# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
瞄准AI大模型芯片,这12家创企凭什么?
芯东西1月10日报道,谈起生成式AI热潮的受益者,没有人能忽略英伟达。据The Information统计,目前北美地区至少有12家AI芯片创企想从英伟达独享的生成式AI算力红利中分一杯羹。
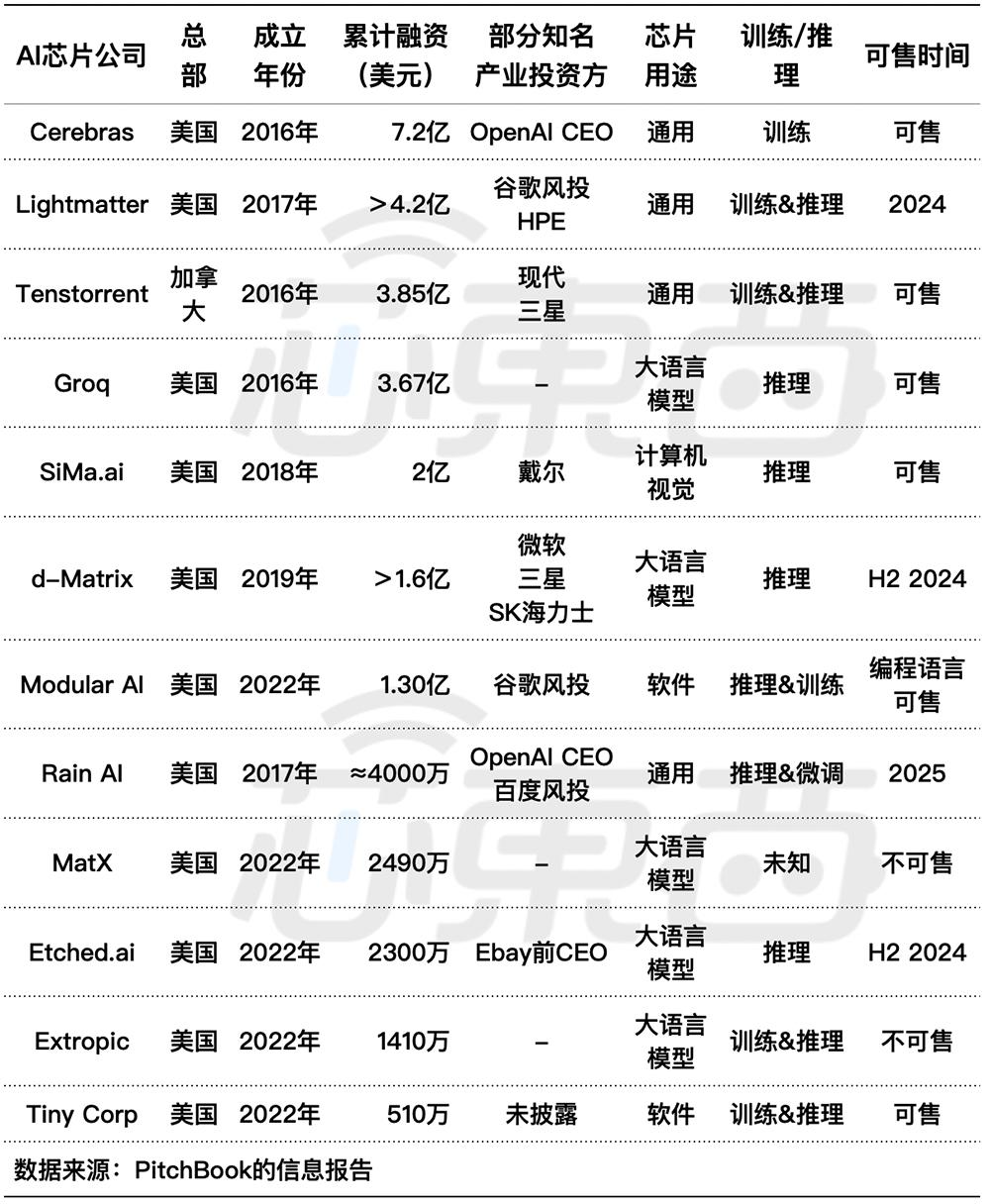
▲12家AI芯片瞄准大模型(芯东西根据The Information表格编译整理)
这些创企创办时间不超过8年,其中有5家都是2022年创办的,有4家创始成员有谷歌背景。累计融资金额最高的Cerebras,早已凭晶圆级芯片声名鹊起;成立相对较晚的5家创企,创始成员背景也各有千秋。
总的来看,这12家盯上生成式AI算力蛋糕的北美AI芯片创企,有的定位做训练,有的主攻推理,有些则更进一步,将其产品定位瞄准特定类型的AI模型,如多数大模型的基础Transformer。
这是一个高风险的游戏:这些关键选择将决定初创公司是生存还是失败。
推理一直是更受欢迎的选择。因为很多客户使用或微调已经被训练过的模型,而不是从头开始构建一个新模型。而高推理成本正对包括OpenAI在内的大模型及生成式AI公司们产生压力。
d-Matrix、Etched.ai、Extropic、SiMa.ai、Groq正在构建专门用于某些模型架构的芯片,如为OpenAI和Anthropic的大语言模型提供动力的Transformer。这些公司认为,专用芯片比英伟达、Cerebras、Lightmatter、Rain AI、Tenstorrent等的通用芯片更快、效率更高。
但芯片研发充满挑战与未知。这些创企的多数产品最早要到今年年底才会上市销售。到那时,Transformer可能已经是旧新闻了。一些开发人员已经在测试像Mamba这样的新模型架构。
Cerebras成立于2016年。其核心产品是第二代晶圆级引擎WSE-2,将85万个核心打包到一个处理器上,并采用40GB超快片上SRAM和比传统集群快几个数量级的互联技术。Cerebras官网将WSE-2称作是“地球上最快的AI芯片”。

Cerebras的创始成员中,CEO Andrew Feldman与CTO Gary Lauterbach曾分别是高带宽微服务器先驱SeaMicro的CEO和CTO,首席架构师Michael James曾任SeaMicro首席软件架构师。SeaMicro在2012年被AMD收购。

多位OpenAI联合创始人、Stripe前CTO、AMD前CTO兼总裁、Cadence前CEO等业界大佬都在其投资方阵容中。
Lightmatter成立于2017年,创始团队来自麻省理工学院。其研发的Envise光电混合计算芯片能够满足训练大语言模型等任务的计算要求,并减少数据中心功耗与成本。

2023年11月,Lightmatter宣布获得1.55亿美元融资,投资方包括谷歌风投等,这笔融资是其5月份C轮融资的延续。至此,Lightmatter累计融资额超过4.2亿美元,估值达12亿美元。
Tenstorrent成立于2016年,由AMD前嵌入式工程师Ivan Hamer、AMD前集成电路设计总监Ljubisa Bajic和AMD前固件设计工程师Milos Trajkovic创办。
硅谷顶级芯片架构师Jim Keller担任Tenstorrent CEO。该公司累计融资额达3.85亿美元,投资者包括三星、现代等,估值大约达到10亿美元,跻身独角兽企业之列。

这家AI芯片创企利用RISC-V和Chiplet技术打造可扩展、高能效的AI芯片,目前有两款机器学习处理器Grayskull和Black Hole,其更先进的3nm AI芯片Grendel预计今年推出。
Groq成立于2016年年底,由多位前谷歌TPU开发团队成员创办。他们基于软件定义硬件的思路,设计了一个张量流处理器TSP架构,旨在实现高性能、低延迟的AI加速。
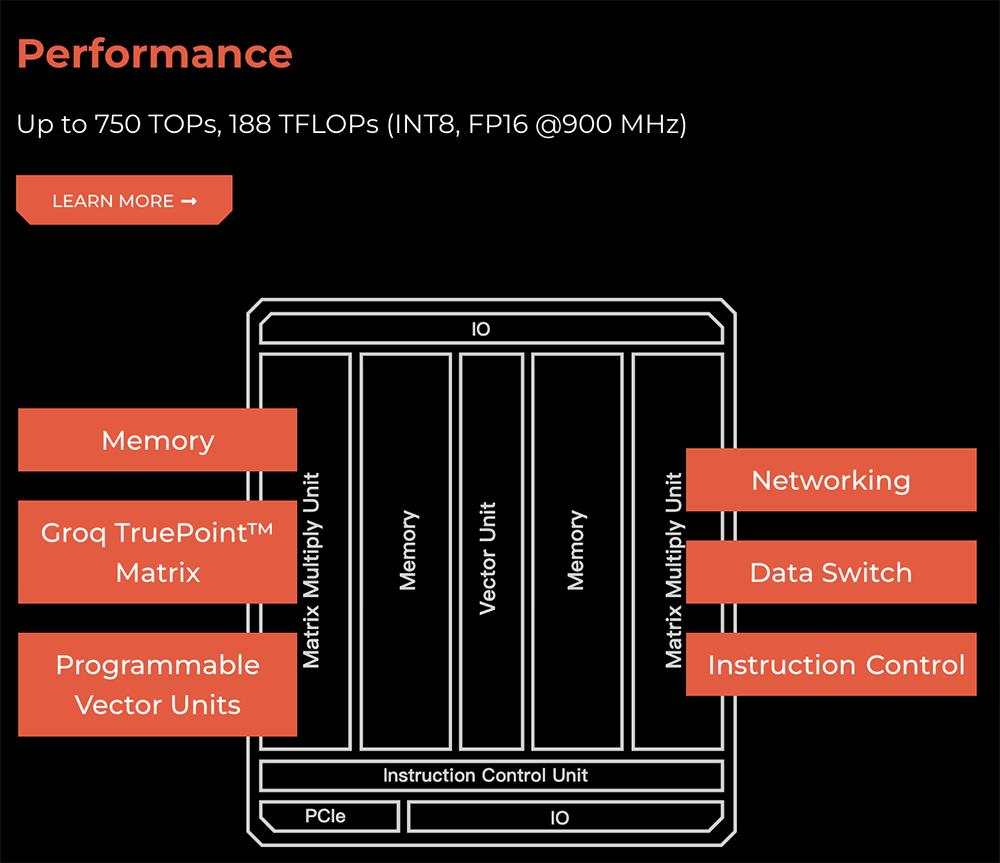
这家创企主要研发云端AI推理芯片,累计融资额达到3.67亿美元。去年Groq LPU加速器在Meta Llama 2 70B大语言模型上实现了每秒生成超过280个token的推理性能。
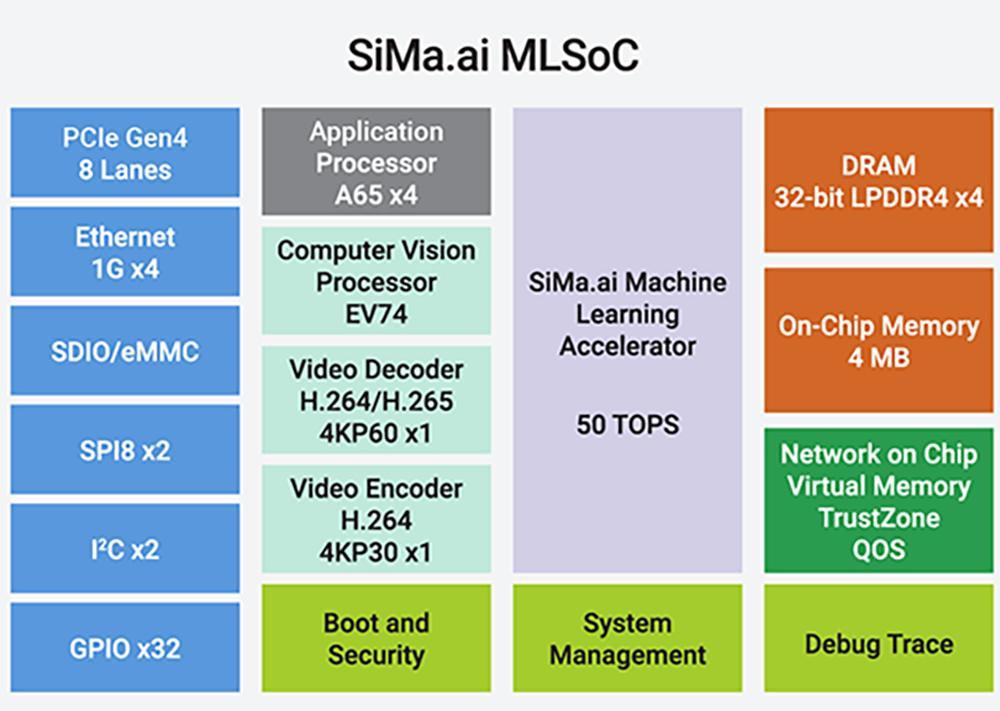
SiMa.ai成立于2018年。创始人兼CEO Krishna Rangasayee曾在全球最大FPGA芯片供应商赛灵思工作了近20年。
这家创企在2019年推出首款AI芯片组MLSoC,主要面向计算机视觉领域的推理计算。2023年6月,SiMa.ai称其第一代边缘AI芯片已开始量产,正与制造、汽车、航空等行业的50多家客户合作。
d-Matrix成立于2019年,主要研发存内计算AI芯片。官网宣称构建了“世界上最高效的大规模AI推理平台”,跑Llama 2 13B大语言模型的大规模推理速度“倍杀”H100和A100。

其最新数字存内计算芯片Jayhawk II采用台积电6nm制程和Chiplet D2D互连方案,可为生成式AI应用推理任务提供支撑。
该创企融资金额超过1.6亿美元,投资方包括微软、SK海力士等。微软承诺今年将对其芯片进行自用评估。d-Matrix预计两年内收入将达到7000万~7500万美元区间,并实现收支平衡。

Modular AI是这12家创企中唯一一家专注于软件的公司,成立于2022年,致力于构建出模块化、可组合和分层架构的AI基础设施,包括打造编译器、运行时环境等,开发出CUDA替代品。

这家创企在2023年8月获得1亿美元融资,投资方包括谷歌风投。其CEO是LLVM之父Chris Lattner,曾在苹果公司领导Swift编程语言的开发,后来与Modular首席产品官Tim Davis一起在谷歌工作,负责监督AI产品开发。
2023年5月,Modular AI首次举办发布会,推出高效推理引擎和Mojo编程语言。其高效推理引擎可轻松将主流深度学习框架上的模型快速部署到服务器或边缘设备上。Mojo编程语言无需C++和CUDA运行环境,即可直接将类似Python语言的代码高效部署到芯片上运行。
Rain AI成立于2017年,旨在解决使用传统GPU训练和运行机器学习的高成本问题。OpenAI CEO Sam Altman、百度风投都投资了这家公司。

其AI芯片设计理念受大脑启发。早在2018年,Altman就看好Rain走得类脑芯片路线,以个人名义向Rain AI领投了一笔种子轮融资。第二年,OpenAI签署一项不具有约束力的协议,计划等Rain AI的芯片上市后斥资5100万美元采购这些芯片,不过至今尚未采取后续措施。
Rain AI在2021年推出可训练的端到端模拟AI芯片的工作原型芯片,近期的AI芯片产品则采用数字存内计算技术。截至目前,其累计融资金额约为4000万美元。

MatX成立于2022年,专注于面向大语言模型开发更快的专用芯片,旨在设计出通用人工智能(AGI)的计算平台,比英伟达GPU等硬件更快、更省钱的芯片。
其CEO Reiner Pope参与构建谷歌PaLM模型,曾写出谷歌最快的推理软件;CTO Mike Gunter曾参与谷歌TPU工作。

根据官网信息,MatX已获得一些风投机构以及领先的大语言模型和AI研究人员的支持,但并未公布产品或融资额。

Etched.ai成立于2022年10月,两位创始人CEO Gavin Uberti和CTO Chris Zhu均在本科期间从哈佛休学,想要研发一款能加速大语言模型的AI芯片“Sohu”。
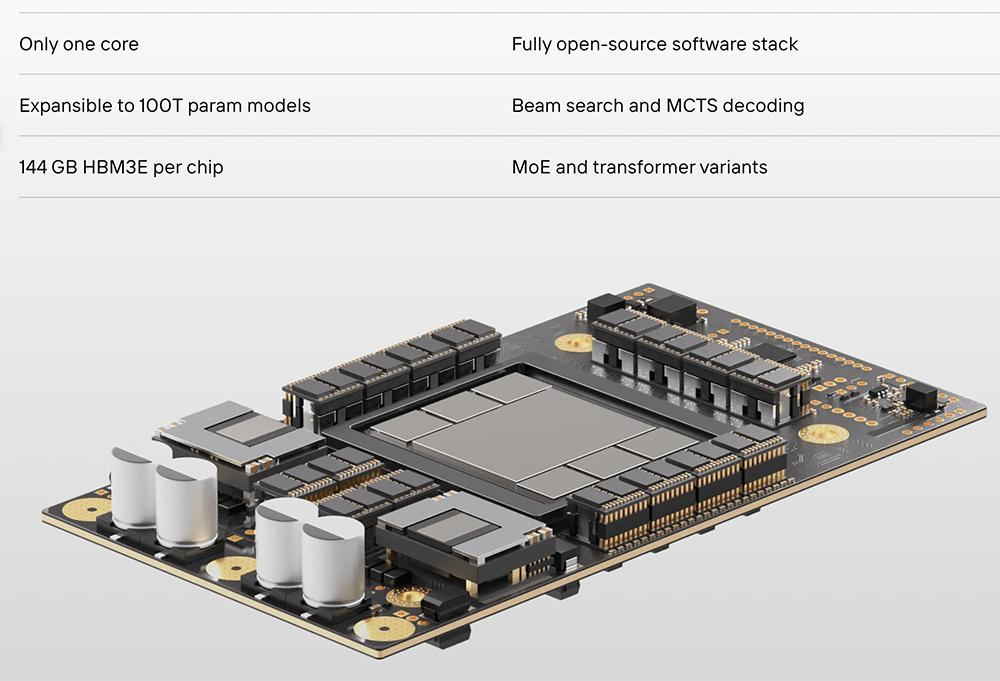
通过在硬件层面集成Transformer架构、配备144GB HBM3e显存,Sohu芯片的推理性能将达到英伟达H100的10倍,单位价格将获得140倍于H100的吞吐量性能。该芯片预计今年交付。

2023年6月,Etched.ai宣布获得536万美元种子轮融资,投资方包括包括Ebay前CEO Devin Wenig。融资后其估值达到3400万美元。
2023年的最后一个月,AI芯片创企Extropic宣布获得1410万美元天使轮融资。这家创企成立于2022年,创始成员CEO Guillaume Verdon和CTO Trevor McCourt来自谷歌量子AI团队。Guillaume 被认为是量子深度学习领域的先驱。

Extropic自称正在为物理世界中的生成式AI构建终极基础,利用热力学和信息的第一原理构建人工智能超级计算机。
目前,Extropic正在研发一款能运行大语言模型的AI芯片。其芯片的核心部件是一种叫做热力学逻辑门的微型装置,利用了热力学系统的能量转换和信息处理功能把热能等能量转化为算力。
Tiny Corp成立于2022年5月,其创始人兼CEO是业界知名黑客“神奇小子”George Hotz,他也是自动驾驶创企Comma AI的创始人。2023年5月,Tiny Corp获得510万美元融资。
George Hotz认为,创办AI芯片公司的唯一途径就是从软件开始,这家创业公司想要帮助开发人员加快训练和运行机器学习模型的过程。其首个项目是为AMD芯片构建框架、运行时和驱动程序,短期目标是使用tinygrad框架让AMD支持MLPerf。

文章来自于微信公众号 “芯东西”(ID:aichip001),作者 “ZeR0”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
