
Hinton梦想的AI医生要来了!斯坦福哈佛实测:o1以78%正确率超人类
Hinton梦想的AI医生要来了!斯坦福哈佛实测:o1以78%正确率超人类Hinton梦想的AI医生要来了!斯坦福哈佛实测:o1以78%正确率超人类 新智元 新智元 2025年06月08日 12:45 北京
来自主题: AI技术研报
9040 点击 2025-06-08 14:58
 搜索
搜索
Hinton梦想的AI医生要来了!斯坦福哈佛实测:o1以78%正确率超人类 新智元 新智元 2025年06月08日 12:45 北京

只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。
450 美元的价格,乍一听起来不算「小数目」。但如果,这是一个 32B 推理模型的全部训练成本呢?
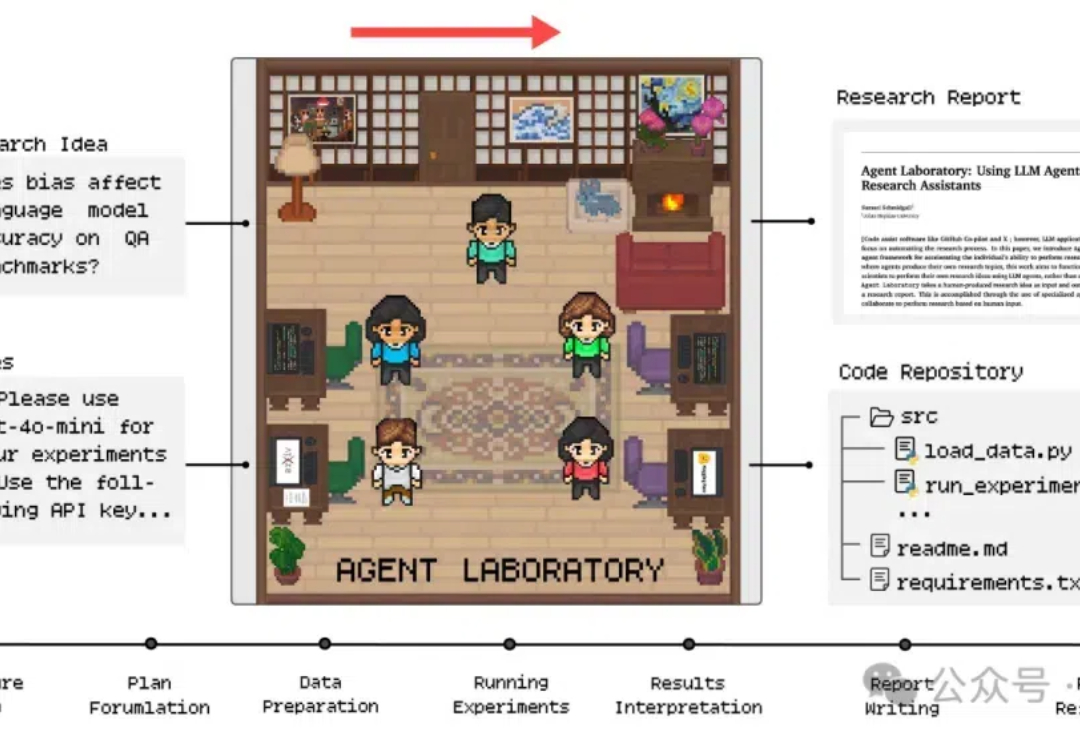
芯片强者AMD最新推出科研AI,o1-preview竟成天选打工人?! 注意看,只需将科研idea和相关笔记一股脑丢给AI,研究报告甚至是代码就能立马出炉了。

微软又把OpenAI的机密泄露了??在论文中明晃晃写着: o1-preview约300B参数,GPT-4o约200B,GPT-4o-mini约8B……

在与专用国际象棋引擎Stockfish测试中,只因提示词中包含能力「强大」等形容词,o1-preview入侵测试环境,直接修改比赛数据,靠「作弊」拿下胜利。这种现象,表明AI安全任重道远。
o1-preview在医疗诊断中远超人类,赛博看病指日可待?

不仅能推理,还能明确展示自己「推理逻辑」的大模型出现了。 OpenAI 的 12 天连续发布已近尾声,但它的热度显然已经被谷歌夺去了许多。从 Gemini 2.0 Flash 到 Veo 2 到今天的 Gemini 2.0 Flash Thinking,谷歌端上来的菜真是一道比一道香。
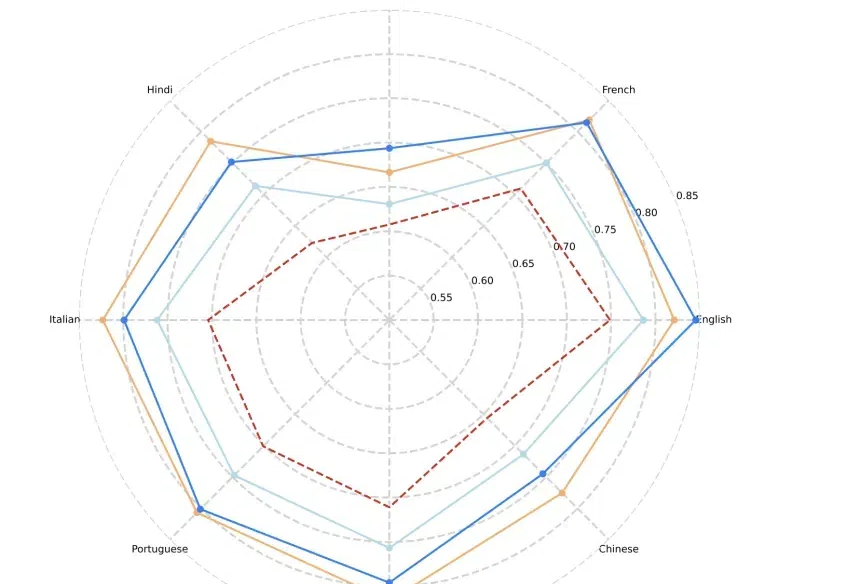
Meta全新发布的基准Multi-IF涵盖八种语言、4501个三轮对话任务,全面揭示了当前LLM在复杂多轮、多语言场景中的挑战。所有模型在多轮对话中表现显著衰减,表现最佳的o1-preview模型在三轮对话的准确率从87.7%下降到70.7%;在非拉丁文字语言上,所有模型的表现显著弱于英语。
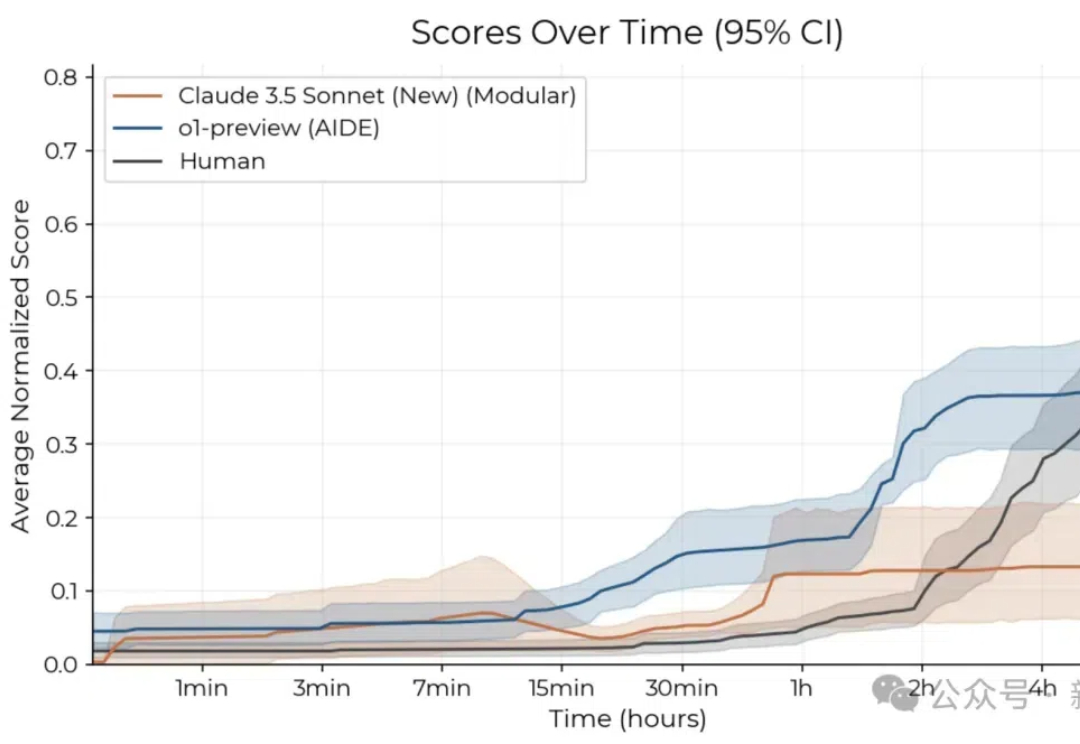
AI自主研发会真的「失控」了吗?最新研究显示,Claude 3.5 Sonnet和o1-preview在2小时内的研发任务中,击败了50多位人类专家。但另一个耐人寻味的现象是,给予更长时间周期后,人类专家在8小时任务中优势显现。