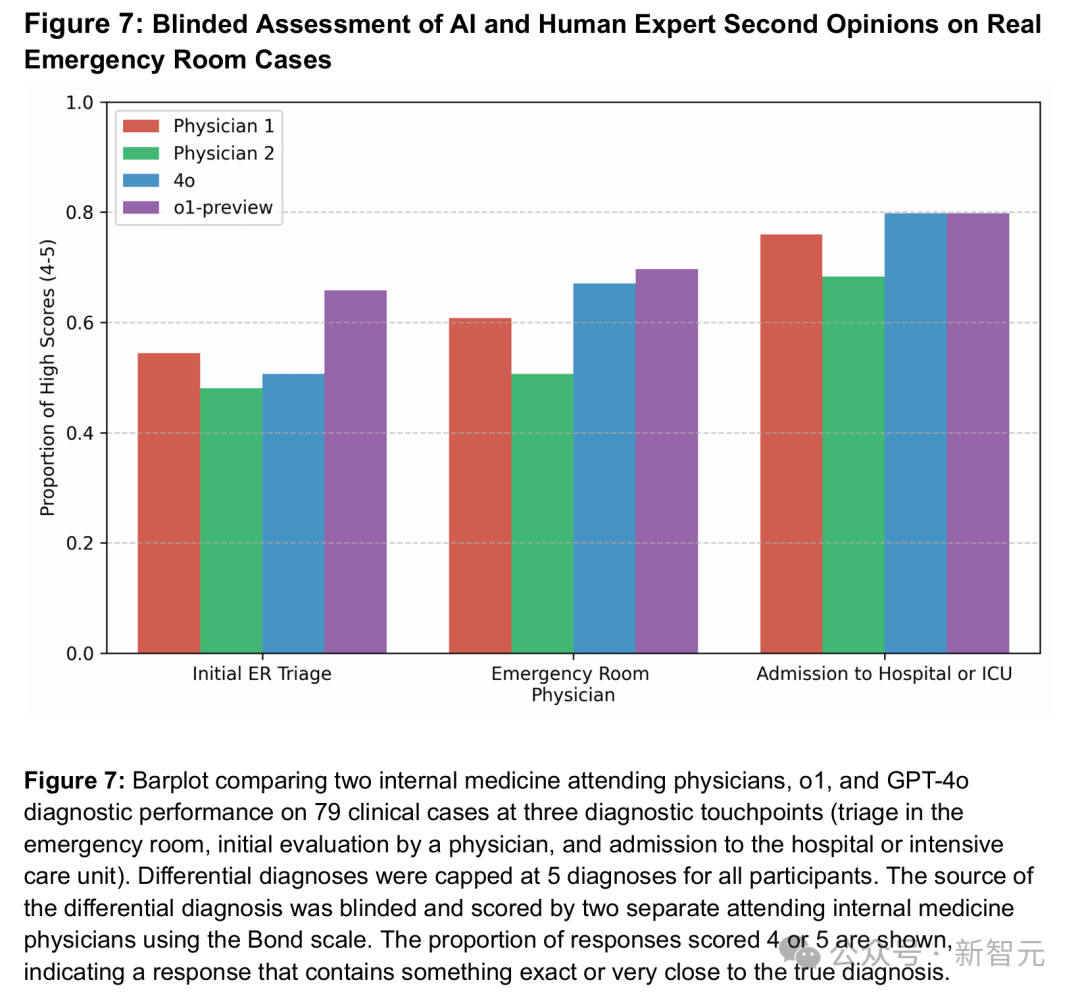
总的来说,o1的表现比4o和两位专家医生都要好。
这个评估是由另外两位医生进行的,他们事先都不知道自己评估的诊断结果是来自人类医生还是AI。
这种「盲评」很成功:一位评估医生猜对诊断来源(AI还是人类)的准确率只有 14.8%
(83.5%的情况表示「无法判断」),另一位医生则只有 2.7%(84.6%的情况表示「无法判断」)。
在每一个诊断节点上,o1的表现要么优于两位医生和4o,要么与他们持平。
尤其是在第一个诊断节点——急诊室初步分诊时,表现差异最为明显。在这个阶段,关于患者的信息最少,但做出正确诊断的紧迫性却最高。
o1在初步分诊中识别出完全正确或非常接近的诊断的比例为65.8%,急诊医生阶段为69.6%,ICU阶段为79.7%,均超过两位医生
(医生1:54.4%、60.8%、75.9%;医生2:48.1%、50.6%、68.4%)。
总的来说,o1在所有实验中都展现了超越人类的表现。尤其是在急诊科使用真实且非结构化的临床数据进行真实病例诊断时,o1的表现超越了专业医生。
随着可用信息的增加,o1、4o和人类医生的诊断能力均有所提升。
然而,两个模型的表现始终优于人类,尤其是在信息量较少的情况下,o1的优势最为明显。
对于该论文的研究成果,沃顿教授Ethan Mollick认为,医生应该使用AI来获取诊断的「第二意见」。
他们可以选择是否采纳AI的建议,但不使用AI「越来越像自愿放弃一种能帮助患者的重要工具。」
本文作者之一,医学博士Liam McCoy也表示称,AI尤其适合执行鉴别诊断的任务。这类任务富有创造性,且高度依赖联想。
不像敲定最终诊断结果那样,需要依赖「世界模型」或无懈可击的推理能力。

o1-preview的突破表明,AI不仅能辅助医生,还可能重塑医疗诊断流程,未来或将广泛应用于临床实践。

正如沃顿教授Ethan Mollick所言,拒绝AI辅助如同「放弃重要工具」。
但这场变革的核心,或许不在于谁更优秀,而在于如何让人类医生的经验与AI的精准形成合力。
参考资料:
https://x.com/emollick/status/1925362565946786206
https://arxiv.org/pdf/2412.10849
文章来自于微信公众号 “新智元”,作者 :犀牛



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
